基于韵律域信息监督的解耦-增强越南语语音识别口音自适应方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及基于韵律域信息监督的解耦-增强越南语语音识别口音自适应方法,属于人工智能技术领域。
背景技术
端到端模型在自动语音识别(Automatic Speech Recognition,ASR)领域逐渐成为主流。由于越南语缺乏像中文或英文等语言那样的大量标注数据,目前越南语性能最佳的端到端ASR模型基于大规模无监督预训练模型构建。从发音上看,越南语通常分为北部和南部口音,北部口音作为越南官方标准口音,互联网上大量的越南语语音数据如有声读物、新闻视频等主要为北部口音,越南语语音预训练模型主要基于北部口音数据进行训练和微调。然而,当对越南语南部口音进行识别时,由于口音差异,识别模型性能下降明显。越南语语音预训练模型基于大量越南语语音数据训练,仅从当前北部口音识别性能来看,预训练模型对内容信息已有较好的表征能力,本发明考虑分离域相关信息和域无关内容信息,使预训练模型专注于对内容信息的表征。此外,由于越南语南北口音在音高和节奏上存在发音差异,考虑对音高特征及频谱特征进行细粒度韵律表征,依赖符合越南语发音的口音韵律信息增强模型对南北差异性特征的自适应表征。
越南语南北口音在声调、节奏方面存在发音差异,现有越南语语音预训练模型对南北口音存在口音表征偏置,导致语音识别模型自适应能力不足。
本发明结合越南语南北口音发音特点,提出以韵律和域标签信息为指导的解耦-增强越南语语音识别自适应表征训练策略。
发明内容
本发明提供了基于韵律域信息监督的解耦-增强越南语语音识别口音自适应方法,解决了越南语语音预训练模型存在口音表征偏置问题,还缓解了识别模型因口音差异导致的性能下降问题,显著降低了南部口音的识别词错率。
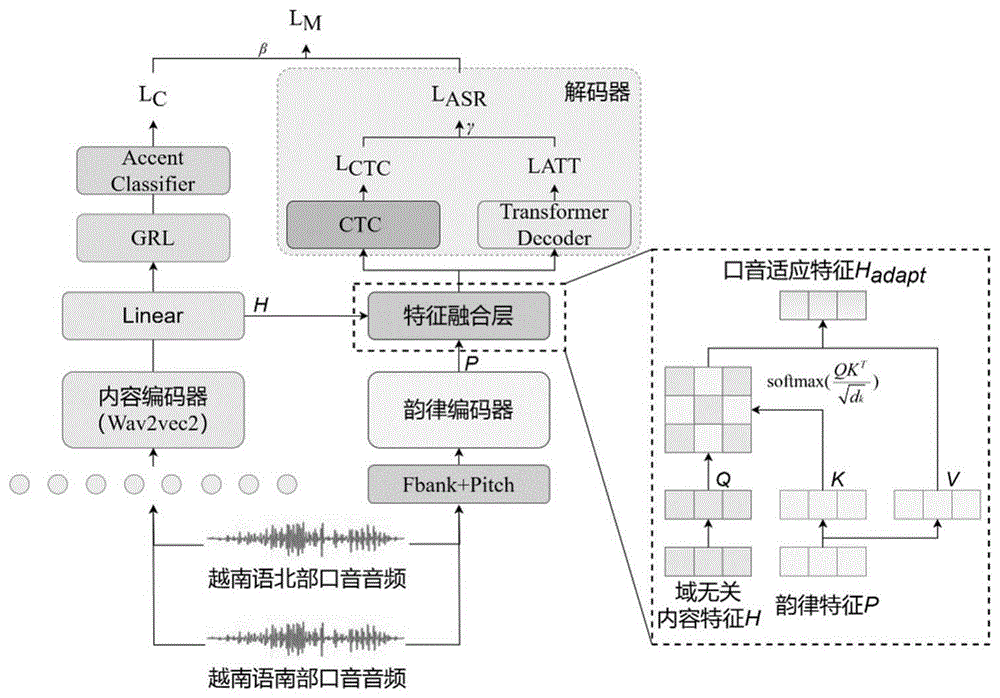
本发明的技术方案是:基于韵律域信息监督的解耦-增强越南语语音识别口音自适应方法,所述方法首先,提取口音音频数据的Fbank+Pitch特征进行细粒度口音韵律表征;其次,通过域对抗训练预训练模型解耦域无关内容特征,基于自适应选择实现域无关内容特征与韵律特征融合增强;最终联合域分类与混合CTC/attention实现口音自适应表征;模型训练过程中仅越南语北部口音数据使用标注文本,南部口音数据不使用标注文本。
所述方法的具体步骤如下:
Step1、收集越南语北部和南部口音的文本及语音数据作为训练语料和测试语料;
Step2、对收集到的语料进行预处理,语料的预处理包括:文本语料清洗、vad切割音频、去除嘈杂无意义的音频;
Step3、使用开源工具Kaldi提取预处理后的音频的Fbank+Pitch特征;
Step4、在步骤Step3的基础上使用交叉熵损失和结合梯度反转层的CTC损失训练韵律编码器;
Step5、在步骤Step4的基础上将从wav2vec内容编码器提取的特征与韵律编码器提取的特征通过特征融合层进行融合:
Step6、在步骤Step5的基础上,使用结合梯度反转层的交叉熵损失训练wav2vec内容编码器,同时使用混合CTC/Attention解码器进行语音识别的解码;
Step7、利用解耦-增强的自适应策略消除预训练模型中的口音偏置信息,同时越南语补充越南语发音韵律信息,最终在越南语南北部口音数据上进行语音识别实验验证。
进一步地,所述Step4中,使用交叉熵损失和结合梯度反转层的CTC损失训练韵律编码器,具体包括如下:
韵律编码器由卷积层和Bi-LSTM层组成,卷积层捕获局部时域信息,Bi-LSTM捕获长距离时序依赖,在Bi-LSTM对特征进行切片+拼接,得到更具代表性的韵律特征,最终使韵律编码器对输入的Fbank+Pitch特征序列仅编码成包含韵律信息的固定长度向量,韵律编码过程为
其中
其中
其中C
所述Step4中,使用交叉熵损失和结合梯度反转层的CTC损失训练韵律编码器:在正常的神经网络中,梯度在反向传播过程中会根据损失函数来更新模型参数。而梯度反转层会改变梯度的方向,使其相当于将一个相反的梯度信号传递回去。结合两次使用梯度反转层,用于韵律编码器时期望编码特征尽可能模糊内容信息仅关注对韵律的表征,因此在CTC损失前加入梯度反转层。用于内容编码器时期望减弱预训练模型对口音的表征能力,因此在口音分类前加入梯度反转层。
进一步地,所述Step5中,将从wav2vec内容编码器提取的域无关内容特征H与韵律编码器提取的韵律特征P基于选择适应融合为口音适应特征H
进一步地,所述Step6中,使用结合带梯度反转层的交叉熵损失训练wav2vec内容编码器,同时使用口音适应特征进行语音识别解码,解码策略为
进一步地,所述Step6中,总损失为口音分类与语音识别的联合损失,为L
本发明的有益效果是:
(1)本发明通过多任务联合域分类解耦域无关内容特征与基于自适应选择的域无关特征与韵律特征融合增强,实现对越南语南北区分性口音的自适应表征;
(2)本发明利用域标签监督越南语语音预训练模型解耦域无关内容特征,而越南语口音韵律信息辅助增强模型的口音表征能力,通过自适应选择的融合方式实现口音信息增强,实现语音识别模型对南北口音差异性特征的自适应表征。在越南语南北口音数据进行了理论与技术的验证,在保证模型对北部口音识别性能的基础上,显著降低了南部口音的识别词错率,缓解了识别模型因口音差异导致的性能下降问题,提高了越南语语音识别模型对南北口音的识别鲁棒性,充分证明了该方法的有效性。
附图说明
图1为本发明中的流程图;
图2为本发明中韵律编码器模型图。
具体实施方式
实施例1:如图1-图2所示,基于韵律域信息监督的解耦-增强越南语语音识别口音自适应方法,所述方法的具体步骤如下:
Step1、收集越南语北部和南部口音的文本及语音数据作为训练语料和测试语料;
Step2、对收集到的语料进行预处理,语料的预处理包括:文本语料清洗、vad切割音频、去除嘈杂无意义的音频;
具体的,实验所用的越南语北部口音数据来自于越南语开源数据VLSP2020的有标注语音,共88小时。南部口音的数据集由网络随机搜索的86248句越南语文本,对文本进行清洗,删除文本中不可读字符等,然后由越南语本土23名南部口音人员对文本进行标注,得到70小时越南语南部口音语音数据。北部口音中分为80小时训练集,10小时开发集和8小时测试集,南部口音中分为60小时训练集,7小时开发集和3小时测试集;
Step3、韵律编码器的输入为音频的Fbank+Pitch特征,使用开源工具Kaldi提取预处理后的音频的Fbank+Pitch特征;Fbank+Pitch特征使用开源语音识别工具kaldi[24]提取,设置帧移为10ms,帧窗口大小为25ms,提取83维的Fbank+pitch特征,特征提取过程为f
Step4、在步骤Step3的基础上使用交叉熵损失和结合梯度反转层的CTC损失训练韵律编码器;使韵律编码器能够从语音Fbank+Picth特征中提取越南语的口音韵律特征;
进一步地,所述Step4中,使用交叉熵损失和结合梯度反转层的CTC损失训练韵律编码器,具体包括如下:
韵律编码器由卷积层和Bi-LSTM层组成,卷积层捕获局部时域信息,Bi-LSTM捕获长距离时序依赖,在Bi-LSTM对特征进行切片+拼接,得到更具代表性的韵律特征,最终使韵律编码器对输入的Fbank+Pitch特征序列仅编码成包含韵律信息的固定长度向量,韵律编码过程为
其中
其中
其中
所述Step4中,使用交叉熵损失和结合梯度反转层的CTC损失训练韵律编码器:在正常的神经网络中,梯度在反向传播过程中会根据损失函数来更新模型参数。而梯度反转层会改变梯度的方向,使其相当于将一个相反的梯度信号传递回去。结合两次使用梯度反转层,用于韵律编码器时期望编码特征尽可能模糊内容信息仅关注对韵律的表征,因此在CTC损失前加入梯度反转层。用于内容编码器时期望减弱预训练模型对口音的表征能力,因此在口音分类前加入梯度反转层。
Step5、在步骤Step4的基础上将从wav2vec内容编码器提取的特征与韵律编码器提取的特征通过特征融合层进行融合;补充符合越南语发音的口音信息;
进一步地,域无关内容特征由内容编码器表征而来,韵律特征由韵律编码器表征,所述Step5中,将从wav2vec内容编码器提取的域无关内容特征H与韵律编码器提取的韵律特征P基于选择适应融合为口音适应特征H
从wav2vec内容编码器提取的域无关内容特征包括基于域对抗解耦的域无关内容表征,具体如下:
域对抗训练的目的在于分离域相关信息和域无关内容信息,使内容编码器仅进行越南语内容相关信息表征,消除预训练数据中混淆的域信息。口音分类器的损失为交叉熵损失,语音识别的损失为混合CTC/Attention损失,损失函数L
Step6、在步骤Step5的基础上,使用结合梯度反转层的交叉熵损失训练wav2vec内容编码器,同时使用混合CTC/Attention解码器进行语音识别的解码;
进一步地,所述Step6中,使用结合带梯度反转层的交叉熵损失训练wav2vec内容编码器,同时使用口音适应特征进行语音识别解码;
语音识别口音自适应解码采用当前流行的混合CTC/Attention解码策略,CTC解码器由一个线性层、log softmax层构成;Attention-Based解码器由多层Transformer解码器构成。损失函数L
解码策略为
联合带梯度反转层的口音分类损失模糊预训练wav2vec编码器中对的域信息,与混合CTC/Attention联合为多任务训练微调预训练模型,达到越南语语音识别模型对南北口音的自适应表征;
进一步地,所述Step6中,总损失为口音分类与语音识别的联合损失,为L
Step7、利用解耦-增强的自适应策略消除预训练模型中的口音偏置信息,同时越南语补充越南语发音韵律信息,最终在越南语南北部口音数据上进行语音识别实验验证。
越南语南北口音在声调、节奏方面存在发音差异,现有越南语语音预训练模型对南北口音存在口音表征偏置,导致语音识别模型自适应能力不足。本发明针对发音差异性下自适应语音识别问题,提出以韵律和域标签信息为指导的越南语语音解耦-增强的自适应表征策略,实现了越南语南北口音差异性特征的自适应表征;
实验基于espnet框架进行,针对南北部口音数据与现有三种无监督域适应方法进行比较,同时验证最优训练策略及特征融合方式。表1为不同域适应方法的识别性能
表1:不同域适应方法的识别性能(WER%)
以上数据可以看出,由于预训练和微调均缺少南部口音数据,预训练+微调在北部口音的词错率仅为10.56%,然而南部口音的词错率上升至16.00%,模型对南部口音表征能力不足。MMD和DAT分别将南部口音词错率降到了15.35%和15.20%。相比于其他域适应算法之下,本发明所提解耦-增强的多任务算法将南部口音词错率降至14.86%,表明适应性选择融合域无关内容特征与韵律特征的有效性,解码器能直接关注到生成的口音适应性特征,缓解了预训练模型对南部口音表征能力不足的问题,在南部口音上识别词错率显著下降。此外,相较于微调预训练模型在北部口音的词错率仅相差0.15%,表明在带来南部口音性能提升的同时尽可能保持了北部口音上的识别性能,没有造成灾难性遗忘,证明该方法在有效进行域无关内容表征的同时补充了越南语南北发音韵律信息,缓解了预训练模型的口音表征偏置问题,有效提升了越南语语音识别模型的对南北口音的识别鲁棒性。
表2为域对抗解耦的影响下的识别性能
表2:域对抗解耦的影响(WER%)
以上数据可以看出,将口音适应特征作为解码器的输入时,北部口音的词错率相较基线模型有所下降,达到10.47%,证明本发明所提越南语细粒度韵律表征方法有效捕捉了越南语发音韵律信息。而南部口音词错率为15.49%,这是因为越南语语音预训练模型主要由大规模北部口音数据训练,对北部口音已有较好表征能力,对南部口音表征能力不足,模型存在口音表征偏置问题。当引入域对抗解耦域无关内容特征后,模型在保持北部口音识别性能的基础上,南部口音识别性能达到最佳,证明域对抗有效区分了预训练模型表征的域相关信息和域无关信息,解耦出的域无关内容特征中不再包含域信息,缓解了预训练模型的口音表征偏置问题。
表3为融合韵律特征的影响下的识别性能
表3:融合韵律特征的影响(WER%)
以上数据可以看出,当模型不进行韵律特征的融合,仅使用域对抗解耦域无关内容特征作为解码器的输入时,南部口音为15.20%的词错率,虽然较基线模型有所下降,但并不是最佳结果,且对于北部口音词错率也升高了0.45%。将融合后的口音适应特征作为多任务联合中口音分类的输入时,较基线模型南部口音词错率降低至15.29%,但未取得最佳结果,越南语韵律口音信息在口音分类任务中被模糊,同时北部口音词错率也上升至10.82%。而本发明方法达到南部口音上最低词错率14.86%,同时北部口音的词错率也仅与预训练微调模型相差0.15%,达到模型的自适应语音识别。原因是韵律特征基于自适应选择的融合为域无关内容特征合理补充了越南语口音发音信息,解码器的文本信息在计算注意力分数时能够直接关注到具有区分性的口音韵律信息,增强了模型的自适应表征能力。
表4为不同融合方式的影响
表4:不同融合方式的影响(WER%)
以上数据可以看出,这些方法中交叉注意力融合的方法能同时得到北部和南部最低词错率。拼接融合-L的性能最差,这是因为在长度上的拼接导致了两种特征的信息错乱,无法完全对应上。拼接融合-D有了部分提升,但性能并非最佳,因为维度上的简单叠加容易产生冗余信息,造成一定干扰。相比之下,本发明所提的交叉注意力融合根据当前任务及输入特征,自适应进行权重调整及注意力分配,将域无关内容特征于韵律特征有效融合,实现模型对南北区分性口音的自适应表征。
表5为对识别结果的实例分析
表5:识别结果实例分析
以上数据可以看出,在第一个实例中,北部口音在三种方法中均能正确识别,然而使用南部口音时,对于带声调的音节
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 一种感温自启闭快速灭火装置及使用方法
- 一种感温包插片及使用该感温包插片的空调器
- 一种中医针灸用设有温感提醒功能的温针装置及方法
- 一种温感提醒的中医针灸针