基于AI大数据的课程教学资源个性推荐方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及数据处理技术领域,具体涉及基于AI大数据的课程教学资源个性推荐方法。
背景技术
传统的课程搜索和筛选过程可能消费大量的时间和精力,而智能课程资源推荐可以根据用户的需求和背景自动筛选出适合的学习资源,帮助用户更快速地找到适合的学习材料;智能课程资源推荐能够根据用户的兴趣、学习风格和能力水平提供个性化的学习内容,帮助用户更好地发现和发展自身的潜能,智能课程资源推荐通过数据分析和学习算法对用户的学习需求和难点进行分析,为其提供相应的解决方案,提升学习效果和学习效率。
而现有技术通过用户的偏好关键词进行关键词推荐,采用基于聚类的局部离群因子检测算法(CBLOF),但CBLOF通过聚类结果进行数据点的异常评价的计算过程中,由于聚类结果中局部极小值体现出的用户对某一部分关键词更加偏重的情况,所以局部极小值会对其附近数据点的异常评价的计算造成引导效果,进而导致检测出的离群数据点不准确,影响后续根据离群数据点所代表的用户偏好关键词进行教学资源推荐的准确性,陷入“信息茧房”效应,导致教学资源与用户需求差异性过大,降低用户的使用体验。
发明内容
为了解决上述问题,本发明提供基于AI大数据的课程教学资源个性推荐方法,所述方法包括:
获取用户的课程资源浏览数据,用户的课程资源浏览数据包括每个课程资源窗口的每次浏览时长、每次浏览时刻、平均点击次数以及对应的若干个偏好关键词;根据用户的课程资源浏览数据中每个课程资源窗口的每次浏览时长和平均点击次数构建样本空间;
对样本空间中所有数据点进行聚类获得若干个聚类簇;根据每个聚类簇的位置分布,获取样本空间中每个聚类簇的用户注意程度;
根据每个聚类簇中数据点所对应的课程资源窗口的浏览时刻和平均点击次数以及每个聚类簇的用户注意程度,获取每个聚类簇的用户注重程度;根据每个聚类簇的用户注重程度获取离散数据点;根据离散数据点所对应的课程资源窗口的若干个偏好关键词,获取用户的关键词推荐序列;
根据用户的关键词推荐序列对用户进行教学资源推荐。
优选的,所述根据用户的课程资源浏览数据中每个课程资源窗口的每次浏览时长和平均点击次数构建样本空间,包括的具体方法为:
将课程资源窗口的平均浏览时长作为样本空间的X轴,将课程资源窗口的平均点击次数作为样本空间的Y轴,样本空间中每个数据点表示每个课程资源窗口的浏览平均时长和平均点击次数。
优选的,所述根据每个聚类簇的位置分布,获取样本空间中每个聚类簇的用户注意程度,包括的具体方法为:
获取样本空间中第
式中,
优选的,所述获取样本空间中第
将样本空间中第
优选的,所述根据每个聚类簇中数据点所对应的课程资源窗口的浏览时刻和平均点击次数以及每个聚类簇的用户注意程度,获取每个聚类簇的用户注重程度,包括的具体方法为:
获取样本空间中第
式中,
优选的,所述获取样本空间中第
式中,
优选的,所述根据每个聚类簇的用户注重程度获取离散数据点,包括的具体方法为:
获取所有第一聚类簇和所有第二聚类簇,将所有第一聚类簇组成集合记为大簇,将所有第二聚类簇组成集合记为小簇,将大簇、小簇和样本空间输入异常检测之基于聚类的局部异常因子检测算法,获得样本空间中所有数据点的异常得分,将所有数据点按照异常得分从大到小进行排序获得数据点异常得分序列;将数据点异常得分序列中所有数据点的数量与
优选的,所述获取所有第一聚类簇和所有第二聚类簇,包括的具体方法为:
获取聚类簇顺序序列,若聚类簇顺序序列中第一个聚类簇的用户注重程度大于或等于a,则将聚类簇顺序序列中第一个聚类簇作为第一聚类簇,将聚类簇顺序序列中除第一个聚类簇以外的其他所有聚类簇均记为第二聚类簇;
若聚类簇顺序序列中第一个聚类簇的用户注重程度小于
优选的,所述获取聚类簇顺序序列,包括的具体方法为:
将所有聚类簇按照用户注重程度从大到小进行排序,获得聚类簇顺序序列。
优选的,所述根据离散数据点所对应的课程资源窗口的若干个偏好关键词,获取用户的关键词推荐序列,包括的具体方法为:
将所有离散数据点和样本空间中每个聚类簇的中心数据点记为目标数据点,将所有目标数据点所对应的课程资源窗口的若干个偏好关键词,按照偏好关键词的数量从大到小进行排序获得用户的关键词推荐序列。
本发明的技术方案的有益效果是:本发明根据每个聚类簇中数据点所对应的课程资源窗口的浏览时刻和平均点击次数以及每个聚类簇的用户注意程度,获取每个聚类簇的用户注重程度;根据每个聚类簇的用户注重程度获取离散数据点,避免聚类结果中局部极小值会对其附近数据点的异常评价的计算造成引导效果,进而使得检测出的离群数据点更准确;根据离散数据点所对应的课程资源窗口的若干个偏好关键词,获取用户的关键词推荐序列,根据用户的关键词推荐序列对用户进行教学资源推荐,降低了推荐的教学资源与用户需求之间的差异性,进而能够准确实现对用户的个性推荐,增加用户的使用体验。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
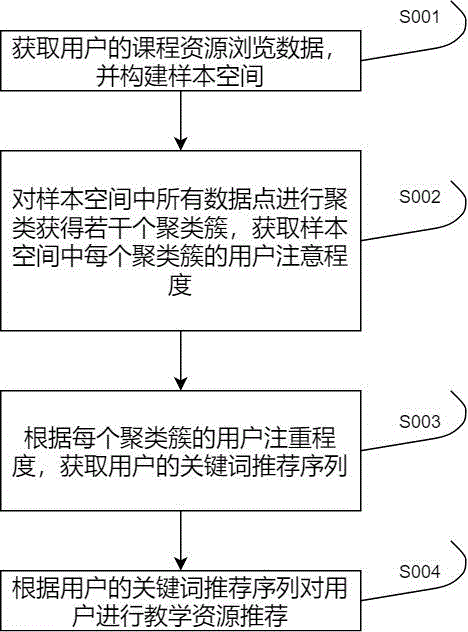
图1为本发明基于AI大数据的课程教学资源个性推荐方法的步骤流程图。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的基于AI大数据的课程教学资源个性推荐方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
下面结合附图具体的说明本发明所提供的基于AI大数据的课程教学资源个性推荐方法的具体方案。
请参阅图1,其示出了本发明一个实施例提供的基于AI大数据的课程教学资源个性推荐方法的步骤流程图,该方法包括以下步骤:
步骤S001:获取用户的课程资源浏览数据,并构建样本空间。
需要说明的是,由于用户对每个课程资源窗口都具有对应的多个偏好关键词、浏览平均时长和平均点击次数,通过对课程资源窗口属性进行聚类,避免了偏好关键词在窗口中出现交叉情况,从而被其他窗口的交叉情况产生影响。
具体的,为了实现本实施例提出的基于AI大数据的课程教学资源个性推荐方法,首先需要采集用户的课程资源浏览数据,具体过程为:
在课程资源系统记录中,采集用户最新登录系统的时刻和用户对每个课程资源窗口的每次浏览时长和每次浏览时刻、每个课程资源窗口的平均点击次数以及每个课程资源窗口对应的若干个偏好关键词,并将其统称为用户的课程资源浏览数据;根据用户的课程资源浏览数据中每个课程资源窗口的每次浏览时长和平均点击次数构建样本空间,将课程资源窗口的平均浏览时长作为样本空间的X轴,将课程资源窗口的平均点击次数作为样本空间的Y轴,样本空间中每个数据点表示每个课程资源窗口的浏览平均时长和平均点击次数。
其中,用户的课程资源浏览数据是指用户最新登录系统的时刻、每个课程资源窗口的每次浏览时长和每次浏览时刻、每个课程资源窗口的平均点击次数以及每个课程资源窗口对应的若干个偏好关键词。
至此,通过上述方法得到用户的课程资源浏览数据。
步骤S002:对样本空间中所有数据点进行聚类获得若干个聚类簇,获取样本空间中每个聚类簇的用户注意程度。
具体的,通过迭代自组织聚类算法对样本空间中所有数据点进行聚类,在样本空间中获得若干个聚类簇。
需要说明的是,样本空间中,一个聚类簇代表了一群浏览特征相似的课程资源窗口,因此通过判断聚类簇之间的浏览特征差异能够分析出聚类簇是否发生了具有导向特征的偏移情况,进而推断出用户对当前聚类簇内的偏好关键词的偏好情况变化,再综合用户的浏览情况计算用户对于本聚类簇的关注程度,进而分析用户对本聚类簇内的偏好数据点代表的教学资源的需求程度,根据需求程度进行自适应推荐。
其中,迭代自组织聚类算法为现有技术,本实施例此处不作过多赘述。
需要说明的是,聚类簇在样本空间的位置信息代表了用户偏好情况的专一程度,当聚类簇数量越少,说明用户对单个聚类簇内代表的偏好关键词关注越明显;当前聚类簇中数据点个数相比其他聚类簇更多,说明聚类簇之间分布越离散,说明用户的偏好关键词之间差异更大,更有利于通过聚类簇代表的浏览偏好情况更容易做出区分。
具体的,样本空间中第
式中,
需要说明的是,
至此,通过上述方法得到样本空间中每个聚类簇的用户注意程度。
步骤S003:根据每个聚类簇的用户注重程度,获取用户的关键词推荐序列。
需要说明的是,由于用户对学习资源的使用存在阶段性,即用户通过使用学习资源窗口中的资源一定时间后,该学习资源窗口中的资源相对用户的价值会逐渐下降,因此通过聚类簇中数据点的获取顺序与聚类簇的用户注意评价进行综合,将用户对该教学资源的使用情况进行量化分析,准确识别用户对于学习资源窗口中教学资源的实际关注程度。
具体的,样本空间中第
式中,
需要说明的是,
预设一个参数
进一步的,将所有聚类簇按照用户注重程度从大到小进行排序,获得聚类簇顺序序列;
若聚类簇顺序序列中第一个聚类簇的用户注重程度大于或等于
若聚类簇顺序序列中第一个聚类簇的用户注重程度小于
将所有第一聚类簇组成集合记为大簇,将所有第二聚类簇组成集合记为小簇,将大簇、小簇和样本空间输入异常检测之基于聚类的局部异常因子检测算法,获得样本空间中所有数据点的异常得分,将所有数据点按照异常得分从大到小进行排序获得数据点异常得分序列;将数据点异常得分序列中所有数据点的数量与
其中,异常检测之基于聚类的局部异常因子检测算法为现有技术,本实施例此处不作过多赘述。
需要说明的是,离群数据点代表了用户对该课程资源窗口的访问次数与其他课程资源窗口访问特征差异较大的情况,可能代表用户的个性喜好情况。
具体的,将所有离散数据点和样本空间中每个聚类簇的中心数据点记为目标数据点,将所有目标数据点所对应的课程资源窗口的若干个偏好关键词,按照偏好关键词的数量从大到小进行排序获得用户的关键词推荐序列。
至此,通过上述方法得到用户的关键词推荐序列。
步骤S004:根据用户的关键词推荐序列对用户进行教学资源推荐。
具体的,在教学资源的数据库中获取与用户的关键词推荐序列中每个偏好关键词相关的教学资源,按照用户的关键词推荐序列的排序顺序依次对用户进行教学资源推荐。
至此,本实施例完成。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 用于卷绕无刷直流电动机的定子的方法
- 一种适用于无槽无刷直流电动机定子结构的整形固化模