一种基于LSTM的智能交互方法
文献发布时间:2024-04-18 20:00:50
技术领域
本发明涉及语义处理技术领域,具体涉及一种基于LSTM的智能交互方法。
背景技术
在货物监管及仓储作业过程中,把物品存入仓储库中,在需要物品时从仓储库中取出。仓储库保存着大量的物品。在现有的仓储系统中,根据物品的编码或者编号可以直接明确的获取物品的位置。但是物品的编码或者标号存储在存储器中或者标识在物品上,在无法获取到物品的编码或者标号时,在仓储库中较难找准物品的位置。因此,现有的仓储系统缺乏一种灵活的语义交互方法,增加了工作人员寻找物品的难度。
发明内容
针对现有技术中的上述不足,本发明提供的一种基于LSTM的智能交互方法解决了现有的仓储系统缺乏一种灵活的语义交互方法,增加了工作人员寻找物品的难度的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于LSTM的智能交互方法,包括以下步骤:
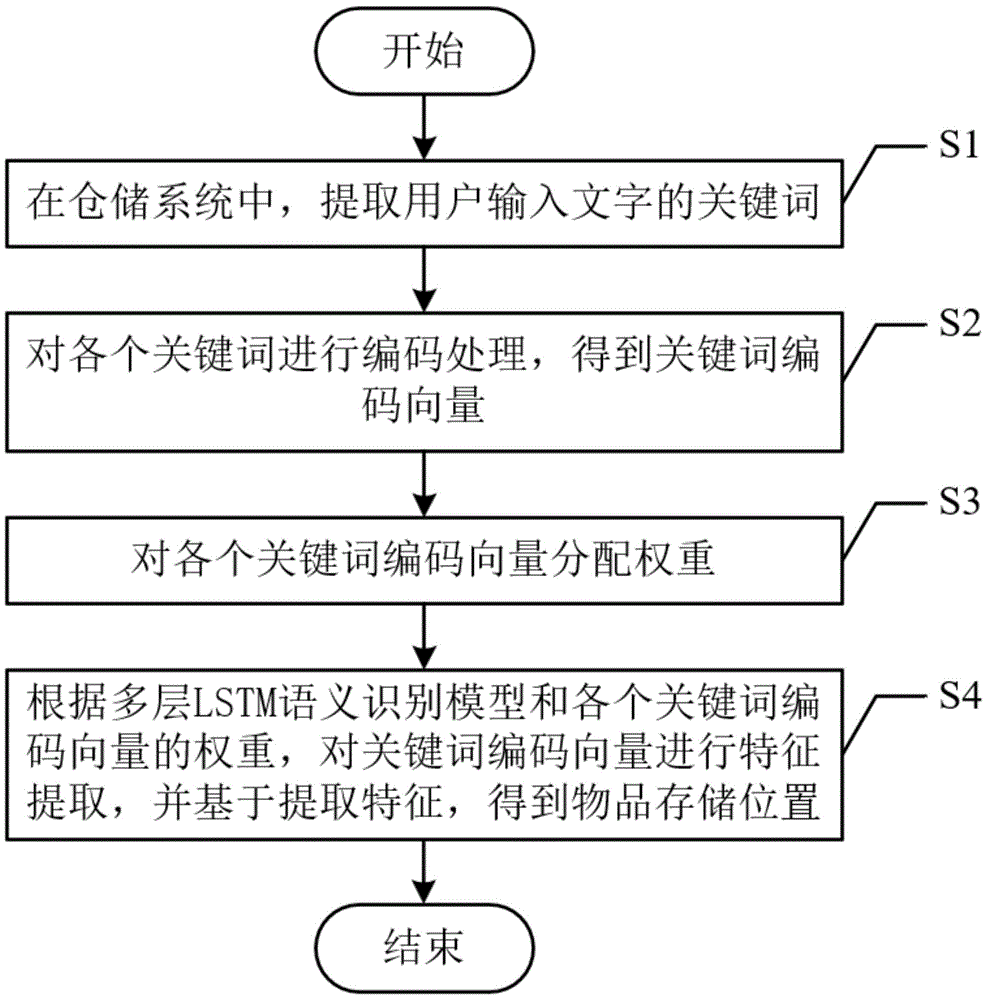
S1、在仓储系统中,提取用户输入文字的关键词;
S2、对各个关键词进行编码处理,得到关键词编码向量;
S3、对各个关键词编码向量分配权重;
S4、根据多层LSTM语义识别模型和各个关键词编码向量的权重,对关键词编码向量进行特征提取,并基于提取特征,得到物品存储位置。
本发明的有益效果为:本发明提取用户输入文字的关键词,并对各个关键词编码向量分配权重,实现根据不同权重分配不同注意力,提高语义识别的精度,并利用多层LSTM语义识别模型对各个关键词编码向量进行语义识别,获取物品存储位置,本发明中提供一种在仓储系统中的语义交互方法,对于工作人员来说,物品特征相比于编码和标号更好记忆,因此,增加了在仓储库中寻找物品的方式。本发明应用于货物监管及仓储作业,实现更便捷和灵活的获取物品位置信息。
进一步地,所述S3包括以下分步骤:
S31、根据现有词汇编码向量在仓储系统中的使用频次和评分,计算现有词汇编码向量的权重;
S32、计算各现有词汇编码向量的标识位;
S33、计算每个关键词编码向量的标识位;
S34、找到与关键词编码向量的标识位相等的现有词汇编码向量对应的权重,得到备选权重;
S35、在备选权重的数量等于1时,备选权重作为关键词编码向量的权重;
S36、在备选权重的数量大于1时,将备选权重对应的现有词汇编码向量作为备选向量;
S37、选出与关键词编码向量相同的备选向量的备选权重作为该关键词编码向量的权重。
上述进一步方案的有益效果为:本发明中对关键词编码向量分配权重,该权重体现出该关键词在仓储系统中的重要性,因此,本发明统计现有词汇编码向量在仓储系统中的使用频次和评分,得到现有词汇编码向量的权重,并对现有词汇编码向量和关键词编码向量计算出一个标识位,初步对比标识位,找到关键词编码向量的权重,在存在多个相同的标识位对应的现有词汇编码向量时,才需要对比关键词编码向量与哪个现有词汇编码向量相同,对应的权重则为关键词编码向量的权重,本发明的分步骤S3能大量减少数据量的运算,又能实现对根据重要性对关键词编码向量分配不同权重。
进一步地,所述S31中计算现有词汇编码向量的权重的公式为:
上述进一步方案的有益效果为:本发明中现有词汇编码向量的权重考虑使用频次和评分,权重跟随使用频次和评分而增长。
进一步地,所述S32或S33中计算标识位的公式为:
上述进一步方案的有益效果为:本发明中根据编码向量中编码值的位置以及编码值本身的大小,计算出标识位,通过指数函数尽可能的放大位置与数值上的区别,实现大量的关键词编码向量只在对比标识位时就能找到对应权重。
进一步地,所述S4中多层LSTM语义识别模型包括:多个LSTM特征提取单元、Concat层、第一卷积层、第二卷积层、第三卷积层、sigmoid层、乘法器M1和全连接层;
每个所述LSTM特征提取单元的输入端用于输入一个关键词编码向量;
所述Concat层的输入端分别与多个LSTM特征提取单元的输出端连接,其输出端分别与第一卷积层的输入端和第二卷积层的输入端连接;
所述sigmoid层的输入端与第一卷积层的输出端连接,其输出端与乘法器M1的第一输入端连接;
所述第三卷积层的输入端与第二卷积层的输出端连接,其输出端与乘法器M1的第二输入端连接;
所述全连接层的输入端与乘法器M1的输出端连接,其输出端作为多层LSTM语义识别模型的输出端。
上述进一步方案的有益效果为:本发明中设置了多个LSTM特征提取单元,每个LSTM特征提取单元处理一个关键词编码向量,Concat层将多个LSTM特征提取单元提取到的多个关键词特征进行拼接,实现语义特征的汇总,然后再分别通过第一卷积层和第二卷积层提取特征,在第一卷积层所在路提取的特征通过sigmoid层计算出特征权重,再施加到第三卷积层输出的特征上,实现对特征的自适应强化,便于全连接层分类,提高语义识别的精度。
进一步地,每个所述LSTM特征提取单元包括:LSTM层、数据融合层、权重施加层和重点特征提取层;
所述LSTM层的输入端作为LSTM特征提取单元的输入端,其输出端与数据融合层的输入端连接;
所述权重施加层的输入端与数据融合层的输出端连接;
所述权重施加层的输出端与重点特征提取层的输入端连接;
所述重点特征提取层的输出端作为LSTM特征提取单元的输出端。
进一步地,所述数据融合层的表达式为:
进一步地,所述权重施加层的表达式为:
进一步地,所述重点特征提取层的表达式为:
,其中,R为重点特征提取层的输出,Avg为平均池化操作,Mp为最大池化操作,/>
上述进一步方案的有益效果为:在一个LSTM特征提取单元中,在数据融合层将LSTM层中各个细胞单元输出的数据进行数据融合处理,在权重施加层根据关键词编码向量的权重对融合的数据进行增强处理,增加重要信息的关注度,最后通过重点特征提取层分别进行两次平均池化和最大池化提取出重要的特征,以哈达玛积相乘的方式,对重要的特征进行自增强。
附图说明
图1为一种基于LSTM的智能交互方法的流程图;
图2为多层LSTM语义识别模型的结构示意图;
图3为LSTM特征提取单元的结构示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于LSTM的智能交互方法,包括以下步骤:
S1、在仓储系统中,提取用户输入文字的关键词;
S2、对各个关键词进行编码处理,得到关键词编码向量;
S3、对各个关键词编码向量分配权重;
S4、根据多层LSTM语义识别模型和各个关键词编码向量的权重,对关键词编码向量进行特征提取,并基于提取特征,得到物品存储位置。
所述S3包括以下分步骤:
S31、根据现有词汇编码向量在仓储系统中的使用频次和评分,计算现有词汇编码向量的权重;
S32、计算各现有词汇编码向量的标识位;
S33、计算每个关键词编码向量的标识位;
S34、找到与关键词编码向量的标识位相等的现有词汇编码向量对应的权重,得到备选权重;
S35、在备选权重的数量等于1时,备选权重作为关键词编码向量的权重;
在步骤S35中,只有1个与关键词编码向量的标识位相等的现有词汇编码向量的标识位,因此,也只对应一个现有词汇编码向量的权重;
S36、在备选权重的数量大于1时,将备选权重对应的现有词汇编码向量作为备选向量;
在步骤S36中,备选向量存在多个,一个备选权重对应一个现有词汇编码向量;
S37、选出与关键词编码向量相同的备选向量的备选权重作为该关键词编码向量的权重;
在步骤S37中,需要对比关键词编码向量和备选向量的编码值,从而找到权重。
本发明中对关键词编码向量分配权重,该权重体现出该关键词在仓储系统中的重要性,因此,本发明统计现有词汇编码向量在仓储系统中的使用频次和评分,得到现有词汇编码向量的权重,并对现有词汇编码向量和关键词编码向量计算出一个标识位,初步对比标识位,找到关键词编码向量的权重,在存在多个相同的标识位对应的现有词汇编码向量时,才需要对比关键词编码向量与哪个现有词汇编码向量相同,对应的权重则为关键词编码向量的权重,本发明的分步骤S3能大量减少数据量的运算,又能实现对根据重要性对关键词编码向量分配不同权重。
所述S31中计算现有词汇编码向量的权重的公式为:
在本实施例中,现有词汇编码向量的评分是人主观根据使用习惯设置的分值。
本发明中现有词汇编码向量的权重考虑使用频次和评分,权重跟随使用频次和评分而增长。
所述S32或S33中计算标识位的公式为:
本发明中根据编码向量中编码值的位置以及编码值本身的大小,计算出标识位,通过指数函数尽可能的放大位置与数值上的区别,实现大量的关键词编码向量只在对比标识位时就能找到对应权重。
如图2所示,所述S4中多层LSTM语义识别模型包括:多个LSTM特征提取单元、Concat层、第一卷积层、第二卷积层、第三卷积层、sigmoid层、乘法器M1和全连接层每个所述LSTM特征提取单元的输入端用于输入一个关键词编码向量;所述Concat层的输入端分别与多个LSTM特征提取单元的输出端连接,其输出端分别与第一卷积层的输入端和第二卷积层的输入端连接;所述sigmoid层的输入端与第一卷积层的输出端连接,其输出端与乘法器M1的第一输入端连接;所述第三卷积层的输入端与第二卷积层的输出端连接,其输出端与乘法器M1的第二输入端连接;所述全连接层的输入端与乘法器M1的输出端连接,其输出端作为多层LSTM语义识别模型的输出端。
本发明中设置了多个LSTM特征提取单元,每个LSTM特征提取单元处理一个关键词编码向量,Concat层将多个LSTM特征提取单元提取到的多个关键词特征进行拼接,实现语义特征的汇总,然后再分别通过第一卷积层和第二卷积层提取特征,在第一卷积层所在路提取的特征通过sigmoid层计算出特征权重,再施加到第三卷积层输出的特征上,实现对特征的自适应强化,便于全连接层分类,提高语义识别的精度。
在本实施例中,每个LSTM特征提取单元处理一个关键词编码向量,一个多层LSTM语义识别模型可一次性处理用户输入的一句文本中的所有关键词,更好识别用户语义,匹配程度更好。
如图3所示,每个所述LSTM特征提取单元包括:LSTM层、数据融合层、权重施加层和重点特征提取层;
所述LSTM层的输入端作为LSTM特征提取单元的输入端,其输出端与数据融合层的输入端连接;所述权重施加层的输入端与数据融合层的输出端连接;所述权重施加层的输出端与重点特征提取层的输入端连接;所述重点特征提取层的输出端作为LSTM特征提取单元的输出端。
所述数据融合层的表达式为:
所述权重施加层的表达式为:
所述重点特征提取层的表达式为:
在一个LSTM特征提取单元中,在数据融合层将LSTM层中各个细胞单元输出的数据进行数据融合处理,在权重施加层根据关键词编码向量的权重对融合的数据进行增强处理,增加重要信息的关注度,最后通过重点特征提取层分别进行两次平均池化和最大池化提取出重要的特征,以哈达玛积相乘的方式,对重要的特征进行自增强。
本发明提取用户输入文字的关键词,并对各个关键词编码向量分配权重,实现根据不同权重分配不同注意力,提高语义识别的精度,并利用多层LSTM语义识别模型对各个关键词编码向量进行语义识别,获取物品存储位置,本发明中提供一种在仓储系统中的语义交互方法,对于工作人员来说,物品特征相比于编码和标号更好记忆,因此,增加了在仓储库中寻找物品的方式。本发明应用于货物监管及仓储作业,实现更便捷和灵活的获取物品位置信息。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 注射喷嘴、注射装置、注射成型装置、注射方法及注射成型方法
- 注射喷嘴、注射装置、注射成型装置、注射方法及注射成型方法