一种基于大数据的文件推荐方法和装置
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及一种基于大数据的文件推荐方法和装置。
背景技术
目前,用户在通过知网数据库、百度文库、万方数据库等进行文件搜索时,这些数据库往往会根据用户的相关要求向用户推荐符合要求的文件,但是,这种推荐方式只推荐符合要求的文件,却无法在符合要求的文件之外,还推荐一些与这些符合要求的文件的相关性比较大的其他文件,而这些其他文件中可能有用户更加需要的信息,因此,现有的文件推荐方法比较片面,无法实现更加全面地文件推荐。
发明内容
本发明提供一种基于大数据的文件推荐方法和装置,用于解决现有的文件推荐方法比较片面,无法更加全面推荐的技术问题。
为了解决上述问题,本发明采用以下技术方案:
一种基于大数据的文件推荐方法,包括:
获取目标用户的文件搜索指令,所述文件搜索指令包括文件搜索要求和所述目标用户的身份信息;
根据所述目标用户的身份信息,对所述目标用户进行身份验证;
若所述目标用户身份验证通过,则根据所述文件搜索要求,从预设的文件数据库中获取初始目标文件集和其他文件集,所述初始目标文件集包括至少一个符合所述文件搜索条件的初始目标文件,所述其他文件集包括所述文件数据库中除去所述初始目标文件集的其他文件;
根据所述初始目标文件集获取所述初始目标文件集的初始目标特征向量矩阵,根据所述其他文件集获取所述其他文件集的扩充特征向量矩阵;
根据所述初始目标特征向量矩阵和扩展特征向量矩阵,获取各个其他文件与所述初始目标文件集的关联度;
根据各个其他文件对应的关联度获取符合预设关联度条件的目标关联度,获取最终目标文件,所述最终目标文件包括所述初始目标文件和所述符合预设关联度条件的目标关联度对应的其他文件。
可选地,所述目标用户的身份信息包括所述目标用户的目标身份标识、目标密码以及所述目标用户输入的实际数据结合规则;
预设有所述目标用户在注册时存储的身份验证信息,所述身份验证信息为所述目标用户的原始身份标识和原始密码按照随机确定的数据结合规则进行结合所得到的原始结合数据;
相应地,所述根据所述目标用户的身份信息,对所述目标用户进行身份验证具体为:
根据所述实际数据结合规则,对所述目标身份标识和所述目标密码进行结合,得到实际结合数据;
验证所述原始结合数据和所述实际结合数据是否相同,若相同,则身份验证通过,若不同,则身份验证未通过。
可选地,所述根据所述初始目标文件集获取所述初始目标文件集的初始目标特征向量矩阵,根据所述其他文件集获取所述其他文件集的扩充特征向量矩阵具体为:
获取各个初始目标文件的特征向量,以及各个其他文件的特征向量;
根据各个初始目标文件的特征向量获取所述初始目标文件集的初始目标特征向量矩阵,根据各个其他文件的特征向量获取所述其他文件集的扩充特征向量矩阵。
可选地,所述获取各个初始目标文件的特征向量,以及各个其他文件的特征向量具体为:
获取各个初始目标文件的关键词数据,根据各个初始目标文件的关键词数据得到各个初始目标文件的特征向量;获取各个其他文件的关键词数据,根据各个其他文件的关键词数据得到各个其他文件的特征向量。
可选地,所述根据所述初始目标特征向量矩阵和扩展特征向量矩阵,获取各个其他文件与所述初始目标文件集的关联度具体为:
根据所述初始目标特征向量矩阵,获取初始目标文件集在预设的多维向量空间中的中心点;
根据所述扩展特征向量矩阵以及所述中心点,获取各个其他文件与所述初始目标文件集的关联度。
可选地,所述根据所述初始目标特征向量矩阵,获取初始目标文件集在预设的多维向量空间中的中心点具体为:
将各个初始目标文件的关键词数据进行分组,相同的关键词数据划分为一组,获取各组关键词数据对应的初始目标文件的特征向量;
根据各组关键词数据对应的初始目标文件的特征向量,计算各组关键词数据对应的初始目标文件的特征向量的均值向量,各均值向量为所述中心点的向量。
可选地,所述根据所述扩展特征向量矩阵以及所述中心点,获取各个其他文件与所述初始目标文件集的关联度具体为:
根据所述中心点的向量和所述扩展特征向量矩阵,获取各个其他文件的特征向量与所述中心点之间的距离;
根据各个其他文件的特征向量对应的距离,获取各个其他文件与所述初始目标文件集的关联度,其中,关联度与距离呈反相关关系。
可选地,所述根据各个其他文件对应的关联度获取符合预设关联度条件的目标关联度具体为:
根据各个其他文件对应的关联度以及预设的关联度阈值,获取大于或者等于所述关联度阈值的目标关联度。
一种基于大数据的文件推荐装置,包括存储器和处理器,以及存储在所述存储器上并在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述基于大数据的文件推荐方法。
本发明的有益效果为:先对目标用户进行身份验证,只有身份验证通过之后才能够进行后续的文件推荐处理过程,提升数据处理的安全性,防止无关人员获取到比较机密的文件;目标用户身份验证通过之后,先获取初始目标文件,然后根据文件数据库中的其他文件与初始目标文件集的关联度获取符合要求的目标关联度,最终目标文件为初始目标文件和符合预设关联度条件的目标关联度对应的其他文件。因此,该基于大数据的文件推荐方法除了推荐符合文件搜索要求的文件,还推荐与符合文件搜索要求的文件的关联度符合要求的其他文件,最终得到的文件比较全面,防止遗漏部分具有一定关联度的其他文件,解决了现有的文件推荐方法比较片面,无法实现更加全面推荐的问题。
附图说明
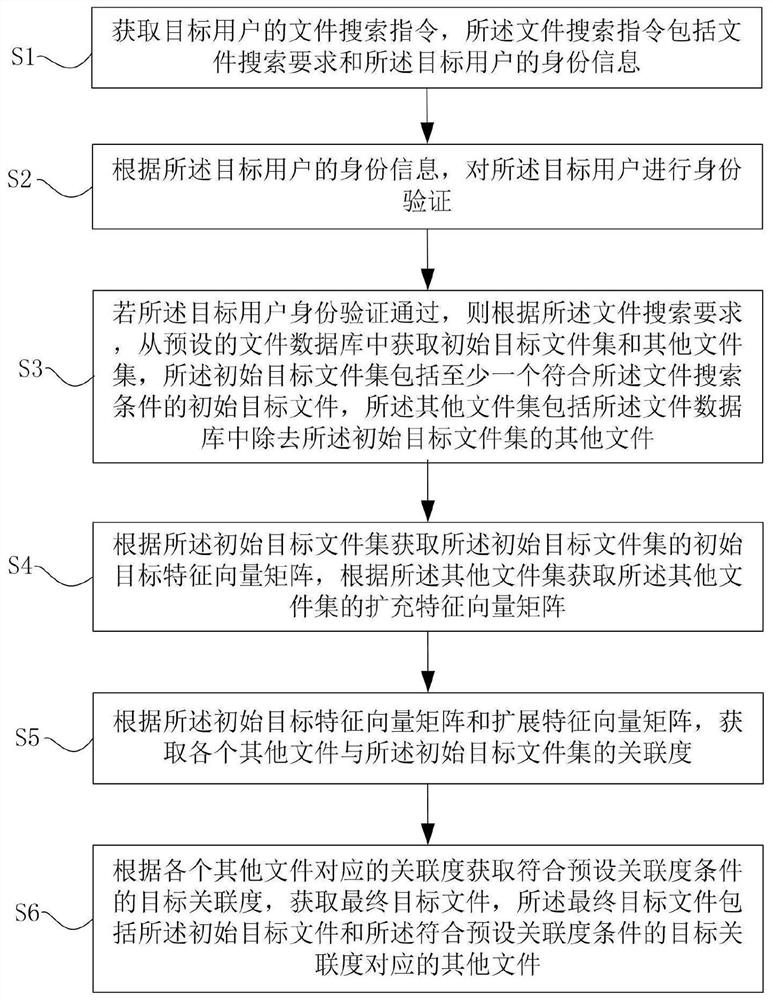
图1是本发明提供的一种基于大数据的文件推荐方法的流程图。
具体实施方式
本实施例提供一种基于大数据的文件推荐方法,该文件推荐方法可以用在计算机设备或者服务器设备中,比如可以应用在目前主流的文件数据库所对应的服务器中,比如知网数据库、百度文库、万方数据库等等,也可以应用在一些没有市场化的内部文件数据库中。本实施例中,该文件推荐方法的硬件执行主体以计算机设备为例。
如图1所示,该文件推荐方法包括如下步骤:
步骤S1:获取目标用户的文件搜索指令,所述文件搜索指令包括文件搜索要求和所述目标用户的身份信息:
获取目标用户的文件搜索指令,文件搜索指令包括两部分,分别是文件搜索要求和目标用户的身份信息。其中,文件搜索要求可以为目标用户的文件搜索条件,比如关键要素、文件名称或者其他搜索条件。文件搜索要求可以由计算机设备上的键盘等数据输入设备进行输入。目标用户的身份信息为表示目标用户唯一性的身份信息,比如身份标识信息(比如身份证信息、工号)等等。目标用户的身份信息可以由身份识别器,比如身份证刷卡器、员工卡识别器进行识别得到,然后输出给计算机设备,或者,由计算机设备上的键盘等数据输入设备进行输入。
步骤S2:根据所述目标用户的身份信息,对所述目标用户进行身份验证:
本实施例中,目标用户的身份信息包括目标用户的目标身份标识、目标密码以及目标用户输入的实际数据结合规则。其中,目标密码为目标用户进行文件搜索时所输入的密码。应当理解,目标身份标识和目标密码均为由字母/数字构成的字符串。
目标用户需要事先向计算机设备进行用户注册,用户注册是文件搜索的基础。在目标用户注册时,目标用户向计算机设备发送原始身份标识和原始密码,原始身份标识为目标用户的身份标识,与上述中的目标身份标识相对应,原始密码与上述目标密码相对应。应当理解,之所以称为“原始身份标识”和“原始密码”,是表示原始身份标识和原始密码是事先在目标用户注册时输入的。
计算机设备中预设有至少一种数据结合规则,具体种类数由实际需要进行设置。而且,各数据结合规则也由实际需要进行设置,比如原始身份标识在前、原始密码在后进行首尾连接,或者原始密码在前、原始身份标识在后进行首尾连接,或者,由于原始身份标识和原始密码均为字符串,则将原始身份标识间隔穿插在原始密码中等等。在注册时,目标用户在将原始身份标识和原始密码输入到计算机设备中之后,计算机设备从各数据结合规则中随机确定一种数据结合规则,计算机设备根据该确定得到的数据结合规则对原始身份标识和原始密码进行结合,得到身份验证信息,那么,该身份验证信息为目标用户的原始身份标识和原始密码按照随机确定的数据结合规则进行结合所得到的原始结合数据。应当理解,目标用户在注册时能够获知随机确定得到的某一个数据结合规则,即计算机设备在随机确定一种数据结合规则时,可以通过触摸屏或者显示屏等向目标用户展示确定的某一个数据结合规则。
那么,在此时进行身份验证时,目标用户向计算机设备发送的目标用户的身份信息中除了包含目标用户的目标身份标识和目标密码之外,还包括目标用户输入的实际数据结合规则。作为一个具体实施方式,在进行身份验证时,计算机设备的屏幕显示多个数据结合规则,目标用户从中选取一种数据结合规则,并将选取的数据结合规则输出给计算机设备,比如通过触摸屏点击选取的数据结合规则,或者通过键盘输入选取的数据结合规则的标号。将选取得到的数据结合规则称为实际数据结合规则。作为其他的实施方式,还可以通过键盘手动输入实际数据结合规则所对应的代码。
计算机设备根据实际数据结合规则,对目标身份标识和目标密码进行结合,得到实际结合数据。
那么,计算机设备验证在注册时得到的原始结合数据和与身份验证时得到的实际结合数据是否相同,若相同,则身份验证通过,若不同,则身份验证未通过。
上述身份验证过程能够提升身份验证的安全性,作为其他的实施方式,还可以采用已有的验证过程,比如:目标用户的身份信息仅仅为目标用户的指纹信息,将目标用户的指纹信息输入到指纹数据库中进行比对,若目标用户的指纹信息属于指纹数据库,则身份验证通过,否则身份验证未通过。
步骤S3:若所述目标用户身份验证通过,则根据所述文件搜索要求,从预设的文件数据库中获取初始目标文件集和其他文件集,所述初始目标文件集包括至少一个符合所述文件搜索条件的初始目标文件,所述其他文件集包括所述文件数据库中除去所述初始目标文件集的其他文件:
计算机设备中预设有文件数据库,该文件数据库为文件推荐的基础,推荐的文件属于该文件数据库中的文件。该文件数据库中的各文件可以是论文,也可以是专利文件,或者是其他类型的文件。该文件数据库的规模,即所包含的文件的数量和领域由实际应用场景进行确定。
若目标用户身份验证通过,则根据文件搜索要求,从文件数据库中获取初始目标文件集和其他文件集。其中,初始目标文件集包括至少一个符合文件搜索条件的初始目标文件,即将文件数据库中符合文件搜索条件的文件称为初始目标文件,初始目标文件集包括文件数据库中所有的符合文件搜索条件的初始目标文件。其他文件集包括文件数据库中除去初始目标文件集的其他文件。也就是说,将文件数据库中的文件分为两部分,第一部分是符合文件搜索条件的文件,第二部分是不符合文件搜索条件的文件,其中,将第一部分的文件称为初始目标文件,所有的初始目标文件构成初始目标文件集;将第二部分的文件称为其他文件,所有的其他文件构成其他文件集。
步骤S4:根据所述初始目标文件集获取所述初始目标文件集的初始目标特征向量矩阵,根据所述其他文件集获取所述其他文件集的扩充特征向量矩阵:
根据初始目标文件集获取初始目标文件集的初始目标特征向量矩阵,根据其他文件集获取其他文件集的扩充特征向量矩阵,本实施例给出初始目标特征向量矩阵和扩充特征向量矩阵的一种具体实现过程:
步骤S41:获取各个初始目标文件的特征向量,以及各个其他文件的特征向量:
获取各个初始目标文件的特征向量,以及各个其他文件的特征向量。本实施例中,根据各个初始目标文件的关键词数据获取各个初始目标文件的特征向量,根据各个其他文件的关键词数据获取各个其他文件的特征向量。其中,关键词数据可以是文件摘要的关键词,也可以是文件名称的关键词。那么,获取各个初始目标文件的关键词数据,根据各个初始目标文件的关键词数据得到各个初始目标文件的特征向量;获取各个其他文件的关键词数据,根据各个其他文件的关键词数据得到各个其他文件的特征向量。应当理解,关键词数据为文件的已知数据。
作为一个具体实施方式,对于任意一个文件而言,可以将各个关键词数据按照预设的顺序进行排序(预设的顺序的设置过程可以为:设置有多个关键词类型,将各关键词类型按照预设的顺序进行排序,那么,根据各关键词数据所属的关键词类型,就可以将各个关键词数据进行排序,对于没有关键词数据的关键词类型,可以将对应位置设为0),然后根据排序得到特征向量,比如特征向量为[x
应当理解,文件的特征向量的获取过程还可以采用已有的其他获取过程,不再赘述。
步骤S42:根据各个初始目标文件的特征向量获取所述初始目标文件集的初始目标特征向量矩阵,根据各个其他文件的特征向量获取所述其他文件集的扩充特征向量矩阵:
得到各个初始目标文件的特征向量和各个其他文件的特征向量之后,将各个初始目标文件的特征向量添加到对应向量矩阵中,具体地:可以将每一个初始目标文件的特征向量作为初始目标特征向量矩阵的一行元素,得到初始目标文件集的初始目标特征向量矩阵。同理,将各个其他文件的特征向量添加到对应向量矩阵中,具体地:可以将每一个其他文件的特征向量作为扩充特征向量矩阵的一行元素,得到其他文件集的扩充特征向量矩阵。
步骤S5:根据所述初始目标特征向量矩阵和扩展特征向量矩阵,获取各个其他文件与所述初始目标文件集的关联度:
得到初始目标特征向量矩阵和扩展特征向量矩阵之后,根据初始目标特征向量矩阵和扩展特征向量矩阵获取各个其他文件与初始目标文件集的关联度,作为一个具体实施方式,以下给出一种实现过程:
步骤S51:根据所述初始目标特征向量矩阵,获取初始目标文件集在预设的多维向量空间中的中心点:
先将各个初始目标文件的关键词数据进行分组,具体是将相同的关键词数据划分为一组,不同的关键词数据划分在不同的组内,就得到多组关键词数据,进而获取各组关键词数据对应的初始目标文件的特征向量。作为其他的实施方式,还可以将具有一定关联性(即不相同,但是具有一定的关联性)的关键词数据划分为一组,将不具备关联性的关键词数据划分在不同的组内,就得到多组关键词数据,进而获取各组关键词数据对应的初始目标文件的特征向量。
然后根据各组关键词数据对应的初始目标文件的特征向量,计算各组关键词数据对应的初始目标文件的特征向量的均值向量(即向量均值),各均值向量为中心点的向量。
步骤S52:根据所述扩展特征向量矩阵以及所述中心点,获取各个其他文件与所述初始目标文件集的关联度:
得到中心点之后,根据扩展特征向量矩阵以及中心点,获取各个其他文件与初始目标文件集的关联度,作为一个具体实施方式,以下给出一种实现过程:
先根据中心点的向量和扩展特征向量矩阵,获取各个其他文件的特征向量与中心点之间的距离,其中,距离为欧式距离。具体地:由于均值向量为中心点的向量,则获取各个其他文件的特征向量与对应的均值向量的欧氏距离。其中,对于任意一个其他文件的特征向量而言,获取与该其他文件的关键词数据相同的关键词数据所对应的均值向量,该均值向量为与该其他文件相对应的均值向量,或者获取与该其他文件的关键词数据具有最大关联性的关键词数据所对应的均值向量,该均值向量为与该其他文件相对应的均值向量。由于欧式距离的计算过程属于常规技术手段,不再赘述。
根据各个其他文件的特征向量对应的距离,获取各个其他文件与初始目标文件集的关联度,其中,关联度与距离呈反相关关系。也就是说,距离越小的其他文件,与初始目标文件集的关联度越高,相应地,距离越大的其他文件,与初始目标文件集的关联度越低。应当理解,关联度与距离之间的具体数值关系由实际需要进行设置。
步骤S6:根据各个其他文件对应的关联度获取符合预设关联度条件的目标关联度,获取最终目标文件,所述最终目标文件包括所述初始目标文件和所述符合预设关联度条件的目标关联度对应的其他文件:
预设有关联度阈值,该关联度阈值的具体数值由实际需要进行设置。得到各个其他文件对应的关联度之后,与预设的关联度阈值进行比对,就能够得到两种关联度,分别是大于或者等于关联度阈值的关联度,以及小于关联度阈值的关联度。获取大于或者等于关联度阈值的关联度,该大于或者等于关联度阈值的关联度为目标关联度,相应地,获取目标关联度所对应的其他文件,获取到的其他文件与初始目标文件的关联度比较高,即关联比较密切。那么,获取到的目标关联度所对应的其他文件为符合预设关联度条件的关联度对应的其他文件。
获取最终目标文件,最终目标文件包括初始目标文件和目标关联度所对应的其他文件。
得到最终目标文件之后,向目标用户输出最终目标文件,比如显示屏显示各最终目标文件的文件名称或者链接。
本实施例还提供一种基于大数据的文件推荐装置,包括存储器和处理器,以及存储在存储器上并在处理器上运行的计算机程序,处理器执行计算机程序时实现上文中的基于大数据的文件推荐方法。因此,该基于大数据的文件推荐装置本质仍旧是基于大数据的文件推荐方法,由于该基于大数据的文件推荐方法在上文已给出了详细说明,不再赘述。
- 一种基于大数据的文件推荐方法和装置
- 一种基于大数据双向推荐的深度学习方法及双向推荐装置