一种异常停留车辆的检测方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及大数据分析技术领域,尤其涉及一种异常停留车辆的检测方法。
背景技术
随着大数据时代的来临,将大数据分析方法应用到公共安全的场景是必然的发展趋势。一些犯罪行为发生之前,往往犯案人员会到案发地点进行踩点,通过筛选出案发地点附近疑似踩点的车辆,可以帮助锁定嫌疑人。
相比于人工筛选,通过大数据分析的方法可以更加快捷准确的筛选出异常停留的车辆。但是,某些情况下,犯罪前进行踩点的车辆在卡口之间停留的时间不会特别长,仅仅根据停留时间的长短来判断车辆是否停留存在一定的局限性,即无法区分是道路拥堵还是车辆停留造成的通行时间较长。
发明内容
本发明主要解决现有技术的无法区分是道路拥堵还是车辆停留造成的车辆停留的技术问题,提出一种异常停留车辆的检测方法,能够筛选出指定区域、指定时间段内非规律性停留的车辆,筛选出异常停留车辆,帮助警方找到疑似作案前踩点的车辆。
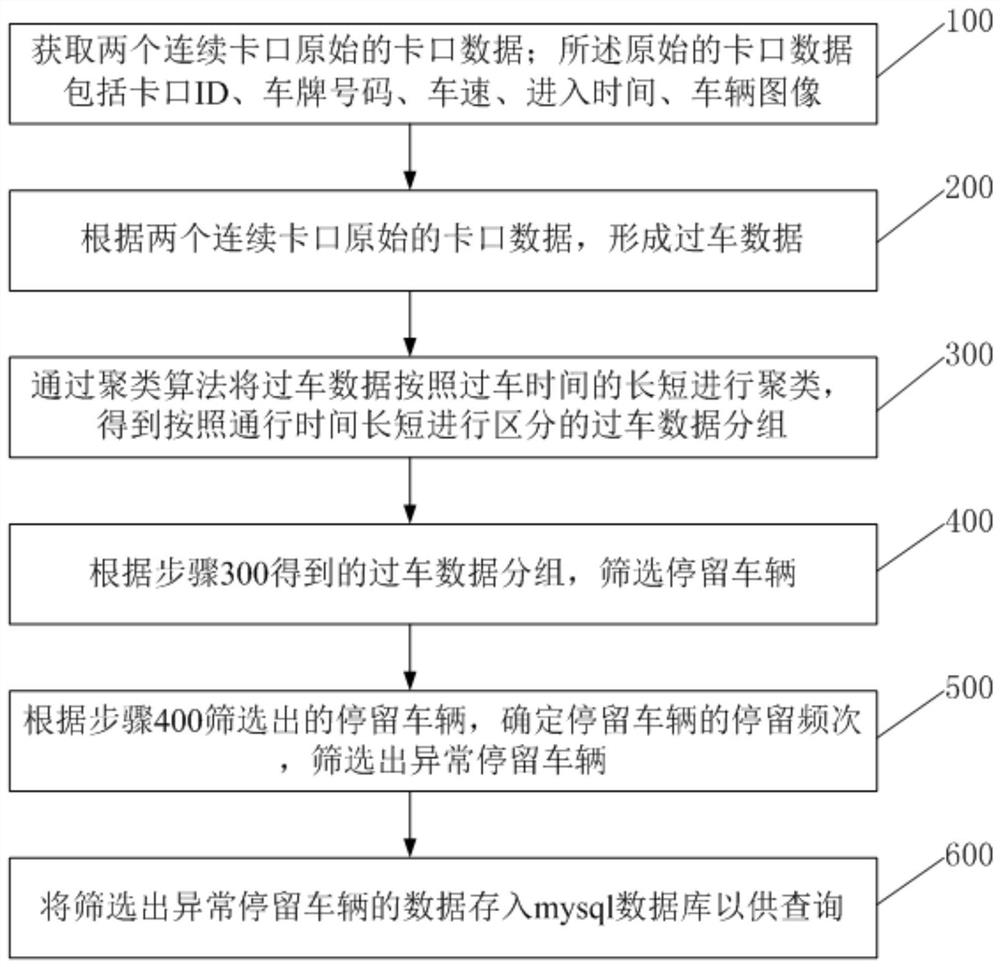
本发明提供的一种异常停留车辆的检测方法,包括:
步骤100,获取两个连续卡口原始的卡口数据;所述原始的卡口数据包括卡口ID、车牌号码、车速、进入时间、车辆图像;
步骤200,根据两个连续卡口原始的卡口数据,形成过车数据;
步骤300,通过聚类算法将过车数据按照过车时间的长短进行聚类,得到按照通行时间长短进行区分的过车数据分组;
步骤400,根据步骤300得到的过车数据分组,筛选停留车辆;
步骤500,根据步骤400筛选出的停留车辆,确定停留车辆的停留频次,筛选出异常停留车辆。
进一步的,在步骤500之后,还包括:
步骤600,将筛选出异常停留车辆的数据存入数据库以供查询。
进一步的,步骤300,通过K均值聚类算法将过车数据按照过车时间的长短进行聚类。
进一步的,步骤300包括以下过程:
步骤301,确定聚类分组数K和最大更新次数N;
步骤302,在数据范围内随机选取K个起始过车数据分组中心;
步骤303,遍历所有数据,对于每一条过车数据,计算这条数据通行时间与各过车数据分组中心的差距,将该过车数据放入差距最小的过车数据分组中;
步骤304,将各过车数据分组的中心更新为该过车数据分组的平均通行时间;
步骤305,重复302-303,直到各过车数据分组不再变化,计算各过车数据分组通行时间方差的加权平均和;
步骤306,将第一次的聚类结果设为起始最优结果,重复步骤301-步骤305,如果新结果的各过车数据分组的通行时间方差的加权平均和小于当前最优结果的通行时间方差的加权平均和,则更新最优结果;如果连续N次聚类都未更新最优结果,则停止聚类,得到最优结果;
步骤307,将最优结果中的过车数据分组,按照平均通行时间由大到小排序输出。
进一步的,步骤400包括以下过程:
根据预设的停留等级制定停留指标组,停留指标组包括[A1、A2、A3、…、AM];
超过最大的A1分位数的记录将被判定为停留车辆,停留等级为一级;超过最大的A2分位数的记录的停留等级为二级;超过最大的A3分位数的记录的停留等级为三级;…;超过最大的AM分位数的记录的停留等级为M级;有多个停留等级时取最大停留等级。
进一步的,所述过车数据的格式为:[车牌,过车时间,进入时间]。
本发明提供的一种异常停留车辆的检测方法,通过获取两个连续卡口原始的卡口数据,并形成过车数据;通过聚类算法将过车数据按照过车时间的长短进行聚类,得到按照通行时间长短进行区分的过车数据分组;再根据过车数据分组,筛选停留车辆;在根据停留车辆,筛选出异常停留车辆;本发明能够基于道路拥堵和车辆停留两种情况的特征差异(停留车辆的通行时间较长且与其他正常通行车辆的通行时间有明显差异;道路拥堵时通行时间长的车辆之间的通行时间相近),可以较为准确的区分出道路拥堵和车辆停留;能够筛选出指定区域、指定时间段内非规律性停留的车辆,帮助警方找到疑似作案前踩点的车辆;通过聚类方法有效的解决了从道路拥堵和车辆停留两种情况造成的通行时间过长的数据中筛选出停留的车辆的问题。
附图说明
图1是本发明提供的异常停留车辆的检测方法的实现流程图。
具体实施方式
为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部内容。
如图1所示,本发明实施例提供的异常停留车辆的检测方法,包括:
步骤100,获取两个连续卡口原始的卡口数据。
在交通卡口,普遍是通过高清卡口系统采集卡口数据,并将卡口数据上传到服务器;向服务器中读取一段时间(如一个月内)两个连续卡口的数据,按天分类。两个连续卡口分别为第一卡口和第二卡口。
其中,原始的卡口数据包括卡口ID、车牌号码、车速、进入时间、车辆图像等数据。原始的卡口数据格式为:[卡口ID,车牌号码,进入时间,…]
步骤200,根据两个连续卡口原始的卡口数据,形成过车数据。
过车数据的格式为:[车牌,过车时间,进入时间]
其中,过车时间为车辆进入第一卡口到车辆进入第二卡口所经过的时间长度,进入时间为车辆通过第一卡口的时间。将整理后的过车数据按照时段分类。
步骤300,通过K均值聚类(k-means clustering algorithm,K-means)算法将过车数据按照过车时间的长短进行聚类,得到按照通行时间长短进行区分的过车数据分组。具体过程包括如下步骤301至步骤307:
步骤301,确定聚类分组数K和最大更新次数N;
步骤302,在数据范围内随机选取K个起始过车数据分组中心;
步骤303,遍历所有数据,对于每一条过车数据,计算这条数据通行时间与各过车数据分组中心的差距,将该过车数据放入差距最小的过车数据分组中;
步骤304,将各过车数据分组的中心更新为该过车数据分组的平均通行时间;
步骤305,重复302-303,直到各过车数据分组不再变化,计算各过车数据分组通行时间方差的加权平均和;
步骤306,将第一次的聚类结果设为起始最优结果,重复步骤301-步骤305,如果新结果的各过车数据分组的通行时间方差的加权平均和小于当前最优结果的通行时间方差的加权平均和,则更新最优结果;如果连续N次聚类都未更新最优结果,则停止聚类,得到最优结果。
步骤307,将最优结果中的过车数据分组,按照平均通行时间由大到小排序输出。
需要说明的是,本申请可以视具体情况,可以将方法中的K-means聚类方法替换成密度聚类算法OPTICS。
步骤400,根据步骤300得到的过车数据分组,筛选停留车辆。
首先根据预设的停留等级制定停留指标组。停留指标组包括[A1、A2、A3、…、AM];
超过最大的A1分位数的记录将被判定为停留车辆,停留等级为一级;超过最大的A2分位数的记录的停留等级为二级;超过最大的A3分位数的记录的停留等级为三级;…;超过最大的AM分位数的记录的停留等级为M级;有多个停留等级时取最大停留等级。
举例对本步骤进行说明,例如,停留指标组中设置三个停留等级,停留指标组A1=20%,A2=15%,A3=10%。
这表示聚类意义下超过最大的20%分位数的记录将被判定为停留车辆,停留等级为一级;
聚类意义下超过最大的15%分位数的记录的停留等级为二级;
聚类意义下超过最大的10%分位数的记录的停留等级为三级;
有多个停留等级时取最大停留等级。
一条记录所谓聚类意义下超过最大的20%分位数是指,该条记录所在的过车数据分组及其他平均通行时间大于该过车数据分组的所有过车数据分组中记录的总数目不超过总记录数的20%。
将所有停留车辆及其停留等级按天汇总。
步骤500,根据步骤400筛选出的停留车辆,确定停留车辆的停留频次,筛选出异常停留车辆。
针对一个月内通过相同的连续卡口的停留车辆,统计其停留频次(按天计次,区分工作日和休息日)。
如果一辆车在一个月内工作日停留超过N天,判断该车辆视为规律性停留。对于所有非规律性停留车辆,判断其为异常停留车辆,并记录其异常停留日期及停留等级。
步骤600,将筛选出异常停留车辆的数据存入mysql数据库以供查询。
本发明实施例提供的异常停留车辆的检测方法,基于道路拥堵和车辆停留两种情况的特征差异:停留车辆的通行时间较长且与其他正常通行车辆的通行时间有明显差异,道路拥堵时通行时间长的车辆之间的通行时间相近;可以较为准确的区分出道路拥堵和车辆停留;能够筛选出指定区域、指定时间段内非规律性停留的车辆,帮助警方找到疑似作案前踩点的车辆。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 一种异常停留车辆的检测方法
- 一种车辆异常停留监控方法及系统