一种基于热力图的景区内游客导航方法
文献发布时间:2024-04-18 20:01:55
技术领域
本发明涉及景区游客导航方法,更具体地说,涉及一种基于热力图的景区内游客导航方法。
背景技术
随着旅游业的迅速发展,越来越多的人们选择在假期或周末参观各类景区、公园和旅游胜地。这些场所为游客提供了丰富的文化、娱乐和自然体验,但同时也面临着一个重要的管理挑战:如何确保大量游客能够顺畅、安全地游览,特别是在高峰期或特定的热门景点。
由于景区面积一般较大,如果对游客导航路线未做规划,游客容易产生局部区域的拥挤,这不仅会降低游客的游览体验,还可能引发安全隐患,如踩踏事件。因此,如何实时、准确地预测和管理这种局部拥挤情况成为了景区管理者亟需解决的问题。
发明内容
本发明要解决的技术问题是提供一种基于热力图的景区内游客导航方法,以解决背景技术中提到的问题。
为了达到上述目的,本发明采取以下技术方案:
一种基于热力图的景区内游客导航方法,包括以下步骤:
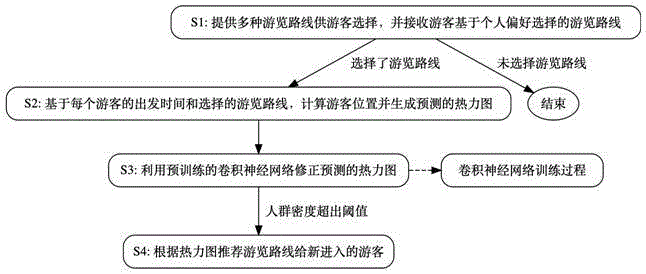
S1:提供多种导航路线供游客选择,并接收游客基于个人偏好选择的导航路线;
S2:基于每个游客的出发时间和选择的导航路线,利用历史数据统计的游客平均步行速度和在每个景点的平均停留时间,计算每个游客在景区内的实时位置,并据此生成预测的热力图;
S3:利用预先训练完成的卷积神经网络对预测的热力图进行修正;其中,所述卷积神经网络的训练过程为:收集实际热力图数据,并将所述预测的热力图与实际热力图数据配对,形成训练数据集;使用所述训练数据集,通过卷积神经网络进行模型训练,其目标是最小化预测热力图与实际热力图之间的差异;
S4:当预测并修正过的热力图中未来存在任意一个预设面积内的人群密度超出预设的阈值时,对于新进入景区的游客,采取如下导航路线推荐方法:对于每一种导航路线,计算其如果被分配给新进入景区的游客后,在未来分别会导致的修正过的热力图,对于每种修正过的热力图,计算其在未来一段时间内的均匀程度,其中,均匀程度越高的热力图对应的导航路线被优选推荐给游客。
优选的,所述导航路线是一个以景区入口开始,以出口结尾,经过所有景点的哈密顿路径。
优选的,所述热力图中,颜色越深的区域表示人群密度越高。
优选的,所述热力图任一时刻的均匀度计算方式如下:
提取热力图上所有点的人群密度值构成一个数据集,其中每个点代表一个单位面积;计算这个数据集的标准差;标准差越小,均匀度越高。
在一些实施例中,取标准差的倒数作为均匀度的度量。
优选的,一段时间内的均匀度通过标准差对于时间的积分表示,积分值越小,均匀度越高。
在一些实施例中,所述一段时间内的均匀度等于所述积分值的倒数。
在一些实施例中,所述一段时间为计算均匀度的时刻到景区关闭时刻。
在一些实施例中,S4中所述预设面积为50平方米。
在一些实施例中,所述预设的阈值为0.2人/平方米。
本发明相对于现有技术的优点在于,本发明结合了预测热力图、卷积神经网络和动态路线推荐技术,能够实时、准确地预测和管理景区内的人流分布,尤其针对可能的局部拥挤情况,并且能够根据已有人流分布情况,提供使得人流分布更加均匀的导航路线推荐,这不仅显著提高了游客的游览体验和安全性,还为景区管理者提供了一个高效、科学的人流管理工具。
附图说明
图1是本发明方法的示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作描述。
如图1所示,本发明方法包括如下步骤:越深的颜色表示人群越密集
S1:提供多种导航路线供游客选择,并接收游客基于个人偏好选择的导航路线;
S2:基于每个游客的出发时间和选择的导航路线,利用历史数据统计的游客平均步行速度和在每个景点的平均停留时间,计算每个游客在景区内的实时位置,并据此生成预测的热力图;
S3:利用预先训练完成的卷积神经网络对预测的热力图进行修正;其中,所述卷积神经网络的训练过程为:收集实际热力图数据,并将所述预测的热力图与实际热力图数据配对,形成训练数据集;使用所述训练数据集,通过卷积神经网络进行模型训练,其目标是最小化预测热力图与实际热力图之间的差异;
S4:当预测并修正过的热力图中未来存在任意一个预设面积内的人群密度超出预设的阈值时,对于新进入景区的游客,采取如下导航路线推荐方法:对于每一种导航路线,计算其如果被分配给新进入景区的游客后,在未来分别会导致的修正过的热力图,对于每种修正过的热力图,计算其在未来一段时间内的均匀程度,其中,均匀程度越高的热力图对应的导航路线被优选推荐给游客。
以上方法中,对于导航路线,是一个从入口开始,以出口结尾,是一个可以经过所有景点的哈密顿路径。一般来说,导航路线是景区工作人员根据对于景区地形等的了解所制定的比较推荐游客采取的几个导航路线,可以根据具体的景区情况制定。
以上方法中,对于S2中,所谓的统计的游客平均步行速度和在每个景点的平均停留时间,指的是,在历史游客数据中,我们可以对大量的游客的步行速度、在每个景点的停留时间进行统计,然后对其进行平均,从而获得游客平均步行速度和在每个景点的平均停留时间。平均过后,对于后续进入的大量的游客,采用平均的数据去确定每个游客所位于的位置,虽然对于单个游客可能不准确,但是对于大量的游客,总体导致的热力图的变化不会相差太大。这里的热力图会显示在某个特定时间点,景区内各个区域的人群密度,颜色的深浅表示人群的多少,越深的颜色表示人群越密集。
另外,一般来说,我们给定的路径前往景点的排序,以及景点之间互通的道路。当游客到达一个景点的时候,由于一个景点往往包含一个大块区域,那么如果我们可以计算出某一个时刻在该景点的游客数,便可以把游客数除以该景点的面积,作为该景点处的密度。而由于游客在道路上行走的位置可以预测,且道路一般都是比较窄的区域,因此游客走到道路上哪个点,就算在哪个点,由此计算道路上的密度。
热力图的绘制可以使用基于Python的开源库Matplotlib完成的,输入对应计算出的人群密度后,可以用其绘制出热力图。这些热力图还可以实时显示在景区以及景区管理处的屏幕上,以供人参考。
除此之外,为了能够使得计算得到的热力图尽量和实际的热力图的差距还能够进一步减小,本发明还设计卷积神经网络来修正热力图:
首先,需要从历史数据中收集实际热力图,确保它们的分辨率和尺寸都是统一的。实际热力图可以通过红外摄像头统计景区游客数量来进行生成,也就是说,实际热力图是实际观测到的景区热力图,而预测的热力图是通过游客平均步行速度和游客在每个景点的平均停留时间进行计算的。将预测热力图作为输入,实际热力图作为目标输出,形成训练数据对。对于网络架构,可以选择一个基本的卷积神经网络架构。通常,可以从简单的几层卷积层开始,然后增加层数以获得更好的性能。每个卷积层后面可以接一个批量归一化层和ReLU激活函数以增加模型的非线性。最终,网络应该有一个或几个全连接层,输出的尺寸应与实际热力图相同。
由于任务是回归性质的,可以使用均方误差(MSE)作为损失函数,以衡量预测热力图与实际热力图之间的差异。还可以使用像Adam或RMSprop这样的自适应优化器进行训练。
训练过程中,将数据集分成训练集和验证集。使用训练集进行模型训练,并定期在验证集上检查性能,以防止过拟合。考虑使用早停技巧,即当验证损失不再明显减少时停止训练。对于生成的修正后的热力图,可以使用阈值技巧进行进一步处理,如滤除那些人群密度极低的区域。
对于步骤S4中,其中涉及到一个关键是,如何评估未来一段时间内热力图的均匀程度呢?可以采用标准差计算方法:
在任何给定的热力图中,每个像素或区域代表了那个特定地点的人群密度。热力图的均匀度实际上是指人群在景区中的分布均匀程度。若人群在各区域的分布相对均匀,那么游客体验和流动性都将得到提高,而拥挤和潜在的安全隐患则会得到降低。
标准差是一个常用的统计工具,用于衡量一组数据的分散程度。在本发明中,使用标准差来衡量热力图上各点人群密度的分散程度,具体步骤如下:
首先,提取热力图上所有点(一个点代表一个特定的景区面积,比如50平方米区域)的人群密度值。这些值将构成一个数据集,代表了景区中各个区域的预期人群数量。
其次,计算这个数据集的平均值。这个值告诉我们景区内的平均人群密度是多少。理论上,如果每个区域的人群密度都与这个平均值相近,那么景区的人群分布就相对均匀。
为了了解各区域的人群密度与平均值的偏离程度,计算每个数据点(即每个区域的人群密度)与平均值的差异。然后,将每个差异平方,并求和。最后,我们将这个总和除以数据点的数量,得到方差。方差的平方根就是标准差。
较低的标准差意味着大部分区域的人群密度都接近平均值,因此分布相对均匀。相反,较高的标准差表示某些区域的人群密度远高于或低于平均值,暗示景区内存在拥挤或空旷的区域。
通过此方法,可以得到每张热力图的均匀度。对于每个时刻计算出的均匀度,对于时间求积分,就可以求出总体一段时间内的均匀程度。这里的一段时间,通常指的是从计算时刻到场馆闭馆的时间。
可以使用这个均匀度为新进入景区的游客推荐导航路线,从而努力使人流在景区内尽可能均匀分布。也就是说,那些后续导航路线中,可以使得热力图变得尽量均匀的导航路线,便是优先推荐的导航路线。可以按照均匀程度,对于导航路线进行排序,然后对游客进行推荐。
另外,一般来说,S4中所述“人群密度超出预设的阈值”中的阈值,都并非是真正达到非常拥挤的阈值,而是对于拥挤可能产生的预警值,比如说每平方米0.2人。通过这样的预警的阈值的设定,既可以对于游客少的情况下给予游客充分的选择权利,又可以提早对导航路线进行规划,以防止可能出现的拥堵。
这里以一个虚构的景区为案例,说明本发明技术方案:
假设有一个叫做“绿野仙踪”的大型主题公园。这个公园有四大区域:魔法森林、奇幻城堡、魔法学院和童话村。
步骤S1:公园为游客提供了三种导航路线:
路线A:首先参观魔法森林,然后前往奇幻城堡,接下来是魔法学院,最后是童话村。
路线B:首先参观童话村,接着去奇幻城堡,然后是魔法森林,最后结束于魔法学院。
路线C:首先到魔法学院,接着是魔法森林,然后前往奇幻城堡,最后参观童话村。
游客Alice进入公园后,她选择了路线A。
步骤S2:基于历史数据,公园预测Alice在魔法森林会停留45分钟,在奇幻城堡会停留1小时,在魔法学院会停留1.5小时,而在童话村会停留30分钟。根据这些数据和Alice的出发时间,系统预测她的行进路线和时间。对于公园内的其他所有游客,也进行了相似的预测,生成了预测的热力图。
步骤S3:过去,公园已经收集了实际的人群热力图,并用这些数据训练了一个卷积神经网络。公园使用该模型对预测的热力图进行了修正。
步骤S4:系统注意到修正后的热力图显示,在未来1小时内,奇幻城堡的人群密度会非常高。为了避免这种过度拥挤,当新游客Bob进入公园时,系统推荐他选择路线C,因为这条路线经过的景点顺序预测出的热力图显示人流分布最为均匀,尤其是在奇幻城堡这个热门景点。
通过这种方式,公园不仅确保每位游客都能参观到所有的景点,还有效地管理了人流,使得游客之间的分布更为均匀,提高了游客的整体游览体验。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。