一种文本纠错的方法和装置
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及智能外呼的技术领域,尤其是涉及一种文本纠错的方法和装 置。
背景技术
目前,在外呼机器人领域,一般通过ASR(Automatic Speech Recognition, 自动语音识别)技术将通信电话语音信号转成文本格式文件,然后对该文本 进行分析,获取用户意图然后做出相应处理。由于电话语音信号较差,ASR 转换成文本存在一定的错误率,导致机器人理解用户意图出现偏差。
近场情况下的SNR(Signal to Noise Ratio,人机对话信噪比)较高, 信号清晰,ASR算法能够生成较为准确的文本。但是远场情况下由于噪声较 大,SNR大幅降低,导致ASR算法处理难度增加且准确率大大降低。此外, 地区差异引起的口音差异、麦克风的数量和灵敏度差异都会对语音识别转换 所生成文本内容的准确率产生较大影响。
现有的文本纠错方法主要有:基于中文分词、n-gram语言模型、语言学 规则和混淆词库的方法,基于统计机器翻译和神经机器翻译的方法,基于散 列串和依存句法的方法,基于深度学习的方法等。这些方法的准确率和效果 各有不同,但多数是针对输入错误和人为错误,应用在通用领域,却较少有 针对ASR识别的文本错误和针对特定应用领域的方法研究。现有的文本纠错 方法对细分领域的ASR识别出现的文本纠错效果有待提高。
发明内容
本发明的目的是提供一种文本纠错的方法和装置,其具有提高文本纠错 率的效果。
本发明的上述发明目的一是通过以下技术方案得以实现的:
一种文本纠错的方法,包括:
将待纠错文本预处理后生成待检字集合,利用预训练的语言模型预测所 述待检字集合中每个字的概率分布,根据每个字的概率分布确定错字位置并 生成候选字集合,将所述候选字集合中的每个字替换错字位置形成生成候选 句集合,对候选句集合中的各元素进行评分,保留评分最优的所述候选句集 合中的元素所对应候选字,用该候选字替换相应错字位置并输出句子。
所述语言模型的训练步骤包括:随机将待训练句子中的部分汉字替换成 另一个同音字和/或近音字;逐批次将替换后的待训练句子输入语言模型中进 行前向传播计算,输出替换后文字的预测概率分布;用预测概率分布和真实 字符计算负对数似然损失函数;用反向传播算法迭代优化直到模型收敛。
所述候选字集合包括同音字或近音字以及排除不符合语言常识的候选字。
所述待检字集合的生成步骤包括:将待纠错文本基于通用词典和领域词 典进行分词;
基于HMM分词;
把出现在混淆词中的词替换为相应的正确词;
保留分出的单字词和新词,组成待检字集合。
本发明的上述发明目的二是通过以下技术方案得以实现的:
一种文本纠错的装置,包括:
文本预处理模块,用于将待纠错文本进行分词;
检错模块,用于预测待检字集合中每个字的概率分布,根据每个字的概 率分布确定错字位置;
候选词召回模块,用于对每个错字位置确定候选字集合;
候选词评分模块,用于对每个候选字评分;
替换和输出模块,用于对每个错字位置替换为相应的、评分最优的候选 字以及句子输出。
所述检错模块包括语言模型训练,训练步骤包括:随机将待训练句子中 的部分汉字替换成另一个同音字和/或近音字;逐批次将替换后的待训练句子 输入语言模型中进行前向传播计算,输出替换后文字的预测概率分布;用预 测概率分布和真实字符计算负对数似然损失函数;用反向传播算法迭代优化 直到模型收敛。
所述候选字集合包括同音字和近音字并排除不符合语言常识的候选字。
所述文本预处理模块包括将待纠错文本基于通用词典和领域词典进行分 词后基于HMM分词;把出现在混淆词中的词替换为相应的正确词;保留分出 的单字词和新词,组成待检字集合。
附图说明
图1是本发明实施例一的整体结构示意图。
具体实施方式
实施例一
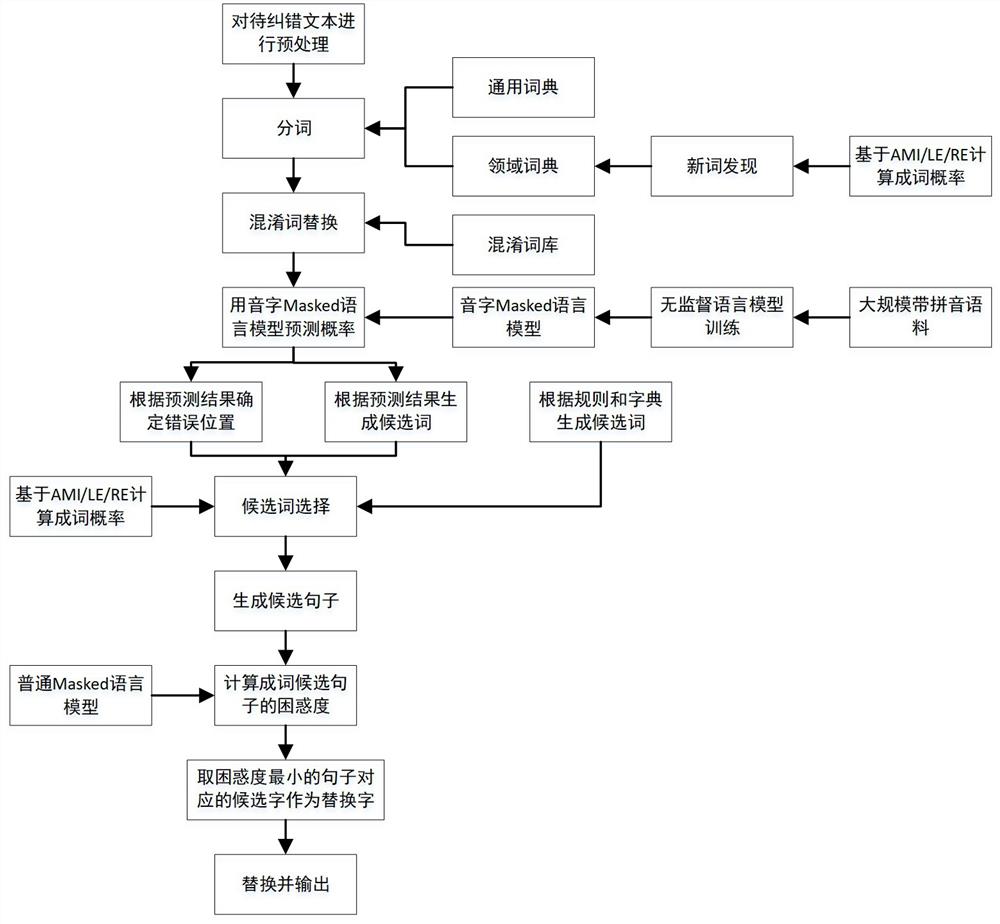
本发明公开了一种文本纠错的方法,参照图1,包括以下步骤:
S1、将通过ASR技术转化后文本格式文件进行预处理,获得待检字集合;
S2、检测句子中的错字位置,通过预测待检字集合中每个字的概率分布, 根据每个字的概率分布确定错字位置,对每个错字位置确定候选字集合;
S3、将候选字集合中的每个字替换错字位置,形成生成候选句集合,对 候选句集合中的各候选句进行评分,保留评分最优的候选句中错字位置所对 应候选字;
S4、用上述候选字替换相应错字位置并输出句子。
在步骤S1中,预处理具体包括有以下步骤:
S11、按照通用词典和领域词典进行分词;
具体地,可以使用jieba分词库进行分词,通用词典就是jieba分词库 自带的词典。领域词典为通过新词发现算法生成的词典。jieba分词库允许 指定自定义词典,配置参数中指定自定义词典为领域词典即可。
S12、基于HMM(Hidden Markov Model,隐马尔可夫模型)分词;
jieba分词库支持此分词模式,并且使用HMM算法,可以发现一些词典 中未出现的新词。
S13、混淆词替换,即把出现在混淆词库中的错词替换为相应的正确词;
混淆词库是人为根据经验和积累的数据总结出的常用易错词,是一个错 词到相应正确词的对应表,分成两列,第一列是错词,第二列是正确词。如 果一个词出现在混淆词库的第一列,就认为它是错的,可以用相应的正确词 替换它。混淆词库第二列的正确词应该都出现在通用词典或者领域词典里; 如果没有,就把它们加入到领域词典。
S14、保留分出的单字词和HMM分出的新词,组成待检字集合。
单字词就是只有一个字组成的词。HMM分出的新词就是使用HMM模型分 词时,不在通用词典也不在领域词典中的词。把这些词放在一起,其中每个 字都当作待检测的错字,称为待检字集合。
在步骤S11中,领域词典是通过新词发现算法从训练语料中提取得到的, 训练语料由通用语料和领域语料合并而成。通用语料比如维基百科的文章语 料、网易新闻语料、微信聊天语料、微博语料等等,它们包括了数以百万计 的文章或短消息,覆盖了范围广泛的各行各业各个领域的话题,包含了足够 全面和足够量的语言、语法现象及它们的组合,是训练一个好的语言模型的 基础语料。领域语料是针对范围较小特定行业、特定应用领域收集的专用语 料,数量可能没有通用语料规模那么大,但是包含了通用语料未必能覆盖或者出现频次不足的特有语句,比如特定的专有名词,领域常用的句式等等。 例如:面向金融领域的信用卡发卡机器人,可能会较多出现“白金信用卡”、 “最低额度”、“免年费”等词语。
领域词典的获得步骤包括:
S111、从训练语料生成n-gram集合,即字数为n的所有文字片段,n为 取值为2至5中的任意整数;
具体的,训练语料先根据标点符号分成一个一个的句子。然后对每个句 子中的字按顺序截取长度分别为2到5的片段。例如对句子“少先队员应该 给老人让座”,当n=2时,所有2-gram为:少先、先队、队员、员应、应该、 该给、给老、老人、人让、让座;当n=3时,所有3-gram为:少先队,先队 员,队员应,……,老人让,人让座;以此类推。
S112、从n-gram集合中去掉包含在通用词典中的部分;
以上书句子为例,当n=2时,队员、应该、老人、让座已经出现在通用 词典中,则去掉,保留少先、先队、员应、该给、给老、人让。
S113、对n-gram集合剩下的每个n-gram计算基于左右信息熵和平均互 信息的计算成词概率;
成词概率score定义为
score=AMI+L(W)
其中AMI(average mutual information)是平均互信息,L(W)是邻字丰富 度。
平均互信息AMI定义为:
其中W=c1c1...ck是待评估的候选词,ci是它的第i个字,i=1..k,k是字 数;
P(W)是该候选词出现的概率,P(ci)是ci这个字出现的概率。
邻字丰富度L(W)定义为:
其中ε是一个很小的数,用以避免分母出现0;
LE为左信息熵,RE为右信息熵,定义如下:
其中,V是字表,P(aW|W)为a这个字出现在候选词W左边的条件概率。 右信息熵的定义类似。
S114、保留成词概率大于预定阈值的n-gram;
S115、按照语法规则过滤不合法的词,剩下的n-gram都当作新词加入领 域词典。
常用的语法规则有停用词表法和句法规则法。
停用词表法指的是不能出现在一个词串首部和尾部的词。例如“把”“是” 就是停用词,它们不能出现在一个词的首部。根据阈值过滤后剩下的n-gram, 如果有“把”字或“是”字开头的,就把它们去掉。
句法规则法指汉语中有些词类是不能出现在多字词的首部或尾部。例如 助词、量词不能位于多字词的首部;副词、连词不能出现在多字词的尾部。 对前面过滤剩下的n-gram,如果符合这些规则的,就把它们去掉。
在步骤S2中,检错错字位置使用语音字Masked语言模型进行检错。语 音字Masked语言模型是类似于BERT(Bidirectional Encoder Representations from Transformers)模型、基于多层双向Transformer 架构的深度神经网络。网络由输入层、嵌入层、位置编码层、若干个 Transformer层和输出层组成。每个Transformer层也叫一个Transformer 块(Transformer Block),它们结构完全相同。每个Transformer块由几个 子模块组成,包括一个Attention层(Multi-head Self Attention),一个 前馈网络层(FFN,feed forwardnetwork),两者分别带有残差连接(Residual Connection)和归一化(Normalization)层。这几个字模块的连接关系,各 自的功能和作用,相应的理论分析,均有现有学术资料可以参考。根据需要 可以叠加任意多个Transformer层。层数越多,计算量越大,需要的训练数据越多,训练和预测时间越长。综合考虑模型效果和训练、预测时间,本实
模型的输入是一组句子。句子中的每个汉字都转换成对应的带声调拼音, 训练和预测时把汉字和拼音同时输入网络。为了训练模型对错别字进行纠错 的能力,以一定概率随机把句子中的某些汉字替换为另一个字(保留对应的 拼音),替换掉汉字称为mask字符,并记下每个mask的位置。这样,相当 于让模型根据句子上下文和待预测汉字的发音,预测发音在句中对应的汉字。 根据模型输出的预测概率分布,既可以判断错别字位置,也可以帮助选择纠 正错别字对应的候选字。
具体来说,对输入的待纠错句子,用模型预测其中每个位置上汉字的概 率分布,概率小于某特定阈值的字,认为是错别字,而同一位置上的其它概 率较高的字,就可以当成纠正该错别字对应的候选汉字。因为预测时输入了 该位置上的汉字的发音,该发音是根据错别字标注的发音,模型输出的高概 率汉字都是和错别字同音或发音相近的字。同时,由于预测时既考虑了待预 测位置前面的文字,也考虑了待预测位置后面的文字,所以模型预测出的高 概率汉字,都是比较符合整个句子语义且符合语法习惯的字。
举例来说,假如待纠错句子为“少先队员因该给老人让座”,模型的输 出如下表。
在本实施例中,只显示了3个位置的预测结果,概率较小的字从略。其 中:
第3个字位置上,预测结果为(括号内为概率):队(0.66),对(0.20), 堆(0.14)……
第5个字位置上,预测结果为(括号内为概率):应(0.72),音(0.22), 因(0.05)……
第11个字位置上,预测结果为(括号内为概率):坐(0.45),座(0.42), 做(0.12)……
假设概率阈值选择为0.1。
句子中第3个字位置上的字“队”,在预测分布中对应的概率为0.66, 大于阈值0.1,所以认为是正确的。
句子中第11个字位置上的字为“座”,在预测分布中对应的概率为0.42, 大于阈值0.1(虽然不是排在第1个),也认为是正确的。
句子中第5个字位置上的字为“因”,在预测分布中对应的概率为0.05, 小于阈值0.1,认为是错的。该位置的预测分布中,概率大于阈值的字包括 “应”和“音”,就可以都加入候选汉字中。当然,实际正确的字是“应”, “音”字可以在后续步骤中进一步排除。
其中,步骤S2包括以下步骤:
1、根据模型预测结果生成候选字;
如前所述,已经给出了根据模型预测结果生成候选字的方法和例子,不 再重复。
2、根据规则生成候选词,所述候选词包括同音字和近音字。
从同音字表和近音字表中,把和错字对应的所有同音字和近音字都加入 到该错字对应的候选字表中。
3、候选字选择,按照一定的规则排除掉一部分候选字。
可以用的规则很多,主要是根据语言常识和经验总结出来的,例如:
根据词典(包括前述通用词典和领域词典),如果一个候选字和该字前 后的词能构成一个合法的词(出现在词典中的词),就保留;否则就排除。
候选字评分包括以下步骤:
1、对每个候选字的组合尝试替换,得到候选句子;
例如,原句是“少先队员因该给老人让坐”,错字有两个:“因”和“坐”。 “因”的候选字之一是“应”,“坐”的候选字之一是“做”。把“因”替 换成“应”,把“坐”替换成“座”,结果得到一个候选句子:“少先队员 应该给老人让座”。
2、基于n-gram语言模型计算候选句子困惑度;
3、选择困惑度最小的候选句子对应的那些候选字用于替换。
如果候选句子有3个,分别计算困惑度为PP(S1)=130,PP(S2)=15, PP(S3)=450,选择困惑度最小的S2。
其中,困惑度(perplexity)定义为:
其中:S=w1w2...wn是一个句子;
wi是句子S的第i个词(包括句子结束标记
句长n是句子中词的个数;
P(w1w2...wn)是句子S出现的概率;
P(wi|w1...wi-1)是的前面i-1个词出现的前提下,词wi出现的条件概 率;
i=1时,条件概率为P(w1|w0),w0表示句子的起始占位符。
领域词典是通过新词发现算法从训练语料中提取得到的,所述训练语料 由通用语料和领域语料合并而成,所述领域词典的获得步骤包括:
1、从训练语料生成n-gram集合,即字数为n的所有文字片段,n=2..5;
训练语料先根据标点符号分成一个一个的句子。然后对每个句子中的字 按顺序截取长度分别为2到5的片段。例如对句子“少先队员应该给老人让 座”:
n=2时,所有2-gram为:少先,先队,队员,...,人让,让座;
n=3时,所有3-gram为:少先队,先队员,队员应,...,老人让,人 让座;
......
诸如此类。
2、从n-gram集合中去掉包含在通用词典中的部分;
这里的通用词典就是前面分词步骤用到的通用词典。还是前面的例子, 假如所有n-gram是:
少先,先队,队员,人让,让座,少先队,先队员,队员应,老人让, 人让座(为行文简洁起见,省略号代表的部分未列出)。
假如其中:队员,让座两个词已经在通用词典中,则把它们去掉。剩下 的n-gram是:少先,先队,人让,少先队,先队员,队员应,老人让,人让 座。
3、对n-gram集合剩下的每个n-gram计算基于左右信息熵和平均互信息 的计算成词概率;
4、保留成词概率大于预定阈值的n-gram;
5、按照语法规则过滤不合法的词,剩下的n-gram都当作新词加入领域 词典;
常用的语法规则有停用词表法和句法规则法。
停用词表法:停用词指的是不能出现在一个词串首部和尾部的词。例如 “把”“是”就是停用词,它们不能出现在一个词的首部。根据阈值过滤后 剩下的n-gram,如果有“把”字或“是”字开头的,就把它们去掉。
句法规则法:汉语中有些词类是不能出现在多字词的首部或尾部。例如 助词、量词不能位于多字词的首部;副词、连词不能出现在多字词的尾部。 对前面过滤剩下的n-gram,如果符合这些规则的,就把它们去掉。
其中,成词概率score定义为
score=AMI+L(W)
AMI(average mutual information)是平均互信息,L(W)是邻字丰富度。
平均互信息AMI定义为:
其中W=c1,c1,...,ck是待评估的候选词,ci是它的第i个字,i=1..k, k是字数;
P(W)是该候选词出现的概率,P(ci)是ci这个字出现的概率。
邻字丰富度L(W)定义为:
其中ε是一个很小的数,用以避免分母出现0;
LE为左信息熵,RE为右信息熵,定义如下:
其中,V是字表,P(aW|W)为a这个字出现在候选词W左边的条件概率。
右信息熵的定义类似。
Masked语言模型需要用大规模的文本语料训练得到,训练步骤包括:
1、对训练语料进行预处理,包括分句,按字分割,逐字加拼音,构造汉 字和拼音词汇表,把汉字和拼音都转成数字表示等。这里的训练语料由通用 语料和领域语料合并而成。通用语料比如维基百科的文章语料,网易新闻语 料,微信聊天语料,微博语料等等,它们包括了数以百万计的文章或短消息, 覆盖了范围广泛的各行各业各个领域的话题,包含了足够全面和足够量的语 言、语法现象及它们的组合,是训练一个好的语言模型的基础语料。领域语 料是针对范围较小特定行业、特定应用领域收集的专用语料,数量可能没有 通用语料规模那么大,但是包含了通用语料未必能覆盖或者出现频次不足的 特有语句,比如特定的专有名词,领域常用的句式等等。例如:面向金融领 域的信用卡发卡机器人,可能会较多出现“白金信用卡”,“最低额度”, “免年费”等词语。
预处理时首先把语料中的文章按照标点符号,换行等分割成句子。然后 是分字/词,因为我们的语言模型是以字为单位的,所有只要按单个汉字分割, 字与字中间用空格隔开就可以了。把语料中出现的所有汉字放在一起构成词 汇表,字数大约3万多。汉字词汇表记为V,其长度为|V|。再把每个汉字对 应的拼音加到汉字后面,拼音包括0~4的数字表示的声调,0表示轻声,1~4 表示一到四声。拼音同样需要做成拼音词汇表,由于汉字重音字多的特点, 拼音词汇表只有1千多。汉字词汇表记为P,其长度为|P|。最后,按照词汇 表中的顺序,把每个汉字转换成一个1到|V|之间的整数;每个拼音也转换成 1到|P|之间的整数。
2、每个句子作为一个样本,以一定概率随机把句子中的某些汉字替换为 另一个字(保留对应的拼音),称为mask字符,并记下每个mask的位置。
例如,把mask概率设为0.05,在读取句子中的每个字时,随机生成有 一个0~1之间的数,如果这个数小于0.05,就把这个汉字替换为一个特殊符 号
按照上述规则,在训练过程中的某一次迭代,句子“少先队员应该给老 人让座”这句话,可能会变成成“
为了神经网络计算过程使用矩阵计算的方便,还需要把句子长度调整成 全都一样,长度不足的句子需要进行填充(padding)。例如设置最大句子长 度max_length为100,一个句子长度只有80,就在后面填充20个
3、逐批次把句子输入音字Masked语言模型进行前向传播计算,输出mask 位置的预测概率分布。
把处理好的句子(数字表示),每若干句作为一个批次(一批中的句子 数称为batch_size)送入模型进行前向传播计算。转换为数字以后,需要对 每个字和拼音进行嵌入(embedding),即每个字/拼音都用一个固定维数的 浮点数向量表示。词汇表中所有符号对应的嵌入向量称为嵌入矩阵。所以模 型实际的输入是一个batch_size*max_length*E的矩阵(2阶以上的矩阵也 叫张量,Tensor),其中E为嵌入向量的维数,例如batch_size=64,max_length=100,E=256,则输入是一个64*100*256的张量。
和BERT模型类似,为了反映句子中文字的先后顺序关系,输入层还包括 位置编码(Positional Encoding)。需要说明的是,对同一个位置的汉字和 相应的拼音,对应的Positional Encoding是相同的,例如上面的例句中“队” 字和它的拼音“dui4”对应的位置编码都是3。
前向传播计算就是从输入层开始,从前到后,把前一层的输出(矩阵) 当作后一层的输入,逐层计算,直到输出层。每一层执行的计算操作取决于 层的类型。最后输出层的输出也是一个矩阵(张量),它的维数为 batch_size*max_length*|V|,表示当前批次每个句子的每个位置上的概率分 布,把它记为M。
4、用预测概率分布和真实字符计算负对数似然(negative log likelihood)loss。
对每个句子的所有mask位置,对应一个概率分布,其中词汇表中的每个 字对应一个概率。从M中取该位置上句子中实际出现的字对应的概率,连乘 起来,就得到这个句子的似然(likelihood),训练优化的目标就是最大化 这个似然,即让这些字出现的可能性最大。考虑到浮点数计算精度的稳定性 问题,实际计算时使用负对数似然,即先取对数,再累加。公式如下:
式中NLL为负对数似然,yij代表第i个句子第j个位置上实际出现的 字,
5、用反向传播算法迭代优化直到模型收敛。
反向传播算法即从后向前(从输出层先输入层的方向),逐层计算Loss 函数的梯度,按照梯度调整参数。对整个训练集重复此过程(前向传播、计 算梯度、修改参数)。整个数据集完整训练一次称为一个epoch。重复若干 个epoch,直到模型收敛,收敛的判断依据是Loss函数值足够小。
实际训练时使用随机梯度下降(SGD,Stochastic gradient descent) 或其改进算法。我们使用Adam(Adaptive Moment Estimation,自适应动量 估计)算法进行训练。这些算法都是人工神经网络和深度学习中常用的标准 算法,可以直接调用深度学习框架(如tensorflow或pytorch)中的库函数, 在此不再赘述。
实施例二
本发明公开了一种文本纠错的装置,包括:
文本预处理模块,用于将待纠错文本进行分词;
检错模块,用于预测待检字集合中每个字的概率分布,根据每个字的概 率分布确定错字位置;
候选词召回模块,用于对每个错字位置确定候选字集合;
候选词评分模块,用于对每个候选字评分;
替换和输出模块,用于对每个错字位置替换为相应的、评分最优的候选 字以及句子输出。
检错模块包括语言模型训练,训练步骤包括:随机将待训练句子中的部 分汉字替换成另一个同音字和/或近音字;逐批次将替换后的待训练句子输入 语言模型中进行前向传播计算,输出替换后文字的预测概率分布;用预测概 率分布和真实字符计算负对数似然损失函数;用反向传播算法迭代优化直到 模型收敛。
候选字集合包括同音字和近音字并排除不符合语言常识的候选字。
文本预处理模块包括将待纠错文本基于通用词典和领域词典进行分词后 基于HMM分词;把出现在混淆词中的词替换为相应的正确词;保留分出的单 字词和新词,组成待检字集合。
本具体实施方式的实施例均为本发明的较佳实施例,并非依此限制本发 明的保护范围,故:凡依本发明的结构、形状、原理所做的等效变化,均应 涵盖于本发明的保护范围之内。
- 一种文本纠错方法及文本纠错装置
- 文本纠错模型的训练方法、文本纠错处理方法和装置