一种麦克风阵列模块及包含其的声学成像装置
文献发布时间:2024-04-18 19:59:31
技术领域
本发明属于声学成像技术领域,更具体地,涉及一种麦克风阵列模块及包含其的声学成像装置。
背景技术
现有的手持式声学成像仪主要包括麦克风阵列模块、信号处理模块和图像显示模块。其中,麦克风阵列模块用于采集目标空间内声源发出的声波信号,并将采集到的声波信号转换为电信号进行输出;信号处理模块用于对麦克风阵列模块输出的电信号进行预处理,基于预处理后的电信号并采用波束成形算法获取目标空间对应的空间声场分布云图像;图像显示模块用于显示信号处理模块获取的空间声场分布云图像。
现有手持式声学成像仪所采用的麦克风阵列模块按照通道数划分主要包括7种,分别为64通道、96通道、112通道、124通道、128通道、144通道和162通道。其中,64通道的麦克风阵列模块因在体积、灵敏度、功耗、测量频率范围和成本方面上的综合优势而最具有性价比,进而得到了越来越广泛的应用。
然而,由于麦克风阵列模块的灵敏度与其通道数呈正相关,64通道的麦克风阵列模块的灵敏度明显低于其他通道数的麦克风阵列模块,采用64通道的麦克风阵列模块的声学成像仪在实验室环境下能够稳定成像的最小声源强度高达9.5dB至15dB,这使得现有采用64通道麦克风阵列模块的手持式声学成像仪无法适用于对声源检测灵敏高要求较高的场景。
为此,有必要提出一种优化的麦克风阵列模块,使其在体积、功耗、测量频率范围和成本方面上的综合优势相较于64通道的麦克风阵列模块略微下降的情况下,在灵敏度方面具有较为明显的提升。
发明内容
本发明的目的在于解决现有64通道的麦克风阵列模块虽然相较于其他通道数的麦克风阵列模块在体积、功耗、测量频率范围和成本方面具有综合优势,但是具有灵敏度低这一明显短板的问题。
为了实现上述目的,本发明提供一种麦克风阵列模块及包含其的声学成像装置。
根据本发明的第一方面,提供一种麦克风阵列模块,该麦克风阵列模块包括基板以及形成于所述基板上的麦克风阵列;
所述麦克风阵列包括:
螺旋形的麦克风面阵列,包括六十四个主麦克风;
多对辅麦克风,沿所述麦克风面阵列的外周间隔分布,所述辅麦克风的对数为四对、六对、八对、十对、十二对或者十四对;
作为可选的是,所述基板为平面基板。
作为可选的是,所述六十四个主麦克风划分为十三组,其中的一组包括四个主麦克风,其余的各组均包括五个主麦克风;
每组中的各个主麦克风间隔排布并构成弧形的麦克风线阵列;
各个麦克风线阵列在整体上呈放射状地分布于所述基板的中心点的周围,各个麦克风线阵列的开口侧依次沿顺时针方向或者逆时针方向分布。
作为可选的是,所述辅麦克风的对数为四对,该四对辅麦克风分别设置在所述麦克风面阵列的最小外接矩形框的四个顶点处,每对辅麦克风中的两个辅麦克风间隔设置。
作为可选的是,所述主麦克风和所述辅麦克风均为MEMS麦克风。
根据本发明的第二方面,提供一种声学成像装置,该声学成像装置包括上述任一种麦克风阵列模块以及信号处理模块;
所述信号处理模块用于:
对所述多个主麦克风和所述多对辅麦克风输出的电信号进行预处理,所述电信号转换自目标空间内声源发出的声波信号,
基于预处理后的多个主麦克风输出的电信号,采用波束成形算法获取所述目标空间内的声源检测结果,并获取相应的空间声场分布云图像,
基于预处理后的多对辅麦克风输出的电信号,采用声达时间差算法获取所述目标空间内的声源检测结果,
判断所述空间声场分布云图像上是否存在成像不连续的目标声源,若存在,则根据采用声达时间差算法获取的声源检测结果对目标声源进行二次判定,包括:
根据采用声达时间差算法获取的声源检测结果判断目标声源是否为所述目标空间内的最大声源,若是,则将目标声源每次成像的时间进行延长。
作为可选的是,所述二次判定还包括:
若判断出目标声源不是所述目标空间内的最大声源,则判断采用波束成形算法是否检测出包括目标声源在内的至少两个声源且其中存在最大声源,若判断结果为是,则不对目标声源每次成像的时间进行调整,若判断结果为否,则将目标声源每次成像的时间进行缩短。
作为可选的是,所述声学成像装置还包括图像采集模块和图像显示模块;
所述图像采集模块用于采集所述目标空间对应的环境图像;
所述信号处理模块还用于将所述空间声场分布云图像叠加于所述环境图像之上,得到空间声场分布实景图像;
所述图像显示模块用于响应于所述信号处理模块输出的图像数据显示所述环境图像、所述空间声场分布云图像或者所述空间声场分布实景图像。
作为可选的是,所述声学成像装置还包括:
补光灯模块,用于在所述图像采集模块采集所述环境图像时进行补光。
作为可选的是,所述麦克风阵列形成于所述基板的第一面上,所述图像采集模块设置在所述基板的第一面的中心点处,所述信号处理模块设置在所述基板的第二面上;
所述声学成像装置还包括第一壳体、第二壳体和电池模块;
所述第一壳体和所述第二壳体被配置为能够互合设置;
所述基板固定设置在所述第一壳体内,在所述第一壳体的与所述基板相对的部分上设置有与所述麦克风阵列相匹配的进音孔阵列以及与所述图像采集模块相匹配的进光孔,所述补光灯模块嵌设在所述第一壳体上;
所述图像显示模块嵌设在所述第二壳体上;
所述电池模块设置在所述第一壳体内,用于通过所述信号处理模块同时为各个主麦克风、各个辅麦克风、图像采集模块、图像显示模块和补光灯模块供电。
本发明的有益效果在于:
本发明的麦克风阵列模块,包括基板以及形成于基板上的麦克风阵列。其中,麦克风阵列包括由六十四个主麦克风构成的螺旋形的麦克风面阵列,以及沿麦克风面阵列的外周间隔分布的多对辅麦克风,辅麦克风的对数优选为四对。
本发明的声学成像装置,包括与上述麦克风阵列模块配合工作的信号处理模块。其中,信号处理模块采用融合算法对上述麦克风阵列模块输出的对应于目标空间内声源发出的声波信号的电信号进行处理,以得到最终用于显示的空间声场分布云图像。具体地,在对上述麦克风阵列模块输出的电信号进行预处理之后,采用波束成形算法对预处理后的多个主麦克风输出的电信号进行进一步的处理以得到初步的空间声场分布云图像,同时采用声达时间差算法对预处理后的多对辅麦克风输出的电信号进行进一步的处理以得到用于二次判定的声源检测结果;当初步的空间声场分布云图像上存在成像不连续的目标声源时,根据采用声达时间差算法获取的声源检测结果判断目标声源是否为目标空间内的最大声源,若是,则将目标声源每次成像的时间进行延长,以使其持续成像或者接近持续成像,即通过延长目标声源每次成像的时间的方式来改善其在空间声场分布云图像上的忽隐忽现的不稳定显示情况。
一方面,本发明中,麦克风阵列模块在现有64通道麦克风阵列模块的基础上增设了多对辅麦克风,以提升自身的灵敏度。其中,增设的辅麦克风的对数最多为14对,即本发明的麦克风阵列模块的最大通道数为94通道,小于现有96通道的麦克风阵列模块的通道数;与此同时,本发明中增设的多对辅麦克风沿麦克风面阵列的外周分布,如此设置,能够在增加麦克风阵列模块的麦克风通道数的同时尽可能地降低麦克风阵列模块的体积因麦克风通道数的增加而增大的程度。另一方面,本发明中,信号处理模块采用基于波束成形算法与声达时间差算法的融合算法实现了空间声场分布云图像的获取以及空间声场分布云图像上成像不连续的最大声源的成像优化,进而实现了对强度处于一定范围内的小声源的稳定成像,从而提高了声源检测的灵敏度。
根据以上两方面可知,在结合使用上述信号处理模块的前提下,通过合理设置上述麦克风阵列模块中辅麦克风的增设数量,能够使得上述麦克风阵列模块在体积、功耗、测量频率范围和成本上的综合优势相较于64通道的麦克风阵列模块略微下降的情况下,在灵敏度方面得到较为明显的提升,进而达到整体层面上的利大于弊的积极效果,从而在一定程度上改善现有64通道的麦克风阵列模块虽然相较于其他通道数的麦克风阵列模块在体积、功耗、测量频率范围和成本方面具有综合优势,但是具有灵敏度低这一明显短板的问题。
本发明的其他特征和优点将在随后具体实施方式部分予以详细说明。
附图说明
本发明可以通过参考下文中结合附图所做出的描述而得到更好的理解,其中在所有附图中使用了相同或相似的附图标记来表示相同或者相似的部件。
图1示出了根据本发明的实施例的麦克风阵列在基板上的分布示意图;
图2示出了根据本发明的实施例的声学成像装置的结构框图;
图3示出了根据本发明的实施例的声学成像装置的爆炸图。
具体实施方式
为了使所属技术领域的技术人员能够更充分地理解本发明的技术方案,在下文中将结合附图对本发明的示例性的实施方式进行更为全面且详细的描述。显然地,以下描述的本发明的一个或者多个实施方式仅仅是能够实现本发明的技术方案的具体方式中的一种或者多种,并非穷举。应当理解的是,可以采用属于一个总的发明构思的其他方式来实现本发明的技术方案,而不应当被示例性描述的实施方式所限制。基于本发明的一个或多个实施方式,本领域的普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施方式,都应当属于本发明保护的范围。
实施例:对于现有的手持式声学成像仪,其麦克风阵列模块所采用的麦克风阵列大多为由多个MEMS麦克风构成的小型化平面式阵列,按照麦克风通道数划分主要包括7种,分别为64通道、96通道、112通道、124通道、128通道、144通道和162通道。
而对于麦克风通道数的选择,即麦克风阵列中麦克风数量的选择,主要基于如下几个因素:
算法适应性:声源捕捉准确,无鬼影,无漏检;
体积:手持式应用场景,体积越小越好;
成本:低成本为优;
性能:功耗小为优、定位灵敏度高为优、测量频率范围宽为优。
以下就上述各个通道数的麦克风阵列模块在算法适应性、体积、成本和性能方面上的单项表现进行排序:
在算法适应性方面,上述各个通道数的麦克风阵列模块基本上做到了声源捕捉准确、无鬼影以及无漏检,故此项排名不分先后。
在体积方面,排名顺序为64通道<96通道<112通道≈124通道≈128通道<144通道<162通道,麦克风阵列模块的通道数越多,为了使算法适应性好,体积就越大,否则增加的通道数不仅起不到作用,而且可能起反作用。
定位灵敏度方面:采用64通道麦克风阵列模块的手持式声学成像仪在实验室环境下能够稳定成像的最小声源强度为9.5dB~15dB左右,采用112通道麦克风阵列模块的手持式声学成像仪在实验室环境下能够稳定成像的最小声源强度为6.4dB左右,采用124通道和128通道的麦克风阵列模块的手持式声学成像仪在实验室环境下能够稳定成像的最小声源强度为5.5dB左右,采用144通道麦克风阵列模块的手持式声学成像仪在实验室环境下能够稳定成像的最小声源强度为5.2dB。由此可见,当通道数达到一定程度时,已经很难通过增加通道数的方式来提升定位灵敏度了。此项排名为:64通道<96通道(猜测)≈112通道<124通道≈128通道≈144通道≈162通道。
功耗方面:MEMS麦克风的功耗都很接近,因此通道数越多,功耗越大。此项排名为:64通道<96通道<112通道<124通道≈128通道<144通道<162通道。
测量频率范围方面:实际上,对于麦克风阵列模块,通道数对测量频率的影响不大,主要是麦克风阵列的尺寸对测量频率的影响较大;通常来说,声波波长与麦克风阵列直径的比值(λ/D)会影响麦克风阵列的方向解析度,λ/D越小,方向解析度就越高,麦克风阵列就能够在更窄的方向范围内区分不同的声源,也就是说若要更好地检测低频的声源,麦克风阵列的直径就要做得越大。而对于手持式声学成像仪而言,麦克风阵列的直径很难做到成倍的差异,仅仅通过增加或减少通道数,或者稍微增大麦克风阵列的直径,对测量频率的影响不大,现有的手持式声学成像仪一般能检测的频率最低为2kHz,不同通道数的设备之间的差距不大,若要测量更高频率的声源,如超过40kHz的声源,提升采集卡的电子采样频率即可;故此项排名不分先后。
成本方面,通道数的数量基本上决定了硬件成本高低,因此此项排名为:64通道<96通道<112通道<124通道≈128通道<144通道<162通道。
基于上述各个通道数的麦克风阵列模块在算法适应性、体积、成本和性能方面的单项排名确定综合得分,详见表1,其中,单项排名最优得1分,次之得2分,以此类推:
表1各个通道数的麦克风阵列模块的综合得分表
根据表1可知,麦克风阵列模块的通道数越多,其总得分越多,综合排名越靠后;在同等技术能力的前提下,在上述各个通道数的麦克风阵列模块中,64通道麦克风阵列模块是最具有性价比的。然而,64通道麦克风阵列模块也具有明显的缺点,即灵敏度相对较差,在很多对灵敏度要求较高的场景,其表现较差。如果在能够明显提升麦克风阵列模块的灵敏度同时,使其仍然相对具有体积、成本、功耗、测量频率范围上的优势,那么无疑将能够大幅度地提升现有麦克风阵列模块的性价比。
为此,本发明实施例提出一种麦克风阵列模块及包含其的声学成像装置。
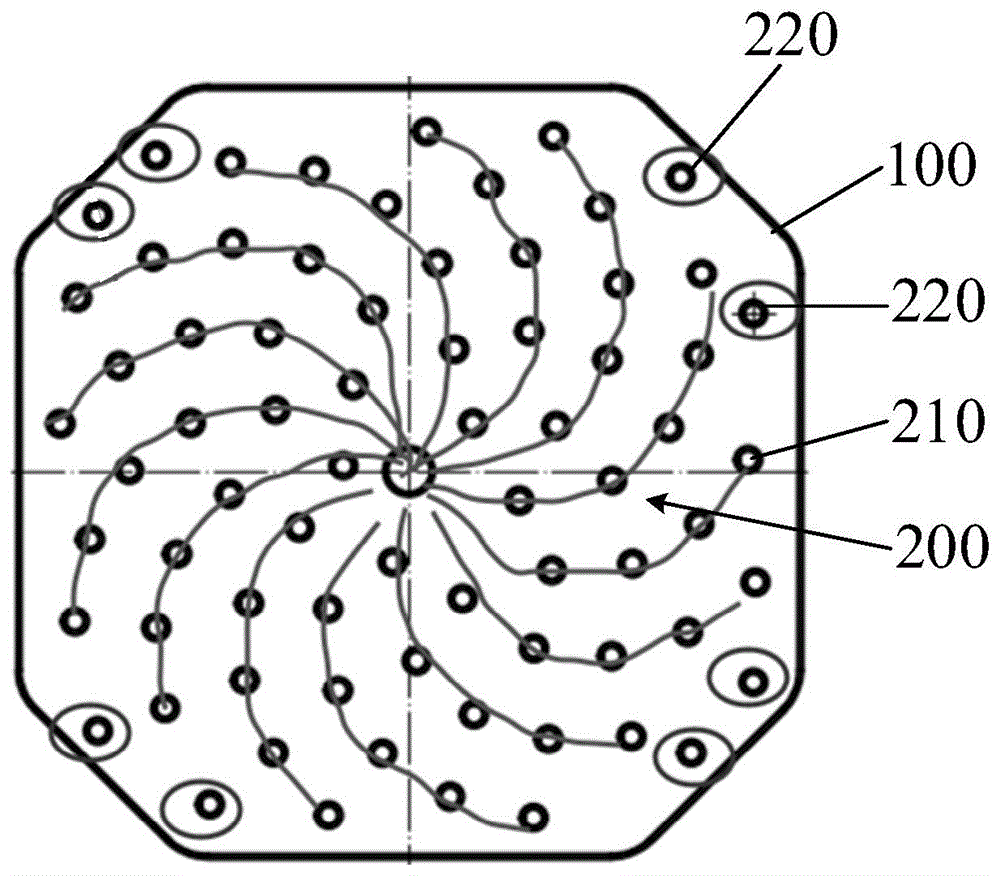
图1示出了本发明实施例的麦克风阵列在基板上的分布示意图。参照图1,本发明实施例的麦克风阵列模块包括基板100以及形成于基板100上的麦克风阵列200;
麦克风阵列200包括:
螺旋形的麦克风面阵列,包括多个主麦克风210;
多对辅麦克风220,沿麦克风面阵列的外周间隔分布。
进一步地,本发明实施例中,基板100为平面基板。
再进一步地,本发明实施例中,麦克风面阵列包括六十四个主麦克风210;
六十四个主麦克风210划分为十三组,其中的一组包括四个主麦克风210,其余的各组均包括五个主麦克风210;
每组中的各个主麦克风210间隔排布并构成弧形的麦克风线阵列;
各个麦克风线阵列在整体上呈放射状地分布于基板100的中心点的周围,各个麦克风线阵列的开口侧依次沿顺时针方向或者逆时针方向分布。
具体地,本发明实施例中,一麦克风线阵列的开口侧为该麦克风线阵列对应的弧形的开口一侧。
再进一步地,本发明实施例中,辅麦克风220的对数为四对;
四对辅麦克风220分别设置在麦克风面阵列的最小外接矩形框的四个顶点处,每对辅麦克风220中的两个辅麦克风220间隔设置。
再进一步地,本发明实施例中,主麦克风210和辅麦克风220均为MEMS麦克风。
具体地,本发明实施例中,麦克风面阵列采用现有螺旋形的64通道麦克风阵列,而增设的四对辅麦克风220分别设置在麦克风面阵列的最小外接矩形框的四个顶点处,如此设置,不仅能够在相应程度上提升麦克风阵列模块的灵敏度,而且能够在增加麦克风阵列模块的通道数的同时尽可能地降低麦克风阵列模块的体积随通道数增加而增大的幅度,实际上,由于在增加了四对辅麦克风220之后,麦克风面阵列的面积基本不变,麦克风阵列模块的体积也基本不变,相应地,手持式声学成像仪的体积也基本保持不变。与此同时,由于仅增加了八个辅麦克风,使得本发明实施例的麦克风阵列模块相对于现有64通道的麦克风阵列模块,在成本和功耗上的优势的下降程度是非常微小的。
具体地,本发明实施例中,增设的辅麦克风对的插入规则是插入之后方便后续的声达时间差算法的计算,增设的四个辅麦克风对分布于麦克风面阵列的四个对角处。由于采用的是声达时间差算法,在麦克风面阵列的最小外接矩形框的对角线上的两个辅麦克风对不需要完全对称,主要从结构上方便布置的角度出发来确定位置。
相应地,在本发明实施例提出的麦克风阵列模块的基础上,本发明实施例还提出了一种声学成像装置。
图2示出了本发明实施例的声学成像装置的结构框图,图3示出了本发明实施例的声学成像装置的爆炸图。参照图2和图3,本发明实施例的声学成像装置包括上述麦克风阵列模块和信号处理模块300;
信号处理模块300用于:
对多个主麦克风210和多对辅麦克风220输出的电信号进行预处理,其中,所述电信号转换自目标空间内声源发出的声波信号,
基于预处理后的多个主麦克风210输出的电信号,采用波束成形算法获取目标空间内的声源检测结果,并获取相应的空间声场分布云图像,
基于预处理后的多对辅麦克风220输出的电信号,采用声达时间差算法获取目标空间内的声源检测结果,
判断空间声场分布云图像上是否存在成像不连续的目标声源,若存在,则根据采用声达时间差算法获取的声源检测结果对目标声源进行二次判定,包括:
根据采用声达时间差算法获取的声源检测结果判断目标声源是否为目标空间内的最大声源,若是,则将目标声源每次成像的时间进行延长。
进一步地,本发明实施例中,根据采用声达时间差算法获取的声源检测结果对目标声源进行二次判定,还包括:
若判断出目标声源不是目标空间内的最大声源,则判断采用波束成形算法是否检测出包括目标声源在内的至少两个声源且其中存在最大声源,若判断结果为是,则不对目标声源每次成像的时间进行调整,若判断结果为否,则将目标声源每次成像的时间进行缩短。
具体地,本发明实施例中,目标空间内的声源检测结果包括声源中心点的位置和强度,其中,声源中心点的位置采用空间坐标表示,声源中心点的强度采用声压级表示。
具体地,本发明实施例的声学成像装置为手持式声学成像装置。
具体地,本发明实施例中,若空间声场分布云图像上不存在成像不连续的声源,则将相应的空间声场分布云图像直接作为最终用于显示的空间声场分布云图像,此时采用声达时间差算法所获取的目标空间内的声源检测结果仅作为冗余参考。
进一步地,本发明实施例的声学成像装置还包括图像采集模块400和图像显示模块500;
图像采集模块400用于采集目标空间对应的环境图像;
信号处理模块300还用于将空间声场分布云图像叠加于环境图像之上,得到空间声场分布实景图像;
图像显示模块500,用于响应于信号处理模块300输出的图像数据显示环境图像、空间声场分布云图像或者空间声场分布实景图像。
再进一步地,本发明实施例的声学成像装置还包括:
补光灯模块600,用于在图像采集模块400采集环境图像时进行补光。
再进一步地,本发明实施例中,麦克风阵列200形成于基板100的第一面上,图像采集模块400设置在基板100的第一面的中心点处,信号处理模块300设置在基板100的第二面上;
本发明实施例的声学成像装置还包括第一壳体700、第二壳体800、电池模块900和数据接口模块1000;
第一壳体700和第二壳体800被配置为能够互合设置;
基板100固定设置在第一壳体700内,在第一壳体700的与基板100相对的部分上设置有与麦克风阵列200相匹配的进音孔阵列以及与图像采集模块400相匹配的进光孔,补光灯模块600嵌设在第一壳体700上;
图像显示模块500嵌设在第二壳体800上;
数据接口模块1000设置在第一壳体700内,且其上的数据接口的前端贯穿于第一壳体700并与之侧板平齐,数据接口模块1000的数据接口包括Type-C接口、USB接口和Micro接口;
电池模块900设置在第一壳体700内,用于通过信号处理模块300同时为各个主麦克风210、各个辅麦克风220、图像采集模块400、图像显示模块500、补光灯模块600和数据接口模块1000供电。
以下对本发明实施例提出的麦克风阵列模块及包含其的声学成像装置进行更为详细的描述:
虽然现有螺旋形的麦克风阵列具有诸多优点,但其公认的最大缺点是声音反射(回声)处理能力较差,容易导致误判,即误将回声点作为声源;为了减少这种误判,通常会在信号处理算法中加入降噪处理的环节,然而这将导致检测出的声源强度与实际的声源强度之间存在差异;例如某64通道的手持式声学成像仪显示某个声源的声压级为15dB时,用一些无降噪的检测手段可以测到其实际声压级在20dB以上。
基于现有螺旋形的麦克风阵列容易误判的问题,本发明实施例的麦克风阵列模块所采用的麦克风阵列在现有螺旋形的64通道麦克风阵列的基础上增加了四对辅麦克风,形成类螺旋形的72导通麦克风阵列。
本发明实施例中,对于螺旋形的麦克风面阵列,即相当于现有螺旋形的64通道麦克风阵列,采用波束成形算法,对于增设的四对辅麦克风,采用声达时间差算法,并在必要时采用声达时间差算法的声源检测结果对波束成形算法的声源检测结果进行二次判定。具体地,当目标声源强度比较大时,波束成形算法能够对目标声源进行准确的检测及稳定的成像,目标声源在空间声场分布云图像上能够持续成像,此时无需对波束成形算法的声源检测结果进行二次判定,仅将声达时间差算法的声源检测结果作为参考;当目标声源强度比较小时,波束成形算法无法对目标声源进行准确的检测及稳定的成像,目标声源在空间声场分布云图像上无法持续成像,此时启动二次判定:若目标声源为目标空间内的最大声源,则给目标声源的每次成像的时间施加一个正向加权,使目标声源每次成像的时间延长,即将目标声源在空间声场分布云图像上每次显示的时间进行延长,以使其稳定显示,不再忽隐忽现;若目标声源不是目标空间内的最大声源,则判断采用波束成形算法是否检测出包括目标声源在内的至少两个声源且其中存在最大声源,若判断结果为是,则不对目标声源每次成像的时间进行调整;若判断结果为否,则说明空间声场分布云图像上的目标声源可能为不是真实声源,而是回声点,
此时给目标声源的每次成像的时间施加一个负向加权,使目标声源每次成像的时间缩短,即将目标声源在空间声场分布云图像上每次显示的时间进行缩短,以减少目标声源的总显示时间,如此设置,能够帮助筛除一小部分疑似回声点,从而在一定程度上减少误判及误报。
本发明实施例采用基于波束成形算法和声达时间差算法的融合算法对目标空间内的声源进行检测及成像,将波束成形算法和声达时间差算法进行联合使用以实现对疑似误判声源点的二次判定,进而提高声源检测的准确性。
在波束成形算法中,通过优化麦克风的指向性和增益,能够有效地抑制噪声和不相关信号源,提供较为准确的定位估计,并获得初步的声源定位结果。然而,波束成形算法也存在一些限制,例如由于信号多径效应和环境干扰等因素,可能导致定位误差。为了进一步提高声源定位的准确性,采用声达时间差算法进行二次判定。声达时间差算法通过测量声波信号到达不同麦克风之间的时间差,并结合已知的声波信号传播速度,计算目标声源到各个麦克风的距离差,从而实现更准确的声源定位。通过将波束成形算法的声源定位结果与声达时间差算法的声源定位结果进行比对,可以验证和纠正定位误差,并提供更可靠的定位估计。
关于声达时间差算法,本发明实施例做出了如下优化:
1、多径信号处理:多径效应是声达时间差算法中一个常见的误差来源,本发明实施例中,采用多径信号建模和处理技术,利用波形库存储和自适应滤波器等方法来抑制多径干扰,从而修正因其引起的声达时间差算法的测量误差。
2、为了解决时钟同步问题,采用温度补偿和自动校准,实施校准时钟偏移,减小时钟偏差和计算时差时的不确定性。
3、信号预处理和特征提取:在声达时间差算法中,对接收到的信号进行特征提取,增强信号的相关特征,减小噪声的影响,并提取出更准确的时间差特征。
具体地,本发明实施例中,对于空间声场分布云图像上的成像不连续的目标声源,采用声达时间差算法下的声源检测结果对目标声源在波束成形算法下的声源检测结果进行二次判定。当波束成形算法检测到成像不连续的目标声源(X1,Y1,Z1)时,触发间断式地成像,每次成像时间为A秒且中心点声压级为N1分贝,此时进行二次判定,假设声达时间差算法检测出一个坐标为(X2,Y2,Z2)、中心点声压级为N2分贝的最大声源,将该最大声源作为参照声源,若目标声源与参照声源在位置上的偏差小于预定的位置偏差阈值且在中心点声压级上的偏差小于预定的声压级偏差阈值,则说明目标声源与参照声源的相一致,进而判定目标声源为目标空间内的最大声源,并延长其每次成像的时间;若不一致,则先判断波束成形算法所检测出的声源是否不止目标声源一个,若是,则判断波束成形算法所检测出的声源中是否存在与参照声源相一致的声源,若存在,则说明波束成形算法所检测出的声源中包含目标空间内的最大声源,只不过成像不连续的声源并非最大声源,此时不改变目标声源每次成像的时间,若不存在,则将目标声源每次成像的时间减少一半;若否,即目标声源为波束成形算法所检测出的唯一声源且与参照声源不一致,则将目标声源每次成像的时间减少一半。
在采用上述融合算法之后,本发明实施例的声学成像装置能够稳定成像的声源强度低至6.5dB,而采用112通道麦克风阵列模块的手持式声学成像仪能够稳定成像的最小声源强度为6.4dB,二者已经非常接近。然而,很明显地,在体积、重量、功耗和成本方面,本发明实施例的声学成像装置均优于采用112通道麦克风阵列模块的手持式声学成像仪。
本发明实施例的声学成像装置,在空气压力高于0.12Mpa的检测环境下,有效检测距离为0.5~100米,其最大有效检测距离已经达到现有采用128通道麦克风阵列模块的手持式声学成像仪的水平,而现有的采用64通道麦克风阵列模块的手持式声学成像仪的最大有效检测距离通常为50米左右。本发明实施例的声学成像装置的测量频率范围为2kHz~65kHz,优于现有的采用128通道麦克风阵列模块的手持式声学成像仪的2kHz-45kHz的测量频率范围。
虽然以上对本发明的一个或者多个实施方式进行了描述,但是本领域的普通技术人员应当知晓,本发明能够在不偏离其主旨与范围的基础上通过任意的其他的形式得以实施。因此,以上描述的实施方式属于示意性的而非限制性的,在不脱离如所附各权利要求所定义的本发明精神及范围的情况下,对于本技术领域的普通技术人员而言许多修改和替换均具有显而易见性。
- 检测腹泻病毒的核酸组合物、试剂盒及试剂盒的使用方法
- 四氢引达省基催化剂组合物、催化剂体系及其使用方法
- 洗涤剂组合物原液、以及包含该洗涤剂组合物原液的洗涤剂组合物
- 用于浅沟槽隔离的水性低研磨剂二氧化硅浆料和胺羧酸组合物以及其制造和使用方法
- 核酸和细胞保存剂组合物以及使用方法
- 核酸和细胞保存剂组合物以及使用方法