一种人脸和口罩识别的方法
文献发布时间:2023-06-19 10:05:17
技术领域
本发明涉及一种自动扩充为戴口罩的人脸数据集的方法和基于MTCNN的检测人脸是否戴口罩的方法。
背景技术
随着基于深度学习的智能算法的发展,当前常见场景下的人脸检测和物体检测技术已经比较成熟。常见的算法方案比如用于人脸检测的MTCNN对一般不戴口罩的人脸检测效果已经非常好。
对于一般物体的检测,比较成熟的检测算法有faster-RCNN,YOLO,SSD等,这些算法可以在COCO数据集上达到50左右的mAP(平均精确度的平均)。同时这些算法包含非常多的超参数,一般需要GPU资源才能实时运行。
现有的场景人脸检测技术和数据集都是不戴口罩的,因此训练出来的算法模型在口罩的场景检出率会大幅降低,常见方法是需要花费大量精力收集戴口罩的样本,并且重新做精确的标注。
发明内容
本发明目的在于在不增加额外训练数据的基础上提供一种有效训练戴口罩场景下人脸检测的方案。
在人脸检测之后的下一步是判断是否戴了口罩,因为口罩在不同角度下外观差别非常大,比如侧脸时只能看到口罩的绑带,低头时可能只能看到鼻尖部位。这使得在侧脸和低头时,口罩的检测准确率会大大下降。本发明为了解决这一问题,建立了三类不同姿态对应的口罩模型,分别是正脸,侧脸,低头。并且使用一个参数共享的神经网络分类模型一次检出是否存在三种口罩模型的某一种,极大的提高了口罩检测的准确率和速度。
本发明的目的在于克服现有技术的不足,提供利用现有的不戴口罩人脸数据集即可以训练和预测戴口罩的人脸检测方法。
本发明提供了一种人脸和口罩识别的方法,具体是:
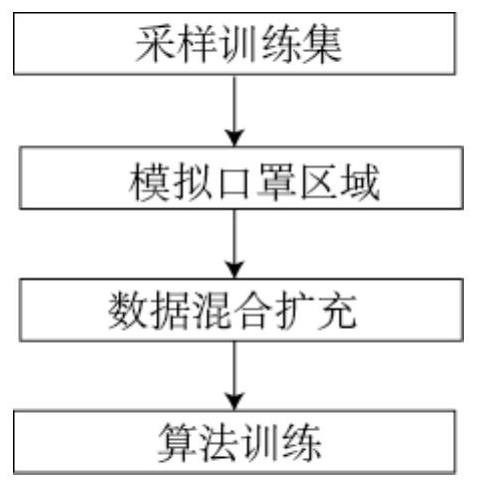
第一步是训练戴口罩或不戴口罩都能适应的人脸检测算法;如附图1所示,它包含以下步骤:
步骤一 采样训练集:对标注好的训练数据集,随机选出边框,然后和标注数据计算IOU,如果大于预设值p,则为正样本,大于预设值f小于预设值p为部分样本,小于f为负样本,该训练集为原始训练集。
步骤二 模拟口罩区域:对标注好的训练数据集,对每个标注的人脸,都有标注的五官位置,分别为两眼位置,鼻尖位置,嘴角两个端点位置。以嘴角两个端点位置为基准,建立矩形区域。中心点为嘴角两端点的中心点记为C,宽为嘴角两端点的距离记为w,高为鼻尖到嘴角两端点的连线记为H。以该区域的中心点和宽高为基础,随机向外扩充,中心点C不变,高H扩大m倍,宽w扩大n 倍,新的矩形区域记为Q。把Q区域内所有像素设为0(随机蓝色,绿色,黑色等颜色),生成新的人脸图片,该训练集为扩充训练集。
步骤三 数据混合扩充:把原始训练集和扩充训练集按照N:1的比例进行混合,生成最终的训练数据。
步骤四 算法训练:有了口罩模拟的训练数据集后,就可以正常训练MTCNN 算法。使用混合后的最终训练数据,使用梯度下降法优化损失,最终得出模型。训练的标注包含二部分:人脸区域框,人脸5个关键点。
第二步是判断人脸是否戴口罩;它的包含一种训练方法和一种预测方法:
一如附图2所示,训练方法包含以下步骤:
步骤一 选取人脸样本:对标注好的人脸训练数据集,随机选出边框,然后和标注数据计算IOU,如果大于预设值p,则选为用来训练的人脸样本。
步骤二 是否戴口罩人脸数据生成:对于和标注数据IOU大于预设值q的人脸样本,首先使用第一步训练戴口罩或不戴口罩都能适应的人脸检测算法的步骤二,模拟生成戴口罩的人脸数据。然后把生成的人脸数据和步骤一中筛选出的人脸样本按照1:1的比例进行混合,生成最终的数据集。
步骤三 人脸姿态估计:人脸姿态估计的步骤为2D人脸关键点检测;3D人脸模型匹配;求解3D点和对应2D点的转换关系;根据旋转矩阵求解欧拉角。首先根据图片标注获取2D人脸关键点;其次定义一个具有n个关键点的3D脸部模型, n与2D人脸关键点的数量一致,并一一对应。利用opencv的solvePnp函数求解3D点和对应2D点的转换关系即旋转和平移矩阵,然后把旋转矩阵转换为欧拉角,得出人脸在三个角度(pitch,yaw,roll)的欧拉角值,学名俯仰角、偏航角和滚转角,通俗讲就是抬头、摇头和转头。
步骤四:根据三个值把步骤二中生成的戴口罩的人脸数据分成3个类别:低头,侧面,正面。分类流程:1首先角度pitch大于预设值P的分为低头;2剩下图片中角度yaw小于预设值-Y或大于预设值Y的分为侧面;3剩下为正面。在结合是否戴口罩的标签,把训练集中的所有人脸图片标注分为4种类别的一种:不戴口罩,低头戴口罩,侧脸戴口罩,正脸戴口罩。
步骤五 训练阶段图片预处理:首先对图片做如下变换以增加数据集的复杂度:包括随机翻转,随机裁剪,随机拉伸,随机像素值变换。然后人脸图片统一缩放到N*N,并根据图片本身的均值和方差对图片做归一化。
步骤六 卷积神经网络:卷积神经网络可以使用任一种卷积神经网络模型,以经典的残差网络为例,它包含若干卷积层和最后的全连接分类层,各层之间使用直接映射来连接。
步骤七 预测类别:神经网络的最终输出为图片所对应的类别得分。
步骤八 损失函数:使用softmax损失函数,公式为:
z
步骤九 训练:使用梯度下降法最小化步骤五的损失函数,当损失函数不在下降时结束训练。
二如附图2所示,预测包含如下步骤:
步骤一 人脸检测:给定任一张待检测图片,首先使用训练好的MTCNN算法模型检测人脸,截取人脸框对应的区域获得人脸图片,并输出人脸的5个关键点。
步骤二 图片预处理:人脸图片统一缩放到N*N,并根据图片本身的均值和方差对图片做归一化。
步骤三 卷积神经网络提取特征:与训练阶段步骤四一样。
步骤四 获取类别:神经网络的最终输出为图片所对应的类别得分,即不戴口罩,低头戴口罩,侧脸戴口罩,正脸戴口罩。这样分的原因是低头,侧脸,正脸三种情况时戴口罩的外观变化非常大,分为3个类别之后相当于做了细分类,可以提高判断准确率。
技术效果
1对戴口罩时人脸的不同姿态做了细分类,提升了判断准确率,与不做细分类的判断比较,96%提升到了99%。
2提供一种自动从正常的人脸生成戴口罩人脸的算法,大大节省了额外收集戴口罩数据并标注的精力和资源。
3训练好的MTCNN对戴口罩的人脸同样有98%的检出率。
附图说明
图1是;训练戴口罩或不戴口罩都能适应的人脸检测算法流程
图2是:判断人脸是否戴口罩的训练方法。
图3是:判断人脸是否戴口罩的预测方法。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。
第一步是训练戴口罩或不戴口罩都能适应的人脸检测算法。结合附图1,它包含以下步骤:
步骤一 采样训练集:对标注好的训练数据集,随机选出边框,然后和标注数据计算IOU,如果大于预设值p=0.65,则为正样本,大于预设值f=0.4小于P=0.65 为部分样本,小于f=0.4为负样本,该训练集为原始训练集。
步骤二 模拟口罩区域:对标注好的训练数据集,对每个标注的人脸,都有标注的五官位置,分别为两眼位置,鼻尖位置,嘴角两个端点位置。以嘴角两个端点位置为基准,建立矩形区域。中心点为嘴角两端点的中心点记为C,宽为嘴角两端点的距离记为w,高为鼻尖到嘴角两端点的连线记为H。以该区域的中心点和宽高为基础,随机向外扩充,中心点C不变,高H扩大m倍,宽w扩大n 倍,新的矩形区域记为Q。把Q区域内所有像素设为0(随机蓝色,绿色,黑色等颜色),生成新的人脸图片,该训练集为扩充训练集。
步骤三 数据混合扩充:把原始训练集和扩充训练集按照N:1的比例进行混合,生成最终的训练数据。
步骤四 算法训练:有了口罩模拟的训练数据集后,就可以正常训练MTCNN 算法。使用混合后的最终训练数据,使用梯度下降法优化损失,最终得出模型。训练的标注包含二部分:人脸区域框,人脸5个关键点。
第二步是判断人脸是否戴口罩。它的包含一种训练方法和一种预测方法:
一结合附图2,训练步骤如下:
步骤一 选取人脸样本:对标注好的人脸训练数据集,随机选出边框,然后和标注数据计算IOU,如果大于p=0.65,则选为用来训练的人脸样本。
步骤二 是否戴口罩人脸数据生成:对于和标注数据IOU大于q=0.8的人脸样本,首先使用第一步训练戴口罩或不戴口罩都能适应的人脸检测算法的步骤二,模拟生成戴口罩的人脸数据。然后把生成的人脸数据和步骤一中筛选出的人脸样本按照1:1的比例进行混合,生成最终的数据集。
步骤三 人脸姿态估计:人脸姿态估计的步骤为2D人脸关键点检测;3D人脸模型匹配;求解3D点和对应2D点的转换关系;根据旋转矩阵求解欧拉角。首先根据图片标注获取2D人脸关键点;其次定义一个具有n个关键点的3D脸部模型, n与2D人脸关键点的数量一致,并一一对应。利用opencv的solvePnp函数求解3D点和对应2D点的转换关系即旋转和平移矩阵,然后把旋转矩阵转换为欧拉角,得出人脸在三个角度(pitch,yaw,roll)的欧拉角值,学名俯仰角、偏航角和滚转角,通俗讲就是抬头、摇头和转头。
步骤四:根据三个值把步骤二中生成的戴口罩的人脸数据分成3个类别:低头,侧面,正面。分类流程:1首先角度pitch大于预设值P的分为低头;2剩下图片中角度yaw小于预设值-Y或大于预设值Y的分为侧面;3剩下为正面。在结合是否戴口罩的标签,把训练集中的所有人脸图片标注分为4种类别的一种:不戴口罩,低头戴口罩,侧脸戴口罩,正脸戴口罩。
步骤五 训练阶段图片预处理:首先对图片做如下变换以增加数据集的复杂度:包括随机翻转,随机裁剪,随机拉伸,随机像素值变换。然后人脸图片统一缩放到N*N,并根据图片本身的均值和方差对图片做归一化。
步骤六 卷积神经网络:卷积神经网络可以使用任一种卷积神经网络模型,以经典的残差网络为例,它包含若干卷积层和最后的全连接分类层,各层之间使用直接映射来连接。
步骤七 预测类别:神经网络的最终输出为图片所对应的类别得分。
步骤八 损失函数:使用softmax损失函数,公式为:
z
步骤九 训练:使用梯度下降法最小化步骤五的损失函数,当损失函数不在下降时结束训练。
二结合附图3,预测步骤如下:
步骤一 人脸检测:给定任一张待检测图片,首先使用训练好的MTCNN算法模型检测人脸,截取人脸框对应的区域获得人脸图片,并输出人脸的5个关键点。
步骤二 图片预处理:人脸图片统一缩放到N*N,并根据图片本身的均值和方差对图片做归一化。
步骤三 卷积神经网络提取特征:与训练阶段步骤四一样。
步骤四 获取类别:神经网络的最终输出为图片所对应的类别得分,即不戴口罩,低头戴口罩,侧脸戴口罩,正脸戴口罩。这样分的原因是低头,侧脸,正脸三种情况时戴口罩的外观变化非常大,分为3个类别之后相当于做了细分类,可以提高判断准确率。
本发明中的卷积神经网络可以有各种形式,只要是多层卷积+1层或者多层全连接,均可实现本算法效果。
- 一种批量口罩人脸样本自动生成以及口罩人脸识别方法
- 一种基于卷积神经网络的佩戴口罩人脸识别检测方法