一种基于文本图像的超分辨率方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于图像处理技术领域,具体地说是一种基于文本图像的超分辨率方法。
背景技术
文本图像的数据包含具有不同背景,高度,宽度和笔划粗细的独立单词的图像,文本和图像是网页最主要得,最常用得元素,网页的内容主要是通过文字和图像来体现的,文本图像不限于独特的语言,还涉及多语言文本。
目前,文本图像在进行图像超分辨时,大多数是使用SRB模块提取序列特征,然而,在SRB中使用Bi-LSTM从变形文本中提取序列信息时存在局限性,同时目前的方法对文本图像提取的质量较差,导致文本图像的背景和边缘模糊,降低了文本图像的识别性能。
为此,本领域技术人员提出了一种基于文本图像的超分辨率方法来解决背景技术提出的问题。
发明内容
为了解决上述技术问题,本发明提供一种基于文本图像的超分辨率方法,以解决现有技术中文本图像在进行图像分辨时,其特征在于,采用并行双向注意网络提取更多的上下文序列信息,进行全局建模,增加文本图像的高频和边缘特征,提高文本图像的识别性能等问题。
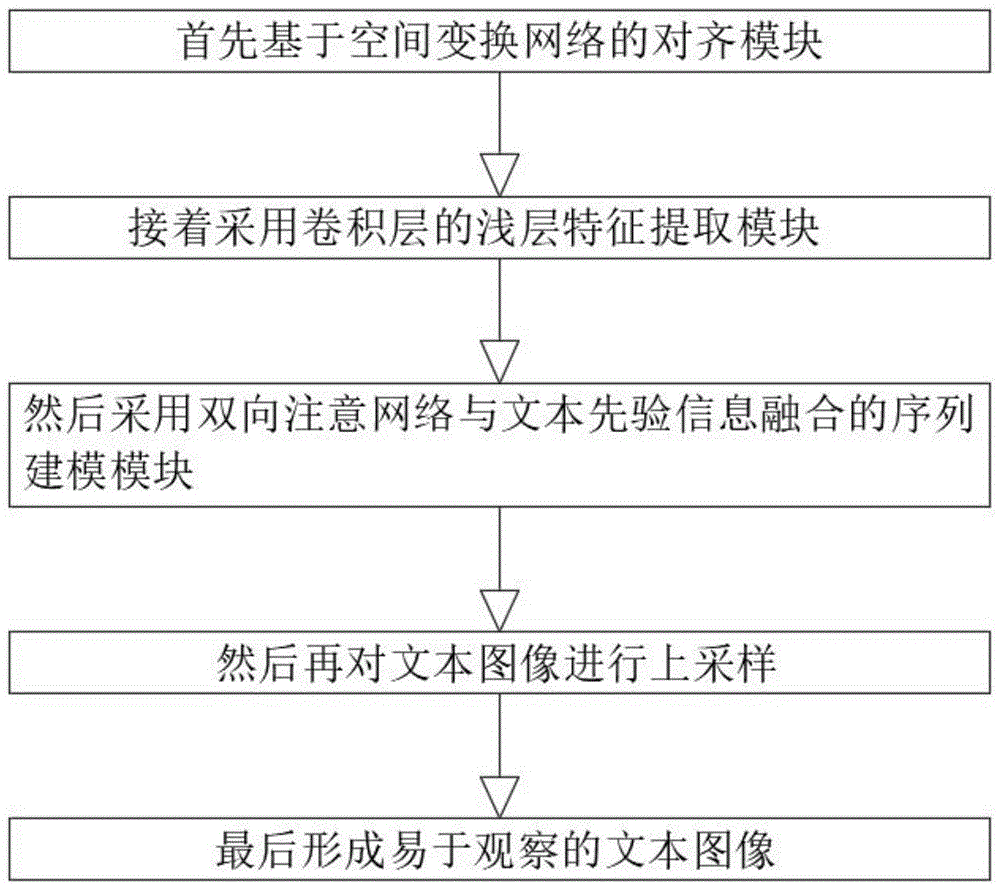
一种基于文本图像的超分辨率方法,包括以下步骤:
S1、首先基于空间变换网络的对齐模块;
S2、接着采用卷积层的浅层特征提取模块;
S3、然后采用双向注意网络与文本先验信息融合的序列建模模块;
S4、然后再对文本图像进行上采样;
S5、最后形成易于观察的文本图像。
优选的,所述S1详细的说:采用空间变换网络STN处理TextZoom数据解决由于人为抖动造成的像素不对齐问题。
优选的,所述S2详细的说:首先采用9×9的卷积进行浅层特征提取,可得到浅层特征F
优选的,所述S3详细的步骤如下:
S301、首先采用两个卷积层提取图像特征F
S301、接着将提取到的图像特征F
S301、接着再根据水平和垂直方向上的信息分别用MDTA-H模块和MDTA-V模块进行建模;
S301、然后用通道注意力机制集成来自不同方向上的全局上下文信息,给不同通道上的相关信息动态加权;
S301、然后再采用Restomer中的GDFN利用不同层级的信息,恢复了更多的高频细节;
S301、最后每一个PBAM都与文本先验分支中生成的文本先验与每个PBAM模块进行有效融合。
优选的,所述MDTA-H模块具体的说:
A、首先对输入特征图X∈R
B、接着在不同水平方向上取特征图的平均值,以获得水平方向上的全局上下文信息X′∈R
C、然后将Y输入到三个不同的分支中;
D、然后先采用1×1逐点卷积在不同特征通道上实现水平方向上下文信息的像素级聚合,再采用1×3深度卷积在水平方向上编码通道级的空间上下文信息。这两步强调局部水平方向上下文信息的聚合,得到了Q(查询),K(键),andV(值)
E、接着采用重塑操作得到
F、然后将
G、然后再与
H、最后经过一个1×1的卷积层和残差学习促进网络生成水平方向上隐式编码的全局上下文注意力特征图
优选的,所述MDTA-V模块具体的说:
a、首先对输入特征图X∈R
b、接着在不同垂直方向上取特征图的平均值,以获得垂直方向上的全局上下文信息X″∈R
c、然后将Y输入到三个不同的分支中;
d、然后先采用1×1的逐点卷积在不同特征通道上实现垂直方向上下文信息的像素级聚合,再采用3×1深度卷积在垂直方向上编码通道级的空间上下文信息。这两步强调局部垂直方向上下文信息的聚合,得到了Q(查询),K(键),andV(值)
e、接着采用重塑操作得到
f、然后将
g、然后再与
h、最后经过一个1×1的卷积层和残差学习促进网络生成垂直方向上隐式编码的全局上下文注意力特征图
优选的,所述S4详细的说:首先采用Pixelshuffle进行上采样操作,然后再经过一个9×9的卷积层f
优选的,所述S5详细的说:为了降低文本识别器的固有缺点,首先用HR图像作为另一个文本识别器的输入,接着用HR图像输出的类别概率序列监督LR图像概率序列的生成,最后重建最终的I
与现有技术相比,本发明具有如下有益效果:
本发明通过采用PBAM方法,有利于从文本图像中提取全局序列信息,并可以快速插入到其他网络模型中,同时该方法更好地恢复了文本图像的质量,使文本图像的背景和边缘更加清晰,更有利于提高文本识别性能。
附图说明
图1为本发明基于文本图像的超分辨率方法流程图;
图2为本发明文本先验指导的并行双向注意网络示意图;
图3为本发明并行双向注意力模块的体系结构示意图;
图4为本发明的并行多Dconv头转置注意力示意图;
图5为本发明的通道注意力示意图;
图6为本发明的可视化比较结果示意图。
具体实施方式
下面结合附图和实施例对本发明的实施方式作进一步详细描述。以下实施例用于说明本发明,但不能用来限制本发明的范围。
如图1至图6所示:
实施例:本发明提供一种基于文本图像的超分辨率方法,包括以下步骤:
S1、首先基于空间变换网络的对齐模块:采用空间变换网络STN处理TextZoom数据解决由于人为抖动造成的像素不对齐问题;
S2、接着采用卷积层的浅层特征提取模块:首先采用9×9的卷积进行浅层特征提取,可得到浅层特征F
S3、然后采用双向注意网络与文本先验信息融合的序列建模模块:首先采用两个卷积层提取图像特征F
具体的,所述MDTA-H模块具体的说:
A、首先对输入特征图X∈R
B、接着在不同水平方向上取特征图的平均值,以获得水平方向上的全局上下文信息X′∈R
C、然后将Y输入到三个不同的分支中;
D、然后先采用1×1逐点卷积在不同特征通道上实现水平方向上下文信息的像素级聚合,再采用1×3深度卷积在水平方向上编码通道级的空间上下文信息。这两步强调局部水平方向上下文信息的聚合,得到了
E、接着采用重塑操作得到
F、然后将
G、然后再与
H、最后经过一个1×1的卷积层和残差学习促进网络生成水平方向上隐式编码的全局上下文注意力特征图
具体的,所述MDTA-V模块具体的说:
a、首先对输入特征图X∈R
b、接着在不同垂直方向上取特征图的平均值,以获得垂直方向上的全局上下文信息X″∈R
c、然后将Y输入到三个不同的分支中;
d、然后先采用1×1的逐点卷积在不同特征通道上实现垂直方向上下文信息的像素级聚合,再采用3×1深度卷积在垂直方向上编码通道级的空间上下文信息。这两步强调局部垂直方向上下文信息的聚合,得到了
e、接着采用重塑操作得到
f、然后将
g、然后再与
h、最后经过一个1×1的卷积层和残差学习促进网络生成垂直方向上隐式编码的全局上下文注意力特征图
S4、然后再对文本图像进行上采样:首先采用Pixelshuffle进行上采样操作,然后再经过一个9×9的卷积层f
S5、最后形成易于观察的文本图像:首先用HR图像作为另一个文本识别器的输入,接着用HR图像输出的类别概率序列监督LR图像概率序列的生成,最后重建最终的I
下面对本发明实施例提供的一种基于文本图像的超分辨率方法进行具体说明。
如图2所示,本文所提出的TPGBA以TPGSR为基线,由SR和文本先验(Text Prior,TP)两个分支组成。接下来,我们将分别介绍这两个分支。
SR分支是TPGBA的主分支,主要分为四个部分:对齐模块、浅层特征提取模块、序列建模模块、上采样模块。TPGBA网络首先将低分辨率文本图像I
F
f
F
f
F
F
I
H
TP分支中我们使用经过双线性插值后的低分辨率文本图像
H
为了进一步的探究文本图像的超分辨率方法,做出如下叙述:
目前,大多数STISR方法都利用TSRN网络中提出的SRB进行序列建模。SRB通过结合CNN和RNN有效地提取序列特征。然而,最近的研究表明,在序列建模能力方面,基于transformer的方法优于CNN和RNN方法的组合。因此,我们为STISR方法的序列特征提取阶段设计了一个PBAM。在这个模块中,我们用一个高效的transformer取代了SRB中的双向长短期记忆网络(Bi-LSTM)。利用自注意机制在通道维度上建立长程依赖关系,获得更多的全局序列信息。
如图3所示,我们的PBAM主要由两部分组成。第一部分是提取图像特征F
表示通过第i个PBAM的特征图,f
我们以提取的图像特征F
F
F
其中H
为了最大限度地利用不同方向的序列上下文信息,我们使用CA机制融合来自不同方向的全局上下文信息,并动态加权不同通道上的相关信息。此外,我们采用Restomer的GDFN,通过利用不同级别的信息来恢复更多高频细节。
f
其中F
如图4的所示,为了获取到文本图像字符间、字符内的全局上下文序列信息。本文对Restomer中的MDTA模块进行改进,提出了并行的MDTA-H和MDTA-V,分别在水平和垂直方向上计算通道维度的互协方差。我们具体介绍MDTA-H。
首先,我们对输入特征图X∈R
Y=LN(Mean(X)) (1)
LN(·)表示层归一化,Mean(·)表示求均值操作。接下来,将Y输入到三个不同的分支中。首先采用1×1逐点卷积在不同特征通道上实现水平方向上下文信息的像素级聚合,然后采用1×3深度卷积在水平方向上编码通道级的空间上下文信息。这两步操作强调水平方向上局部上下文信息的聚合,得到
表示逐点卷积,/>
其中,α是一个可学习的缩放系数。H
与MDTA-H不同,MDTA-V是在垂直方向上编码通道级的空间上下文信息。为了获取垂直方向的上下文信息,在输入特征图X∈R
表示垂直方向上隐式编码的全局上下文注意力特征图。
如图5所示,利用注意力机制,通过对不同的位置动态加权再输出。对重要的区域给予比较大的权重,不重要的区域给予较小的权重,从而突出对网络有用的信息。因为我们提出的MDTA-H和MDTA-V是在通道维度上对全局上下文信息进行建模,所以我们采用通道注意力机制有效融合水平、垂直方向上的全局上下文信息。
通道注意力首先通过全局平均池化将二维特征图H×W×C压缩为一维特征向量1×1×C。然后使用两个全连接层将特征向量的通道数减少为原来的
由上可知,该基于文本图像的超分辨率方法功能如下:
1、PBAM在自然场景下文本图像超分辨率的有效性
大多数现有方法使用SRB模块提取序列特征,如TSRN、TPGSR和TATT,这几种方法都是不同时期的SOTA模型。然而,在SRB中使用Bi-LSTM从变形文本中提取序列信息时存在局限性;因此,我们用我们提出的PBAM取代了上述网络中的SRB模块。为了证明PBAM的有效性,表1为将PBAM集成到其他算法上的文本识别精确度比较,在ASTER和CRNN文本识别器上进行实验。
表1
由上可知,与SRB相比,PBAM带来了显著的性能改进。它有利于从文本图像中提取全局序列信息,并可以快速插入到其他网络模型中。
2、与其他算法的比较
表2为本发明算法与其他算法在TextZoom数据集上文本识别精确度的比较。
表2
由上表可知,我们的方法优于基线模型TPGSR,将三个识别器模型的性能分别提高了0.72%至3.47%、0.21%至2.91%和0.49%至2.39%。与SOTA模型TATT相比,我们在ASTER和MORAN识别器上分别实现了0.47%至0.88%和0.24%至2.61%的性能改进,在CRNN识别器上,我们在easy测试集上的性能超过了0.03%,在medium和hard测试集上实现了类似的性能。
为了评估我们方法的全面性,表3为本算法与其他算法在TextZoom公开数据集上PSNR和SSIM评价指标比较。
表3
TPGBA使用自注意方法来建立与远处像素信息之间的依赖关系,从而更容易获得所有像素信息。结合图6,结果表明,本发明的方法更好地恢复了文本图像的质量,使文本图像的背景和边缘更加清晰,更有利于提高文本识别性能。
本发明的实施例是为了示例和描述起见而给出的,尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 一种基于文本辅助的文本图像超分辨率重建方法
- 一种基于条件生成对抗网络的文本图像超分辨率重建方法