一种基于许可链的联邦学习激励方法及系统
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及针对区块链领域,特别是涉及一种基于许可链的联邦学习激励方法及系统。
背景技术
许可链是由若干个机构共同参与管理的区块链,每个机构都运行着一个或多个节点,只有被许可的节点才能参与投票、记账、建块。传统的机器学习将数据集中到服务端,通过运行机器学习算法训练相应的模型。当前,随着用户对隐私保护的重视,此类算法面临着巨大的隐私挑战。而联邦学习将用户数据留存在本地,仅收集模型参数,从而大大降低用户数据泄露的风险。
联邦学习系统作为一个多个客户端贡献本地数据合作训练一个统一的模型的学习方法,其局限性在于该模型只依赖于一个单一的中央服务器,容易受到服务器故障的影响以及如何公平地评估各个参与方的贡献量,如何保护数据的隐私性。
基于此,提出一种基于许可链的联邦学习激励方法及系统,解决联邦学习正确性、公平激励机制,以及提高数据的隐私性。
发明内容
有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供本发明针对目前技术发展的需求和不足之处,提供一种基于许可链的联邦学习激励方法及系统。
首先,本发明提供一种基于许可链的联邦学习激励方法,解决上述技术问题采的技术方案如下:
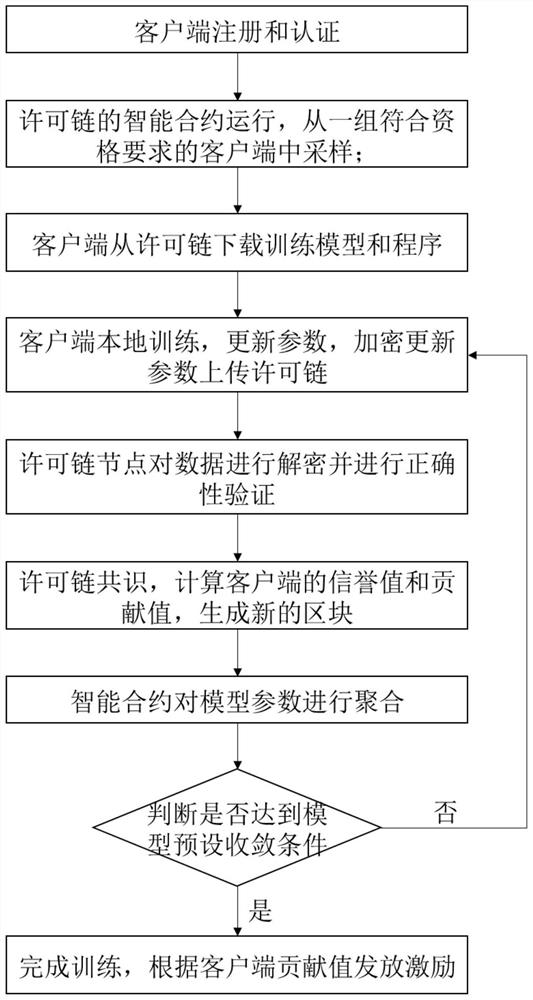
S01、客户端注册和认证,各个客户端向许可链进行注册,许可链对各个客户端进行认证,发放证书;
S02、许可链的智能合约运行,从一组符合资格要求的客户端中采样;
S03、客户端从许可链下载训练模型和程序;
S04、客户端通过执行训练程序在本地计算对模型的参数进行更新,并将更新之后的参数进行加密上传到许可链上;
S05、许可链节点收到客户端加密的数据,对数据进行解密并进行正确性验证;
S06、许可链节点进行共识,共识通过之后,计算客户端的信誉值和贡献值,并生成新的区块;
S07、智能合约对模型参数进行聚合,更新参数;
S08、智能合约判断是否达到模型预设收敛条件,如果没有则进行下一轮训练,如果到达则终止训练,根据客户端贡献值发放激励。
其次,本发明还提供一种基于许可链的联邦学习激励系统,解决上述技术问题采的技术方案如下:
一种基于许可链的联邦学习激励系统,其包括:
(1)客户端,为数据拥有方,能够独立在本地进行机器学习训练,可以是各种终端设备也可以是服务器;
(2)许可链,为由若干个机构或单位共同参与管理的区块链,能够提供存储可信交易;
(3)智能合约,为运行在许可链的程序,是一种执行合约条款的可计算交易协议,通过程序代码规定合约条款和触发条件,一旦满足出发条件合约便会自行执行,能够对外提供联邦学习服务。
具体的,所涉及客户端认证方式可以是数字证书、令牌认证等认证方式。许可链是由若干个机构共同参与管理的区块链,每个机构都运行着一个或多个节点,只有被许可的节点才能参与投票、记账、建块。智能合约是运行在许可链上,联邦学习任务是通过智能合约进行管理,用户可以根据智能合约。智能合约运行根据预设条件选取一组符合资格要求的客户端中进行采样。客户端从许可链下载训练模型和程序,客户端通过智能合约获取初始的训练模型和程序地址,下载初始的训练模型和程序之后,在本地完成初始化,使用梯度下降方法在本地进行训练。加密方式可以是RSA算法、DSA算法、ECC算法、DH算法等非对称加密算法。正确性验证是共识节点验证模型参数是否有效,并进行投票共识。共识算法使用拜占庭类共识算法,各个共识节点验证客户端模型参数的准确性,并计算更新客户端的贡献值和信誉值存储在许可链上,其中贡献值与客户端数据量相关,信誉值与贡献次数、贡献准确次数相关。智能合约将收到的模型参数进行聚合,对收到的模型参数使用可以使用加权平均,也可以是中位数取值。智能合约通过判断聚合之后模型参数是否到达收敛条件,根据客户端贡献值发放激励。
附图说明
后文将参照附图以示例性而非限制性的方式详细描述本发明的一些具体实施例。附图中相同的附图标记标示了相同或类似的部件或部分。本领域技术人员应该理解,这些附图未必是按比例绘制的。本发明的目标及特征考虑到如下结合附图的描述将更加明显,附图中:
图1为本发明基于许可链的联邦学习激励方法及系统的方法流程图。
具体实施方式
本发明本实施例提出一种基于许可链的联邦学习激励方法,该方法的实现过程包括:
S01、客户端C1、C2、C3、C4向许可链B进行注册,许可链B验证客户端C1、C2、C3、C4注册信息,通过认证之后向许可链B客户端C1、C2、C3、C4发放证书。
S02、用户U1根据联邦学习的智能合约模板创建智能合约S1,智能合约S1运行许可链B上,开始从客户端C1、C2、C3、C4采样,根据客户端的任务情况、硬件配置要求和信誉值,从客户端C1、C2、C3、C4选取客户端C1、C3进行联邦学习;
S03、客户端C1、C3从许可链B下载训练模型M和程序P,并进行本地初始化;
S04、客户端通过执行程序P在本地计算进行训练,采用梯度下降方法训练,计算梯度,梯度计算公式如下:
本地更新模型参数,并将更新之后的参数进行加密上传到许可链B上;
S05、许可链B各个节点收到客户端C1、C3加密的数据,对数据进行解密并进行正确性验证,正确性验证是共识节点对模型参数加载运行判断验证模型参数是否有效;
S06、许可链B节点进行共识,共识通过之后,计算客户端C1、C3的信誉值和贡献值,并生成新的区块;
S07、智能合约S模型M数进行聚合,聚合公式如下:
即当前模型ω
S08、智能合约S判断是否达到模型M预设收敛条件,如果没有则进行下一轮训练,如果到达则终止训练,智能合约根据客户端C1、C3贡献值发放对应的激励。
- 一种基于许可链的联邦学习激励方法及系统
- 一种基于差分进化的联邦学习激励方法和系统