一种基于粒子群优化算法的文字形状逼近方法
文献发布时间:2023-06-19 09:29:07
技术领域
本发明属于图像处理技术领域,具体涉及一种基于粒子群优化算法的文 字形状逼近方法。
背景技术
近年来,自然场景文字信息提取已越来越广泛地用于多语言翻译,自主 导航,信息检索,产品和对象识别中。文字提取包括文本检测和文本识别, 作为文本识别的重要前提,文本检测在很大程度上吸引了众多学者和行业研 究人员的关注。基于回归的文本检测方法通常在单词或行级注释的监督下对 文字所在的矩形或四边形进行位置回归。EAST、DeconvNet和Deep Regression算法是近年来性能比较出色的基于回归的自然场景文本检测算 法,具有较高的检测率和召回率,然而由于文本的形状,大小和方向的差异 以及相应的CNN模型的结构限制,基于回归的方法无法处理任意形状的长 文本实例,定位的文字框也常常不能完全包含文字,这是基于回归的目标检 测方法难以解决的问题。
发明内容
本发明的目的是提供一种基于粒子群优化算法的文字形状逼近方法,克 服了基于回归的CNN检测器对任意形状文本定位的局限性,并使定位的文 本框充分包含并贴紧文字内容。
本发明所采用的技术方案是,一种基于粒子群优化算法的文字形状逼近 方法,具体按照以下步骤实施:
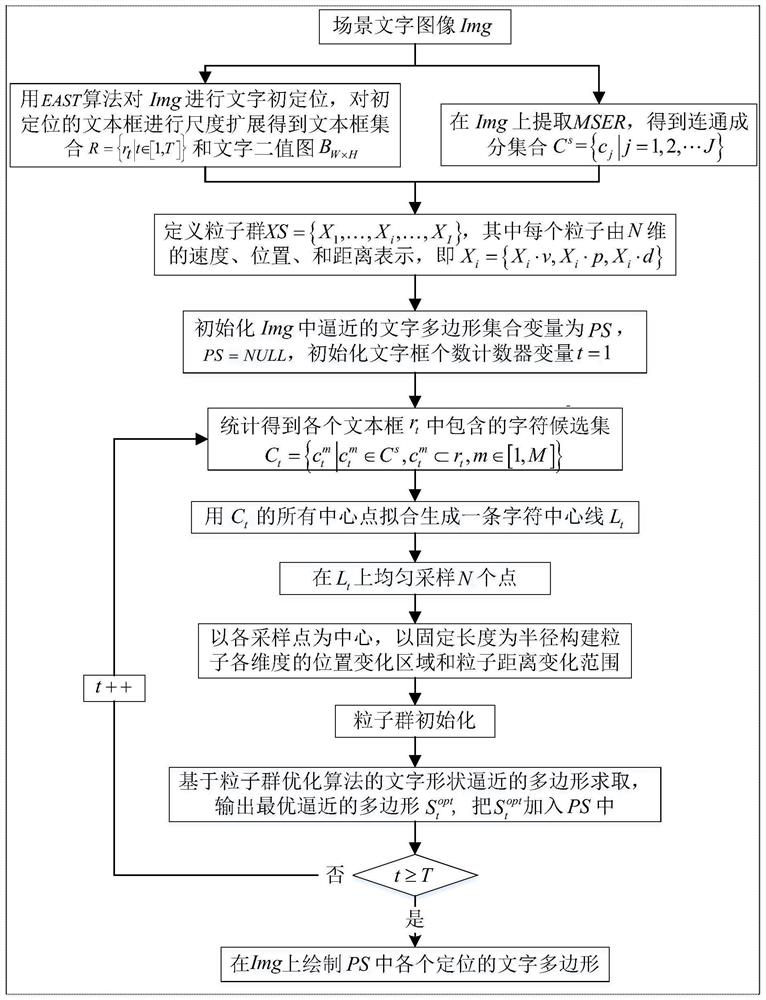
步骤1、在官方场景文字数据集中任意下载或拍摄一张自然场景文字图 像Img,图像的宽为W,高为H;
步骤2、将场景文字图像Img输入至文本检测网络模型Model
步骤3、把场景文字图像Img作为输入,调用开源的求取最大稳定极值 区域的Opencv库函数mser.detectRegions(),计算得到最大稳定极值区域集合, 即连通成分集合C
步骤4、定义粒子群;
步骤5、定义场景文字图像Img中逼近的文字多边形集合变量PS,定义 扩展文本框个数计数器变量为t,PS初始化为空,即PS=NULL,t初始化为 1,即t=1;
步骤6、统计扩展文本框r
步骤7、把C
步骤8、在拟合的字符中心线L
步骤9、对粒子群初始化;
步骤10、执行提出的粒子群文字形状逼近算法,输出最优粒子对应的逼 近文字形状的多边形
步骤11、如果t≥T,执行步骤12;否则,t累加1,即t=t+1;返回步 骤6;
步骤12、在场景文字图像Img上显示PS中的各个文字多边形。
本发明的特点还在于:
步骤1数据集为官方场景文字数据集ICDAR2015、ICDAR2017-MLT、 CTW1500、TOTAL-TEXT和MSRA-TD500中的任意一个。
步骤2中对文本置信度图M
对文本置信度图M
步骤4定义粒子群具体过程为:粒子群变量定义为XS, XS={X
步骤9中,粒子群XS的初始化具体步骤如下:
步骤9.1、定义粒子个数计数器变量为i,定义第i个粒子的维度计数器 变量为n,i初始化为1,即i=1;
步骤9.2、n初始化为1,即n=1;
步骤9.3、采用开源的随机采样的numpy库函数random.uniform()在粒子 第n维位置的变化范围
步骤9.4、如果n≥N,进入步骤9.5;否则,n累加1,即n=n+1,返回 步骤9.3;
步骤9.5、如果i≥I,结束粒子群初始化,输出初始化后的粒子群XS; 否则,i累加1,即i=i+1,返回步骤9.2。
步骤10中具体如下:
步骤10.1、输入初始化后的粒子群XS;
步骤10.2、定义粒子群优化过程中的迭代绝对误差变量为Δε,Δε初始 化为最大值E
步骤10.3、粒子个数计数器变量为i初始化为1;
步骤10.4、把粒子X
步骤10.5、根据粒子X
其中,θn是文本的近似中心线L
步骤10.6、把X
步骤10.7、将文字二值图B
步骤10.8、如果迭代次数k=1,初始化粒子X
步骤10.9、如果i≥I,进入步骤10.10;否则,i累加1,即i=i+1,返回 步骤10.4;
步骤10.10、更新粒子群的历史全局最优粒子Gbest
步骤10.11、定义粒子个数计数器变量为i,即i=1;
步骤10.12、更新粒子X
步骤10.13、如果i≥I,进入步骤10.14;否则,i累加1,即i=i+1,返 回步骤10.12;
步骤10.14、如果迭代次数k≥K或者迭代绝对误差Δε≤ε
步骤10.7中计算得到粒子X
调用开源的Opencv中统计非零像素个数的库函数countNonZero(),统计 文字二值图B
调用开源的Opencv中计算区域面积的库函数contourArea(),计算扩展文 字框r
计算扩展文字框r
统计多边形S
计算粒子X
本发明的有益效果是:
本发明一种基于粒子群优化算法的文字形状逼近方法,在EAST算法检 测结果的基础上,无需预先训练或学习,就能逼近文本形状,实现对多方向 文字和曲线文字的快速定位,本发明方法在任意形状文字检测上取得了竞争 力的结果,对快速弱检测器的文本定位性能有很大程度的改善。
附图说明
图1是本发明基于粒子群优化算法的文本形状逼近方法的流程图;
图2是本发明基于粒子群优化算法的文字形状逼近方法的粒子群初始化 流程图;
图3是本发明基于粒子群优化算法的文字形状逼近方法的文字形状逼近 多边形求取流程图;
图4是本发明基于粒子群优化算法的文字形状逼近方法的等距点求取示 意图;
图5是本发明基于粒子群优化算法的文字形状逼近方法的适应度函数求 取流程图;
图6是本发明实施例中的一幅场景文字图像;
图7是EAST文本检测网络实施例中对图6检测的文本框结果图;
图8是本发明实施例中对图6检测的文本框结果图;
图9是本发明实施例中的另一幅场景文字图像;
图10是EAST文本检测网络实施例中对图9检测的文本框结果图;
图11是本发明实施例中对图9检测的文本框结果图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于粒子群优化算法的文字形状逼近方法,如图1所示,具 体按照以下步骤实施:
步骤1、在官方场景文字数据集ICDAR2015、ICDAR2017-MLT、 CTW1500、TOTAL-TEXT和MSRA-TD500中的任意一个中任意下载或拍摄 一张自然场景文字图像Img,图像的宽为W,高为H;
步骤2、将场景文字图像Img输入至现有的文本检测网络模型Model
对文本框r’
文本框r’
场景文字图像Img上的水平和垂直坐标;在场景文字图像Img上以center
对文本置信度图M
对文本置信度图M
步骤3、把场景文字图像Img作为输入,调用开源的求取最大稳定极值 区域的Opencv库函数mser.detectRegions(),计算得到最大稳定极值区域 (Maximally StableExtremal Region,简称MSER)集合,即连通成分集合 C
步骤4、定义粒子群;定义粒子群具体过程为:粒子群变量定义为XS, XS={X
步骤5、定义场景文字图像Img中逼近的文字多边形集合变量为PS,定 义扩展文本框个数计数器变量为t,PS初始化为空,即PS=NULL,t初始化 为1,即t=1;
步骤6、统计扩展文本框r
步骤7、把C
步骤8、在拟合的字符中心线L
步骤9、粒子群初始化;粒子群XS的初始化具体步骤如下,如图2所示:
步骤9.1、定义粒子个数计数器变量为i,定义第i个粒子的维度计数器 变量为n,i初始化为1,即i=1;
步骤9.2、n初始化为1,即n=1;
步骤9.3、采用开源的随机采样的numpy库函数random.uniform()在粒子 第n维位置的变化范围
步骤9.4、如果n≥N,进入步骤9.5;否则,n累加1,即n=n+1,返回 步骤9.3;
步骤9.5、如果i≥I,结束粒子群初始化,输出初始化后的粒子群XS; 否则,i累加1,即i=i+1,返回步骤9.2。
步骤10、执行提出的粒子群文字形状逼近算法,输出最优粒子对应的逼 近文字形状的多边形
步骤10.1、输入初始化后的粒子群XS;
步骤10.2、定义粒子群优化过程中的迭代绝对误差变量、迭代次数计数 器变量和总迭代次数变量分别为Δε、k和K,定义粒子群的历史最优变量为 Gbest
步骤10.3、粒子个数计数器变量为i初始化为1;
步骤10.4、把粒子X
步骤10.5、如图4所示,根据粒子X
其中,θ
步骤10.6、把X
步骤10.7、如图5所示,将文字二值图B
计算得到粒子X
调用开源的Opencv中统计非零像素个数的库函数countNonZero(),统计 文字二值图B
调用开源的Opencv中计算区域面积的库函数contourArea(),计算扩展文 字框r
计算扩展文字框r
统计多边形S
计算粒子X
步骤10.8、如果迭代次数k=1,初始化粒子X
步骤10.9、如果i≥I,进入步骤10.10;否则,i累加1,即i=i+1,返回 步骤10.4;
步骤10.10、更新粒子群的历史全局最优粒子Gbest
步骤10.11、定义粒子个数计数器变量为i,即i=1;
步骤10.12、更新粒子X
步骤10.13、如果i≥I,进入步骤10.14;否则,i累加1,即i=i+1,返 回步骤10.12;
步骤10.14、如果迭代次数k≥K或者迭代绝对误差Δε≤ε
步骤11、如果t≥T,执行步骤12;否则,t累加1,即t=t+1;返回步 骤6;
步骤12、在场景文字图像Img上显示PS中的各个文字多边形。
本发明基于粒子群优化算法的文字形状逼近方法,首先采用基于回归的 文字检测方法对场景文字图像中的文字所在矩形或四边形进行检测定位;其 次,用MSER检测算法把场景图像中的各个连通成分提取出来,从而得到一 系列的字符框,再统计得到各扩展文本框中包含的字符框集合;最后,进行 基于粒子群的场景图像中各定位文字框的调整使其逼近文字形状。在原有粒 子群算法的基础上,在粒子的特征描述方面引入一个粒子的等距信息,采用 粒子群的优化迭代过程,使由粒子计算得到的多边形逐渐逼近文字形状最终得到最优的文字外围框。具体过程为:利用各扩展文本框中包含的字符框中 心点拟合一条字符中心线;在字符中心线上均匀采样N个点,以各采样点为 中心以固定长度为半径构建粒子的位置活动范围,以一维区间构建粒子的等 距范围,由粒子的位置和等距值计算得到粒子对应的最初的文字逼近多边 形;通过粒子群的优化过程最终得到文字的最佳逼近多边形。本发明克服了 基于回归的CNN检测器对任意形状文字定位的局限性,并使定位的文本框充 分包含并贴紧文字内容,改善了弱检测器的性能,相对现有先进的文字检测 方法,本发明方法在任意形状文字检测上取得了竞争力的结果。
实施例
本发明从场景文字数据集中取出任意一张图片,分别采用EAST文本检 测网络和本发明的方法进行文字定位,图6表示一幅场景文字图像,图7表 示EAST文本检测网络在图6中检测到的文本框结果图,白色框是文本框, 图8表示本发明的方法在图6中检测到的文本框结果图,白色框是文本框; 图9表示另一幅场景文字图像,图10表示EAST文本检测网络在图9中检 测到的文本框结果图,白色框是文本框,图11表示本发明的方法在图9中 检测到的文本框结果图,白色框是文本框。通过主观效果图对比可以看到 EAST文本检测网络检测到的文本框往往无法包全文字,并且无法适应弯曲 文本的形状,而本发明的方法有效解决了这些问题,既能完整包含文字,又 实现了任意方向文字形状的逼近,保证了文字内容的紧凑型,对EAST弱检 测器的性能在一定程度上进行了改善。
通过文字检测率对本发明的文字逼近效果进行评价,评价结果如表1和 表2所示:
①准确率(Precision,P)。准确率表示检测出的正确目标个数占检测 出的总目标个数的比例。
②召回率(Recall,R)。召回率表示是检测出的正确目标个数占所有 标注的真值框总数目的比例。
③调和平均值(F-measure,F)。调和平均值是对召回率和准确率的 加权平均值,因此F-measure是检测算法性能的综合度量,其值越高即算法 性能越好,其计算表达式为:
表1在多方向文字数据集上的文字检测对比结果表
表2在曲线文字数据集上的文字检测对比结果表
由表1、表2可知,本发明在多个多方向文字数据集和曲线文字数据集 上的文字检测率结果都很高,并且通过表1和表2的客观数据可以看到,本 发明方法在各个数据集上的调和平均值相比EAST方法有了显著提高;由此 可以得出,本发明对快速弱检测器的文本定位性能有很大程度的改善。本发 明可以应用于不同场景、不同远近、不同方向、不同大小、不同颜色的多方 向文字和曲线文字的检测。
通过上述方式,本发明提出了一种基于粒子群优化算法的文字形状逼近 方法,在EAST算法检测结果的基础上,无需预先训练或学习,就能逼近文 字形状,实现对多方向和曲线文字的快速定位,实验验证本发明在任意方向 和任意形状文字检测上取得了竞争力的结果,对快速弱检测器的文本定位性 能有很大程度的改善。
- 一种基于粒子群优化算法的文字形状逼近方法
- 一种基于古文字壶字形状的家用照明装置