数据处理装置、数据处理方法和存储介质
文献发布时间:2023-06-19 19:00:17
技术领域
本文中讨论的实施方式涉及数据处理装置、数据处理方法和存储介质。
背景技术
信息处理设备可以用于解决组合优化问题。信息处理设备将组合优化问题转换为伊辛模型(Ising model)的能量函数,伊辛模型是表示磁体中的自旋行为的模型,并且在包括在能量函数中的状态变量的值的组合中搜索使能量函数的值最小化的组合。使能量函数的值最小化的状态变量的值的组合与由一组状态变量表示的最优解或基态对应。用于在可行时间获得组合优化问题的近似解的方法的示例包括基于马尔可夫链蒙特卡罗(MCMC)方法的模拟退火(SA)方法和副本交换方法。
例如,已经提出了包括多个伊辛设备的信息处理设备。在该提议中,伊辛设备包括多个神经元电路,多个神经元电路中的每一个对一位执行处理。多个伊辛设备中的每一个反映经由其自身的神经元电路上的路由器获得的另一伊辛设备的神经元状态。
此外,还提出了一种优化设备,其通过将组合优化问题划分为多个部分问题,并且基于对部分问题的解来获得对整个问题的解来解决组合优化问题。
日本特许专利公布第2017-219948号和日本特许专利公布第2021-5282号作为相关技术被公开。
发明内容
[技术问题]
可以想到,通过使用包括在设备中的算术单元的资源来增加针对问题的解搜索处理的并行度,从而有效地执行解。此处,在通过MCMC方法使伊辛型能量函数最小化的原理中,针对该问题逐个顺序地更新状态变量的顺序处理是一种原理。因此,除非遵守MCMC方法中的顺序处理的原理,否则即使当搜索处理的并行度增加时,也不可能获得对该问题的适当解。
在一个方面中,实施方式的目的是提供一种有效地利用算术资源的数据处理装置、数据处理方法和程序。
[问题的解]
根据实施方式的一个方面,数据处理装置包括:存储单元,其存储多个副本,多个副本中的每一个指示能量函数中指示0或1的多个状态变量;以及处理单元,其并行地执行第一处理和第二处理,第一处理针对多个副本,在多个状态变量中的多个第一状态变量是改变的候选时,基于能量函数的值的改变量,改变多个第一状态变量的第一目标状态变量的值,多个副本中的每一个指示所包括的多个状态变量,多个第一状态变量属于与多个状态变量中的每一个对应的索引的第一索引范围;第二处理针对多个副本,在多个状态变量中的属于第二索引范围的多个第二状态变量是改变的候选时,基于能量函数的值的改变量,改变多个第二状态变量的第二目标状态变量的值,第二索引范围不与第一索引范围交叠,其中,在第一处理和第二处理中以相同的定时执行的多个副本中的副本彼此不同。
[发明的有利效果]
在一个方面中,可以高效地利用算术资源。
附图说明
图1是用于描述第一实施方式的数据处理装置的图;
图2是示出第二实施方式的数据处理装置的硬件示例的图;
图3是示出数据处理装置的功能示例的图;
图4是示出组中局部场更新的功能示例的图;
图5是示出流水线处理的示例的图;
图6是示出读出加权系数的示例的图;
图7A和图7B是示出数据处理装置的处理示例的流程图;
图8是示出第三实施方式的流水线处理的示例的图;
图9是示出用于存储加权系数的存储器配置的示例的图;
图10是示出加权系数存储存储器单元的示例的图;以及
图11是示出数据处理装置的停顿控制的功能示例的图。
具体实施方式
下文中,将参照附图描述本实施方式。
[第一实施方式]
将描述第一实施方式。
图1是用于描述第一实施方式的数据处理装置的图。
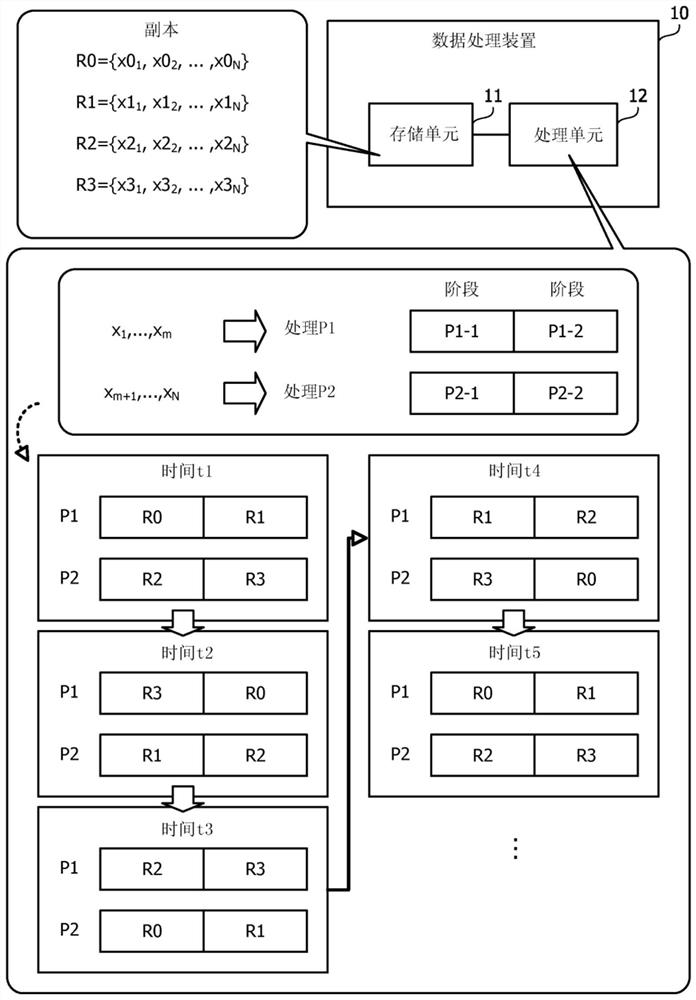
数据处理装置10通过使用马尔可夫链蒙特卡罗(MCMC)方法搜索组合优化问题的解,并且输出搜索到的解。例如,数据处理装置10使用基于MCMC方法的模拟退火(SA)方法、并行回火(PT)方法等来进行解搜索。也将PT方法称为副本交换方法。数据处理装置10包括存储单元11和处理单元12。
存储单元11可以是诸如随机存取存储器(RAM)的易失性存储设备,或者可以是诸如闪存的非易失性存储设备。存储单元11可以包括诸如寄存器的电子电路。处理单元12可以是诸如中央处理单元(CPU)、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)和图形处理单元(GPU)的电子电路。处理单元12可以是执行程序的处理器。“处理器”可以包括一组多个处理器(多处理器)。
例如,组合优化问题由伊辛型能量函数公式化,并且被使能量函数的值最小化的问题代替。可以将能量函数称为目标函数、评估函数等。能量函数包括多个状态变量。状态变量是取0或1的值的二进制变量。状态变量可以被表达为位。组合优化问题的解由多个状态变量的值表示。使能量函数的值最小化的解表示伊辛模型的基态并且对应于组合优化问题的最优解。能量函数的值被表达为能量。
伊辛型能量函数由表达式(1)表示。
[表达式1]
状态向量x具有多个状态变量作为元素,并且表示伊辛模型的状态。表达式(1)是以二次无约束二进制优化(QUBO)格式公式化的能量函数。注意,在使能量最大化的问题的情况下,使能量函数的符号相反就足够了。
表达式(1)右侧的第一项是针对可以从所有状态变量中选择的两个状态变量的所有组合,在不遗漏和重复的情况下对两个状态变量的值与加权系数的乘积进行积分。下标i和下标j是状态变量的索引。标记x
表达式(1)右侧的第二项是针对所有状态变量获得状态变量的每个偏差与值的乘积之和。标记b
当状态变量x
[表达式2]
标记h
[表达式3]
当状态变量x
[表达式4]
存储单元11保持与多个状态变量中的每一个对应的局部场h
处理单元12使用梅特罗波利斯(Metropolis)方法和吉布斯(Gibbs)方法来确定是否允许状态转变(例如,状态变量x
[表达式5]
标记β指示温度值T(T>0)的倒数(β=1/T)并且被称为逆温度。min运算符指示取自变量的最小值。表达式(5)的右上侧对应于梅特罗波利斯方法。表达式(5)的右下侧对应于吉布斯方法。处理单元12将A与均匀随机数u(关于某个索引i,0 [表达式6] ln(u)×T≤-ΔE (6) 例如,在能量变化ΔE满足均匀随机数u(0 处理单元12可以通过确定其值由多个状态变量的并行试验改变的状态变量来加速解搜索。例如,处理单元12针对属于预定索引范围的每个索引并行地计算ΔE。然后,处理单元12从各个索引中的满足用于ΔE的表达式(6)的索引中选择通过使用随机数等改变其值的状态变量的索引。预定索引范围是整个索引范围的部分索引范围。在本示例中,处理单元12针对每个索引范围执行该索引范围的并行试验(例如部分并行试验)。 此外,处理单元12通过使用多个副本来并行地对问题进行解搜索处理,多个副本中的每一个指示多个状态变量。例如,处理单元12可以对多个副本中的每一个并行地执行SA方法。替选地,处理单元12可以通过使用多个副本来执行副本交换方法。 例如,存储单元11保持副本R0、R1、R2和R3。R0={x0 处理单元12通过多个流水线对副本R0至R3中的每一个并行地执行上述部分并行试验。流水线是对每个副本顺序执行属于流水线的一系列阶段的处理。对于流水线,每个循环可以输入待处理的副本,每个循环与一个阶段的执行时间对应。流水线的数目与要经受部分并行试验的索引范围的数目匹配。处理单元12针对一个副本的多个索引范围中的每一个(例如,第一索引范围、第二索引范围、……)顺序地执行部分并行试验。在对某个副本的最后索引范围执行部分并行试验之后,处理单元12返回到对该副本的第一索引范围的部分并行试验。 在一个示例中,处理单元12并行地执行与第一流水线对应的处理P1以及与第二流水线对应的处理P2。处理P1与第一流水线(例如,第一流水线)中的一系列阶段对应。处理P2与第二流水线(例如,第二流水线)中的一系列阶段对应。向处理P1分配索引范围{1至m}。例如,向处理P1分配一组状态变量{x 处理P1和处理P2中的每一个具有相同数目的多个阶段。多个阶段包括部分并行试验中的每个过程。在一个示例中,多个阶段的数目是2。在这种情况下,例如,第一阶段是在属于相应索引范围的每个状态变量被设置为更新候选的情况下,根据每个更新候选的能量变化量来确定待更新的任何一个状态变量。第二阶段是更新通过该确定获得的待更新的一个状态变量。状态变量的更新伴随着上述局部场的更新。此外,可以进一步细分这些阶段。 处理P1包括阶段P1-1和阶段P1-2。阶段P1-1是处理P1的第一阶段。阶段P1-2是处理P1的第二阶段。第二阶段在第一阶段之后执行。在阶段P1-1和阶段P1-2中,将处理属于索引范围{1到m}的状态变量。处理P2包括阶段P2-1和阶段P2-2。阶段P2-1是处理P2的第一阶段。阶段P2-2是处理P2的第二阶段。在阶段P2-1和阶段P2-2中,将处理属于索引范围{m+1到N}的状态变量。 处理单元12在处理P1和处理P2中所包括的每个阶段中以相同的定时处理彼此不同的副本。例如,处理单元12包括算术电路,该算术电路针对处理P1和处理P2中包括的每一阶段执行阶段。例如,处理单元12在时间t1、t2、t3、t4和t5的每个定时如次处理副本R0至副本R3。注意,在时间t1至时间t5,从时间t1至时间t5的方向是时间的正方向。此外,假设时间t1是从处理单元12使用副本R0至副本R3的解搜索开始起经过了特定时间量的定时。 在时间t1,处理单元12在阶段P1-1处理副本R0并且在阶段P1-2处理副本R1。此外,处理单元12在阶段P2-1处理副本R2并且在阶段P2-2处理副本R3。 在时间t2,处理单元12在阶段P1-1处理副本R3并且在阶段P1-2处理副本R0。此外,处理单元12在阶段P2-1处理副本R1并且在阶段P2-2处理副本R2。 在时间t3,处理单元12在阶段P1-1处理副本R2并且在阶段P1-2处理副本R3。此外,处理单元12在阶段P2-1处理副本R0并且在阶段P2-2处理副本R1。 在时间t4,处理单元12在阶段P1-1处理副本R1并且在阶段P1-2处理副本R2。此外,处理单元12在阶段P2-1处理副本R3并且在阶段P2-2处理副本R0。 在时间t5,处理单元12在阶段P1-1处理副本R0并且在阶段P1-2处理副本R1。此外,处理单元12在阶段P2-1处理副本R2并且在阶段P2-2处理副本R3。 处理单元12在时间t1至时间t4对副本R0至副本R3中的每一个的整个索引范围进行部分并行试验的循环,并且在时间t5之后重复该循环的过程。当通过重复执行该过程通过SA方法或副本交换方法来完成搜索时,处理单元12输出由副本R0至副本R3中的每一个指示的多个状态变量的一组值作为解。例如,处理单元12可以输出针对副本R0至副本R3获得的四个解中具有最小能量的解作为最佳解。 以这种方式,根据数据处理装置10,并行地执行第一处理和第二处理。在第一处理中,针对多个副本执行多个阶段。多个阶段包括:确定待更新的第一状态变量,以及在属于第一索引范围的多个第一状态变量中的每一个被设置为更新候选的情况下,根据能量变化量来更新待更新的第一状态变量的值。在第二处理中,针对多个副本执行多个阶段。多个阶段包括:确定待更新的第二状态变量,以及在属于第二索引范围的多个第二状态变量中的每一个被设置为更新候选的情况下,根据能量变化量来更新待更新的第二状态变量的值。第二索引范围与第一索引范围不交叠。然后,在第一处理和第二处理中所包括的每个阶段中,以相同的定时处理彼此不同的副本。 通过该配置,数据处理装置10可以高效地利用算术资源。 例如,数据处理装置10使每个副本的处理定时移位,使得在第一处理和第二处理中所包括的每个阶段中以相同的定时处理彼此不同的副本。通过该配置,对于每个副本观察到MCMC方法中的顺序处理的原理。因此,对于多个副本,数据处理装置10可以通过在副本中的部分并行试验来适当地并行化搜索。此外,数据处理装置10可以通过使用每个副本适当地获得解。以这种方式,数据处理装置10可以高效地利用处理单元12的算术资源来高效地执行解。 此外,对于数据处理装置10来说,针对多个副本,仅保持一组整个加权系数就足够了。例如,即使当副本的数目增加时,数据处理装置10也不必增加用于保持加权系数的存储容量。 注意,虽然在第一实施方式的示例中例示了两个流水线,但是数据处理装置10可以并行地执行三个或更多个流水线。此外,一个流水线中的阶段的数目可以为3或更多。副本的数目可以是除4以外的多个数字。例如,在处理单元12并行执行三个或更多个流水线的情况下,可选的两个流水线对应于第一处理和第二处理。 [第二实施方式] 接下来,将描述第二实施方式。 图2是示出第二实施方式的数据处理装置的硬件示例的图。 数据处理装置20通过使用MCMC方法搜索组合优化问题的解,并且输出搜索到的解。数据处理装置20包括CPU 21、RAM 22、硬盘驱动器(HDD)23、GPU 24、输入接口25、介质读取器26、网络接口卡(NIC)27和加速器卡28。 CPU 21是执行程序命令的处理器。CPU 21将存储在HDD 23中的程序和数据的至少一部分加载到RAM 22中以执行程序。注意,CPU 21可以包括多个处理器核。此外,数据处理装置20可以包括多个处理器。下面描述的处理可以通过使用多个处理器或处理器核来并行地执行。此外,可以将一组多个处理器称为“多处理器”或简称为“处理器”。 RAM 22是易失性半导体存储器,其临时存储由CPU 21执行的程序和CPU 21用于算术运算的数据。注意,数据处理装置20可以包括与RAM不同类型的存储器,或者可以包括多个存储器。 HDD 23是非易失性存储设备,其存储数据以及诸如操作系统(OS)、中间件和应用软件的软件的程序。注意,数据处理装置20可以包括诸如闪存存储器或固态驱动器(SSD)的另一类型的存储设备,或者可以包括多个非易失性存储设备。 GPU 24根据来自CPU 21的命令向连接至数据处理装置20的显示器101输出图像。作为显示器101,可以使用诸如阴极射线管(CRT)显示器、液晶显示器(LCD)、等离子显示器或有机电致发光(OEL)显示器的可选类型的显示器。 输入接口25从连接至数据处理装置20的输入设备102获取输入信号,并且将输入信号输出至CPU 21。作为输入设备102,可以使用诸如鼠标、触摸面板、触摸板或跟踪球的指向设备、键盘、遥控器、按钮开关等。此外,可以将多种类型的输入设备连接至数据处理装置20。 介质读取器26是读取记录在记录介质103上的程序和数据的读取装置。作为记录介质103,例如,可以使用磁盘、光盘、磁光(MO)盘或半导体存储器。磁盘包括软盘(FD)和HDD。光盘包括致密盘(CD)和数字多功能盘(DVD)。 介质读取器26将例如从记录介质103读取的程序和数据复制到诸如RAM 22或HDD23的另一记录介质。所读取的程序例如由CPU 21执行。注意,记录介质103可以是便携式记录介质,并且有时用于程序和数据的分发。此外,可以将记录介质103和HDD 23称为计算机可读记录介质。 NIC 27是连接至网络104并且经由网络104与另一计算机通信的接口。NIC 27例如通过电缆连接至诸如交换机或路由器的通信设备。NIC 27可以是无线通信接口。 加速器卡28是通过使用MCMC方法搜索由表达式(1)的伊辛型能量函数表示的问题的解的硬件加速器。通过在固定温度下执行MCMC方法或者执行其中在多个温度之间交换伊辛模型的状态的副本交换方法,加速器卡28可以用作采样器以在相应温度下根据玻尔兹曼分布对状态进行采样。加速器卡28执行例如副本交换方法和SA方法的退火处理,其中温度值逐渐降低以求解组合优化问题。 SA方法是通过在每个温度值处根据玻尔兹曼分布对状态进行采样并且将用于采样的温度值从高温降低到低温(例如,增加逆温度β)来高效地找到最优解的方法。由于即使在低温侧(例如,即使在β大的情况下),状态也在一定程度上变化,所以即使当温度值快速下降时,也很可能发现良好的解。例如,在使用SA方法的情况下,加速器卡28在以固定温度值重复状态转变的试验一定次数之后重复降低温度值的操作。 副本交换方法是用于通过使用多个温度值独立地执行MCMC方法,并且针对在各个温度值处获得的状态适当地交换温度值的方法。通过在低温下由MCMC搜索状态空间的窄范围并且在高温下由MCMC搜索状态空间的宽范围,可以高效地找到好的解。例如,在使用副本交换方法的情况下,加速器卡28重复以下操作:在多个温度值中的每一个温度值处并行地执行状态转变的试验,并且每当执行一定数目的试验时,对于在各个温度值处获得的状态以预定的交换概率交换温度值。 加速器卡28包括FPGA28a。FPGA 28a在加速器卡28中实现搜索功能。搜索功能可以由诸如GPU或ASIC的另一类型的电子电路来实现。FPGA 28a包括存储器28b。存储器28b保持诸如用于在FPGA 28a中搜索的问题信息以及由FPGA28a搜索的解的数据。FPGA28a可以包括多个存储器,多个存储器包括存储器28b。FPGA 28a是第一实施方式的处理单元12的示例。存储器28b是第一实施方式的存储单元11的示例。注意,加速器卡28可以包括FPGA 28a外部的RAM,并且存储在存储器28b中的数据可以根据FPGA28a的处理临时保存在RAM中。 可以将搜索伊辛格式问题的解的硬件加速器(例如,加速器卡28)称为伊辛机器、玻尔兹曼机器等。 加速器卡28通过使用多个副本并行地执行解搜索。副本指示在能量函数中包括的多个状态变量。在下面的描述中,将状态变量表达为位。包含在能量函数中的每个位与整数索引相关联并且由该索引标识。 图3是示出数据处理装置的功能示例的图。 数据处理装置20包括存储器单元30、存储器单元30a、存储器单元30b和存储器单元30c、读出单元31、h计算单元32a1至h计算单元32aN、ΔE计算单元33a1至ΔE计算单元33aN、以及选择器34、选择器34a、选择器34b和选择器34c。标记N是一个副本中的位的数目。在一个示例中,N=1024。在这种情况下,例如,每个位由从1到1024的索引标识。 h计算单元32a1至h计算单元32aN指示h计算单元32a1、h计算单元32a2、……、h计算单元32a(N-1)和h计算单元32aN。省略h计算单元32a2至h计算单元32a(N-1)的说明。ΔE计算单元33a1至ΔE计算单元33aN指示ΔE计算单元33a1、ΔE计算单元33a2、……、ΔE计算单元33a(N-1)和ΔE计算单元33aN。省略ΔE计算单元33a2、……、ΔE计算单元33a(N-1)的说明。 例如,存储器单元30至存储器单元30c由包括FPGA 28a中的存储器28b的多个存储器实现。读出单元31、h计算单元32a1至h计算单元32aN、ΔE计算单元33a1至ΔE计算单元33aN、以及选择器34、选择器34a、选择器34b、选择器34c由FPGA 28a的电子电路实现。 在图3中,h计算单元32a1至h计算单元32aN用添加到它们的名称中的下标n来表示(如“hn”计算单元),以使其对应于第n位更加清楚。此外,在图3中,ΔE计算单元33a1至ΔE计算单元33aN用添加到它们的名称上的下标n来表示(如“ΔEn”计算单元),以使其对应于第n位更加清楚。 例如,h计算单元32a1和ΔE计算单元33a1对N位中的第一位执行算术运算。此外,h计算单元32ai和ΔE计算单元33ai对第i位执行算术运算。类似地,在诸如“32an”和“33an”的附图标记末尾处的数值n指示执行与第n位对应的算术运算。 此处,数据处理装置20将整个索引划分为多个索引范围,并且针对每个索引范围,执行与属于该索引范围的索引对应的每个位的反转的并行试验(例如,部分并行试验)。作为示例,数据处理装置20将整个索引划分为四个索引范围。第一索引范围是1到i。第二索引范围是i+1到j。第三索引范围是j+1到k。第四索引范围是k+1到N。在N=1024的情况下,属于每个索引范围的索引的数目可以是256。以上在FPGA 28a中描述的每个电路被分成如下的四个组G0、G1、G2和G3。 存储器单元30、h计算单元32a1至h计算单元32ai、ΔE计算单元33a1至ΔE计算单元33ai、以及选择器34属于组G0。存储器单元30a、h计算单元32a(i+1)至h计算单元32aj、ΔE计算单元33a(i+1)至ΔE计算单元33aj、以及选择器34a属于组G1。存储器单元30b、h计算单元32a(j+1)至h计算单元32ak、ΔE计算单元33a(j+1)至ΔE计算单元33ak、以及选择器34b属于组G2。存储器单元30c、h计算单元32a(k+1)至h计算单元32aN、ΔE计算单元33a(k+1)至ΔE计算单元33aN、以及选择器34c属于组G3。 在一个组中,确定是否反转状态向量中所包括的位中的任何一个位以及根据确定结果反转相应的位与该组中的一个解搜索试验对应。注意,一个试验可能不会产生位反转。重复执行一个试验。在每个组中,执行部分并行试验——h计算单元和ΔE计算单元对属于该组的每个位并行地执行算术运算——以加速算术运算。此外,如稍后将描述的,数据处理装置20通过用于多个副本的多个流水线并行地执行针对副本的部分并行试验,由此使得可以高效地使用FPGA 28a的算术资源。例如,数据处理装置20通过与组G0至组G3对应的四个流水线并行地处理多个副本。在本示例中,假设副本的数目是16。将16个副本表达为副本R0、副本R1、……、副本R15。 此处,将描述存储在存储器单元30至存储器单元30c中的信息。存储器单元30至存储器单元30c中的每一个存储用于其自身组的一个位与另一位的每个对的加权系数W={W 存储器单元30存储加权系数W 存储器单元30a存储加权系数W 存储器单元30b存储加权系数W 存储器单元30c存储加权系数W 在下文中,将通过主要例示与第一位对应的h计算单元32a1和ΔE计算单元33a1进行描述。具有相同名称的h计算单元32a2至h计算单元32aN和ΔE计算单元33a2至ΔE计算单元33aN具有相似的功能。 读出单元31从存储器单元30至存储器单元30c读出与选择器34至选择器34c提供的索引对应的加权系数W,并且将加权系数W输出至h计算单元32a1至h计算单元32aN。由于选择器34至选择器34c的数目是4,所以至多四个索引被同时提供给读出单元31。例如,读出单元31针对h计算单元32a1至h计算单元32aN中的每一个同时输出至多四个加权系数。四个加权系数与由四个选择器34至选择器34c并行处理的四个副本对应。读出单元31同时获取例如待输出至h计算单元32a1的来自W h计算单元32a1通过使用从读出单元31提供的加权系数,基于表达式(3)和表达式(4)为并行处理的四个副本中的每一个计算局部场h ΔE计算单元33a1基于表达式(2),通过使用保持在h计算单元32a1中的下一个待处理副本的局部场h 选择器34针对从ΔE计算单元33a1至ΔE计算单元33ai同时供给的每个ΔE,确定表达式(6),并且确定是否反转相应的位。例如,选择器34基于表达式(6)来确定是否允许对由ΔE计算单元33a1计算出的能量变化ΔE 此外,选择器34基于随机数随机地选择基于表达式(6)被确定为可反转的位之一,并且将与所选择的位对应的索引提供给读出单元31。 注意,选择器34可以通过将索引提供给保持与副本对应的位的存储单元来更新与索引对应的位。此外,选择器34可以通过将与索引对应的ΔE添加到能量保持单元来更新相应的副本的能量,该能量保持单元保持与对应于相应副本的当前位对应的能量。在图3中,省略了保持与每个副本对应的当前位的存储单元以及保持与每个副本的当前位对应的能量的能量保持单元。存储单元和能量保持单元可以通过例如FPGA28a中的存储器28b的存储区域来实现,或者可以通过寄存器来实现。 选择器34a至选择器34c对于它们自身的组的位也与选择器34类似地工作。 图4是示出组中局部场更新的功能示例的图。 存储器单元30包括存储器30p1、存储器30p2、存储器30p3和存储器30p4。在图4中省略了读出单元31。存储器30p1存储加权系数W 对于一个h计算单元,读出单元31从存储器30p1、存储器30p2、存储器30p3和存储器30p4中同时读出与至多四组中的位更新对应的四个加权系数,并且将四个加权系数提供给h计算单元。例如,当从选择器34至选择器34c输入待更新的四个位的索引时,读出单元31对于h计算单元31a1至h计算单元32ai中的每一个从存储器30p1至存储器30p4中的每一个读出四个加权系数,并且将四个加权系数提供给h计算单元31a1至32ai。 例如,针对由选择器34输出的待更新的位的索引,从保持在存储器30p1中的W h计算单元32a1至h计算单元32ai中的每一个通过使用所提供的至多四个加权系数,基于表达式(3)和表达式(4)并行地更新与至多四个副本的自身位对应的局部场。例如,h计算单元32a1包括h保持单元r1、选择器s11、选择器s12和选择器s13、以及加法器c1、加法器c2、加法器c3和加法器c4。 h保持单元r1保持与16个副本中的每一个对应的自身位的局部场。h保持单元r1可以包括触发器,或者可以包括每次读出一个字的四个RAM。h计算单元32a1中的自身位是索引=1的位。 选择器s11从h保持单元r1读出每个组中要进行h更新处理的副本的局部场,并且将局部场提供给加法器c1、加法器c2、加法器c3和加法器c4。选择器s11同时从h保持单元r1读出的局部场的最大数目是4。 加法器c1、加法器c2、加法器c3和加法器c4分别通过将从存储器30p1至存储器30p4读出的加权系数与选择器s11提供的局部场相加来更新局部场,并且将局部场提供给选择器s12。如上所述,加权系数的符号可以根据位的反转方向由读出单元31确定,或者可以由h计算单元32a1确定。加法器c1更新组G0中被处理的副本的局部场。加法器c2更新组G1中被处理的副本的局部场。加法器c3更新组G2中被处理的副本的局部场。加法器c4更新组G3中被处理的副本的局部场。 选择器s12将由加法器c1至加法器c4更新的相应副本的局部场存储在h保持单元r1中。 选择器s13从h保持单元r1读出组G0中接下来要处理的副本中的自身位的局部场,并且将该局部场提供给ΔE计算单元33a1。 以这种方式,h计算单元32a1可以通过选择器s11和选择器s12以及加法器c1、加法器c2、加法器c3和加法器c4同时更新与索引=1对应的至多四个副本的局部场。 另一h计算单元也具有与h计算单元32a1的功能类似的功能。例如,h计算单元32ai包括h保持单元ri、选择器si1、选择器si2和选择器si3、以及加法器c5、加法器c6、加法器c7和加法器c8。h保持单元r1保持与16个副本中的每一个对应的自身位的局部场。h计算单元32ai中的自身位是索引=i的位。 选择器si1从h保持单元ri读出每个组中要进行h更新处理的副本的局部场,并且将局部场提供给加法器c5、加法器c6、加法器c7和加法器c8。与在h保持单元r1中一样,选择器si1从h保持单元ri同时读出的局部场的最大数目是4。 加法器c5、加法器c6、加法器c7和加法器c8分别通过将从存储器30p1到存储器30p4读出的加权系数与选择器si1提供的局部场相加来更新局部场,并且将局部场提供给选择器si2。如上所述,加权系数的符号可以根据位的反转方向由读出单元31确定,或者可以由h计算单元32ai确定。加法器c5更新组G0中被处理的副本的局部场。加法器c6更新组G1中被处理的副本的局部场。加法器c7更新组G2中被处理的副本的局部场。加法器c9更新组G3中被处理的副本的局部场。 选择器si2将由加法器c5至c8更新的对应副本的局部场存储在h保持单元ri中。 选择器si3从h保持单元ri读出组G0中接下来将要处理的副本中的自身位的局部场,并且将该局部场提供给ΔE计算单元33ai。 组G1至G3也具有类似于组G0的局部场更新功能。 利用上述配置,数据处理装置20对16个副本并行执行四个流水线。 图5是示出流水线处理的示例的图。 作为示例,假设一个流水线中的阶段的数目,例如,假设阶段的数目为四。第一阶段是ΔE计算。ΔE计算是在每个组中针对属于该组的每个位并行计算ΔE的处理。第二阶段是翻转确定。翻转确定是针对所并行计算的每个位的ΔE选择要反转的一个位的处理。第三阶段是W读取。W读取是从存储器单元30至存储器单元30c读出加权系数的处理。第四阶段是h更新。h更新是基于所读出的加权系数更新与对应副本相关的局部场的处理。与h更新级并行地执行对应副本中要反转的位的反转。因此,也可以说h更新阶段是位更新阶段。 时间图201、202、203和204表示由四个流水线在每个定时逐阶段处理的副本。时间图201指示ΔE计算阶段。时间图202指示翻转确定阶段。时间图203指示W读取阶段。时间图204指示h更新阶段。图中从左到右的方向是时间的正方向。 附加至时间图201、202、203和204的相应行的G0、G1、G2和G3标识对应行所属的流水线。在对应于G0的流水线中,执行与对应于索引范围1至i的位相关的算术运算。在对应于G1的流水线中,执行与对应于索引范围i+1至j的位相关的算术运算。在对应于G2的流水线中,执行与对应于索引范围j+1至k的位相关的算术运算。在对应于G3的流水线中,执行与对应于索引范围k+1至N的位相关的算术运算。 数据处理装置20在移位了流水线的4个阶段或更多阶段的定时处开始对副本的处理,使得例如在组G0中处理的副本的h更新结束之后,在组G1中执行同一副本的处理。利用这种配置,通过使用反映先前位更新的局部场来在每个副本中执行ΔE计算,使得遵守MCMC的顺序处理的原理。 此处,局部场更新需要反映在对应副本的所有位中。因此,对四个副本的所有位同时执行加权系数的读出。如图5所例示,数据处理装置20将保持与每个组对应的加权系数的存储器划分成例如存储器30p1至30p4。因此,对应于多个副本的访问在同一存储器下不交叠。例如,在时间图203的步骤203a中,如次读出加权系数。 图6是示出读出加权系数的示例的图。 例如,组G0的存储器单元30分别在存储器30p1、30p2、30p3和30p4中分别保持加权系数W0(G0)、W0(G1)、W0(G2)和W0(G3)。组G1的存储器单元30a在四个存储器中分别保持加权系数W1(G0)、W1(G1)、W1(G2)和W1(G3)。组G2的存储器单元30b在四个存储器中分别保持加权系数W2(G0)、W2(G1)、W2(G2)和W2(G3)。组G3的存储器单元30c在四个存储器中分别保持加权系数W3(G0)、W3(G1)、W3(G2)和W3(G3)。 加权系数W0(G0)是与分配给G0的位(例如索引范围1至i的位)的更新对应的加权系数W 加权系数W0(G1)是与分配给G1的位(例如索引范围i+1至j的位)的更新对应的加权系数W 加权系数W0(G2)是与分配给G2的位(例如索引范围j+1至k的位)的更新对应的加权系数W 加权系数W0(G3)是与分配给G3的位(例如索引范围k+1至N的位)的更新对应的加权系数W 加权系数W1(G0)是与分配给G0的位的更新对应的加权系数W 加权系数W1(G1)是与分配给G1的位的更新对应的加权系数W 加权系数W1(G2)是与分配给G2的位的更新对应的加权系数W 加权系数W1(G3)是与分配给G3的位的更新对应的加权系数W 加权系数W2(G0)是与分配给G0的位的更新对应的加权系数W 加权系数W2(G1)是与分配给G1的位的更新对应的加权系数W 加权系数W2(G2)是与分配给G2的位的更新对应的加权系数W 加权系数W2(G3)是与分配给G3的位的更新对应的加权系数W 加权系数W3(G0)是与分配给G0的位的更新对应的加权系数W 加权系数W3(G1)是于分配给G1的位的更新对应的加权系数W 加权系数W3(G2)是于分配给G2的位的更新对应的加权系数W 加权系数W3(G3)是于分配给G3的位的更新对应的加权系数W 以这种方式,存储器单元30至30c对与组G0至G3对应的相应索引范围划分存储器并且保持加权系数。在步骤203a中,从保持组G0至G3的W0(G0)至W3(G0)的每个存储器中读出加权系数,用于组G0中的副本R0的位更新。此外,从保持组G0至G3中的W0(G1)至W3(G1)的每个存储器中读出加权系数,用于组G1中的副本R12的位更新。此外,从保持组G0至G3的W0(G2)至W3(G2)的每个存储器中读出加权系数,用于组G2中的副本R8的位更新。此外,从保持组G0至G3的W0(G3)至W3(G3)的每个存储器中读出加权系数,用于组G3中的副本R4的位更新。 因此,数据处理装置20可以在步骤203a中同时读出与例如以下对应的每个加权系数:分配给副本R0的G0的位的更新、分配给副本R12的G1的位的更新、分配给副本R8的G2的位的更新以及分配给副本R4的G3的位的更新,并且可以并行地更新副本R0、R12、R8和R4中的每一个的所有位的局部场。此时,用于读出加权系数的访问在同一存储器下不交叠。 接下来,将描述数据处理装置20的处理过程。 图7A和图7B是示出数据处理装置的处理示例的流程图。 (S10)CPU 21在FPGA28a中设置运算参数。例如,运算参数包括部分区域的所划分的组的数目(例如,通过划分整个索引范围而创建的组的数目),以及副本的数目M。例如,副本的数目M=16。此外,运算参数包括组之间的副本间隔。例如,副本间隔是4。将副本间隔设置成值为流水线中阶段的数目或者等于或大于阶段的数目。在这种情况下,对于以下循环处理的执行次数i,组G0至G3处理由以下数字标识的副本。 由组G0处理的副本编号G0(i)是:G0(i)=i mod M。由组G1处理的副本编号G1(i):是G1(i)=i+12mod M。由组G2处理的副本编号G2(i)是:G2(i)=i+8mod M。由组G3处理的副本编号G3(i)是:G3(i)=i+4mod M。对于整数a和b,“a mod b”指示当a除以b时的余数。根据副本间隔,确定包括在a中的+4、+8等。 (S11)FPGA28a对副本的数目执行循环处理。在循环处理中,FPGA28a以组之间的复本间隔的移位使四个组G0至G3并行运算。FPGA28a将循环处理的执行次数i的初始值设置为0,并且使执行次数i递增,直到满足i FPGA28a并行执行以下步骤S12至S12c。 (S12)ΔE计算单元33a1至33ai针对副本R(G0(i))的组G0计算ΔE (S12a)ΔE计算单元33a(i+1)至33aj针对副本R(G1(i))的组G1计算ΔE (S12b)ΔE计算单元33a(j+1)至33ak针对副本R(G2(i))的组G2计算ΔE (S12c)ΔE计算单元33a(k+1)至33aN针对副本R(G3(i))的组G3计算ΔE FPGA 28a并行执行以下步骤S13至S13c。 (S13)选择器34对副本R(G0(i))的组G0进行翻转确定。例如,选择器34执行基于ΔE (S13a)选择器34a对副本R(G1(i))的组G1进行翻转确定。例如,选择器34a执行基于ΔE (S13b)选择器34b对副本R(G2(i))的组G2进行翻转确定。例如,选择器34b执行基于ΔE (S13c)选择器34c对副本R(G3(i))的组G3进行翻转确定。例如,选择器34c执行基于ΔE FPGA28a并行执行以下步骤S14至S14c。 (S14)在步骤S13的确定中选择了要翻转的位的情况下,选择器34将所选择的位的索引输出至读出单元31,并且使处理前进至步骤S15。选择器34在步骤S13的确定中未选择要翻转的位的情况下,选择器34跳过下面的步骤S15和S16,并且进行至步骤S17。在跳过步骤S15和S16的情况下,组G0等待而不执行副本R(G0(i))的W读取和h更新,而其他组执行与步骤S15和S16对应的步骤。 (S14a)在步骤S13a的确定中选择了要翻转的位的情况下,选择器34a将所选择的位的索引输出至读出单元31,并且使处理前进至步骤S15a。选择器34a在步骤S13a的确定中未选择要翻转的位的情况下,选择器34a跳过下面的步骤S15a和S16a,并且进行至步骤S17。在跳过步骤S15a和S16a的情况下,组G1等待而不执行副本R(G1(i))的W读取和h更新,而其他组执行与步骤S15a和S16a对应的步骤。 (S14b)在步骤S13b的确定中选择了要翻转的位的情况下,选择器34b将所选择的位的索引输出至读出单元31,并且使处理前进至步骤S15b。选择器34b在步骤S13b的确定中未选择要翻转的位的情况下,选择器34b跳过下面的步骤S15b和S16b,并且进行至步骤S17。在跳过步骤S15b和S16b的情况下,组G2等待而不执行副本R(G2(i))的W读取和h更新,而其他组执行与步骤S15b和S16b对应的步骤。 (S14c)在步骤S13c的确定中选择了要翻转的位的情况下,选择器34c将所选择的位的索引输出至读出单元31,并且使处理前进至步骤S15c。选择器34c在步骤S13c的确定中未选择要翻转的位的情况下,选择器34c跳过下面的步骤S15c和S16c,并且进行至步骤S17。在跳过步骤S15c和S16c的情况下,组G3等待而不执行副本R(G3(i))的W读取和h更新,而其他组执行与步骤S15c和S16c对应的步骤。 FPGA28a并行执行以下步骤S15至S15c。 (S15)读出单元31基于从选择器34至34c中的每一个提供的索引读出副本R(G0(i))的所有组的加权系数。 (S15a)读出单元31基于从选择器34至34c中的每一个提供的索引读出副本R(G1(i))的所有组的加权系数。 (S15b)读出单元31基于从选择器34至34c中的每一个提供的索引读出副本R(G2(i))的所有组的加权系数。 (S15c)读出单元31基于从选择器34至34c中的每一个提供的索引读出副本R(G3(i))的所有组的加权系数。 FPGA 28a并行执行以下步骤S16至S16c。 (S16)h计算单元32a1至32aN对副本R(G0(i))的所有组执行LF更新,例如局部场更新。 (S16a)h计算单元32a1至32aN对副本R(G1(i))的所有组执行LF更新,例如局部场更新。 (S16b)h计算单元32a1至32aN对副本R(G2(i))的所有组执行LF更新,例如局部场更新。 (S16c)h计算单元32a1至32aN对副本R(G3(i))的所有组执行LF更新,例如局部场更新。 (S17)FPGA28a重复执行步骤S12至S16、S12a至S16a、S12b至S16b以及S12c至S16c,直到循环处理的执行次数i满足i (S18)FPGA28a确定搜索是否结束。在搜索结束的情况下,FPGA28a结束处理。在搜索未结束的情况下,FPGA 28a使处理前进至步骤S11。 注意,SA方法或副本交换方法用于由FPGA 28a进行的解搜索。在使用SA方法的情况下,FPGA28a执行在预定定时降低用于每个副本的翻转确定的温度值的处理。此外,在使用副本交换方法的情况下,FPGA28a执行在预定定时交换用于副本之间各个副本的温度值的处理。此外,在步骤S16中,FPGA28a还基于在步骤S14至S14c中由选择器34至34c输出的要被反转的位的索引,并行地执行针对对应副本的要翻转的位的更新。 当处理结束时,FPGA28a将与最终获得的每个副本对应的位串输出至CPU 21作为解。FPGA 28a可以将与每个副本对应的能量与位串一起输出至CPU 21。FPGA28a可以将通过搜索获得的解中具有最低能量的解作为最终解输出至CPU 21。 以这种方式,第二实施方式的数据处理装置20使用组G0至G3来并行地执行四个流水线,该四个流水线执行对多个副本的部分并行试验。利用这种配置,可以通过有效地利用诸如FPGA28a的算术单元的资源、同时遵守MCMC的顺序处理的原理并且确保解的收敛性,来提高针对相对大规模问题的解性能。 [第三实施方式] 接下来,将描述第三实施方式。将主要描述与上述第二实施方式不同的事项,并且将省略对共同事项的描述。 在第二实施方式中,由于包括零系数的所有加权系数被分别存储在每个组的存储器中,例如,数据处理装置20可以在固定时间内处理包括所有加权系数为非零的情况的任何情况。另一方面,不是所有的加权系数总是非零。根据该问题,一些加权系数可能是非零,而其他加权系数可能是零。在这样的情况下,从减小加权系数的存储器容量的观点来看,代替在存储器中存储值为0的加权系数,采用以下配置可能更好:通过在存储器中存储表示加权系数的位置和加权系数值的地址信息来减小存储器容量。 因此,与第二实施方式相比,在第三实施方式中,数据处理装置20在存储器中不保持值为0的加权系数的情况下提供减小存储器容量的功能。 在第三实施方式的数据处理装置20中,每个组的加权系数的读出时间根据伴随位更新而要读出的非零加权系数的数目而改变。因此,在第三实施方式中,数据处理装置20具有用于根据加权系数的读出时间使流水线停顿的机制。 同样在第三实施方式中,如在第二实施方式中,假设数据处装置20执行四个流水线作为示例。此外,一个流水线中的阶段的数目是4。副本的数目是16。 图8是示出第三实施方式的流水线处理的示例的图。 时间图211、212、213和214表示由四个流水线在每个定时逐阶段处理的副本。时间图211指示ΔE计算阶段。时间图212指示翻转确定阶段。时间图213指示W读取阶段。时间图214指示h更新阶段。图中从左到右的方向是时间的正方向。附加至时间图211、212、213和214的相应行的G0、G1、G2和G3标识对应行所属的流水线。 例如,在时间图213中的步骤213a中,假设在读出用于更新副本R2、R6、R10和R14的局部场的加权系数时,发生存储器读出竞争,并且读出用于副本R10和R14的加权系数延迟。在这种情况下,组G0至G3在W读取阶段中停顿流水线一次,并且在停顿流水线之后立即将停顿传播至h更新阶段。同样地,组G0至G3在h更新之后立即将流水线的停顿也传播到ΔE计算阶段和翻转确定阶段中。利用这种配置,数据处理装置20可以在所有副本中保持MCMC的顺序处理的原理。 接下来,将描述用于考虑加权系数的稀疏性来存储加权系数的存储器配置。 图9是示出用于存储加权系数的存储器配置的示例的图。 在一个副本中的位的数目是1024的情况下,加权系数的整体C1由具有1024个行元素和1024个列元素的矩阵表示。在1024位被分成4组每组256位的情况下,分配给一个组(例如组G0)的加权系数是整体C1的一部分C1a。部分C1a包括256个行元素和1024个列元素。 部分C1a包括加权系数W00、W10、W20和W30。加权系数W00是与分配给组G0的位的更新对应的加权系数。加权系数W10是与分配给组G1的位的更新对应的加权系数。加权系数W20是与分配给组G2的位的更新对应的加权系数。加权系数W30是与分配给组G3的位的更新对应的加权系数。 包括在部分C1a中的加权系数存储在地址存储存储器41、42、43和44以及加权系数存储存储器单元50中。地址存储存储器41、42、43和44以及加权系数存储存储器单元50由包括存储器28b的FPGA28a中的多个存储器实现。 地址存储器41至44保持指示256×1024个加权系数中的非零加权系数的存储位置的地址,并且该地址是加权系数存储存储器单元50中的地址。假设地址存储存储器41至44的数目是四,对应于组的索引范围。利用这种配置,对于四个组中的至多四个更新位,可以同时访问地址存储存储器41至44。 作为示例,假设一个加权系数的大小是2字节。在这种情况下,地址存储存储器41至44总共为四个存储器的3字节×1024个字。一个地址存储存储器是256个字。一个字在地址存储存储器中的位置(例如图9的地址存储存储器41至44的行位置)对应于更新位的索引。对应于更新位,一个地址存储器保持加权系数存储存储器单元50的逻辑地址和加权系数存储存储器单元50中的字的数目,在加权系数存储存储器单元50中,在一个组中存储最多256个加权系数。逻辑地址为2字节,并且字的数目为1字节。 加权系数存储存储器单元50存储加权系数的实质。加权系数存储存储器单元50作为整体为32字节×8K个字。作为示例,假设加权系数存储存储器单元50包括256个字×32个存储器。 例如,在包括加权系数为0的所有加权系数被保持在存储器中的情况下,需要2字节×1K×1K=2兆字节的存储器容量,但是在图9的存储器配置中,存储器容量可以被抑制到约1/2。 图10是示出加权系数存储存储器单元的示例的图。 在加权系数存储存储器单元50中,一个加权系数包括指示行中的位置的位置索引和加权系数的值。位置索引取从0至255的值,因此它是1字节。如上所述,加权系数值为2字节。此外,每行具有包括在该行中的非零加权系数的数目。该数目取从0至256的值,因此它是2字节。 加权系数存储存储器单元50以逻辑地址的低5位的交叉方式被划分成32个物理存储器(例如物理存储器)。当从四个组中对加权系数存储存储器单元50进行每行的加权系数的读出访问时,可以同时读出在同一存储器下不交叠的访问的部分。物理存储器由物理存储器编号标识。物理存储器编号取从0至31的值。此外,图10的行号对应于地址存储存储器41至44的每一行,例如,更新位的索引。行号取从L0至L1023的值。 在从逻辑地址读出加权系数并且字的数目保持在地址存储存储器中的情况下,首先,图10中的一行由加权系数存储存储器单元50的逻辑地址指定。例如,FPGA 28a通过逻辑地址的低5位来指定物理存储器的物理存储器编号。此外,FPGA 28a通过例如逻辑地址的低6位或更多位来指定物理存储器中的物理存储器地址。此外,在保持在地址存储存储器中的字的数目是多个数的情况下,FPGA 28a根据字的数目指定另一物理存储器和另一物理存储器中的物理存储器地址。然后,FPGA28a从加权系数存储存储器单元50读出对应的字,并且将读出的字的位置索引转换成属于对应组的位的索引。FPGA28a针对读出的字中不具有加权系数的索引将加权系数设置为0。 图8中例示的引起停顿的因素的示例包括加权系数存储存储器单元50中的一行包括多个字的情况,或者多个组或多个副本同时访问一个物理存储器的情况。 数据处理装置20可以具有用于上述存储器配置的以下停顿控制功能。 图11是示出数据处理装置的停顿控制的功能示例的图。 在图11中,将通过主要例示数据处理装置20中的组G0来进行描述,但是数据处理装置20中的组G1至G3也具有与组G0类似的功能。组G0的存储器单元30包括地址存储存储器41至44和加权系数存储存储器50a1、50a2、……、50a32。此外,除了图3和图4中例示的功能之外,第三实施方式的组G0还包括物理存储器地址生成单元61、62、63和64、竞争检测仲裁单元65a1、65a2、……、65a32、加权系数恢复单元66、选择器67a1至67ai、停顿信号生成单元68以及选择器69a1至69ai。 物理存储器地址生成单元61、62、63和64、竞争检测仲裁单元65a1、65a2、……、65a32、加权系数恢复单元66、选择器67a1至67ai、停顿信号生成单元68和选择器69a1至69ai由包括在FPGA28a中的电子电路实现。 设置选择器69a1至69ai来代替h计算单元32a1至32ai的选择器s13至si3。此外,在第三实施方式中,在由图11的虚线包围的部分中的加权系数读出功能对应于图3的读出单元31。 地址存储存储器41至44保持加权系数存储存储器单元50的逻辑地址和字的数目,在加权系数存储存储器单元50中针对每个组的更新位存储非零加权系数。关于来自每个组的更新位的信息被传递至每个地址存储存储器,并且从每个地址存储存储器并行读出逻辑地址和字的数目。 加权系数存储存储器50a1至50a32是保持加权系数值的32个物理存储器。加权系数存储存储器50a1、50a2、……、50a32包括在加权系数存储存储器单元50中。加权系数存储存储器50a1至50a32由物理存储器编号标识。 物理存储器地址生成单元61从地址存储存储器41获取与在组G0中处理的副本的更新位对应的逻辑地址和字的数目。物理存储器地址生成单元61基于逻辑地址和字的数目生成访问目的地的物理存储器编号和物理存储器地址。物理存储器地址生成单元61将所生成的物理存储器地址输出至与所生成的物理存储器编号对应的竞争检测仲裁单元。 物理存储器地址生成单元62从地址存储存储器42获取与在组G1中处理的副本的更新位对应的逻辑地址和字的数目。物理存储器地址生成单元62基于逻辑地址和字的数目生成访问目的地的物理存储器编号和物理存储器地址。物理存储器地址生成单元62将所生成的物理存储器地址输出至与所生成的物理存储器编号对应的竞争检测仲裁单元。 物理存储器地址生成单元63从地址存储存储器43获取与在组G2中处理的副本的更新位对应的逻辑地址和字的数目。物理存储器地址生成单元63基于逻辑地址和字的数目生成访问目的地的物理存储器编号和物理存储器地址。物理存储器地址生成单元63将所生成的物理存储器地址输出至与所生成的物理存储器编号对应的竞争检测仲裁单元。 物理存储器地址生成单元64从地址存储存储器44获取与在组G3中处理的副本的更新位对应的逻辑地址和字的数目。物理存储器地址生成单元64基于逻辑地址和字的数目生成访问目的地的物理存储器编号和物理存储器地址。物理存储器地址生成单元64将所生成的物理存储器地址输出至与所生成的物理存储器编号对应的竞争检测仲裁单元。 注意,在读出多个字的情况下,物理存储器地址生成单元61至64在多个循环中生成物理存储器地址。注意,在读出多个字的情况下,物理存储器地址生成单元61至64可以实行控制,以在单次循环中同时访问多个物理存储器,并且将仲裁委托给竞争检测仲裁单元65a1至65a32。 竞争检测仲裁单元65a1至65a32被一对一地提供给加权系数存储存储器50a1至50a32。竞争检测仲裁单元65a1至65a32基于由物理存储器地址生成单元61至64提供的物理存储器地址来检测对加权系数存储存储器50a1至50a32的访问的竞争的存在或不存在,并且在竞争中对访问进行仲裁。例如,竞争检测仲裁单元65a1基于由物理存储器地址生成单元61至64提供的物理存储器地址来检测对加权系数存储存储器50a1的访问的竞争。 在来自每个组的访问处于竞争的情况下,竞争检测仲裁单元65a1至65a32根据优先级使任何访问等待。例如,竞争检测仲裁单元65a1至65a32通过诸如以下方法来确定优先级:对具有小的物理存储器地址的编号给予优先级或者对具有要访问的大数目的字的访问给予优先级。竞争检测仲裁单元65a1至65a32将访问目的地的物理存储器地址提供给加权系数存储存储器50a1至50a32,并且使要访问的加权系数从加权系数存储存储器50a1至50a32输出至加权系数恢复单元66。 此外,当检测到访问竞争时,竞争检测仲裁单元65a1至65a32将指示检测到访问竞争的信号输出至停顿信号生成单元68。竞争检测仲裁单元65a1至65a32可以根据伴随访问竞争的加权系数的读出时间来确定使流水线停顿的循环数目,并且可以向停顿信号生成单元68通知该循环数目。 加权系数恢复单元66基于从加权系数存储存储器50a1至50a32读出的字中所包括的位置索引,恢复值为0的加权系数。 将选择器67a1至67ai一对一地提供给h计算单元32a1至32ai。选择器67a1至67ai将由加权系数恢复单元66恢复的加权系数提供给h计算单元32a1至32ai。 当基于来自竞争检测仲裁单元65a1至65a32的信号OR检测到发生访问竞争时,停顿信号生成单元68在组G0中生成停顿信号。停顿信号生成单元68将所生成的停顿信号输出至选择器69a1至69ai以及其他组的停顿信号生成单元。 此外,当基于来自组G1至G3的停顿信号OR检测到另一组中发生访问竞争时,停顿信号生成单元68生成停顿信号,并且将所生成的停顿信号输出至选择器69a1至69ai。 将选择器69a1至69ai一对一地提供给ΔE计算单元33a1至33ai。选择器69a1至69ai从h计算单元32a1至32ai获取接下来要处理的副本的局部场,并且将该局部场输出至ΔE计算单元33a1至33ai。此外,选择器69a1至69ai基于从停顿信号生成单元68提供的停顿信号来使流水线停顿。例如,选择器69a1至69ai基于停顿信号,将从h计算单元32a1至32ai向ΔE计算单元33a1至33ai的局部场的供给延迟由访问竞争引起的读出时间。 注意,在发生访问竞争的情况下,在读出某个副本的加权系数时发生延迟,并且在该延迟期间,在流水线中执行另一副本的ΔE计算阶段和翻转确定阶段。因此,组G0至G3中的每一个可以具有缓冲器,以用于保持在由于访问竞争而发生读出延迟之后执行的每个组中的翻转确定的结果。然后,可以设想,在伴随着访问竞争的加权系数的读出结束之后,组G0至G3中的每一个从缓冲器顺序地读出翻转确定的结果并且执行h更新。 以这种方式,第三实施方式的数据处理装置20在诸如FPGA 28a中的存储器28b的物理存储器中仅保持非零加权系数,并且在物理存储器中不保持具有值为0的加权系数,使得可以节省物理存储器的存储器容量。此外,数据处理装置20使用组G0至G3并行地执行进行多个副本的部分并行试验的四个流水线,并且在读出加权系数时发生对物理存储器的访问竞争的情况下允许流水线的停顿。利用这种配置,数据处理装置20可以通过有效地利用诸如FPGA28a的算术单元的资源、同时遵守MCMC的顺序处理的原理并且确保解的收敛性,来提高针对相对大规模问题的解性能。 此外,对于数据处理装置20,针对多个副本仅保持整个加权系数的一个集合就足够了。例如,即使当副本的数目增加时,数据处理装置20也不必增加用于保持加权系数的存储器容量。 第二实施方式和第三实施方式的数据处理装置20包括多个模块,多个模块将问题划分成多个区域并且执行部分并行试验,并且对多个副本执行流水线并行处理。在每个部分并行试验的模块之间,在一个模块正在处理某个副本的情况下,直到完成对副本的试用/更新处理,另一个模块才执行对副本的并行试验处理,并且在该时间期间,移位流水线的处理定时使得执行对另一个副本的处理。利用这种配置,可以有效地利用算术资源,同时遵守MCMC方法的顺序处理的原理。 此外,为了减少局部场更新处理的瓶颈,例如从每个并行试验的模块中的存储器读出加权系数的处理的瓶颈,数据处理装置20具有以下第一机制和第二机制中的一个或两个。 首先,数据处理装置20划分加权系数的存储器,使得与各个模块负责的部分区域对应的权重成为单独的存储器(单独的端口),并且可以同时读出从各个模块接收的部分区域的更新位信息的加权系数。利用这种配置,可以避免伴随加权系数的读出而对存储器的访问竞争。注意,存储器仅被划分,并且总容量与存储器未被划分的情况下的总容量相同。 其次,数据处理装置20具有用于确定系数值为0、不从存储器读出系数值为0的加权系数、仅读出非零加权系数、以及减少局部场更新处理所需的读出次数的机制。在这种情况下,用于读出加权系数的周期根据加权系数的稀疏度而变化,但是当周期长于指定数目的周期时,数据处理装置20使流水线停顿。利用这种配置,可以减小用于存储加权系数的存储器容量。 注意,在第二实施方式和第三实施方式中,作为示例,流水线的数目是四,但是流水线的数目可以是除了四之外的多个数目。此外,流水线中的阶段的数目可以是除了四之外的多个数目。此外,副本的数目可以是除了16之外的多个数目。例如,对于具有四个阶段的四个流水线,副本的数目可小于或大于16。 上述数据处理装置20例如执行以下处理。 数据处理装置20求解由包括多个状态变量的能量函数表示的问题。数据处理装置20在存储单元中保持多个副本,多个副本中的每一个指示多个状态变量。数据处理装置20并行执行第一流水线和第二流水线。第一流水线是对多个副本执行多个阶段的处理,多个阶段包括:确定要更新的第一状态变量,以及在属于第一索引范围的多个第一状态变量中的每一个被用作更新候选的情况下,根据能量函数的值的改变量来更新要更新的第一状态变量的值,所述第一索引范围是与多个状态变量中的每一个对应的索引的范围。第二流水线是对多个副本执行多个阶段的处理,多个阶段包括:确定要更新的第二状态变量,以及在属于第二索引范围的多个第二状态变量中的每一个被用作更新候选的情况下,根据能量函数的值的改变量来更新要更新的第二状态变量的值,所述第二索引范围与第一索引范围不交叠。数据处理装置20在包括在第一流水线和第二流水线中的每一个阶段中以相同的定时处理彼此不同的副本。 利用这种配置,数据处理装置20可以有效地利用诸如FPGA 28a的算术单元的资源,同时保持MCMC的顺序处理的原理。第一流水线可以表示为第一处理。第二流水线可以表示为第二处理。 注意,数据处理装置20中的每个副本的处理可以由FPGA 28a执行,或者可以由诸如CPU 21或GPU的另一算术单元执行。诸如FPGA28a或CPU21的算术单元是数据处理装置20中的处理单元的示例。此外,保持多个副本的存储单元可以由如上所述的存储器28b或寄存器来实现,或者可以由RAM 22来实现。此外,也可以说加速器卡28是“数据处理装置”的示例。 此外,数据处理装置20将关于局部场的信息保持在存储单元中,该局部场用于计算包括在多个副本的每一个中的每个状态变量的能量函数的值的改变量。基于指示包括在多个状态变量中的状态变量的对的权重的加权系数来计算局部场。例如,数据处理装置20或数据处理装置20的处理单元包括第一算术电路和第二算术电路。第一算术电路执行第一流水线,例如第一处理。第二算术电路执行第二流水线,例如第二处理。第一算术电路根据第一副本中第一状态变量的值的更新,针对属于第一副本的第一索引范围的状态变量中的每一个来更新第一局部场,并且根据第二副本中第二状态变量的值的更新,针对属于第二副本的第一索引范围的状态变量中的每一个来更新第二局部场。第二算术电路根据第一副本中第一状态变量的值的更新,针对属于第一副本的第二索引范围的状态变量中的每一个来更新第三局部场,并且根据第二副本中第二状态变量的值的更新,针对属于第二副本的第二索引范围的状态变量中的每一个来更新第四局部场。 以这种方式,数据处理装置20可以通过并行地执行伴随第一状态变量的值的更新的第一局部场和第三局部场的更新以及伴随第二状态变量的值的更新的第二局部场和第四局部场的更新来加速算术运算。在第二实施方式和第三实施方式中,组G0是第一算术电路的示例。组G1是第二算术电路的示例。替选地,可以说组G0至G3中的可选的两个组是第一算术电路和第二算术电路的示例。 此外,数据处理装置20可以包括第一存储器、第二存储器、第三存储器和第四存储器。第一存储器保持第一加权系数,该第一加权系数指示属于第一索引范围的一对状态变量的权重,并且第一加权系数用于第一局部场的更新。第二存储器保持第二加权系数,该第二加权系数指示属于第一索引范围的状态变量和属于第二索引范围的状态变量的对的权重,并且第二加权系数用于第二局部场的更新。第三存储器保持第三加权系数,该第三加权系数指示属于第二索引范围的状态变量和属于第一索引范围的状态变量的对的权重,并且第三加权系数用于第三局部场的更新。第四存储器保持第四加权系数,该第四加权系数指示属于第二索引范围的一对状态变量的权重,并且第四加权系数用于第四局部场的更新。 利用这种配置,当更新第一局部场至第四局部场时,数据处理装置20可以避免伴随着加权系数的读出而发生对存储器的访问竞争。在第二实施方式中,存储器30p1是第一存储器的示例。存储器30p2是第二存储器的示例。例如,在第二实施方式中,组G1的存储单元30a包括总共四个存储器,四个存储器包括与第三存储器和第四存储器对应的两个存储器。 替选地,数据处理装置20可以包括第一加权系数存储存储器单元、第一地址存储存储器、第二地址存储存储器、第二加权系数存储存储器单元、第三地址存储存储器和第四地址存储存储器。第一加权系数存储存储器单元保持加权系数中指示属于第一索引范围的状态变量和属于整个索引范围的状态变量的对的权重的非零加权系数。第一地址存储存储器保持根据属于第一索引范围的状态变量的更新而读出的加权系数的存储目的地地址,该存储目的地地址是第一加权系数存储存储器单元中的存储目的地地址。第二地址存储存储器保持根据属于第二索引范围的状态变量的更新而读出的加权系数的存储目的地地址,该存储目的地地址是第一加权系数存储存储器单元中的存储目的地地址。第二加权系数存储存储器单元保持加权系数中指示属于第二索引范围的状态变量和属于整个索引范围的状态变量的对的权重的非零加权系数。第三地址存储存储器保持根据属于第一索引范围的状态变量的更新而读出的加权系数的存储目的地地址,该存储目的地地址是第二加权系数存储存储器单元中的存储目的地地址。第四地址存储存储器保持根据属于第二索引范围的状态变量的更新而读出的加权系数的存储目的地地址,该存储目的地地址是第二加权系数存储存储器单元中的存储目的地地址。 以这种方式,数据处理装置20可以通过在存储器中仅保持非零加权系数而不是在存储器中保持包括加权系数为0的所有加权系数,来减少用于存储加权系数的存储器容量。 在第三实施方式中,加权系数存储存储器单元50是第一加权系数存储存储器单元的示例。例如,在第三实施方式中,为组G1提供与第二加权系数存储存储器单元对应的加权系数存储存储器单元。在第三实施方式中,地址存储器41是第一地址存储存储器的示例。此外,地址存储存储器42是第二地址存储存储器的示例。例如,在第三实施方式中,为组G1提供总共四个地址存储存储器,包括与第三地址存储存储器和第四地址存储存储器的两个存储器。 在这种情况下,第一算术电路根据第一副本中的第一状态变量的值的更新,从第一地址存储存储器获取第一加权系数的第一存储目的地地址,并且基于第一存储目的地地址,从第一加权系数存储存储器单元获取第一加权系数。同时,第一算术电路根据第二副本中第二状态变量的值的更新,从第二地址存储存储器中获取第二加权系数的第二存储目的地址,并且基于第二存储目的地址从第一加权系数存储存储器单元中获取第二加权系数。然后,第一算术电路通过第一加权系数更新第一局部场,并且通过第二加权系数更新第二局部场。此外,第二算术电路根据第一副本中的第一状态变量的值的更新,从第三地址存储存储器获取第三加权系数的第三存储目的地地址,并且基于第三存储目的地地址从第二加权系数存储存储器单元获取第三加权系数。同时,第二算术电路根据第二副本中第二状态变量的值的更新,从第四地址存储存储器中获取第四加权系数的第四存储目的地地址,并且基于第四存储目的地地址从第二加权系数存储存储器单元中获取第四加权系数。然后,第二算术电路通过第三加权系数更新第三局部场,并且通过第四加权系数更新第四局部场。 以这种方式,数据处理装置20可以通过并行地执行伴随第一状态变量的值的更新的第一局部场和第三局部场的更新以及伴随第二状态变量的值的更新的第二局部场和第四局部场的更新,来加速算术运算。 此外,第一加权系数存储存储器单元包括多个第一存储器。此外,第二加权系数存储存储器单元包括多个第二存储器。第一算术电路基于第一存储目的地地址和第二存储目的地地址来检测对多个第一存储器中的任何一个的访问竞争。然后,第一算术电路输出使第一流水线和第二流水线根据加权系数的读出时间停顿的停顿信号。例如,第一算术电路输出使第一处理和第二处理根据加权系数的读出时间停顿的停顿信号。此外,当第二算术电路基于第三存储目的地地址和第四存储目的地地址检测到对多个第二存储器中的任何一个的访问竞争时,第二算术电路输出停顿信号。 利用这种配置,即使在由于访问竞争而使加权系数的读出延迟的情况下,数据处理装置20也可以适当地保持每个副本的MCMC的顺序处理的原理。注意,第一算术电路和第二算术电路可以例如根据从其中发生访问竞争的存储器读出的字的数目来指定加权系数的读出时间,并且可以根据读出时间来确定停顿时间。例如,在第一算术电路和第二算术电路均输出停顿信号的情况下,第一算术电路和第二算术电路可以根据由于访问竞争而导致的最长读出时间来确定使第一流水线和第二流水线停顿的时间。 此外,当数据处理装置20开始通过第一流水线对第一副本进行处理时,数据处理装置20在完成通过第一流水线对第一副本的处理之后,开始通过第二流水线对第一副本进行处理。例如,当数据处理装置20开始对第一副本的第一处理时,数据处理装置20在完成对第一副本的第一处理之后开始对第一副本的第二处理。 以这种方式,数据处理装置20将每个副本的输入定时移位至第一流水线和第二流水线,使得在包括在第一流水线和第二流水线(例如,第一处理和第二处理)中的每个阶段中在相同的定时处理彼此不同的副本。利用这种配置,数据处理装置20可以有效地利用诸如FPGA 28a的算术单元的资源,同时适当地保持MCMC的顺序处理的原理。 此外,如在第二实施方式和第三实施方式中所例示的,数据处理装置20可以针对彼此不交叠的三个或更多个索引范围并行地执行进行多个阶段的三个或更多个流水线(例如,执行多个阶段的三种或更多种类型的处理)。三个或更多个流水线包括上述第一流水线和第二流水线。例如,三种或更多种类型的处理包括第一处理和第二处理。数据处理装置20在包括在三个或更多个流水线(例如,三种或更多种类型的处理)中的每一个阶段中在相同的定时处理彼此不同的副本。 利用这种配置,数据处理装置20可以有效地利用诸如FPGA 28a的算术单元的资源,同时保持MCMC的顺序处理的原理。 注意,根据第一实施方式的信息处理可以通过使处理单元12执行程序来实现。此外,根据第二实施方式的信息处理可以通过使CPU 21执行程序来实现。程序可以记录在计算机可读记录介质103中。 例如,可以通过对记录有程序的记录介质103进行分发来分发程序。替选地,程序可以存储在另一计算机中并且通过网络分发。例如,计算机可以将记录在记录介质103中或从另一计算机接收的程序存储(安装)在诸如RAM 22或HDD 23的存储设备中、从存储设备读取程序、并且执行程序。
- 数据处理方法、数据处理装置以及存储介质
- 一种数据处理方法、数据处理装置、计算机设备及可读存储介质
- 存储系统的数据处理方法、装置、系统及可读存储介质
- 数据处理方法、装置、存储介质和电子装置
- 数据处理方法、装置、存储介质和电子装置
- PET 数据处理方法、PET 数据处理装置、计算机可读的存储介质、以及数据处理方法
- 数据处理装置、数据处理系统、数据处理方法、数据处理程序及存储介质