一种检测医保欺诈的方法、系统及存储介质
文献发布时间:2023-06-19 09:29:07
技术领域
本发明涉及医疗技术领域,尤其涉及的是一种检测医保欺诈的方法、系统及存储介质。
背景技术
医疗保险是我国的一项社会保障项目,是为补偿公民或劳动者因为疾病风险造成的经济损失而建立的一种社会保障制度。但是,随着医疗保险的普及,伴随的是不法分子借助全民医保的契机进行医疗保险欺诈的现象层出不穷,造成全国财政医疗卫生支出额外增高。
因此,需对医保欺诈活动进行有效的检测,现有的检测方法包括非监督学习和监督学习。其中,非监督学习依赖于异常值分析来发现未标记数据中潜在的异常,但是用于检测异常的方法并不适用于如医疗保险欺诈数据等高度偏斜的数据;监督学习则需要有大量标记点数据,通过标记欺诈和非欺诈示例以实现预测,但由于缺少专家和医疗欺诈调查,实际能够做到的标记点很少,并不能够实现有效的检测。
可见,目前针对医保欺诈检测的两种方式均不能对真实的医保欺诈进行有效检测,并不利于预防医保欺诈行为的发生。
因此,现有技术存在缺陷,有待改进与发展。
发明内容
本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供一种检测医保欺诈的方法、系统及存储介质,旨在解决现有技术中的医保欺诈检测方法并不能够进行有效检测,不能预防医保欺诈行为的问题。
本发明解决技术问题所采用的技术方案如下:
一种检测医保欺诈的方法,其中,包括:
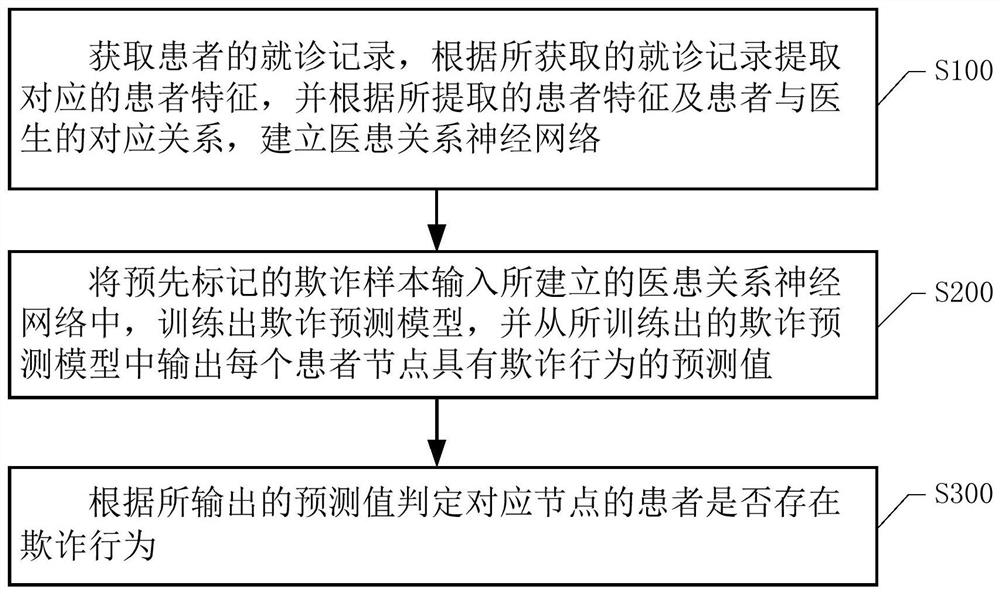
获取患者的就诊记录,根据所获取的就诊记录提取对应的患者特征,并根据所提取的患者特征及患者与医生的对应关系,建立医患关系神经网络;
将预先标记的欺诈样本输入所建立的医患关系神经网络中,训练出欺诈预测模型,并从所训练出的欺诈预测模型中输出每个患者节点具有欺诈行为的预测值;
根据所输出的预测值判定对应节点的患者是否存在欺诈行为。
能够通过机器主动学习并预测出存在欺诈行为的患者节点,方便对医保欺诈行为进行有效的管理,以利于医保体系健康普及。
进一步地,所述将预先标记的欺诈样本输入所建立的医患关系神经网络中,训练出欺诈预测模型,并从所训练出的欺诈预测模型中输出每个患者节点具有欺诈行为的预测值之后包括:
监测是否有新增的就诊记录;
若有新增的就诊记录,将具有预测值的患者节点输入预先建立的动态更新网络中,删除其中无效的患者节点;
将删除无效节点后的其余就诊记录与新增的就诊记录整理成更新后的就诊记录;
根据更新后的就诊记录继续判定每个节点对应的患者是否存在欺诈行为。
通过及时对数据进行更新,以删除无效的节点,在保证预测准确度的前提下能够提高预测的效率,保证系统快速运行以预测出更多的具有欺诈行为的患者节点。
进一步地,所述若有新增的就诊记录,将具有预测值的患者节点输入预先建立的动态更新网络中,删除其中无效的患者节点,其中,判定无效的患者节点的依据为:
根据具有预测值的患者节点的生成日期及预测值,分别计算每个患者节点的优先级;
对每个患者节点的优先级进行排序,选取优先级低的作为无效的患者节点。
通过有效的方式定义无效的患者节点,能进一步提高预测的准确性,保证进行预测时所采取的数据的有效度,利于提高预测速率。
进一步地,所述删除其中无效的患者节点,具体包括:
根据新增的就诊数量,以优先级低的患者节点为序删除同等数量的无效的患者节点。
进一步地,所述将预先标记的欺诈样本输入所建立的医患关系神经网络中,其中,得到预先标记的欺诈样本的步骤包括:
采用预设方式从就诊记录中选取部分就诊记录作为待标记样本;
对所选取的待标记样本进行专家标注,标识待标记样本中具有欺诈行为的样本,得到预先标记的欺诈样本。
通过专家进行待标记样本的标注,提高了得到欺诈样本的权威度,使得所预测出的结果真实有效。
进一步地,所述采用预设方式从就诊记录中选取部分就诊记录作为待标记样本,其中,采用预设方式选取待标记样本的方式至少包括:
通过最大熵选择策略计算出每个患者的熵值,选取所计算熵值中最大值作为待标记样本;
或者,采取随机策略随机采取就诊记录中部分就诊记录作为待标记样本;
或者,通过最大概率策略计算每个患者的概率值,选取所计算概率值中最大值作为待标记样本。
通过随机的方式选择待标记样本,最大程度地增加了选择的随机性,利于提高预测的准确度。
进一步地,所述获取患者的就诊记录,根据所获取的就诊记录提取对应的患者特征,并根据所提取的患者特征及患者与医生的对应关系,建立医患关系神经网络,之前包括:
将患者就诊信息中的患者身份信息进行匿名处理,并将处理后的就诊信息转换成数据结构类型的就诊记录。
通过对患者身份信息进行匿名处理,能够保障患者隐私,也避免了患者信息泄露。
进一步地,所述获取患者的就诊记录,根据所获取的就诊记录提取对应的患者特征,并根据所提取的患者特征及患者与医生的对应关系,建立医患关系神经网络,具体包括:
获取患者的就诊记录,从就诊记录中提取对应的患者特征,建立患者特征度矩阵;
分析就诊记录中医生与患者之间的医患关系,建立对应的医患关系邻接矩阵;
根据患者特征度矩阵和医患关系邻接矩阵,建立医患关系神经网络。
本发明还公开一种系统,其中,包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于执行如上所述的检测医保欺诈的方法。
本发明还公开一种存储介质,其中,所述存储介质存储有计算机程序,所述计算机程序能够被执行以用于实现如上所述的检测医保欺诈的方法。
本发明所提供的一种检测医保欺诈的方法、系统及存储介质,其中,所述方法包括:获取患者的就诊记录,根据所获取的就诊记录提取对应的患者特征,并根据所提取的患者特征及患者与医生的对应关系,建立医患关系神经网络;将预先标记的欺诈样本输入所建立的医患关系神经网络中,训练出欺诈预测模型,并从所训练出的欺诈预测模型中输出每个患者节点具有欺诈行为的预测值;根据所输出的预测值判定对应节点的患者是否存在欺诈行为。通过机器学习的方法预测患者是否存在欺诈行为,降低了预测欺诈行为的难度,且能够有效地检测医保欺诈行为,利于维护医保体系健康普及。
附图说明
图1是本发明中检测医保欺诈的方法的较佳实施例的流程图。
图2是本发明中步骤S100的具体实施例的流程图。
图3是本发明中结合动态更新网络后的较佳实施例的流程图。
图4是本发明中表示欺诈预测模型与动态更新网络联系的较佳实施例的流程图。
图5是本发明中图3中步骤S410的具体实施例的流程图。
图6是本发明中更新算法的执行过程的较佳实施例的流程图。
图7是本发明中使用与不使用动态更新网络的实验结果对比图。
图8是本发明系统的较佳实施例的功能原理框图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
医疗保险是我国的一项社会保障项目,是为补偿公民或劳动者因为疾病风险造成的经济损失而建立的一种社会保障制度。通过个人和用人单位缴纳一定的保险金额,当参保人患病就诊产生医疗费用后,医疗保险机构给予患者一定的经济补偿。截止2018年底,中国基本医疗保险参与人数已经达到13.5亿人,参保率超过了95%。同时,医疗保险基金在本文生活中扮演者举足轻重的作用,根据人社部数据统计,我国的医疗支出费用从2008年的1.45万亿增长到2015年的4.10万亿,年均增长率达16%。然而就在医保基金压力不断增大的同时,不法分子借助全民医保的契机进行医疗保险欺诈的现象层出不穷。
医保欺诈是医疗服务过程中的以谋取利益为目的的欺诈行为。此处的欺诈行为主要包括两大类:患者利用某种手段骗取医保;患者和医生联合骗取医保。2013年到2017年,全国财政医疗卫生累计支出59502亿元,年均增幅为11.7%,在国家对医疗卫生重视的同时,由于医保欺诈所造成的额外支出也越来越高。
现有的对于医保欺诈的检测可以分为两个主要分支:非监督学习方法和监督学习方法。其中,非监督学习依赖于异常值分析来发现未标记数据中潜在的异常,但是,离群值检测方法不适用于高度偏斜的数据,例如医疗保险欺诈数据。监督学习则需要大量标记数据点,包括欺诈和非欺诈示例,以实现良好的预测性能,但是,由于缺少领域专家和昂贵的医疗欺诈调查,可标记的点极少;此外,医疗欺诈数据集的标签极不平衡,因为通常不会在真实明确公开非欺诈示例。为解决此问题,当缺乏非欺诈示例时,一类分类(OCC)算法是用于对医疗欺诈数据进行建模的解决方案,然而,在医疗欺诈数据集中,OCC方法仍然由于训练点数量不足而导致预测性能不佳。故而,以上对医保欺诈活动进行检测的非监督学习和监督学习方法都存在不足,不能够对欺诈行为进行有效的预测。
基于此,本发明利用机器学习方式提出了一种检测医保欺诈的方法,进而解决了现有技术中不能有效预测欺诈行为的问题,以下对本发明所述的方法进行详细地解释说明。
请参见图1,图1是本发明中一种检测医保欺诈的方法的流程图。如图1所示,本发明实施例所述的一种检测医保欺诈的方法包括以下步骤:
S100、获取患者的就诊记录,根据所获取的就诊记录提取对应的患者特征,并根据所提取的患者特征及患者与医生的对应关系,建立医患关系神经网络。
具体地,当患者在门诊挂号使用医保时,医院医生将患者的就诊信息输入医疗信息系统中,然后医疗信息系统中存在该患者的就诊记录。其中,就诊信息包括但不限于患者身份信息、参保类型、购买药品项目、购买数量、就诊日期等,由于就诊信息可根据患者的就诊情况进行逐样增加,且参保类型大同小异,故而,此处并不对就诊信息做一一详解,可以理解地,此处仅用于举例说明就诊信息所涵盖的部分内容,并不用于限定本发明。
且一般情况下,进行医保欺诈分析时,分析医生与患者间的关系也至关重要。患者就诊信息中也包含当次医疗项目接诊的医生,通过获取患者的就诊记录,能够得到患者详细的就诊信息以及单次就诊时对应接诊的医生。
本发明通过采用机器学习和深度学习的方法对从就诊信息中所提取出的患者特征和患者与医生关系进行建模,进而建立医患关系神经网络,能够加强各个患者节点之间的联系,进而有利于对患者节点进行分类。
S200、将预先标记的欺诈样本输入所建立的医患关系神经网络中,训练出欺诈预测模型,并从所训练出的欺诈预测模型中输出每个患者节点具有欺诈行为的预测值。
具体地,将选择好的具有标记的欺诈样本输入医患关系神经网络中,然后进行模型训练,通过机器主动学习策略,进而根据预先标记的欺诈样本对更多的患者节点进行分类与标记,即计算出所有患者节点具有欺诈行为的预测值,进而通过预测值分析患者的欺诈行为,有利于对医保欺诈行为进行检测,进而监督医保欺诈行为,帮助医保健康普及。
S300、根据所输出的预测值判定对应节点的患者是否存在欺诈行为。
具体地,通过所计算出的预测值的大小即可判定存在欺诈行为可能性的高低,一般地,将预测值较大的作为重点分析对象,而具体以预测值的大小判定欺诈行为的界限可由领域专家或者医保管理人员或者医院自定义设定,此处并不做详述,仅用于说明通过预测值即可判定欺诈行为。
在一实施例中,如图2所示,所述步骤S100具体包括:
S110、获取患者的就诊记录,从就诊记录中提取对应的患者特征,建立患者特征度矩阵。
S120、分析就诊记录中医生与患者之间的医患关系,建立对应的医患关系邻接矩阵。
当医疗信息系统中录入患者的就诊信息之后,对应地系统中就会增加就诊记录,通过从系统的所有就诊记录中提取每个患者的特征,以及每个患者就诊时对接的医生,通过对两种信息进行处理,以数据的形式展示,便于进行机器学习。
S130、根据患者特征度矩阵和医患关系邻接矩阵,建立医患关系神经网络。
其中,对患者特征建立特征度矩阵,以及根据医生与患者间关系建立邻接矩阵,之后根据度矩阵与邻接矩阵形成医患关系神经网络的算法演示如下:
具体地,定义患者(P)与医生(D)的关系网(P-D)为一个无向图
然后,基于谱领域卷积定义一个图卷积操作
通过对患者节点进行卷积操作,可以让相互连接的患者节点之间实现信息互通,使同类型的患者节点分布更加紧密。
之后,使用拉普拉斯矩阵对度矩阵和邻接矩阵进行处理,实现特征分解(也即谱分解),定义其表达式如下:
其中,I
由于上述公式所呈现的复杂度为O(n
之后通过GCN提取拓扑图的空间特征,以便于特征提取,所以Graph ConvolutionNetwork(GCN)有了如下逐层传播规则:
其中H
对于本发明中所建立的监督学习模型,对预测模型进行训练,一般要求有足够数据的已标记数据,且已标记数据越多预测精度越高。由于在实际应用中,欺诈行为的标注主要依赖于领域专家去调查,这样的成本无疑是巨大的,且调动专家调查的效率也很低,况且,日益剧增的医疗数据中进行人工标注,显然并不现实。故而,在本发明中通过主动学习的方法选取最具价值的数据进行标注,以减少现有方式进行标注所要付出的人力和财力。
在一具体实施例中,本发明通过主动学习的方法进行欺诈样本标注的步骤包括:
S210、采用预设方式从就诊记录中选取部分就诊记录作为待标记样本。
S220、对所选取的待标记样本进行专家标注,标识待标记样本中具有欺诈行为的样本,得到预先标记的欺诈样本。
在一具体实施例中,所述步骤S210中采用预设方式选取待标记样本的方式至少包括最大熵策略、随机策略、最大概率策略中的一种或几种,可以理解地,此处仅对随机取样的几种方式进行了简单的介绍,而具体地将此处所列举的几种策略进行结合或者将其与其他的手段进行结合,进而对整体采取的样本选取平均点、均值点、中间点等方式均为本实施例所列举方式的延伸,此处并不做详解,其均为本实施例所涉及的保护范围。
方式一、通过最大熵选择策略计算出每个患者的熵值,选取所计算熵值中最大值作为待标记样本。
其中,熵的计算公式为:
我们采用最大熵(最不确定)策略选择标注节点。
通过采用最大熵选择策略(Maximum Entropy selection:MEs)对就诊记录中最不确定分布的就诊记录进行选取,能够保证数据的随机性。具体地,通过条件熵描述样本点属于哪个类别的自信值,若条件熵值越大,说明对某个样本点的分类越不明确(分类信心越小);若条件熵值越小,说明对某个样本点的分类越明确(分类信心越大)。条件熵值由以下公式计算得到:
H(Y|Z)=H(Z,Y)-H(Z)
通过对每个患者节点计算熵值,然后对其进行排序,每次都选择熵最大的节点进行欺诈标注。
方式二、采取随机策略随机采取就诊记录中部分就诊记录作为待标记样本。即随机从所有就诊记录中选取预设数量的就诊记录作为待标记样本。
方式三、通过最大概率策略计算每个患者的概率值,选取所计算概率值中最大值作为待标记样本。具体地,通过计算每个患者的概率值,通过概率值的大小选择待标记样本,由于计算概率值为现有技术,此处不再进行举例。
需要说明的是,上述三种方式中优先选择最大熵策略选取待标记样本,能够以最大的随机性选择出最不确定的待标记样本,进而增加了样本选取的真实性。
在一实施例中,所述步骤S200中训练出预测模型的步骤包括:
通过结合医患关系神经网络与变分自解码器模型,能够建立出预测模型。
一般情况下,贝叶斯公式:
自编码器(Auto-Encoder)包含两个部分:解码器和编码器。本发明中能够直接得到的是患者的就诊数据X,同时X又由隐藏变量Z产生,从Z→X的生成模型为p
通过先获取患者的就诊记录,然后使用编码器q
而两个就诊记录之间分布的相似程度用KL散度(Kullback–Leibler divergence)衡量,即得出如下公式:
进一步将医患关系神经网络与自分编码器进行结合得到预测模型的表达式为:
通过欺诈预测模型可对患者节点进行预测,具体以患者的就诊记录作为输入数据,建立医患关系神经网络,以医患关系神经网络的输出作为变分自解码器的输入,最终输出预测结果。在欺诈预测模型中对所有患者节点进行训练,当达到预设的训练次数之后,能够完成对患者节点中未知患者节点的预测分类,即计算出患者节点具有欺诈行为的预测值,具体地,也可将预测值以0和1进行划分,其中为非欺诈,1为欺诈。
在实际应用场景中,医保欺诈行为方法层出不穷,故而需要对医保欺诈预测模型及时进行更新,但由于图关系网络的复杂性和大量的节点,每次训练更新都需要消耗大量的时间和计算资源,导致在实际应用中具有极大的局限性。
且随着时间的推移,患者就诊记录也会增多,从而导致医-患图关系网络中患者节点越来越多,则对机器计算的条件(硬件、内存、CPU等)要求越高,且随着患者节点的增多,计算量也随之剧增,造成系统预测欺诈值的难度增大,很难应用的实际中。
故而,基于上述原因,本发明还提出了一种在线更新策略,使每天新增数据自动进行更新,然后通过在加入新节点的同时删除无用的旧节点,使图中节点保持在一定数量,从而实现系统可以在短时间内完成训练,保证系统良好的实时性。
在一实施例中,本发明中进行在线更新的策略实施步骤如下:
如图3所示,在所述步骤S200之后还包括:
S400、监测是否有新增的就诊记录。
若有,执行步骤S410、将具有预测值的患者节点输入预先建立的动态更新网络中,删除其中无效的患者节点。
具体地,通过监测新增的就诊记录,当有新增就诊记录时,通过将新增就诊记录加入欺诈预测模型中能够及时对新增就诊记录进行欺诈分析,且进一步通过将欺诈预测模型中原有的无效数据移除,能够保证系统运行效率。而当未监测到有新增的就诊记录时,则按照原先设定的预测周期对所有就诊记录进行欺诈预测,保证所计算出预测值的时效性。
S420、将删除无效节点后的其余就诊记录与新增的就诊记录整理成更新后的就诊记录。
S430、根据更新后的就诊记录继续判定每个节点对应的患者是否存在欺诈行为。具体地,将更新后的就诊记录作为步骤S100中获取就诊记录的源数据循环执行步骤S100-S430,达到不断更新数据以及预测节点的效果,保证预测模型的可实施性。
具体地,通过在线的更新策略,可以定时对系统进行更新,在每次更新时删除图关系网络中一些信息量相对较少的节点,通过不断的迭代,在保证模型预测准确率的同时保持实时性和训练效率。
在一流程图中,如图4所示,为更好地表示本发明中建立欺诈预测模型与动态更新网络之间的联系,用以下图示进一步说明:
S10、开始;
S20、获取就诊记录;从数据中心获取就诊记录;
S30、提取患者特征;从就诊记录中提取患者特征;
S40、根据患者特征建立医患关系神经网络;根据所提取的患者特征及医生与患者的关系建立医患关系神经网络;
S50、获取预先标记的欺诈样本;从数据中心中选取部分就诊记录进行专家标记,以标注欺诈样本;
S60、训练出欺诈预测模型;根据所标记的欺诈样本与医患关系神经网络建立欺诈预测模型;
S70、输出每个患者节点对应的预测值;输出所有患者节点具有欺诈行为的预测值;
S80、是否有新增的就诊记录;将新的就诊记录输入数据中心中;
若有,执行S81、将所有患者节点的预测值输入动态更新网络;
S82、删除无效的患者节点,与新增就诊记录组成更新后的就诊记录;形成新的就诊记录后更新数据中心的数据;
若无,执行S90、结束;
循环步骤S20-S90。
为便于对所有就诊记录进行描述,在此实施例中引入了数据中心这一概念,用于表述就诊记录的流转过程。
在进一步具体实施例中,如图5所示,所述步骤S410具体包括:
S411、将具有预测值的患者节点输入预先建立的动态更新网络中。
S412、根据具有预测值的患者节点的生成日期及预测值,分别计算每个患者节点的优先级。
S413、对每个患者节点的优先级进行排序,选取优先级低的作为无效的患者节点。
S414、根据新增的就诊数量,以优先级低的患者节点为序删除同等数量的无效的患者节点。
其中,将判定患者节点为无效节点的因素定为:患者的就诊时间(越早越优先删除)、患者被预测为欺诈的概率(越小越优先删除)。
具体地,如图6所示,更新算法的执行流程如下:
S42、输入就诊记录V和医院新增的数据W;
S43、根据V生成医患关系神经网络(邻接矩阵A和特征矩阵X);
S44、使用变分自解码关系模型对医患关系神经网络中的所有患者节点进行预测,输出每个患者节点的预测值p;
S45、对每个患者节点的输入日期d进行标准化;
S46、将每个患者节点的预测值p和输入日期d进行联合;通过s=λ
S47、对s进行排序,根据新增数据W的数量,删除s中对应数量的节点;
S48、结合删减后的节点和新增节点对系统迭代更新。
其中,s为优先级(越小越优先),p为患者节点被预测为欺诈的概率,d为患者的就诊日期。λ
在一实施例中,在所述步骤S100之前还包括:
将患者就诊信息中的患者身份信息进行匿名处理,并将处理后的就诊信息转换成数据结构类型的就诊记录。
通过对患者身份信息进行匿名处理,能够保障患者隐私,也避免了患者信息泄露。
本发明通过使用医患关系神经网络和变分自编码器,能够对患者节点的分布进行有效预测,且通过预设条件筛选出最佳的标记样本进行专家标记,然后输入模型中进行训练,进而减少了人工标注成本,也增加了欺诈预测的准确率。进一步地,本发明还提供了在线动态更新网络模型,能够保证系统中需预测的患者节点数量是固定的前提下,对系统进行实时更新,从而提升了欺诈预测模型的预测效率和可实施性;且通过对无效节点进行删除,能够节省预测时长及避免系统资源的占用,也提高了预测的准确率。
本发明还公开一种系统,其中,如图8所示,包括有存储器20,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器20中,且经配置以由一个或者一个以上处理器10执行所述一个或者一个以上程序包含用于执行如上所述的检测医保欺诈的方法;具体如上所述。
本发明还公开一种存储介质,其中,所述存储介质存储有计算机程序,所述计算机程序能够被执行以用于实现如上所述的检测医保欺诈的方法;具体如上所述。
综上所述,本发明公开的一种检测医保欺诈的方法、系统及存储介质,通过获取就诊记录,并根据就诊记录提取患者特征以及患者与医生之间的关系,之后通过机器学习和深度学习的方法对提取的特征进行建模,建立了欺诈预测模型,从而实现在少量的人工干预情况下检测出医保欺诈行为,保证医保欺诈的有效性,进而节省了大量的人力、物力和财力支出。再者,本发明还提出了在线动态更新策略,对图神经网络中的患者节点进行动态更新,从而可以保证预测模型的实时性和准确性,也保证了系统运行效率。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 一种检测医保欺诈的方法、系统及存储介质
- 一种基于聚类的医保欺诈行为的检测方法及系统