自调式听觉补偿装置、方法及电脑程序产品
文献发布时间:2024-04-18 19:58:53
技术领域
本发明关于一种听觉补偿技术,尤其指一种具有真耳测量(real earmeasurement,REM)分析的自调式(self-fitting)听觉补偿装置及其自调式听觉补偿方法。
背景技术
依据统计显示,中国台湾有身心障碍证明的听觉机能障碍者超过12 多万人,听力问题将会导致语言沟通、职业适应、社会参与、学校学习、生命安全等各重要生活层面,产生隐形或显著的障碍。
再者,中国台湾即将迈入超高龄社会,听力损失更是高居老人慢性病中的前三位。目前,由于在市面上的现代助听器及听觉辅具科技的进步,因而可大幅改善听觉障碍对个人、家庭、社区,乃至于整个社会的负面影响及负担。
然而,现代助听器及听觉辅具科技仍需要真耳分析仪进行调整,现有的真耳分析仪设置有探管,分别具有第一麦克风和第二麦克风,第一麦克风负责采集耳道口附近的声音,而第二麦克风负责采集近鼓膜处的声音。在进行真耳测试分析时,先将探管插入耳道内,探管尖端距离鼓膜约5mm左右,分别测试未戴助听器时和佩戴助听器后耳道内的声音改变情况,进而得到真耳插入响应REIR。具体而言,现有的真耳测试的操作步骤为:1)当耳道口没有放置助听器,即耳道口开放的时候,声场发出声音(包括所有频率且声压级相同),第一麦克风和第二麦克风记录的声压级差值曲线称为真耳未助听响应REUR(也称真耳未助听增益REUG);以及2)当耳道口放置助听器的时候,声场发出声音,第一麦克风和第二麦克风记录的声压级差值曲线称为真耳有助响应REAR(也称真耳有助听增益REAG),但是由于真耳测试必须在听检室内利用仪器检测且需通过听力专业人员的协助执行,如此较不具效率也不够即时。
此外,测量到的真耳响应通常与验配软体预期的结果不一致,主要的原因是,听损者的外耳与内耳的声学特性(例如,共振、音量、阻抗等特性)可能与软体预测中使用的「平均耳」资料不同,当进行真耳测试时,听损者独特的耳道特性则会体现,导致有所误差。再者,听损者的助听器的声学参数不同,例如,气孔大小或耳膜深度。因此,真耳测试需要额外的增益调整来匹配所指定或预期的目标增益。
另外,插入增益测量是验证助听器性能特征的常用方法。然而,正如上述,插入增益在助听器调试时有许多限制,导致仍有误差。
基于上述的原因,如何提供一种无须真耳分析仪、探管换能器(即,探管麦克风(probe microphone))、无须限定在专业的听力空间(如听检室)内进行真耳测量分析、并无须通过听力专业人员(如专业调音师) 的协助,以有效地解决上述问题的听觉补偿装置及听觉补偿方法,可在非听检室内的当前真实环境提供精准、即时、自动化且客制化使用者(特别是听障患者)的听力辅助器(如助听器、听觉辅具或具有助听功能的耳机、眼镜等听力设备、ANC耳机或TWS耳机等),遂成为业界亟待解决的课题。
发明内容
为解决前述现有的技术问题或提供相关的功效,本发明提供一种具有真耳测量的自调式听觉补偿装置、方法及电脑程序产品,以至少部分解决现有技术中的问题。
本发明的具有真耳测量的自调式听觉补偿装置,包括:第一换能器,其接收来自一装置的第一测试讯号,且将该第一测试讯号转换成第一电性讯号;听力补偿模组,其连接至该第一换能器,且对该第一电性讯号进行增益补偿;第二换能器,其连接至该听力补偿模组,并将增益补偿后的该第一电性讯号转换成声音,且将该声音传送至耳道内;以及第三换能器,其同步将该耳道内传送的该声音转换成第二电性讯号,以通过无线传输网络传送该第二电性讯号至该装置,其中,该装置计算该第二电性讯号在各频带下的能量分布,且比较该能量分布与目标增益及听力阈值的误差,若该误差不符合误差目标,则该装置对该误差进行量化,以借由补偿增益转换模型产生经修正的滤波器参数后,通过该无线传输网络传送该经修正的滤波器参数至该听力补偿模组以进行听力增益补偿。
本发明还提供一种具有真耳测量的自调式听觉补偿方法,包括下列步骤:借由第一换能器,接收来自一装置的第一测试讯号,且将该第一测试讯号转换成第一电性讯号;借由连接至该第一换能器的听力补偿模组,对该第一电性讯号进行增益补偿;借由连接至该听力补偿模组的第二换能器,将增益补偿后的该第一电性讯号转换成声音,且将该声音传送至耳道内;借由第三换能器同步将该耳道内传送的该声音转换成第二电性讯号,以通过无线传输网络传送该第二电性讯号至该装置;借由该装置计算该第二电性讯号在各频带下的能量分布,且比较该能量分布与目标增益及听力阈值的误差;以及若该误差不符合误差目标,则该装置对该误差进行量化,以借由补偿增益转换模型产生经修正的滤波器参数后,通过该无线传输网络传送该经修正的滤波器参数至该听力补偿模组以进行听力增益补偿。
此外,在一实施例中,本发明还提供一种具有真耳测量的自调式听觉补偿方法,包括下列步骤:借由第一换能器,接收来自一装置的第一测试讯号,且将该第一测试讯号转换成第一电性讯号;借由连接至该第一换能器的听力补偿模组,对该第一电性讯号进行增益补偿;借由连接至该听力补偿模组的第二换能器,将增益补偿后的该第一电性讯号转换成声音,且将该声音传送至耳道内;借由第三换能器同步将该耳道内传送的该声音转换成第二电性讯号,以通过无线传输网络传送该第二电性讯号至该装置;借由该装置计算该第二电性讯号在各频带下的能量分布,且比较该能量分布与目标增益及听力阈值的误差;依据该听力阈值,利用补偿处方计算出所需增益补偿,且将该所需增益补偿传送至补偿增益转换模型,并依据该听力阈值,利用听觉动态范围应用优化计算出所需听觉动态范围应用优化参数,且将该所需听觉动态范围应用优化参数传送至该补偿增益转换模型;以及若该误差不符合误差目标,则该装置对该误差进行量化,以借由补偿增益转换模型产生经修正的滤波器参数后,通过该无线传输网络传送该经修正的滤波器参数至该听力补偿模组以进行听力增益补偿。
于一实施例中,该听力补偿模组设置在主动式降噪的晶片或数字讯号处理电路的晶片中。
于一实施例中,该经修正的滤波器参数为主动式降噪的增益补偿的滤波器参数或数字讯号处理电路的增益补偿参数。
于一实施例中,该主动式降噪的该增益补偿的该滤波器参数为音讯增益补偿滤波器单元参数。换言之,该主动式降噪技术的增益补偿单元为该主动式降噪技术的音讯增益补偿滤波器单元,例如SZ或APT 滤波器,而该音讯增益补偿滤波器单元的滤波器参数例如为SZ或APT 滤波器参数。
于一实施例中,本发明还包括:储存模组,其中,若该误差符合误差目标,则该装置将该经修正的滤波器参数储存至该储存模组。
于一实施例中,该装置将原滤波器参数或将该经修正的滤波器参数储存至具有音源处理能力的设备,其中,该设备具有听力补偿模组以进行听力增益补偿。
于一实施例中,该设备中的该听力补偿模组由听觉补偿装置依据使用者于当前真实环境中获得的即时客制化听力图或听力表,通过降噪技术结合最佳化方法及损失函数自动地搜寻多个滤波器的多组参数所产生的最佳滤波器参数值作为该原滤波器参数,但本发明不以此为限。
于一实施例中,本发明还包括:无线传送接收模组,通过该无线传输网络接收来自该装置的第二测试讯号,以进行听力增益补偿。此外,第一测试讯号于空气中传送,而第二测试讯号经由无线通讯传送。
于一实施例中,若该误差仍不符合该误差目标,则该装置对该误差再进行量化以及传送量化后的该误差及听觉动态范围应用优化参数至该补偿增益转换模型,以借由该补偿增益转换模型产生另一修正后滤波器参数后,通过该无线传输网络传送该另一修正后滤波器参数至该听力补偿模组以进行该听力增益补偿。
于一实施例中,该装置还包括:探管或长型耳塞,其一端连接到该第三换能器,其另一端系最短至耳道口而最长至鼓膜附近 (如1mm或更接近)处,其中,该另一端越靠近鼓膜,所获得之高频音讯品质越精准。
于另一实施例中,该探管或该长型耳塞的一端连接到该第三换能器,其另一端系至外耳道第一弯道或至距离鼓膜约数mm(如 5mm)等处,使得获得之高频音讯品质相较于现有技术更精准。
于一实施例中,该具有真耳测量的自调式听觉补偿装置及该具有真耳测量的自调式听觉补偿方法于非听检室的环境下进行听力测试 (audiometry)。
于一实施例中,该具有真耳测量的自调式听觉补偿装置设置于具有主动式降噪或数字讯号处理电路的听力辅助器,而该具有真耳测量的自调式听觉补偿方法应用于该自调式听觉补偿装置,该自调式听觉补偿装置非为在听检室中的听检室专用耳机且无须通过听力专业人员的协助执行;在另一实施例中,该具有真耳测量的自调式听觉补偿方法应用于具有主动式降噪或数字讯号处理电路的听力辅助器。
于一实施例中,该具有真耳测量的自调式听觉补偿装置及该具有真耳测量的自调式听觉补偿方法借由该装置的应用程序结合该补偿增益转换模型及无线通讯技术进行自动化、即时及/或同步处理。
据此,本发明提供了无须真耳分析仪、探管换能器(即,探管麦克风(probemicrophone))、无须限定在专业的听力空间内进行真耳测量分析、并无须通过听力专业人员的协助,以有效地解决上述问题,且可在非听检室内的当前真实环境通过无线通讯技术使用听力辅助器进行真耳测量,并提供精准、即时、自动化且客制化使用者的听力辅助器。
附图说明
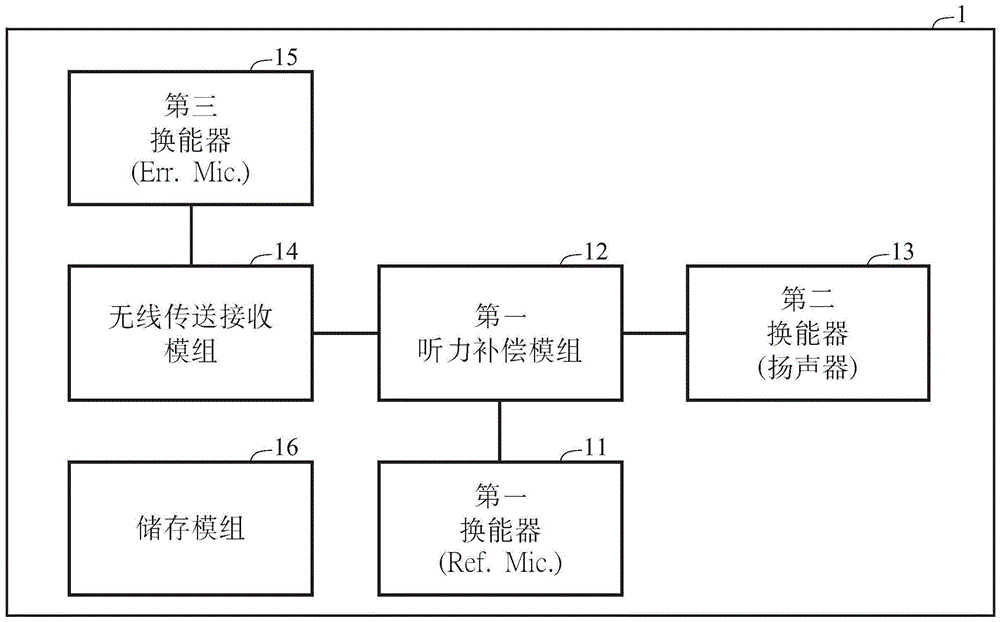
图1为本发明的具有真耳测量的自调式听觉补偿装置的方块示意图。
图2、2-1、2-2为本发明的具有真耳测量的自调式听觉补偿装置结合智能装置的实施例的示意图。
图3为本发明的具有真耳测量的自调式听觉补偿装置的听力补偿模组通过补偿增益转换模型技术以及主动式降噪(active noise cancellation,ANC)技术的步骤流程图。
图4为依据本发明实施例,显示补偿增益转换模型的模型训练 (model training)的示意图。
图5为依据本发明实施例,显示对数功率频谱(log-power spectrum,LPS)撷取方法。
图6为依据本发明实施例,显示补偿增益转换模型的模型训练的方块示意图。
图7A为本发明的应用程序端在接收电性讯号
图7B为本发明的具有真耳测量的自调式听觉补偿装置的目标增益、听力阈值及能量分布的示意图。
图8为本发明的具有真耳测量的自调式听觉补偿方法的步骤流程图。
主要组件符号说明
1 具有真耳测量的自调式听觉补偿装置
11第一换能器
12第一听力补偿模组
13第二换能器
14无线传送接收模组
15第三换能器
16储存模组
10装置
102 第二听力补偿模组
110 设备或装置
120 探管
122 长型耳塞
21窗框
22离散傅立叶转换(DFT)
23|·|
24对数(log(·))
31听力阈值A
32补偿处方
33补偿增益转换模型
34耳机装置
35计算
36判断是否符合误差目标
37听觉动态范围应用优化(
S1-S6 步骤
S11-S17 步骤
S21-S27 步骤。
具体实施方式
以下借由特定的具体实施例说明本发明的实施方式,熟悉此技艺的人士可由本说明书所揭示的内容轻易地了解本发明的其他优点及功效。
须知,本说明书所附图式所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技艺的人士的了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。
图1为本发明的具有真耳测量的自调式听觉补偿装置的方块示意图。依据本发明实施例,如图1所示,本发明的具有真耳测量的自调式听觉补偿装置1包括第一换能器(Ref.Mic)11、第一听力补偿模组 12、第二换能器(即,扬声器)13、无线传送接收模组14、第三换能器 (Err.Mic)15以及储存模组16,其中,第一换能器(Ref.Mic)11接收来自一装置(如智能装置或行动装置)的测试讯号S,且将该测试讯号S 转换成电性讯号;第一听力补偿模组12连接至第一换能器(Ref. Mic)11,且对该电性讯号进行增益补偿;第二换能器13连接至第一听力补偿模组12,并将增益补偿后的电性讯号转换成声音,且将该声音传送至耳道内;无线传送接收模组14连接至第一听力补偿模组12;以及第三换能器(Err.Mic)15同步将耳道内传送的该声音转换成电性讯号
在本发明一实施例中,该第一听力补偿模组12设置在主动式降噪的晶片或数字讯号处理电路的晶片中,而该第二听力补偿模组设置在该装置(如智能装置或行动装置)中,以应用程序、其固件或云端技术方式实现,其中,该第一听力补偿模组12与该第二听力补偿模组同步。
在本发明一实施例中,该组经修正的滤波器参数为主动式降噪的增益补偿的滤波器参数或数字讯号处理电路的增益补偿参数,其中,主动式降噪的增益补偿的滤波器参数为音讯增益补偿滤波器单元(例如SZ或APT滤波器)参数。
依据图1所示,本发明的具有真耳测量的自调式听觉补偿装置1 更包括储存模组16,其中,若上述误差符合误差目标,则该装置利用应用程序、其固件或云端技术将该组经修正的滤波器参数储存至储存模组16。
进一步地,该装置将原滤波器参数及/或将该经修正的滤波器参数储存至具有音源处理能力的设备或装置,其中,该设备或装置具有听力补偿模组以进行听力增益补偿。在一实施例中,该具有音源处理能力的设备或装置可选择原滤波器参数或经修正的滤波器参数透过听力补偿模组进行听力增益补偿来个人化提升聆听感受。
在一实施例中,该具有音源处理能力的设备或装置将该原滤波器参数及/或将该经修正的滤波器参数储存于具有主动式降噪的晶片或数字讯号处理电路的晶片,以进行听力增益补偿。
此外,在本发明一实施例中,若该误差仍不符合误差目标,则该装置利用应用程序、其固件或云端技术对该误差再进行量化,以借由补偿增益转换模型产生另一组修正后滤波器参数后,通过无线传输网络传送另一组修正后滤波器参数至第一听力补偿模组、第二听力补偿模组或其他具有音源处理能力(或听力补偿模组)的设备或装置,以进行听力增益补偿,其中,补偿增益转换模型可设置于云端、服务器或智能装置中,本发明不以此为限。
依据本发明的另一实施例,如图1及图2所示,本发明的具有真耳测量的自调式听觉补偿装置1的无线传送接收模组亦可以通过无线传输网络(未显示于图式中)接收来自一装置(如智能装置或行动装置)10的测试讯号S。类似于上述实施例,若具有真耳测量的自调式听觉补偿装置1的无线传送接收模组通过无线传输网络(未显示于图式中)接收来自该装置10的测试讯号S,则第一听力补偿模组12对该测试讯号S进行增益补偿;第二换能器13连接至第一听力补偿模组12,并将增益补偿后的测试讯号转换成声音,且将该声音传送至耳道内;无线传送接收模组14连接至第一听力补偿模组12;第三换能器(Err. Mic)15同步将耳道内传送的该声音转换成电性讯号,且通过无线传送接收模组14及无线传输网络传送电性讯号至该装置10,其中,该装置 10利用应用程序(app)、其固件或云端技术计算电性讯号在各频带下的能量分布(energy distribution),且通过第二听力补偿模组102比较能量分布与目标增益及听力阈值的误差,若该误差不符合误差目标,则该装置10利用应用程序、其固件或云端技术对该误差进行量化,以借由补偿增益转换模型产生一组经修正的滤波器参数后,通过无线传输网络传送该组经修正的滤波器参数至第一听力补偿模组12、第二听力补偿模组102或其他具有音源处理能力(或听力补偿模组)的设备或装置,以进行听力增益补偿。
在本发明另一实施例中,该第一听力补偿模组12设置在主动式降噪的晶片或数字讯号处理电路的晶片中,而该第二听力补偿模组102 设置在该装置10(如智能装置或行动装置)中,以应用程序、其固件或云端技术方式实现,其中,该第一听力补偿模组12与该第二听力补偿模组102同步。
在本发明一实施例中,该组经修正的滤波器参数为主动式降噪的增益补偿的滤波器参数或数字讯号处理电路的增益补偿参数,其中,主动式降噪的增益补偿的滤波器参数为音讯增益补偿滤波器单元(例如SZ或APT滤波器)参数。
然而,在本发明另一实施例中,若该误差仍不符合误差目标,则该装置利用应用程序、其固件或云端技术对该误差再进行量化,以借由补偿增益转换模型产生另一组修正后滤波器参数后,通过无线传输网络传送另一组修正后滤波器参数至第一听力补偿模组、第二听力补偿模组或其他具有音源处理能力(或听力补偿模组)的设备或装置,以进行听力增益补偿,其中,补偿增益转换模型可设置于云端、服务器或智能装置中,本发明不以此为限。
在本发明的实施例中,本发明的具有真耳测量的自调式听觉补偿装置设置于具有主动式降噪或数字讯号处理电路的听力辅助器。
此外,上述模组均可为硬件或固件;若为硬件,则可分别实现听力增益补偿、无线传送接收以及储存的各种电路或具有相似技术的硬件单元;若为固件,则可分别为执行听力增益补偿、无线传送接收以及储存的各种固件单元。在一实施例中,听力补偿模组可为听力补偿电路或听力补偿硬/固件单元,无线传送接收模组可为无线传送接收电路或无线传送接收硬/固件单元,而储存模组可为储存电路或储存硬/ 固件单元,其中,本发明的自调式听觉补偿装置包含但不限于ANC。
本发明的具有真耳测量的自调式听觉补偿装置设置于听力辅助器,无需使用额外的探管换能器(即,探管麦克风(probe microphone)),以在非听检室内的当前真实环境通过无线通讯技术提供精准、即时、自动化且客制化的听力辅助器。
具体而言,本发明主要通过降噪(例如,ANC)技术结合应用程序技术及补偿增益转换模型技术,在使用者的当前真实环境中,无需使用额外的探管换能器,本发明的具有真耳测量的自调式听觉补偿装置已包括有无线传送接收模组、听力补偿模组、换能器(即,扬声器)、换能器(Err.Mic)、换能器(Ref.Mic)以及储存模组,其中,换能器(Ref. Mic)接收来自一装置的测试讯号S,且将测试讯号S转换成电性讯号;听力补偿模组连接至换能器(Ref.Mic),且对该电性讯号进行增益补偿;换能器连接至听力补偿模组,并将增益补偿后的电性讯号转换成声音,且将该声音传送至耳道内;以及换能器(Err.Mic)同步将耳道内传送的该声音转换成电性讯号
在本发明另一实施例中,如图2-1、2-2所示,本发明的具有真耳测量的自调式耳机装置亦可使用探管120或长型耳塞122,探管或长型耳塞的一端可连接到换能器(Err.Mic),且探管或长型耳塞的另一端最短至耳道口而最长至鼓膜附近 (如1mm或更接近)处,其中,该另一端越靠近鼓膜,所获得之高频音讯品质越精准,以在当前真实环境下透过无线通信技术提供精准、实时、自动化且客制化的耳机装置。
此外,在又一实施例中,该探管或该长型耳塞的一端连接到该第三换能器,其另一端系至外耳道第一弯道或至距离鼓膜约数mm(如5mm)等处,使得获得之高频音讯品质相较于现有技术更精准。
要说明的是,图2-1、2-2为示意说明,不以此为限。
图3为本发明的具有真耳测量的自调式听觉补偿装置的听力补偿模组通过补偿增益转换模型技术以及主动式降噪(active noise cancellation,ANC)技术的步骤流程图。
首先,在步骤S1,应用程序(app)端通过智能装置的扬声器(或通过无线传输网络)将测试讯号S传送出去,随后通过ANC耳机的换能器 (Ref.Mic)(或无线传送接收模组)接收该测试讯号S。
接着,在步骤S2,ANC耳机的滤波器电路(或数字讯号处理(digital signalprocessing,DSP)电路)通过听力补偿模组进行听力增益补偿,且由ANC耳机中的换能器(即,扬声器)进行播音。
之后,在步骤S3,ANC耳机端同步由换能器(Err.Mic)将耳道内的声音讯号转换成电性讯号
在步骤S4,应用程序端将同步考量经计算后的电性讯号
在步骤S5,补偿增益转换模型会自动地产生经修正的滤波器参数。
最后,在步骤S6,若误差不符合误差目标,则应用程序端自动地对该误差进行量化,以借由补偿增益转换模型产生经修正的滤波器参数后,通过无线传输网络传送该经修正的滤波器参数至听力补偿模组以再一次进行听力增益补偿;若该误差符合误差目标,则应用程序将该经修正的滤波器参数自动地储存至ANC耳机中的储存模组及/或该智能装置中。进一步地,在另一实施例中,应用程序同步将原滤波器参数或将该经修正的滤波器参数自动地储存至具有音源处理能力的设备或装置(如图2所示的110,例如智能装置、行动装置、喇叭或音箱),其中,该设备或装置具有听力补偿模组以进行听力增益补偿。
值得一提的是,若上述误差仍不符合误差目标,则应用程序对该误差再进行量化,以借由补偿增益转换模型产生另一组修正后滤波器参数后,通过无线传输网络传送另一组修正后滤波器参数至听力补偿模组以进行另一次听力增益补偿。
在本发明一实施例中,图4显示补偿增益转换模型的模型训练的示意图。依据电性讯号
以下分别对于电性讯号
电性讯号
图5显示对数功率频谱(log-power spectrum,LPS)撷取方法。于本发明的实施例中,换能器(Err.Mic)将所接收到的电性讯号
其中,Y
其中,Y
此时,再将n个重叠窗框下的对数功率频谱进行累加,以获取电性讯号
通过补偿增益转换模型架构进行补偿增益参数
图6显示补偿增益转换模型的模型训练的方块示意图。当使用者经听力筛检得到的听力阈值A
其中,N表示模型会生成多组(获得N组)滤波器参数,M表示训练模型的样本数,i代表训练中的第几笔增益资料。
当补偿增益转换模型进行模型训练时,将误差反向传播来进行模型参数更新,且进行参数权重调整,从而寻找最佳补偿增益,如公式 (4)所示:
接着,通过ANC装置的换能器将耳道中的电性讯号
值得一提的是,DSP电路也可通过上述的流程,进行电性讯号
图7A为本发明的应用程序端在接收电性讯号
如图7A所示,在步骤S11,ANC耳机端通过换能器(Err.Mic)将电性讯号
接着,在步骤S12,应用程序端接收电性讯号
之后,在步骤S13,取n个音框,对各音框进行傅立叶转换(Fourier transform),且累积n个音框下的能量来获得电性讯号
在步骤S14,计算且比较当前电性讯号
在步骤S15,调整在各频带下的增益量。
在步骤S16,通过模型训练后的补偿增益转换模型产生修正后的 ANC滤波器参数(或DSP电路的增益补偿参数)。
最后,在步骤S17,若上述误差符合误差目标,则将ANC滤波器参数写入ANC耳机的晶片中(即,储存至ANC耳机的储存模组中)及/或该智能装置中;或者,将DSP电路的增益补偿参数写入具有DSP电路的耳机的晶片中。
值得一提的是,本发明的具有真耳测量的自调式听觉补偿装置采用主动式降噪(active noise cancellation,ANC)技术,但在不同实施例中,具有相同或相似降噪技术均可适用,本发明不以此为限。在此实施例中,滤波器(例如,FF,FB、SZ、APT…等)参数可以通过「机构声学特性」及「听觉补偿处方」的资讯进行设定,也就是,将通过均平方误差(mean-square error,MSE)方法进行ANC技术中的滤波器参数设定,进而使ANC技术对换能器所传送的声源进行不同频率的增益补偿能力。在一实施例中,上述滤波器可分别为前馈(FF)滤波器、反馈(FB)滤波器、音讯增益补偿滤波器单元(例如SZ滤波器、APT滤波器),其中,前馈(FF)滤波器可接收换能器(Ref.Mic)的电性讯号,以消除外部噪音;反馈(FB)滤波器可接收换能器(Err.Mic)的电性讯号 (即,换能器(Err.Mic)将耳道内噪音转换成电性讯号),以消除耳道内噪音;而音讯增益补偿滤波器单元(例如SZ滤波器及APT滤波器)则接收适当的目标曲线(target curve),以放大电性讯号中各频带的讯号。此外,在DSP电路中,即可以调处理架构中的时域(或频域)增益放大单元,例如EQ,滤波器、宽广动态范围压缩(widedynamic range compression)、自适性动态范围最佳化(adaptive dynamic rangeoptimization)等。
由于本发明适用于各种智能设备,以使自调式听觉补偿装置可于非听检室(例如,居住房舍、室外、车内、公园等)的环境且无须通过听力专业人员的协助下进行听力测试(audiometry),也就是说,本发明的自调式听觉补偿装置不必限定在听检室内结合真耳测量仪器进行听力测试及真耳测量分析,以在非听检室内的当前真实环境提供自动化、即时、客制化使用者的助听器、听觉辅具或具有助听功能的设备。
在一实施例中,本发明的具有真耳测量的听觉补偿装置设置于听力辅助器,例如,耳机(包括但不限于动圈式、动铁式、压电式、气动式、静电式、有线传输、无线传输的耳机)、助听器、抗噪耳机、监听耳机、智慧眼镜、穿戴式装置或其组合。在另一实施例中,本发明的具有真耳测量的听力辅助器亦为听力设备,具有上述的听觉补偿装置,其中,听觉补偿装置设置并连接于听力设备。
此外,本发明的具有真耳测量的自调式听觉补偿装置借由智能装置的应用程序(app)结合补偿增益转换模型技术以及无线通讯技术(例如,蓝牙(Bluetooth)、Wi-Fi、近场通讯(near-field communication, NFC)、超宽带(ultra-wideband,UWB)、IEEE 802.15.4等无线通讯技术),直接将使用者(特别是听损者)的即时客制化的听力图或听力表同步于设置在相同或单一晶片中的降噪模组及/或听力补偿模组进行运作,进而提供使用者(特别是听障患者)能即时地具有舒适聆听感受。另外,依据本发明的上述实施例,由于听损者使用自身的听觉设备或装置(例如,各种智能设备或装置配合ANC耳机或TWS耳机)能在各种当前真实环境或真实应用环境(即,安静或带噪环境)而非在听检室进行听力测试,因而听损者可依据自身需求,在进行本发明的自调式听觉补偿时选择开启或关闭降噪模组。
值得注意的是,本发明的具有真耳测量的自调式听觉补偿装置除了不必限定在听检室内进行听力测试及/或听力增益补偿且无须通过听力专业人员的协助之外,本发明也无需使用额外的探管换能器,仅通过自身的装置(例如,助听器、听觉辅具、耳机等)且借由智能装置结合补偿增益转换模型技术及无线通讯技术,便可自动地、即时且客制化听障患者的助听器、听觉辅具或具有助听功能的耳机等听力设备。
图8为本发明的具有真耳测量的自调式听觉补偿方法的步骤流程图,一并配合上述实施例的说明,其中,该方法流程至少包含下列步骤S21至S27。
于步骤S21中,借由第一换能器,接收来自一装置(如智能装置或行动装置)的第一测试讯号,且将该第一测试讯号转换成第一电性讯号。
于步骤S22中,借由连接至该第一换能器的第一听力补偿模组,对该第一电性讯号进行增益补偿。
于步骤S23中,借由连接至该第一听力补偿模组的第二换能器,将增益补偿后的该第一电性讯号转换成声音,且将该声音传送至耳道内。
于步骤S24中,借由第三换能器同步将耳道内传送的该声音转换成第二电性讯号,以通过无线传送接收模组及无线传输网络传送该第二电性讯号至该装置。
于步骤S25中,该装置利用应用程序、其固件或云端技术计算该第二电性讯号在各频带下的能量分布,且通过第二听力补偿模组比较该能量分布与目标增益及听力阈值的误差。
于步骤S26中,若该误差不符合误差目标,则该装置利用应用程序、其固件或云端技术对该误差进行量化,以借由补偿增益转换模型产生一组经修正的滤波器参数后,通过该无线传输网络传送该组经修正的滤波器参数至该第一听力补偿模组、该第二听力补偿模组,以进行听力增益补偿。
于步骤S27中,若该误差符合误差目标,则该装置利用应用程序、其固件或云端技术将该组经修正的滤波器参数储存至储存模组。
在另一实施例中,除了将该组经修正的滤波器参数储存至储存模组之外,该装置也可利用应用程序、其固件或云端技术将原滤波器参数或将该经修正的滤波器参数储存至具有音源处理能力的设备或装置,其中,该设备或装置具有听力补偿模组以进行听力增益补偿。
另外,除了第一换能器可接收来自一装置(如智能装置或行动装置)的第一测试讯号之外,无线传送接收模组亦可通过无线传输网络接收来自该装置的第二测试讯号,以进行如上述的听力增益补偿。此外,第一测试讯号于空气中传送,而第二测试讯号经由无线通讯传送。
在上述的方法流程中,若该误差仍不符合该误差目标,则该装置利用应用程序、其固件或云端技术对该误差再进行量化以及传送量化后的该误差及该听觉动态范围应用优化参数至该补偿增益转换模型,以借由该补偿增益转换模型产生另一组修正后滤波器参数后,通过该无线传输网络传送该另一组修正后滤波器参数至该第一听力补偿模组、该第二听力补偿模组,以进行该听力增益补偿。
在上述的方法流程中,该第一听力补偿模组设置在主动式降噪的晶片或数字讯号处理电路的晶片中,而该第二听力补偿模组设置在该装置(如智能装置或行动装置)中,以应用程序、其固件或云端技术方式实现,其中,该第一听力补偿模组与该第二听力补偿模组同步。
在一实施例中,该组经修正的滤波器参数为主动式降噪的增益补偿的滤波器参数或数字讯号处理电路的增益补偿参数,其中,主动式降噪的增益补偿的滤波器参数为音讯增益补偿滤波器单元(例如SZ或 APT滤波器)参数。
此外,上述的方法流程应用于自调式听觉补偿装置,亦可应用于具有主动式降噪或数字讯号处理电路的听力辅助器。
值得注意的是,若上述误差仍不符合该误差目标,则该装置利用应用程序、其固件或云端技术对该误差再进行量化,以借由该补偿增益转换模型产生另一组修正后滤波器参数后,通过该无线传输网络传送该另一组修正后滤波器参数至该听力补偿模组以进行另一次听力增益补偿。
综上所述,本发明的具有真耳测量的自调式听觉补偿装置及具有真耳测量的自调式听觉补偿方法通过主动式降噪(ANC)技术结合数字网络技术及无线传输技术,不仅能使耳机能发出与当前噪音能量相同的反向波(或正向波)来消除耳道中的环境噪音,并且在进行真耳测量 (REM)时也可以借由听力补偿模组直接对使用者(特别是听障患者)即时客制化的听力图或听力表进行听力增益补偿(进而使各频带的讯号(如正向讯号及/或反向讯号)放大),具有自动化、即时且客制化听障患者的助听器、听觉辅具或具有助听功能的耳机的功效。
另外,本发明的具有真耳测量的自调式听觉补偿装置及具有真耳测量的自调式听觉补偿方法通过补偿增益转换模型技术考量听损者的听损特性,以提供听损者代表性测试语句,进而执行真耳测量,且达到自动化、即时且客制化听损者的助听器、听觉辅具或具有助听功能的耳机的功效。
此外,在本发明的实施例中,补偿增益转换模型亦可自动化修正自调式听觉补偿装置的补偿参数(例如,SII(speech intelligibility index),HASQI,HASPI等补偿参数),其中,补偿增益转换模型可设置于云端、服务器或智能装置中,本发明不以此为限。
最后,在本发明的实施例中,一电脑程序产品利用所述装置的应用程序、其固件或云端技术执行上述内容,并可将原滤波器参数或将该经修正的滤波器参数自动地储存至具有音源处理能力的设备或装置 (如图2所示的110,例如智能装置、行动装置、喇叭或音箱),其中,该设备或装置具有听力补偿模组以进行听力增益补偿。因此,该电脑程序产品可选择将经修正的滤波器参数同步至该自调式听觉补偿装置或将原滤波器参数/将该经修正的滤波器参数同步至该具有音源处理能力的设备或装置以进行音源处理与播放。
上述实施形态仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟习此项技艺的人士均可在不违背本发明的精神及范畴下,对上述实施形态进行修饰与改变。因此,本发明的权利保护范围应如权利要求书所列。
- 磁场补偿方法,相关装置及计算机程序
- 一种物品推荐方法、装置、存储介质及程序产品
- 图像处理方法和装置、电子设备、存储介质、程序产品
- 用于定位和移除拖车联轴器的方法、用于定位拖车联轴器的装置以及计算机程序产品
- 一种分类模型优化方法、装置及存储设备、程序产品
- 听觉训练装置、听觉训练方法及程序
- 确定补偿流量和/或补偿流动速度的方法、超声流量测量装置和计算机程序产品