超分辨率卷积神经网络模型的构建方法
文献发布时间:2023-06-19 09:57:26
技术领域
本发明属于的技术领域;具体涉及一种超分辨率卷积神经网络模型的构建方法。
背景技术
传统的超分辨率卷积神经网络的输入通常是经过双三次插值算法输出的伪高分辨率图像,该图像的分辨率大小提升了,但是仍然十分的模糊,需要通过卷积神经网络来进一步提高质量,如SRCNN网络,这种方法的缺点是在神经网络中流动的Tensor数据量很大,这是由于输入了分辨率已经被提高的伪高分辨率图像造成的。近些年来许多通过网络进行上采样的网络结构被提出,如FSRCNN通过反卷积层来实现上采样、ESPCN通过亚像素卷积层来实现上采样,均减少了网络中流动的Tensor的大小。
发明内容
本发明提供了一种超分辨率卷积神经网络模型的构建方法,采用了ESPCN的亚像素卷积层的上采样算法,对亚像素卷积层之前的网络结构进行修改,引入了残差块来构建网络。
本发明通过以下技术方案实现:
一种超分辨率卷积神经网络模型的构建方法,所述构建方法包括以下步骤
步骤1:构建卷积神经网路模型;
步骤2:训练步骤1的卷积神经网路模型;
步骤3:部署步骤2已训练的卷积神经网路模型,实现图像的超分辨率功能。
进一步的,所述步骤1具体为,利用5个残差块与亚像素卷积两种方法构建卷积神经网路模型。
进一步的,所述步骤2具体为,使用100张1920x1080x3的图片进行训练,其中包含50张风景图和50张绘画,训练数据和验证数据为9:1,通过将图片缩小至640x360x3以得到卷积神经网路模型训练的输入,并将其输入值步骤1中构建的模型,原始1920x1080x3的图像做网络的Lable,保存最终训练好的卷积神经网路模型。
进一步的,所述步骤3具体为,将步骤2训练好的卷积神经网路模型进行模型冻结、模型量化和模型编译。
进一步的,所述模型冻结体为,将模型计算图的定义和模型权重合并到同一个文件中。
进一步的,所述模型量化为,通过量化数据集对量化后的模型进行校正,通过脚本调用DNNDK工具包自带的decent_q工具可以方便的量化模型。
进一步的,所述模型编译为,将量化后的模型编译成DPU能够运行的模型。
本发明的有益效果是:
1.本发明的网络推理阶段速度大大提高。
2.本发明的网络推理阶段消耗内存减少。
3.本发明的网络推理输出指标下降不明显。
附图说明
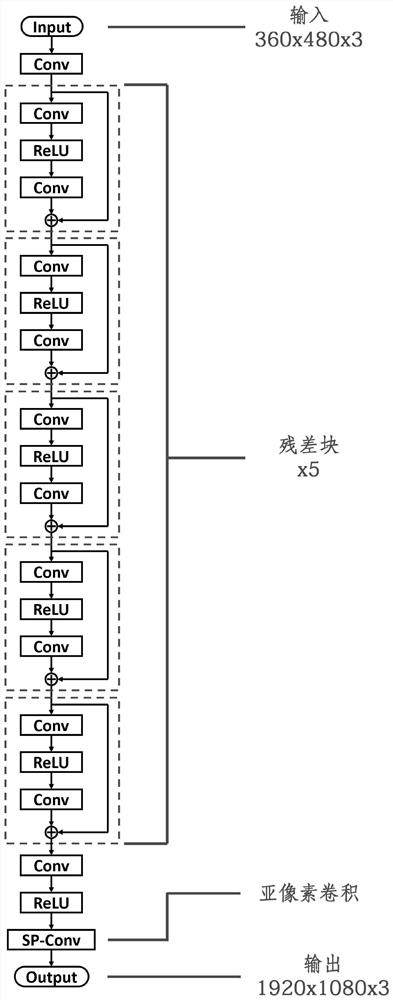
附图1本发明卷积神经网络结构示意图。
附图2本发明残差块结构示意图。
附图3本发明实施例对比图。
具体实施方式
下面将结合本发明实施例中的附图对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
根据图1-2所示,一种超分辨率卷积神经网络模型的构建方法,所述构建方法包括以下步骤,
步骤1:构建卷积神经网路模型;
步骤2:训练步骤1的卷积神经网路模型;
步骤3:部署步骤2已训练的卷积神经网路模型,实现图像的超分辨率功能。
进一步的,所述步骤1具体为,利用5个残差块与亚像素卷积两种方法构建卷积神经网路模型。
进一步的,所述亚像素卷积的构建方法具体为,通过像素洗牌的形式,将长、宽维度小,通道深度深的低分辨率特征图(640x360x27),转化为,长、宽维度大,通道深度浅的高分辨率特征图(1920x1080x3)。
进一步的,所述步骤2具体为,使用100张1920x1080x3的图片进行训练,其中包含50张风景图和50张绘画,训练数据和验证数据为9:1,通过将图片缩小(即双三次插值)至640x360x3以得到卷积神经网路模型训练的输入,并将其输入值步骤1中构建的模型,原始1920x1080x3的图像做网络的Lable,保存最终训练好的卷积神经网路模型。
进一步的,所述步骤3具体为,将步骤2训练好的卷积神经网路模型进行模型冻结、模型量化和模型编译。
进一步的,所述模型冻结体为,将模型计算图的定义和模型权重合并到同一个文件中,方便模型的部署。
进一步的,所述模型量化为,将参数为Float32类型的卷积神经网路模型进行Int8的量化操作,通过量化数据集对量化后的模型进行校正(将量化带来精度下降的不利影响降到最低),通过脚本调用DNNDK工具包自带的decent_q工具可以方便的量化模型。
进一步的,所述模型编译为,将量化后的模型编译成DPU能够运行的模型。通过脚本调用DNNDK工具包自带的DNNC工具能够将模型编译成ELF文件,再将该文件封装为.o文件,方便DNNDK-Python API的调用。
实施例2
步骤1:PSNR(峰值信噪比)和SSIM(结构相似性)是评价神经网络输出图片质量的评价指标,越高越好,而参数量与训练时间,越少越好。
由于亚像素卷积技术的使用,导致网络中流动的图像为低分辨率图像,最终效果为网络推理阶段速度大大提高;网络推理阶段消耗内存减少;网络最终效果提高。
假如任务为超分辨率4倍,低分辨率图像大小为100*100,原始高分辨率图像大小为400*400,如不使用亚像素卷积,网络输入为通过双三次插值算法预先放大的图片,即400*400的大小,如使用亚像素卷积,输入无需预先放大,即输入为100*100,这就导致:
网络推理阶段速度大大提高。
经过计算,相较于不使用亚像素卷积,用输出为3通道的普通卷积替换,计算量减少了160倍左右;使推理时间正比下降。
网络推理阶段消耗内存减少。
经过计算,相较于不使用亚像素卷积,用输出为3通道的普通卷积替换,内存消耗量减少了16倍左右。
网络最终效果提高。
实验条件:网络A(亚像素卷积)与网络B(普通卷积),使用相同的训练集,训练相同的迭代次数,使用的测试集相同,得出以下结果:
网络A相较于网络B来说,在PSNR(峰值信噪比)上,提高了2.79%,在SSIM(结构相似性)上,提高了0.64%,使网络最终推理结果得到了提高。
由于残差学习技术的使用,缓解了网络在训练阶段时深层网络梯度消失的现象,最终效果网络在训练阶段收敛速度大大提高;
实验条件:网络A(使用残差学习),网络B(不使用残差学习),其他条件相同;
实验结果如图3所示;
从图3中能明显看出,使用了残差学习技术的网络A,相比于不使用残差学习的网络B来说,网络收敛速度有明显提高,这意味着在模型训练阶段,使用了残差学习技术的网络A能够在训练迭代次数较少的情况下得到较好的结果,减少了训练网络所消耗的时间与算力成本。
由于网络结构轻量化的设计,使网络模型更小巧,最终效果为网络推理速度上升;内存消耗下降;最终结果质量略微下降。
实验环境:网络A使用了5个残差块,每个卷积层的卷积核个数64个,网络B使用了10个残差块,每个卷积层的卷积核个数128个,其他条件相同;
从上表中可以看出,虽然10个残差块的设计网络输出结果质量上升,但同时也带了参数量的大幅提升,在PSNR和SSIM分别减低2.16%和0.89%的代价下,获得了参数量与训练时间分别减少86.61%和69.40%的大幅度提升,参数量大与训练时间长对该网络模型部署于嵌入式平台是十分不利的,这将导致模型推理时间与内存消耗量大幅上升,对硬件平台要求提高带来的成本上的提高。经多次试验,使用本发明中给定的结构,能够在性能与质量中取得一个较好的平衡点。
步骤3:由于模型量化技术的使用,使网络权重从Float32类型转换为Int8类型最终效果为网络推理阶段速度大大提高;网络推理阶段消耗内存减少;网络推理输出指标下降不明显。
网络推理阶段速度大大提高。
未量化之前数据类型为Float32(32位浮点型),在FPGA中计算需要消耗大量的DSPslice资源,由于该资源十分有限,所以一批数据需要分成很多批次分别计算,而使用Int8(8位整数型)计算时,消耗的资源少,这样一批数据就只用分成较少的批次去计算,大大减少了计算时间。
网络推理阶段消耗内存减少。
由于权重变为Int8,网络中计算出的特征图也为Int8类型,相较于Float32类型,使用Int8类型可直接将内存空间消耗降为原来的4倍。
网络推理输出指标下降不明显
实验条件:网络A使用量化技术,网络B未使用量化技术
从上述数据中可以看出,量化后的网络输出图像的评价指标略有下降但幅度非常微小,人眼几乎无法观测到指标下降带来的输出图像质量上的下降,但推理速度大幅度提高和内存消耗大幅度减少,量化对于该神经网络模型部署于低算力、低功耗的便携式平台是至关重要的。
- 超分辨率卷积神经网络模型的构建方法
- 基于理查德森-露西算法的显微镜去卷积神经网络模型构建方法