一种基于特定索引结构的高效调度算法
文献发布时间:2023-06-19 09:26:02
技术领域
本发明涉及状态机复制技术领域,尤其涉及一种基于特定索引结构的高效调度算法。
背景技术
状态机复制(SMR)是一种设计容错服务的基本方法。然而,它对事务确定性执行的要求常常导致副本成为单线程模型,不能完全利用当今处理器的多核处理能力。因此,并行SMR成为近年来研究的热点。其基本思想是,独立事务可以并行执行,而相互依赖的事务必须以相对顺序执行,以确保副本之间的一致性。基于依赖检测的并行SMR方法要么是成对比较要么是batch比较,它们不能同时保证高效的依赖检测的和事务的并行执行能力。除此之外,这些方法的调度器的执行过程也不能并行执行,进一步增加了主要由依赖检测带来的调度开销,为了进一步降低调度开销同时保证事务的并行执行程度,为此,提出一种基于特定索引结构的高效调度算法。
发明内容
本发明提出的一种基于特定索引结构的高效调度算法,解决了上述背景技术中提出的问题。
为了实现上述目的,本发明采用了如下技术方案:
一种基于特定索引结构的高效调度算法,由一个特殊的布隆过滤器和每个过滤器元素对应的事务队列组成,所述布隆过滤器和事务队列组成特殊的索引结构,其分别进行高效的依赖检测和保留必要的依赖信息,通过布隆过滤器,在一定时间内检测出事务之间的依赖关系,事务队列具有保持总顺序关系和简化依赖关系图的特性,借助于索引结构,调度器支持记录粒度锁,从而支持并发事务调度操作。
优选的,所述索引结构和相应的并发调度设计方法如下:
索引结构的主要部分是由单个hashmap构造的简化版的布隆过滤器,hashmap的每个键表示事务访问的一条记录/record,在不实际构造和遍历依赖关图的情况下,当事务被映射到布隆过滤器同一个位置时,确定事务之间的依赖关系;
hashmap的每个键对应的值/value是一个FIFO队列,其中包含访问该键记录的所有事务,hashmap的所有事务队列头部的事务都可以并行执行;
采用特殊的索引结构,非常自然的使调度器支持record粒度锁的并发调度过程,并可以同时保证调度的安全性和正确性。
优选的,所述事务由若干命令和record组成,将事务集合O
优选的,所述布隆过滤器是由单个hashmap构造的,尽管布隆过滤器通常由多个散列函数组成,但这里唯一使用了hashmap中的hash函数,原因是的布隆过滤器不仅用于检测依赖性,还用于根据访问的记录对事务队列进行索引,其通过让record作为要散列的key,让所有事务作为value来实现的,因此,对于事务t来说,查找与其record有关的所有依赖事务的时间复杂度为0(1)。
优选的,所述事务队列是为了使调度器提供高效的依赖性检测和并发执行能力,t
优选的,所有所述事务队列可以共同形成一个简化的依赖图,其顺序与全序一致,但与原始的完全依赖关系图相比结构简单得多,由于事务队列中的所有事务对于记录都属于同一等价类,因此不必通过事务内的成对比较显式地建立完整的全序关系,因此,提出的索引结构可以有效地降低事务依赖关系检测和调度的开销。
优选的,自由事务:如果表示事务的顶点在依赖图中没有入边,则这个事务可以执行,当工作线程执行完成一个事务时,可以从依赖关系图中删除此顶点及其出边,在算法中,当一个事务t
优选的,细粒度锁:在调度过程中,操作锁定的粒度是调度器中的一个记录,当调度程序在上述索引结构上操作事务t
优选的,所述调度器的算法过程如下:
当系统启动时,过程initialization首先初始化hashmap;
然后初始化worker线程以等待执行事务;
hashmap的长度可以比记录数少,在这种情况下,hash函数存在一定的概率将两个不同的记录映射到同一位置;
一旦调度程序接收到事务,将根据它们的全序将它们插入索引中;
一个事务不依赖于任何其他事务/即是自由事务,那么它可以被调度执行,有两种情况:(i)对于新接受的事务,没有检测到依赖项,则可以在事务的依赖项检测完成,插入事务队列后直接执行;(ii)对于事务队列中尚未执行的事务,它一定存在依赖事务,并且在其依赖事务全部执行并移除之前无法执行;
调度程序不需要单独的dgGetTrans操作,而是将其与insert操作和remove操作组合在一起,分别为dgInsertandGet和dgRemoveAndGet。
优选的,调度程序具体操作步骤如下:
dgInsertAndGet:dgInsertandGet(t
dgRemoveAndGet:与dgInsertandGet一样,从索引中删除已完成的事务t
本发明的有益效果为:本发明提出的方法高效的解决了依赖图调度中由于基于两两比较而调度开销过大导致的性能损失问题,保证了在各种依赖率工作负载下的并行执行能力,与CBASE和batchCBASE相比,为了展现本发明提出的方法在吞吐量、可扩展性和鲁棒性方面优势,在一个数据库原型上进行了实验和分析,在此基础上,正式证明了副本调度与其他调度安全的一致性,调度器比对比方法具有更高的效率、可扩展性和健壮性;
在本发明中,设计了一个高效的调度模型来检测冲突,表达偏序关系和调度事务,这可以确保事务之间的最大并行执行能力,充分利用多核处理器的优点,以及确保副本之间的一致性。
附图说明
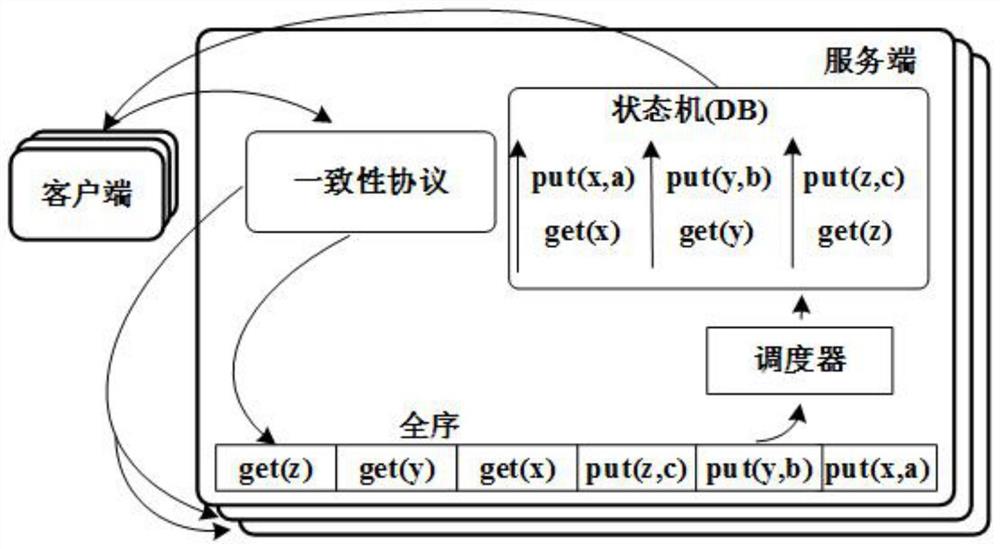
图1为本发明的并行状态机复制示意图;
图2为本发明的索引结构图示例;
图3为本发明的简化依赖图示例;
图4为本发明的CBASE、batchCBASE和fastCBASE在没有冲突工作负载下系统吞吐量示意图;
图5为本发明的相同的配置下冲突率示例;
图6为本发明的低冲突率下系统吞吐量对比示例;
图7为本发明的不同冲突率下吞吐量示例;
图8为现有调度器中算法1的示意图;
图9为本发明算法2的示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
参照图1-9,一种基于特定索引结构的高效调度算法,由一个特殊的布隆过滤器和每个过滤器元素对应的事务队列组成,布隆过滤器和事务队列组成特殊的索引结构,其分别可以进行高效的依赖检测和保留必要的依赖信息,通过布隆过滤器,可以在一定时间内检测出事务之间的依赖关系,事务队列具有保持总顺序关系和简化依赖关系图的特性,借助于索引结构,调度器支持记录粒度锁,从而支持并发事务调度操作。
索引结构的主要部分是由单个hashmap构造的简化版的布隆过滤器,hashmap的每个键表示事务访问的一条记录/record,在不实际构造和遍历依赖关图的情况下,当事务被映射到布隆过滤器同一个位置时,它可以确定事务之间的依赖关系;
hashmap的每个键对应的值/value是一个FIFO队列,其中包含访问该键记录的所有事务,hashmap的所有事务队列头部的事务都可以并行执行;
采用特殊的索引结构,可以非常自然的使调度器支持record粒度锁的并发调度过程,并可以同时保证调度的安全性和正确性。
事务由若干命令和record组成,将事务集合O
布隆过滤器是由单个hashmap构造的,尽管布隆过滤器通常由多个散列函数组成,但这里唯一使用了hashmap中的hash函数,原因是的布隆过滤器不仅用于检测依赖性,还用于根据访问的记录对事务队列进行索引,其通过让record作为要散列的key,让所有事务作为value来实现的,因此,对于事务t来说,查找与其record有关的所有依赖事务的时间复杂度为0(1)。
事务队列是为了使调度器提供高效的依赖性检测和并发执行能力,t
如图2和图3所示举例说明了依赖图简化的基本思想,简化的依赖图:所有事务队列可以共同形成一个简化的依赖图,其顺序与全序一致,但与原始的完全依赖关系图相比结构简单得多,由于事务队列中的所有事务对于记录都属于同一等价类,因此不必通过事务内的成对比较显式地建立完整的全序关系,因此,提出的索引结构可以有效地降低事务依赖关系检测和调度的开销;图2是在同一FIFO事务队列中有四个具有相同记录x的事务的索引结构。图3在图2中,事务队列仅保存两个相邻事务之间保持必要的顺序,例如t
自由事务:直观地说,如果表示事务的顶点在依赖图中没有入边,则这个事务可以执行,当工作线程执行完成一个事务时,可以从依赖关系图中删除此顶点及其出边,在的算法中,当一个事务t
细粒度锁:在调度过程中,操作锁定的粒度是调度器中的一个记录,当调度程序在上述索引结构上操作事务t
根据图9所示,调度器的算法过程细节如下:
algorithm2详细展示了我们的调度器是如何工作的,依赖关系图不需要显式定义,因为事务队列可以有效地替换它,当系统启动时,过程initialization首先初始化hashmap(第7行),然后初始化worker线程以等待执行事务(第8-10行),hashmap的长度可以比记录数少,在这种情况下,hash函数存在一定的概率将两个不同的记录映射到同一位置,幸运的是,这种误报不会违反一致性,因为那些错误地落入同一事务队列的事务将按顺序安全地执行,尽管这种错误的事务冲突可能会发生,但它可以保证永远不会发生假阴性;
一旦调度程序接收到事务,它将根据它们的全序(第12-14行)将它们插入索引中,如前,如果一个事务不依赖于任何其他事务(即,是自由事务),那么它可以被调度执行,有两种情况:(i)对于新接受的事务,如果没有检测到依赖项,则可以在事务的依赖项检测完成,插入事务队列后直接执行;(ii)对于事务队列中尚未执行的事务,它一定存在依赖事务,并且在其依赖事务全部执行并移除之前无法执行,因此,与CBASE和batchCBASE不同,我们的调度程序不需要单独的dgGetTrans操作,而是将其与insert操作和remove操作组合在一起,分别为dgInsertandGet和dgRemoveAndGet。
调度程序具体操作步骤如下:
dgInsertAndGet:dgInsertandGet(t
dgRemoveAndGet:与dgInsertandGet一样,从索引中删除已完成的事务t
正确性:调度器进程的设计考虑的主要因素是在副本之间执行每个事务后确保状态一致性和各个操作本身过程的安全性,从调度程序的数据结构、锁粒度和调度策略等方面论证调度器在无死锁、无饥饿方面的安全性和副本一致性的有效性;
Procedure safety:在细粒度锁的情况下,进程是无死锁和无饥饿的,首先,t
Replica consistency:事务队列可以确保事务之间的<
实验评估:
为了评估基于CBASE的调度程序fastCBASE的性能,实现了一个基于paxos的C/S服务模型的内存数据库,该系统提供了事务操作put、get和delete,CBASE、batchCBASE和fastCBASE都嵌入到这个系统中,只是它们的调度器部分不同,客户端按顺序发送事务命令,副本首先对接收到的所有事务的序列达成一致,然后由调度器执行相应的事务操作,调度器的实现完全按照算法1(进一步说,是[15]中的算法)和算法2;
实验环境由四个hp服务器节点组成,其中三台服务器的节点在paxos协议中扮演提议者和接受者的角色,每台服务器有2个e5-2620cpu,2.10hz,超线程,共24个线程,运行内存为256g;客户机部署在具有4路e7-4820cpu,2.0hz的hp机上,每通道8核,超线程,共64个线程,操作系统都是Ubuntu18.04.2LTS(GNUlinux4.15.0-48-genericx86\u64),客户机中的客户端将发送大量事务,这些事务可以使服务器处于满负荷运行状态,所有应用程序都由go实现,go的版本是go1.12.1,集群内的通信通过千兆网络交换机进行;
加速分析,为了观察每个调度器最明显的加速能力,分析了在没有冲突事务(例如所有读操作和对不同资源的写操作)的工作负载情况下调度器的吞吐量性能,由平均每秒每个副本的吞吐量表示,图4显示了CBASE、batchCBASE和fastCBASE在没有冲突工作负载下系统吞吐量,虽然操作系统需要对每一个事务都进行分配一次线程的操作,但是基于索引结构设计了精致的调度过程,从图中可以看出,调度器在8个线程和16个线程中的吞吐量远高于batchCBASE的相应吞吐量,并且与batchCBASE不同,随着线程数的增加,方法的性能近似线性提高,具有很强的可扩展性;
冲突率分析,从图7可以看出,在相同的配置下,batchCBASE的冲突率是fastCBASE的近10000倍,随着hashmap或bitmap大小的增加,fastCBASE与batchCBASE的冲突率会降低,但batchCBASE会放大由batch引起的冲突率,这也会增加误报率,因此,在现实中,即使冲突率很低,batchCBASE也会受到很大的影响,本发明调度器假阳率对性能影响不大;
不同冲突率负载下的加速分析,根据图5和图6的结果,可以看到调度器可以允许事务之间的最大并行性,当冲突率达到20%时,调度器与在无冲突工作负载下batchCBASE的性能相似,所以随着冲突率的增加,调度器更加健壮。
综上,并行状态机复制需要精心设计使独立的命令以并行方式执行,非独立命令按其相对顺序执行从而使系统具有较高的性能,为了实现这一目标,需要高效、正确的冲突检测和调度策略,现有的工作在这些方面不能取得很好的平衡,因此很容易使现有的调度程序成为系统的性能瓶颈,调度程序设计的优点也成为其缺点的原因,在本发明中,设计了一个高效的调度模型来检测冲突,表达偏序关系和调度事务,这可以确保事务之间的最大并行执行能力,充分利用多核处理器的优点,以及确保副本之间的一致性。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种基于特定索引结构的高效调度算法
- 一种基于害虫特定气味受体筛选高效驱避剂的方法