一种基于Bert Bilstm CRF模型的电网主设备命名实体识别方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及电力认知智能技术领域,特别是一种基于Bert Bilstm CRF模型的电网主设备命名实体识别方法。
背景技术
命名实体识别方法的目的是使用人工智能技术以一种自动化的方式提取文本信息中对应的实体、属性等信息,并将这些信息作为知识图谱中的节点进行存储。
命名实体识别的典型方法包括基于特征的方法和神经网络的方法。基于特征的方法通过预先标注好的语料训练模型,使模型学习到某个字或词作为实体组成部分的概率,进而计算一个候选字段作为实体的概率值;神经网络模型则可以自动地从文本中对有效特征进行表示和捕获,进而完成命名实体识别。典型的实体抽取方法包括隐马尔可夫模型、条件随机场及Bilstm模型等。现有的技术只关注特征的识别,并未对通用领域词汇和专业领域词汇进行区分,也忽略了文本作为有序的输入应采用更合适的序列模型。传统方法中主要关注通用领域的命名实体识别,在电网专业领域的泛化效果差,难以实现对电网非结构化数据的识别和转化。
本发明聚焦于电网领域主设备的缺陷描述,针对电网主设备这一专业领域开展了自动实体识别的研究,采用Bert这一预训练语言模型对电网专业词汇进行训练,有效的提升了电网领域文本的特征捕获能力,并结合Bilstm-CRF序列标注模型,兼顾到了文本数据的序列属性,有效提升了电网专业领域文本的结构化效率。本发明可以根据基层运检工人对设备的情况描述,即可有效提取出文本内的关键信息,并将信息作为实体属性构建成知识图谱,大大提升了设备运检报告的归档效率。
发明内容
本发明的目的在于提供一种基于Bert Bilstm CRF模型的电网主设备命名实体识别方法,可以实现对电网领域的缺陷描述文本进行自动化的实体识别和抽取,并根据构建的本体关系图,将文本转换成电网缺陷知识图谱,实现数据的结构化存储。
为实现上述目的,本发明的技术方案是:一种基于Bert Bilstm CRF模型的电网主设备命名实体识别方法,包括如下步骤:
(1)收集电网领域的文本数据,对非结构化数据进行数据清洗和预处理;
(2)对本体进行设计,规定标注规范和文本中包含的实体类型;
(3)对文本数据进行标注,导出标注结果得到jsonl文件,文件中包含文本的内容及标签,标签信息为文本中该标签实体的开始和结束下标;
(4)对jsonl文件中的数据进行BIO标注格式的转换,生成BIO形式的数据,该数据格式用于Bert模型输入,B代表实体开头的字符,I代表实体的内部,O代表其他,即实体外部,非实体的部分;
(5)将BIO形式的数据进行测试集和训练集的划分,使用交叉验证的方法进行划分;
(6)使用预训练的Bert模型对数据进行特征提取,获得文本数据的向量表示,即通过Bilstm模型对序列文本数据进行特征提取,使用CRF模型对Bilstm模型输出的结果进行处理,捕捉实体间的关系和约束,生成实体抽取的结果;
(7)对模型进行测试,评估指标包括准确率、召回率和F1值,并使用不同的策略达到更好的训练结果。
相较于现有技术,本发明具有以下有益效果:本发明可以实现对电网领域的缺陷描述文本进行自动化的实体识别和抽取,并根据构建的本体关系图,将文本转换成电网缺陷知识图谱,实现数据的结构化存储。
附图说明
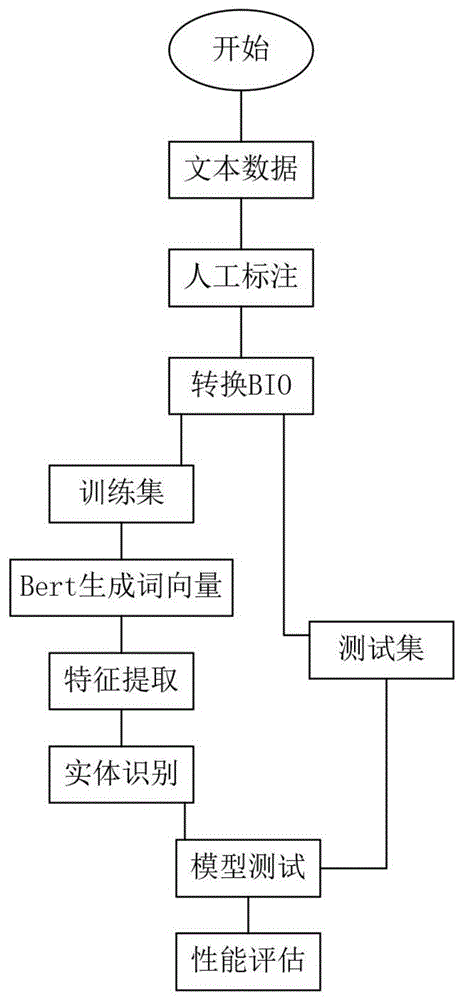
图1为本发明方法流程图。
图2为知识图谱本体图。
图3为实体、关系及缺陷标注。
图4为标注后的jsonl文件。
图5为BIO标注数据示例。
图6为模型预测评价指标。
图7为命名实体识别结果。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
如图1所示,本发明提供了一种基于Bert Bilstm CRF模型的电网主设备命名实体识别方法,包括如下步骤:
步骤1、标签定义,属于前置工作,定义的实体类型包括:电站/线路、电压等级、缺陷设备、设备类型、部件、缺陷部位、缺陷现象、缺陷属性。
步骤2、如图2所示,本体定义,属于前置工作。
步骤3、人工处理(人工标注),通过从已有的知识、经验的描述中提取出语料信息,如设备实体、实体之间的关系、所包含的故障、缺陷等,并进行标注,如图3所示。
原始数据集是一条一条的缺陷描述文本,如“220kV闽61号变#2主变本体油枕渗漏油,未形成持续油滴”。需要人工处理的部分是自己预定义一些实体,然后从数据集中选出一部分进行人工标注。人工标注只需要标出每条文本中有什么实体即可,这一点可利用目前比较成熟的文本标注工具,如doccano实现。
步骤4、标注文件形成,标注后可得到jsonl格式的文件,包含了文本中每个标签的字符起始位置和终止位置,以及标签的名称,如图4所示。
步骤5、转换BIO。经过人工处理的数据需要转换为BIO格式才可用于机器学习模型的训练。BIO标注法将序列中的每个元素标注为“B-X”、“I-X”、“E-X”及“O”,其中“B-X”表示此元素所在实体属于X类型并且此元素在此实体的开头,“I-X”表示此元素所在实体属于X类型并且此元素在此实体的中间位置,“O”表示此元素不属于任何实体。对于中文命名实体识别,每个汉字就是一个元素,都需要有一个对应的标签。
例如,预先定义了电压等级、设备、部件、缺陷、地点、非实体这些实体类型,那么根据这些预定义的实体类型,汉字的类别包括B-VOLTAGE(电压等级首部)、I-VOLTAGE(电压等级中间)、B-DEVICE(设备首部)、I-DEVICE(设备中间)、B-COMPONENT(部件首部)、I-COMPONENT(部件中间)、B-DEFECT(缺陷首部)、I-DEFECT(缺陷中间)、B-LOCATION(地点首部)、I-LOCATION(地点中间)及O(非实体)共11个类别。经过BIO标注的一条数据如图5所示。
不过BIO格式无需人工标注,只需要步骤(1)的标注格式,即可通过代码实现BIO格式转换。
步骤6、模型训练。模型采用BERT-BiLSTM-CRF模型。将原始数据按照一定比例换分为训练集和数据集。训练部分可使用CPU或者GPU进行训练,为了更快的训速练度集和和更测好试的集效的果划。分选用NVDIA GeForce1650 Ti显卡、12G显存进行训练。如使用GPU,需要满足独立显卡NVIDA、CUDA等条件,或者使用免费训练平台如CoLab。如使用CPU,则无需进行GPU那样的繁琐配置,但会使训练速度大幅下降,且可能会对CPU造成不可逆损伤
训练需要使用到谷歌预训练的中文BERT模型参数,此预训练参数采用12层encoder,多头注意力机制头数为12,共110M个参数。对此预训练模型进行微调以使其在本文的数据集上取得更好的性能。谷歌将加载和微调pytorch版本预训练参数的接口集成在pytorch_pretrained_bert包中,只需要用python下载相关组件即可调用。微调实质上就是根据本文中命名实体识别的任务,按照BERT模型的训练过程重新调整参数,从而使其在本数据集上表现更好。训练完成后,代码会将模型自动保存为pt文件,之后即可直接使用。
步骤7、模型测试。利用GPU训练得到的模型进行测试,并对测试结果进行评分,选出效果较好的一个进行后续的预测工作。模型效果如图6所示。
将原始缺陷描述文本直接输入,经过自动BIO处理后,会输入训练好的BERT-BiLSTM-CRF模型,即可实现实体抽取,输出所有实体的类别,此时原始缺陷描述文本已经实现自动命名实体识别的功能。识别结果如图7所示。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 基于BERT-MBIGRU-CRF模型的电网调度指令命名实体识别方法及系统
- 一种基于BiLSTM-CRF模型的电力领域命名实体识别方法