面粉中蛋白质含量的预测方法、装置、光谱仪及介质
文献发布时间:2024-07-23 01:35:21
技术领域
本发明实施例涉及光谱检测技术领域,具体而言,涉及一种面粉中蛋白质含量的预测方法、装置、光谱仪及介质。
背景技术
小麦面粉是烹饪和烘焙中一种非常重要的食材,具有许多重要的特性和功能。面粉中含有丰富的碳水化合物、蛋白质、维生素和矿物质等功能物质,是人类日常饮食中重要的能量来源。常见的面粉种类包括普通面粉、全麦面粉、低筋面粉、中筋面粉、高筋面粉、自发面粉等,不同功能物质在不同种类的面粉中含量也不相同,所以需要有一种快速高效的鉴别方法,对面粉中的功能物质进行检测。
传统的面粉蛋白质检测方法有凯氏定氮法,利用该方法进行蛋白质检测时的精度较高,并且对样品类型的适用性较广,但缺点是检测时间太长,整个过程至少需要两小时才能完成,并且操作复杂,还能会产生有害化学物质。
发明内容
本发明实施例提供一种面粉中蛋白质含量的预测方法、装置、光谱仪及介质,用以实现快速、方便、无损且高效的面粉蛋白质含量识别。
第一方面,本发明实施提供了一种面粉中蛋白质含量的预测方法,该方法包括:
确定待识别面粉的种类信息,其中,种类信息为如下任意一种:普通面粉、全麦面粉、低筋面粉、中筋面粉、高筋面粉或者自发面粉;
获取待识别面粉对应的待识别光谱数据,其中,待识别光谱数据是将待识别面粉经过光谱仪采集,并对采集的原始近红外光谱数据进行光谱噪声滤波后得到;
将待识别光谱数据转换为二维相关光谱数据,其中,二维相关光谱数据包括二维相关同步谱数据;
基于特征波长选取算法对待识别光谱数据进行特征波长选取,得到目标波长点;
确定与待识别面粉的种类信息对应的预设蛋白质含量预测模型,并基于预设蛋白质含量预测模型对目标波长点对应的二维相关同步谱数据进行特征识别,得到待识别面粉中的蛋白质含量信息,其中,不同种类的面粉对应的预设蛋白质含量预测模型不同,预设蛋白质含量预测模型建立了面粉中蛋白质含量与该种类的面粉对应的二维相关同步谱数据之间的关联关系。
可选的,确定待识别面粉的种类信息,包括:
将待识别面粉对应的待识别光谱数据转换为二维相关光谱图像,该二维相关光谱图像包括二维相关同步谱图像或二维相关异步谱图像;
基于预设面粉种类识别模型对二维相关光谱图像进行识别,得到待识别面粉的种类信息;
其中,预设面粉种类识别模型通过不同种类的面粉样本对应的二维相关光谱图像训练得到,预设面粉种类识别模型的结构包括九个模块,其中,第一模块为卷积层,第二模块到第八模块为MBConv卷积块结构,第九阶模块是由卷积层、平均池化层和全连接层依次连接组成。
可选的,基于特征波长选取算法对所述待识别光谱数据进行特征波长选取,得到目标波长点,包括:
第一种实现方式:
对二维相关同步谱数据进行自相关处理,得到自相关值;
依次遍历每个波长点,对于当前任意一个波长点,如果与该波长点相邻的两个波长点对应的自相关值与当前波长点的自相关值的差值均为负数,则将当前波长点及其对应的自相关值进行存储;
将存储的自相关值按照数值从大到小的顺序进行排序,并选择前M个自相关值对应的波长点作为目标波长点;
第二种实现方式:
基于组合偏最小二乘算法SIPLS,将待识别光谱数据对应的全光谱波段划分为若干等宽的子区间;
从得到的各个子区间中选取设定数目各子区间进行组合,比较所有子区间组合基于偏最小二乘法PLS模型得到的蛋白质含量的预测结果,并将该预测结果与蛋白质含量真实值之间的交叉验证均方根误差MRSECV的值最小的子区间组合作为特征波段;
第三种实现方式:
基于连续投影算法SPA,确定波长向量的投影大小,将投影向量最大的波长作为特征波长;
采用循环选取的方式,将每次选取的投影向量最大的单个波长加入特征波长组合中,使得新选入的波长与前一个选入波长之间相关度最低,直到选取一定数目的特征波长组合;
第四种实现方式:
使用冗余因子RF对待识别光谱数据进行冗余特征去除处理;
基于竞争自适应重加权CARS算法,对去除冗余特征后的光谱数据进行特征波长提取,得到目标波长。
可选的,将待识别光谱数据转换为二维相关光谱数据,包括:
按照如下公式将待识别光谱数据转换为二维相关光谱数据:
其中,m表示光谱的个数,
可选的,预设蛋白质含量预测模型为集成学习模型,该集成学习模型包括多个基学习器和一个元学习器,该集成学习模型通过如下方式训练得到:
基于光谱仪对各个种类的面粉样本进行光谱检测,得到各个种类的面粉对应的原始光谱样本数据;
对于每个种类的面粉样本,对其对应的原始光谱样本数据进行光谱预处理,得到待识别光谱样本数据;
将待识别光谱样本数据转换为二维相关光谱样本数据,该二维相关光谱样本数据包括二维相关同步谱样本数据;
基于特征波长选取算法对待识别光谱样本数据进行特征波长选取,得到目标波长点;
将目标波长点对应的二维相关同步谱样本数据作为原始样本数据集,并将原始样本数据集按比例划分为基础训练集和基础测试集;
各个基学习器按照五折交叉验证进行模型训练,训练过程中,将基础训练集中的一份数据作为原始测试集,剩下的数据作为原始训练集,其中,原始训练集用于训练每个基学习器,原始测试集用于进行蛋白质含量的预测,所有基学习器的预测结果为新的训练集;
将基础测试集输入各基学习器进行蛋白质含量的预测,并将得到的预测结果的平均值作为新的测试集;
基于新的训练集和新的测试集对元学习器进行训练,得到预设蛋白质含量预测模型;
其中,各基学习器包括:迭代偏最小二乘回归模型iPLS,弹性网络EN模型,梯度提升决策树模型GBDT和神经网络模型NN,元学习器为支持向量机模型SVM。
可选的,光谱噪声滤波处理包括:
基线校正处理、散射校正处理、平滑处理和/或尺度缩放处理。
第二方面,本发明实施例还提供了一种面粉中蛋白质含量的预测装置,该装置包括:
种类信息确定模块,用于确定待识别面粉的种类信息,其中,所述种类信息为如下任意一种:普通面粉、全麦面粉、低筋面粉、中筋面粉、高筋面粉或者自发面粉;
待识别光谱数据获取模块,用于获取所述待识别面粉对应的待识别光谱数据,其中,所述待识别光谱数据是将所述待识别面粉经过光谱仪采集,并对采集的原始近红外光谱数据进行光谱噪声滤波处理后得到;
二维数据转换模块,用于将待识别光谱数据转换为二维相关光谱数据,其中,二维相关光谱数据包括二维相关同步谱数据;
特征波长选取模块,用于基于特征波长选取算法对所述待识别光谱数据进行特征波长选取,得到目标波长点;
蛋白质含量预测模块,用于确定与待识别面粉的种类信息对应的预设蛋白质含量预测模型,并基于预设蛋白质含量预测模型对所述目标波长点对应的二维相关同步谱数据进行特征识别,得到待识别面粉中的蛋白质含量信息,其中,不同种类的面粉对应的预设蛋白质含量预测模型不同,预设蛋白质含量预测模型建立了面粉中蛋白质含量与该种类的面粉对应的二维相关同步谱数据之间的关联关系。
可选的,种类信息确定模块,具体用于:
将待识别面粉对应的待识别光谱数据转换为二维相关光谱图像,该二维相关光谱图像包括二维相关同步谱图像或二维相关异步谱图像;
基于预设面粉种类识别模型对二维相关光谱图像进行识别,得到待识别面粉的种类信息;
其中,预设面粉种类识别模型通过不同种类的面粉样本对应的二维相关光谱图像训练得到,该预设面粉种类识别模型的结构包括九个模块,其中,第一模块为卷积层,第二模块到第八模块为MBConv卷积块结构,第九阶模块是由卷积层、平均池化层和全连接层依次连接组成。
可选的,特征波长选取模块,具体用于:
第一种实现方式:
对所述二维相关同步谱数据进行自相关处理,得到自相关值;
依次遍历每个波长点,对于当前任意一个波长点,如果与该波长点相邻的两个波长点对应的自相关值与当前波长点的自相关值的差值均为负数,则将所述当前波长点及其对应的自相关值进行存储;
将存储的自相关值按照数值从大到小的顺序进行排序,并选择前M个自相关值对应的波长点作为目标波长点;
第二种实现方式:
基于组合偏最小二乘算法SIPLS,将所述待识别光谱数据对应的全光谱波段划分为若干等宽的子区间;
从得到的各个子区间中选取设定数目各子区间进行组合,比较所有子区间组合基于偏最小二乘法PLS模型得到的蛋白质含量的预测结果,并将该预测结果与蛋白质含量真实值之间的交叉验证均方根误差MRSECV的值最小的子区间组合作为特征波段;
第三种实现方式:
基于连续投影算法SPA,确定波长向量的投影大小,将投影向量最大的波长作为特征波长;
采用循环选取的方式,将每次选取的投影向量最大的单个波长加入特征波长组合中,使得新选入的波长与前一个选入波长之间相关度最低,直到选取一定数目的特征波长组合;
第四种实现方式:
使用冗余因子RF对所述待识别光谱数据进行冗余特征去除处理;
基于竞争自适应重加权CARS算法,对去除冗余特征后的光谱数据进行特征波长提取,得到目标波长。
可选的,二维数据转换模块,具体用于:
将待识别光谱数据转换为二维相关光谱数据,包括:
按照如下公式将待识别光谱数据转换为二维相关光谱数据:
其中,m表示光谱的个数,
可选的,预设蛋白质含量预测模型为集成学习模型,该集成学习模型包括多个基学习器和一个元学习器,该集成学习模型通过如下方式训练得到:
基于光谱仪对各个种类的面粉样本进行光谱检测,得到各个种类的面粉对应的原始光谱样本数据;
对于每个种类的面粉样本,对其对应的原始光谱样本数据进行光谱预处理,得到待识别光谱样本数据;
将待识别光谱样本数据转换为二维相关光谱样本数据,该二维相关光谱样本数据包括二维相关同步谱样本数据;
基于特征波长选取算法对待识别光谱样本数据进行特征波长选取,得到目标波长点;
将目标波长点对应的二维相关同步谱样本数据作为原始样本数据集,并将原始样本数据集按比例划分为基础训练集和基础测试集;
各个基学习器按照五折交叉验证进行模型训练,每个基学习器在训练过程中,将基础训练集中的一份数据作为原始测试集,剩下的数据作为原始训练集,其中,原始训练集用于训练每个基学习器,原始测试集用于进行蛋白质含量的预测,所有基学习器的预测结果为新的训练集;
将基础测试集输入各基学习器进行蛋白质含量的预测,并将得到的预测结果的平均值作为新的测试集;
基于新的训练集和所述新的测试集对元学习器进行训练,得到预设蛋白质含量预测模型;
其中,各基学习器包括:迭代偏最小二乘回归模型iPLS,弹性网络EN模型,梯度提升决策树模型GBDT和神经网络模型NN,元学习器为支持向量机模型SVM。
可选的,光谱噪声滤波处理包括:
基线校正处理、散射校正处理、平滑处理和/或尺度缩放处理。
第三方面,本发明实施例还提供了一种光谱仪,包括:
存储有可执行程序代码的存储器;
与所述存储器耦合的处理器;
所述处理器调用所述存储器中存储的所述可执行程序代码,执行本发明任意实施例所提供的面粉中蛋白质含量的预测方法。
第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本发明任意实施例所提供的面粉中蛋白质含量的预测方法。
本发明实施例提供的技术方案,通过对集成学习模型进行训练,可将单一模型的优势整合到同一个模型中,从而打破传统模型单一性的局限,提升了预测模型的准确率和泛化性。通过将训练完成的模型作为预设蛋白质含量预测模型应用于面粉蛋白质含量的检测中,可提高面粉蛋白质含量的检测精度。此外,通过为不同种类的面粉训练对应的蛋白质含量预测模型,可使得模型的应用更具有针对性,从而使得预测出的蛋白质含量的精度更高。
本发明实施例的创新点包括:
1、在对面粉蛋白质含量进行预测时,通过对原始近红外光谱数据进行光谱噪声滤波,可消除光谱数据中的随机噪声和散射效应,提高光谱数据的质量,从而提高面粉蛋白质预测结果的精度,是本发明实施例的创新点之一。
2、通过将一维待识别光谱数据转换为二维相关同步谱数据,简化分离了复杂的光谱信息,揭示了光谱数据在不同频率或波长之间的相关性,并且突出了一维光谱中难以观察到的光谱特征,提高光谱的分辨率,是本发明实施例的创新点之一。
3、通过对待识别光谱数据进行特征波长选取,可优化待识别光谱数据的数据量,降低了计算资源消耗,同时增加模型预测精度与抗干扰能力,是本发明实施例的创新点之一。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1a为本发明实施例一提供的一种预设蛋白质含量预测模型的训练过程的流程图;
图1b为本发明实施例一提供的将原始光谱样本数据经过标准正态变量变换预处理后得到的待识别光谱样本数据图;
图1c为本发明实施例一提供的将原始光谱样本数据经过移动窗口平滑预处理后得到的待识别光谱样本数据图;
图1d为本发明实施例一提供的将原始光谱样本数据经过SG平滑预处理后得到的待识别光谱样本数据图;
图1e为本发明实施例一提供的同步二维相关谱样本数据的3D示意图;
图1f为本发明实施例一提供的二维同步相关谱样本数据的自相关曲线示意图;
图1g为本发明实施例一提供的Stacking模型的训练过程示意图;
图1h为本发明实施例一提供的iPLS模型输出的面粉蛋白质预测值与实际值的对比效果图;
图1i为本发明实施例一提供的EN模型输出的面粉蛋白质预测值与实际值的对比效果图;
图1j为本发明实施例一提供的GBDT模型输出的面粉蛋白质预测值与实际值的对比效果图;
图1k为本发明实施例一提供的NN模型输出的面粉蛋白质预测值与实际值的对比效果图;
图1L为本发明实施例一提供的SVM模型输出的面粉蛋白质预测值与实际值的对比效果图;
图1m为本发明实施例一提供的Stacking模型输出的面粉蛋白质预测值与实际值的对比效果图;
图1n为本发明实施例一提供的不同测试对象对应的测试结果箱线图;
图2a为本发明实施例二提供的一种面粉中蛋白质含量的预测方法的流程图;
图2b为本发明实施例二提供的一种面粉种类识别模型的结构示意图;
图3为本发明实施例三提供的一种面粉中蛋白质含量的预测装置的结构框图;
图4为本发明实施例四提供的一种光谱仪的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有付出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,本发明实施例及附图中的术语 “包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。
本发明实施例公开了一种面粉中蛋白质含量的预测方法、装置、光谱仪及介质。其中,该预测方法是基于二维相关光谱特征波长选取方法,并结合集成学习模型的近红外光谱定量回归方法,该方法通过二维相关光谱理论对某种类型面粉的近红外光谱进行特征降维处理之后,利用集成学习模型对预处理后的近红外光谱数据集进行回归分析。本发明实施例中,为不同种类的面粉训练了不同的集成学习模型,即预设蛋白质识别模型。在后续利用集成学习模型进行蛋白质含量识别时,可选择与当前面粉种类对应的模型,从而有针对性地对该种面粉进行面粉蛋白质含量的识别。下面先对预设蛋白质识别模型的训练过程进行介绍,然后再对预设蛋白质识别模型的应用过程,即面粉中蛋白质含量的预测过程进行详细说明。
实施例一
图1a为本发明实施例一提供的一种预设蛋白质含量预测模型的训练过程的流程图,该训练过程可应用于面粉中蛋白质含量的预测过程,该方法包括:
S110、基于光谱仪对各个种类的面粉样本进行光谱检测,得到各个种类的面粉对应的原始光谱样本数据。
其中,面粉种类包括普通面粉、全麦面粉、低筋面粉、中筋面粉、高筋面粉或者自发面粉。本实施例中,为不同种类的面粉训练了对应的蛋白质含量预测模型。
具体的,可通过近红外光谱仪对各个种类的面粉样本分别进行光谱检测。光谱仪的波长范围为1750-2150nm,波长间隔为2 nm,每条光谱包含41个波长。在检测之前,可将仪器预热两个小时,并处于常温(25℃)下。对于每个种类别的面粉,可选取三次测量的平均光谱作为该种类的面粉对应的原始近红外光谱数据。
S120、对于每个种类的面粉样本,对原始光谱样本数据进行光谱预处理,得到待识别光谱样本数据。
本领域技术人员可以理解的是,近红外光谱在采集过程中由于光的散射、背景干扰以及仪器误差等原因,会对建立的分析模型产生影响,因此,有必要对已经获得的原始光谱数据进行预处理。其中,预处理方法主要包括基线校正、散射校正、平滑处理和尺度缩放等四类。
其中,基线校正包括一阶导数、二阶导数和小波变换等,这些方法主要是消除仪器背景干扰以及光线漂移对信号产生的影响。
散射校正主要包括多元散射校正(Multiplicative Scatter Correction,MSC)算法、标准正态变量变换(Standard Normal Variate Transformation,SNV)算法、正交信号校正法(OSC)和去趋势算法(De-trending)等,这些方法主要是为了消除由于样品颗粒不均匀及颗粒大小不同而产生的散射。图1b为本发明实施例一提供的将原始光谱样本数据经过标准正态变量变换预处理后得到的待识别光谱样本数据图。如图1b所示,经过SNV预处理,可使得光谱处于均值为0方差为1的正态分布上,从而消除了光强度的散射效应。
平滑处理包括移动窗口平滑、SG(Savitzky-Golay,一种滤波算法)平滑等,主要用于消除光谱中随机噪声产生的影响。图1c为本发明实施例一提供的将原始光谱样本数据经过移动窗口平滑预处理后得到的待识别光谱样本数据图,图1d为本发明实施例一提供的将原始光谱样本数据经过SG平滑预处理后得到的待识别光谱样本数据图,如图1c和1d所示,经过移动窗口平滑与预处理和SG平滑预处理,都能够使得原始光谱样本数据曲线更加平滑。
尺度缩放包括均值中心化、最大最小归一化、标准化和矢量归一化等,主要是通过消除尺度差异过大带来的影响。
本实施例中,根据集成学习模型的性能,可选择最适合该模型的预处理方法,例如根据实验结果比较,可选用MSC作为后续实验的预处理方法。
S130、将待识别光谱样本数据转换为二维相关光谱样本数据。
本实施例中,采用离散广义
因此,
对同步和异步的二维相关强度的乘积被定义为变量
其中,
S140、基于特征波长选取算法对待识别光谱样本数据进行特征波长选取,得到目标波长点。
其中,特征波长选取算法能够从大量波长变量中提取出与目标参数,即与蛋白质含量密切相关的波长,从而优化光谱数据集,最终以尽可能少的波长变量来表征尽可能多的目标参数信息。与全光谱建模相比,利用特征波长进行模型训练能够有效简化模型复杂度,降低计算资源消耗,同时增加模型预测精度与抗干扰能力。
示例性的,基于特征波长选取算法对光谱样本数据进行特征波长选取,得到目标波长可通过如下方式来实现:
第一种实现方式:
基于组合偏最小二乘算法(Synergy Interval Partial Least Squares,SIPLS),将待识别光谱样本数据对应的全光谱波段划分为若干等宽的子区间,然后从得到的各个子区间中选取设定数目个子区间进行组合,比较所有子区间组合基于偏最小二乘法(PartialLeast Squares,PLS)模型得到的蛋白质含量的预测结果,并将该预测结果与蛋白质含量真实值之间的交叉验证均方根误差MRSECV的值最小的子区间组合作为特征波段,即通过利用蛋白质含量预测值和真实值之间的偏差等指标反推出不同子区间组合的优劣。该SIPLS算法改善了IPLS(Incremental Partial Least Squares,间隔偏最小二乘回归)算法单一区间建模造成的特征信息丢失问题,同时考虑到了不同波段之间的相互联系以及组合建模对于定量回归模型的影响。
第二种实现方式:
基于连续投影算法(Sampling Probe Algorithm,SPA),确定波长向量的投影大小,将投影向量最大的波长作为特征波长;采用循环选取的方式,将每次选取的投影向量最大的单个波长加入特征波长组合中,使得新选入的波长与前一个选入波长之间相关度最低,直到选取一定数目的特征波长组合。SPA算法与其他特征波长选取算法相比,其最大优点是能够消除波长变量之间的共线性影响,提高建模速度和模型的稳定性。
第三种实现方式:
使用冗余因子(RF)对待识别光谱数样本据进行冗余特征去除处理,然后基于竞争自适应重加权(Competitive Adapative Reweighted Sampling,CARS)算法,对去除冗余特征后的光谱数据进行特征波长提取,得到目标波长,这样设置能够在保留重要波长的基础上去除噪声干扰,从而降低数据维度,精简模型,提高模型运行效率。
第四种实现方式:
这种方式是在将待识别光谱数据转换为二维相关同步谱样本数据后,利用基于特征波长选取算法对二维相关同步谱样本数据进行特征波长选取,具体步骤如下:
确定二维相关同步谱数据的自相关程度,得到自相关值;
依次遍历每个波长点,对于当前任意一个波长点,如果该波长点相邻的两个波长点对应的自相关值与当前波长点的自相关值的差值均为负数,则将当前波长点及其对应的自相关值进行存储;
将存储的自相关值按照数值从大到小的顺序进行排序,并选择前M个自相关值对应的波长点作为目标波长点。
采用上述方法的原因在于:由于2DCOS将光谱信号扩展到二维,使得原始光谱中的弱峰、重叠峰以及被地面和背景噪声掩盖的峰更加清晰,光谱分辨率显著提高。本实施例中,2DCOS是用来探索蛋白质含量差异较大的光谱之间的特征信息,以蛋白质含量差异作为干扰条件,选择蛋白质含量差异最大的两个样本以计算同步2DCOS及其3D图,图1e为本发明实施例一提供的二维同步相关谱样本数据的3D示意图。图1f为本发明实施例一提供的二维同步相关谱样本数据的自相关曲线示意图。如图1e所示,在同步2DCOS图中有两种类型的自相关峰和交叉峰,位于对角线上的峰值是自相关峰值,对角线外侧的交叉峰表示相应吸收峰之间的相关度。因为自动峰代表了当外部扰动应用于系统时,相应光谱区域对光谱强度变化的总体敏感性。利用2DCOS能放大差异的特性,以蛋白质含量差异为外扰绘制的二维相关同步谱的自相关曲线,如图1f所示,横坐标表示波长,纵坐标表示自相关值,本实施例中,依次遍历每个波长点,对于当前任意一个波长点,如果该波长点相邻的两个波长点对应的自相关值与当前波长点的自相关值的差值均为负数,将当前波长点及其对应的自相关值进行存储,存储点即为图1f中特征曲线的拐点,图1f中曲线的黑色峰值点即为最优选择的符合要求的特征点,即以2DCOS方法选出的特征点,这些特征点所对应的波长点为目标波长点。
S150、将目标波长点对应的二维相关同步谱样本数据作为原始样本数据集,并将原始样本数据集按比例划分为基础训练集和基础测试集。
本实施例采用集成学习模型作为面粉蛋白质含量的预测模型。集成学习通过组合多个基学习器来获得一个稳定且在各方面表现都较好的强学习器。每个基学习器为解决同一个问题,分别运用各自的机器学习算法对训练数据集进行处理,之后根据融合策略将多种不同的机器学习算法进行融合以获得预测能力更好的强学习器。集成学习模型能够结合众多机器学习算法的优点,弥补某些算法在例如运行时间效率、准确率上的缺点,并且可以通过不同的融合策略,改进预测模型的泛化能力,在有限数据条件下提高预测能力。
S160、各个基学习器按照五折交叉验证进行模型训练,在训练过程中,将基础训练集中的一份数据作为原始测试集,剩下的数据作为原始训练集。
其中,原始训练集用于训练每个基学习器,原始测试集用于进行预测,所有基学习器的预测结果为新的训练集。
S170、将原始测试集放入各基学习器进行预测,并将得到的预测结果的平均值作为新的测试集。
S180、基于新的训练集和新的测试集对元学习器进行训练,得到预设蛋白质含量预测模型。
本实施例采用集成学习模型对面粉中的蛋白质进行预测,该集成学习模型包括多个基学习器和一个元学习器,其中,各基学习器包括:迭代偏最小二乘回归模型(Incremental Partial Least Squares,iPLS),弹性网络(Elastic Ne,EN)模型,梯度提升决策树模型(Gradient Boosting Decision Trees,GBDT)和神经网络模型(NeuralNetworks,NN),元学习器为支持向量机模型(Support Vector Machines,SVM)。可选的,集成学习模型可以为Stacking模型(堆叠模型)。
具体的,图1g为本发明实施例一提供的Stacking模型的训练过程示意图,如图1g所示,对于第一级模型,分别将iPLS模型、EN模型、GBDT模型和NN模型作为四个基学习器,利用这四个基学习器对原始数据进行训练,将得到的训练集预测结果和测试集预测结果分别作为下一层学习器SVM模型(第二级模型)的输入训练集和测试集,最终训练得到预测性能更优良的强学习器。
在实验过程中,为了比较各单一模型(基学习器)与Stacking模型对面粉蛋白质含量的预测效果,可将采用相同的输入数据分别输入各单一模型和Stacking模型中,并通过各模型的预测结果,或者通过模型评估参数,判断各个模型与Stacking模型的性能。其中,模型评估参数包括相关系数
其中,
上述模型评估参数中,R
具体的,图1h为本发明实施例一提供的iPLS模型输出的面粉蛋白质预测值与实际值的对比效果图,图1i为本发明实施例一提供的EN模型输出的面粉蛋白质预测值与实际值的对比效果图,图1j为本发明实施例一提供的GBDT模型输出的面粉蛋白质预测值与实际值的对比效果图,图1k为本发明实施例一提供的NN模型输出的面粉蛋白质预测值与实际值的对比效果图,图1L为本发明实施例一提供的SVM模型输出的面粉蛋白质预测值与实际值的对比效果图,图1m为本发明实施例一提供的Stacking模型输出的面粉蛋白质预测值与实际值的对比效果图。图1h-图1m中的黑实线是一条基准线,函数式为:y = x;图中的散点的纵坐标代表了蛋白质含量的预测值,散点的横坐标表示该样本的蛋白质含量真实值。如此,当某个散点恰好落在实现上,便代表预测值与真实值相同;同理,散点偏离实线越多,预测效果便越差。如图1h-图1m所示,图1h-图1L中的散点均偏离实线较多,并且灰色的点相对于黑实线的紧凑度差别不大,即蛋白质含量的预测效果的差别不大。图1m中灰色的散点更贴近于黑实线,即表示模型预测的蛋白质含量的预测值更贴近于实际值,也即该Stacking模型预测的蛋白质含量的精度比其他单一模型所预测的蛋白质含量的精度高。
此外,通过模型评估参数的值也可得出Stacking模型预测效果更好的结论,下表1为不同模型对应的模型评估参数对比表,
表1 单一模型与Stacking模型对比
上表1中,从单一模型的评价指标看iPLS模型的拟合性能表现最好,GBDT是基于决策树构成的模型,能够寻找决策树最优的线性组合,可以灵活处理各种数据,平衡误差,减少误差值的影响。SVM通过高维空间映射能够避免过拟合问题能够提升模型的泛化性。以上5个模型在表现性能上各有优劣,但是单独预测的效果不够理想。Stacking集成模型集成了各个单一模型的优势,打破了传统模型单一性的局限,提升了预测模型的准确率和泛化性,从而表现出更好的效果。
需要说明的是,本实施例中待识别光谱数据经过2DCOS算法得到的是二维相关同步谱数据和二维相关异步谱数据。本实施例中采用的是二维相关同步谱数据作为训练样本的原因是经过实验测试,可得到基于二维相关同步谱数据得到的预测结果精度最高。具体实验过程为:将二维相关同步谱RGB图、二维相关同步谱灰度图、二维相关异步谱RGB图和二维相关异步谱灰度图分别作为测试对象,将各测试对象输入Stacking模型,并计算模型评估参数的值。图1n为本发明实施例一提供的不同测试对象对应的测试结果箱线图,如图1n所示,二维相关同步谱(包括RGB图和灰度图)的
本实施例中,通过对集成学习模型进行训练,可将单一模型的优势整合到同一个模型中,从而打破传统模型单一性的局限,提升了预测模型的准确率和泛化性。通过将训练完成的模型作为预设蛋白质含量预测模型应用于面粉蛋白质含量的检测中,可提高面粉蛋白质含量的检测精度。此外,通过为不同种类的面粉训练对应的蛋白质含量预测模型,可使得模型的应用更具有针对性,从而使得预测出的蛋白质含量的精度更高。
下面,对训练完成的预设蛋白质含量预测模型的应用过程,即利用某种类型的预设蛋白质含量预测模型对该种类面粉中蛋白质含量的预测过程进行详细介绍。
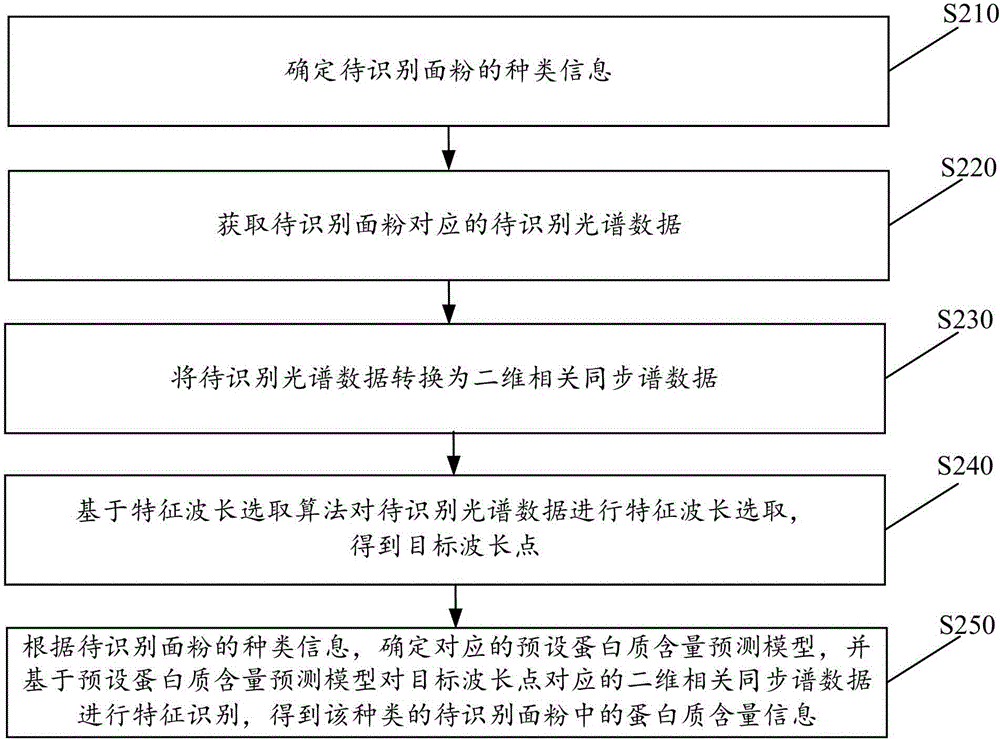
实施例二
图2a为本发明实施例二提供的一种面粉中蛋白质含量的预测方法的流程图,方法可由农产品中营养物质含量的检测装置来执行,该装置可通过软件和/或硬件的方式实现。如图2a所示,本实施例提供的方法具体包括:
S210、确定待识别面粉的种类信息。
其中,面粉种类信息包括普通面粉、全麦面粉、低筋面粉、中筋面粉、高筋面粉或者自发面粉。本实施例中,可通过如下方式确定待识别面粉的种类信息:
将待识别面粉对应的待识别光谱数据转换为二维相关光谱图像,并基于预设面粉种类识别模型对二维相关光谱图像进行特征识别,得到待识别面粉的种类信息。
其中,待识别光谱数据可以是将原始近红外光谱数据进行光谱噪声滤波后得到的近红外光谱数据。其中,光谱噪声滤波的方式可以为:标准化处理,,用于调整数据的尺度,以确保不同特征或变量在相同的数值范围内。此外,光谱噪声滤波的方式还可以为:去趋势法处理,用于消除基线漂移,通过原始光谱值与波长进行最佳线性拟合,然后从原始光谱中减去拟合值,这样可以将分析集中在原始光谱数据本身的变化上。此外,光谱噪声滤波的方式还可以为光谱均值中心化处理,多元散射校正处理或者标准正态变量变换处理等,本实施例对所采用的噪声滤波算法不作具体限定。
本实施例中,二维相关光谱图像包括二维相关同步谱图像或二维相关异步谱图像。将一维近红外光谱数据转换为二维相关光谱图像可采用2DCOS算法,具体转换过程可参照上述实施例的说明,此次不再赘述。通过将一维光谱信号扩展到二维上,可检测到某些在一维光谱中难以观察到的光谱特征,提高光谱的分辨率。同时2DCOS提供了不同组分官能团吸收峰之间的相关信息,提高了光谱的解释能力。
其中,预设面粉种类识别模型可以为EfficientNet(一种深度学习网络模型),该模型在图像分类和物体识别方面具有独特的优势,具有参数量小、识别精度高的特点,可以同时调整模型的网络深度、宽度以及图像大小,能够实现对图像的准确识别和分类。预设面粉种类识别模型通过不同种类的面粉样本对应的二维相关光谱图像训练得到。
具体的,图2b为本发明实施例二提供的一种面粉种类识别模型的结构示意图,如图2b所示,该模型的结构包括九个阶段,其中,第一阶段为卷积层,其卷积核大小为
S220、获取待识别面粉对应的待识别光谱数据。
其中,待识别光谱数据是将待识别的面粉经过光谱仪采集,并对采集的原始近红外光谱数据进行光谱噪声滤波后得到的近红外光谱数据。其中,光谱噪声滤波方法可参加上述实施例的具体说明,此处不再赘述。
S230、将待识别光谱数据转换为二维相关同步谱数据。
具体的,将待识别光谱数据转换为二维相关同步谱数据的具体计算公式如下:
其中,m表示光谱的个数,
S240、基于特征波长选取算法对待识别光谱数据进行特征波长选取,得到目标波长点。
可选的,特征波长选取算法可以为:
第一种实现方式:
确定二维相关同步谱数据的自相关程度,得到自相关值;
依次遍历每个波长点,对于当前任意一个波长点,如果该波长点相邻的两个波长点对应的自相关值与当前波长点的自相关值的差值均为负数,则将所述当前波长点及其对应的自相关值进行存储;
将存储的自相关值按照数值从大到小的顺序进行排序,并选择前M个自相关值对应的波长点作为目标波长点;
第二种实现方式:
基于组合偏最小二乘算法SIPLS,将所述待识别光谱数据对应的全光谱波段划分为若干等宽的子区间;
从得到的各个子区间中选取设定数目各子区间进行组合,比较所有子区间组合基于偏最小二乘法PLS模型得到的蛋白质含量的预测结果,并将该预测结果与蛋白质含量真实值之间的交叉验证均方根误差MRSECV的值最小的子区间组合作为特征波段;
第三种实现方式:
基于连续投影算法SPA,确定波长向量的投影大小,将投影向量最大的波长作为特征波长;
采用循环选取的方式,将每次选取的投影向量最大的单个波长加入特征波长组合中,使得新选入的波长与前一个选入波长之间相关度最低,直到选取一定数目的特征波长组合;
第四种实现方式:
使用冗余因子RF对所述待识别光谱数据进行冗余特征去除处理;
基于竞争自适应重加权CARS算法,对去除冗余特征后的光谱数据进行特征波长提取,得到目标波长。
其中,步骤S220~S240中各个算法的具体实现方式可参见上述实施例的说明,此次不再赘述。
S250、根据待识别面粉的种类信息,确定对应的预设蛋白质含量预测模型,并基于预设蛋白质含量预测模型对目标波长点对应的二维相关同步谱数据进行特征识别,得到该种类的待识别面粉中的蛋白质含量信息。
本实施例中,在对面粉蛋白质含量进行预测时,通过对原始近红外光谱数据进行光谱噪声滤波,可消除光谱数据中的随机噪声和散射效应,提高光谱数据的质量。通过将一维待识别光谱数据转换为二维相关同步谱数据,简化分离了复杂的光谱信息,揭示了光谱数据在不同频率或波长之间的相关性,并且突出了一维光谱中难以观察到的光谱特征,提高光谱的分辨率。通过对待识别光谱数据进行特征波长选取,可优化光谱数据的数据量,降低了计算资源消耗,同时增加模型预测精度与抗干扰能力。通过为不同种类的面粉选择对应的蛋白质含量预测模型,可使得模型的检测更具有针对性,从而使得蛋白质的预测结果更加精准。此外,本实施例提供的蛋白质含量预测方法无需采样昂贵的检测设备,其检测成本较低、也不会产生额外的化学有害物,能够实现快速、方便、无损确高效的检测,在蛋白质含量检测领域具有非常广泛的应用。
实施例三
图3为本发明实施例三提供的一种面粉中蛋白质含量的预测装置的结构框图,如图3所示,该装置包括:种类信息确定模块310、待识别光谱数据获取模块320、二维数据转换模块330、特征波长选取模块340和蛋白质含量预测模块350,其中,
种类信息确定模块310,用于确定待识别面粉的种类信息,其中,所述种类信息为如下任意一种:普通面粉、全麦面粉、低筋面粉、中筋面粉、高筋面粉或者自发面粉;
待识别光谱数据获取模块320,用于获取所述待识别面粉对应的待识别光谱数据,其中,所述待识别光谱数据是将所述待识别面粉经过光谱仪采集,并对采集的原始近红外光谱数据进行光谱噪声滤波处理后得到;
二维数据转换模块330,用于将所述待识别光谱数据转换为二维相关光谱数据,其中,所述二维相关光谱数据包括二维相关同步谱数据;
特征波长选取模块340,用于基于特征波长选取算法对所述待识别光谱数据进行特征波长选取,得到目标波长点;
蛋白质含量预测模块350,用于确定与所述待识别面粉的种类信息对应的预设蛋白质含量预测模型,并基于所述预设蛋白质含量预测模型对所述目标波长点对应的二维相关同步谱数据进行特征识别,得到所述待识别面粉中的蛋白质含量信息,其中,不同种类的面粉对应的预设蛋白质含量预测模型不同,所述预设蛋白质含量预测模型建立了面粉中蛋白质含量与该种类的面粉对应的二维相关同步谱数据之间的关联关系。
可选的,种类信息确定模块310,具体用于:
将待识别面粉对应的待识别光谱数据转换为二维相关光谱图像,该二维相关光谱图像包括二维相关同步谱图像或二维相关异步谱图像;
基于预设面粉种类识别模型对二维相关光谱图像进行识别,得到待识别面粉的种类信息;
其中,预设面粉种类识别模型通过不同种类的面粉样本对应的二维相关光谱图像训练得到,该预设面粉种类识别模型的结构包括九个模块,其中,第一模块为卷积层,第二模块到第八模块为MBConv卷积块结构,第九阶模块是由卷积层、平均池化层和全连接层依次连接组成。
可选的,特征波长选取模块340,具体用于:
第一种实现方式:
对所述二维相关同步谱数据进行自相关处理,得到自相关值;
依次遍历每个波长点,对于当前任意一个波长点,如果与该波长点相邻的两个波长点对应的自相关值与当前波长点的自相关值的差值均为负数,则将所述当前波长点及其对应的自相关值进行存储;
将存储的自相关值按照数值从大到小的顺序进行排序,并选择前M个自相关值对应的波长点作为目标波长点;
第二种实现方式:
基于组合偏最小二乘算法SIPLS,将所述待识别光谱数据对应的全光谱波段划分为若干等宽的子区间;
从得到的各个子区间中选取设定数目各子区间进行组合,比较所有子区间组合基于偏最小二乘法PLS模型得到的蛋白质含量的预测结果,并将该预测结果与蛋白质含量真实值之间的交叉验证均方根误差MRSECV的值最小的子区间组合作为特征波段;
第三种实现方式:
基于连续投影算法SPA,确定波长向量的投影大小,将投影向量最大的波长作为特征波长;
采用循环选取的方式,将每次选取的投影向量最大的单个波长加入特征波长组合中,使得新选入的波长与前一个选入波长之间相关度最低,直到选取一定数目的特征波长组合;
第四种实现方式:
使用冗余因子RF对所述待识别光谱数据进行冗余特征去除处理;
基于竞争自适应重加权CARS算法,对去除冗余特征后的光谱数据进行特征波长提取,得到目标波长。
可选的,二维数据转换模块330,具体用于:
将待识别光谱数据转换为二维相关光谱数据,包括:
按照如下公式将待识别光谱数据转换为二维相关光谱数据:
其中,m表示光谱的个数,
可选的,预设蛋白质含量预测模型为集成学习模型,该集成学习模型包括多个基学习器和一个元学习器,该集成学习模型通过如下方式训练得到:
基于光谱仪对各个种类的面粉样本进行光谱检测,得到各个种类的面粉对应的原始光谱样本数据;
对于每个种类的面粉样本,对其对应的原始光谱样本数据进行光谱预处理,得到待识别光谱样本数据;
将待识别光谱样本数据转换为二维相关光谱样本数据,该二维相关光谱样本数据包括二维相关同步谱样本数据;
基于特征波长选取算法对待识别光谱样本数据进行特征波长选取,得到目标波长点;
将目标波长点对应的二维相关同步谱样本数据作为原始样本数据集,并将原始样本数据集按比例划分为基础训练集和基础测试集;
各个基学习器按照五折交叉验证进行模型训练,每个基学习器在训练过程中,将基础训练集中的一份数据作为原始测试集,剩下的数据作为原始训练集,其中,原始训练集用于训练每个基学习器,原始测试集用于进行蛋白质含量的预测,所有基学习器的预测结果为新的训练集;
将基础测试集输入各基学习器进行蛋白质含量的预测,并将得到的预测结果的平均值作为新的测试集;
基于新的训练集和所述新的测试集对元学习器进行训练,得到预设蛋白质含量预测模型;
其中,各基学习器包括:迭代偏最小二乘回归模型iPLS,弹性网络EN模型,梯度提升决策树模型GBDT和神经网络模型NN,元学习器为支持向量机模型SVM。
可选的,光谱噪声滤波处理包括:
基线校正处理、散射校正处理、平滑处理和/或尺度缩放处理。
实施例四
请参阅图4,图4是本发明实施例四提供的一种光谱仪的结构示意图。如图4所示,该光谱仪可以包括:
存储有可执行程序代码的存储器701;
与存储器701耦合的处理器702;
其中,处理器702调用存储器701中存储的可执行程序代码,执行本发明任意实施例所提供的面粉中蛋白质含量的预测方法。
本发明实施例公开一种计算机可读存储介质,其存储计算机程序,其中,该计算机程序使得计算机执行本发明任意实施例所提供的面粉中蛋白质含量的预测方法。
在本发明的各种实施例中,应理解,上述各过程的序号的大小并不意味着执行顺序的必然先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本发明实施例的实施过程构成任何限定。
在本发明所提供的实施例中,应理解,“与A相应的B”表示B与A相关联,根据A可以确定B。但还应理解,根据A确定B并不意味着仅仅根据A确定B,还可以根据A和/或其他信息确定B。
另外,在本发明各实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
上述集成的单元若以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可获取的存储器中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或者部分,可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储器中,包括若干请求用以使得一台计算机设备(可以为个人计算机、服务器或者网络设备等,具体可以是计算机设备中的处理器)执行本发明的各个实施例上述方法的部分或全部步骤。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质包括只读存储器(Read-Only Memory,ROM)、随机存储器(Random Access Memory,RAM)、可编程只读存储器(Programmable Read-only Memory,PROM)、可擦除可编程只读存储器(Erasable Programmable Read Only Memory,EPROM)、一次可编程只读存储器(One-time Programmable Read-Only Memory,OTPROM)、电子抹除式可复写只读存储器(Electrically-Erasable Programmable Read-Only Memory,EEPROM)、只读光盘(CompactDisc Read-Only Memory,CD-ROM)或其他光盘存储器、磁盘存储器、磁带存储器、或者能够用于携带或存储数据的计算机可读的任何其他介质。
本领域普通技术人员可以理解:附图只是一个实施例的示意图,附图中的模块或流程并不一定是实施本发明所必须的。
本领域普通技术人员可以理解:实施例中的装置中的模块可以按照实施例描述分布于实施例的装置中,也可以进行相应变化位于不同于本实施例的一个或多个装置中。上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围。
- 基于预测模型的年龄预测方法、装置、服务器及存储介质
- 行为数据的处理方法、行为预测方法、装置、设备及介质
- 有机物中的佛波酯去除方法、高蛋白质含量有机物的制造方法、高蛋白质含量有机物、饲料的制造方法、以及饲料
- 用于减少抗体纯化过程中的宿主细胞蛋白质含量的方法和具有减少的宿主细胞蛋白质含量的抗体组合物