一种基于深度学习的带钢缺陷检测方法
文献发布时间:2023-06-19 10:29:05
技术领域
本发明属于计算机视觉技术领域以及缺陷检测领域。其中主要涉及的知识包括一些数字图像处理、图像增强、图像语义分割方法、深度学习图像分割方法等。
背景技术
自工业革命时代起,钢铁材料的产能开始飞速提升,并逐渐成为人类社会中最为广泛应用的材料之一。在现代,一个国家钢铁行业的强盛程度,是其能否在21世纪迅速发展的基础物质保证。钢铁材料在国家工业需求、住房需求、交通需求等诸多方面具有不可或缺的作用。带钢则又是钢铁企业的重要产出物品之一。带钢是一种又窄又长的钢板,在汽车、航空航天、机械制造、建筑、日用五金等方面用途广泛,是产量大、用处广、种类多的钢材。带钢质量的好坏对最终产品的性能与质量有着很大影响。随着时代发展,各个商家对带钢的质量要求也在不断提高,行业竞争日趋白热化。对于钢铁企业来说,为了保证钢铁的生产质量,质量检测水平的提升是必不可少的。
在传统的带钢缺陷检测方法里,人工目测虽是一种有效的方法,但该劳动强度大,带钢的生产环境恶略,容易对工作人员的身体和心理造成极大伤害。目前的自动化检测方法中,涡流检测是一种很常见的方法。该方法的缺陷检测方法主要是使用高频感应线圈让带钢内产生感应电流,只要检测表面温度变化,就可以检测出带钢的表面缺陷。但该方法对被测物表面状态的要求较高,对部分类型的缺陷检测效果并不好。
除此之外,随着图像采集技术的发展,基于计算机视觉的方法也被投入使用。该方法主要是将带钢样品的表面扫描为数字图像,进行进一步的检测。在计算机数字图像处理领域内,带钢的缺陷检测问题可以被视为一种图像的语义分割问题,即将图像中的每一个像素分类为一种类别,将缺陷的区域分割出来。传统的图像语义分割方法主要是根据图像的材质、纹理和颜色等特征,结合专业知识,人工设计图像特征的提取方法,并使用支持向量机(SVM)、随机森林、AdaBoost等分类算法进行分类。显然,对于复杂的图像场景,人工设计特征的提取方法效果并不理想。
随着计算机运算能力的不断提升以及机器学习相关算法的不断积累,深度学习的相关技术得到了极大的发展。深度学习在图像领域的研究很早之前就有过相关的尝试和应用。1998年,Lecun等人就提出了一种结合了卷积操作的神经网络,该网络被叫做卷积神经网络(CNN,Convolutional Neural Network)。起初,在简单的小尺寸图像场景下,CNN取得了很好的效果,但却很难处理大型图片。直到2012年,Krizhevsky等人构建了更深的网络结构AlexNet,该网络在著名的ImageNet数据集上取得了极大的进展,这使得深度学习在图像识别领域的研究工作大幅向前迈进。2015年He等人提出了深度残差网络(ResNet),ResNet引进了跳跃式连接的结构,使得模块输入可以直接加到模块的输出上,避免了模型的退化现象,网络深度也因此达到了前所未有的152层,这种跳跃式连接的结构也基本成为今后CNN设计的基础单元。在语义分割领域,Long等人在2014年设计处理了全卷积神经网络(FCN),该模型可以直接完成端到端的图像语义分割,极大的简化语义分割相关问题的复杂度,取得了突破性进展了突破性进展。在随后的几年中,SegNet,U-Net,DeepLab、PSPNet等其他语义分割模型相继提出,并在语义分割领域大放异彩。
目前,使用深度学习方法应用于带钢缺陷检测仍然存在一些问题。带钢的缺陷样本分布不一,形态各异。哪怕是同一种类别的缺陷,在材质和纹理上也会有很大区别。这是可能是因为带钢的生产流水线复杂、环境多变、采集周期较长,不同批次产品的缺陷差别较大。并且缺陷的大小可能会在尺度上有极大的差距,这要求模型既要有捕获微小细节的能力,又要有获取整体空间信息的能力。这些问题为高精度的检测带来了较大的挑战。
发明内容
基于上述分析,本发明主要设计了一种基于深度学习的语义分割方,进行带钢缺陷的检测。
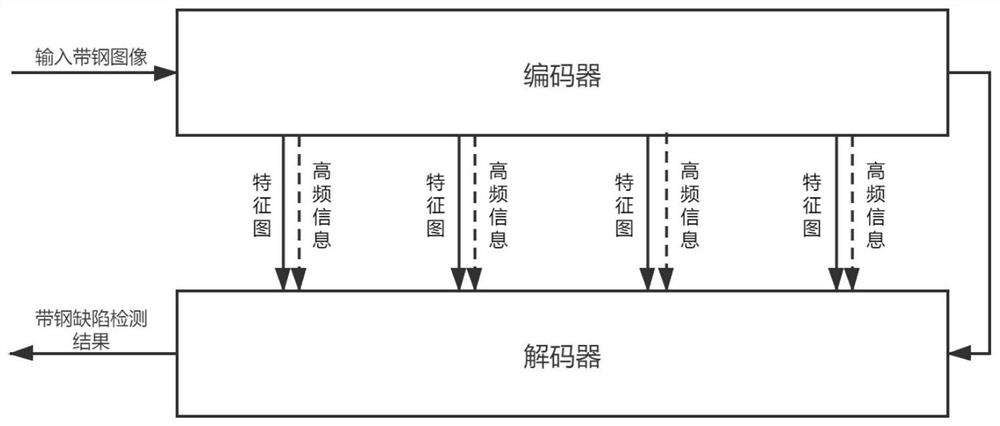
本方法进行语义分割模型的主要架构是基于U-Net的编码器—解码器结构。其中编码器通过反复的卷积操作提取图像中的特征,并进行了五次下采样操作,提取不同尺度的特征。解码器部分与编码器对称,接受了编码器的输出,进行了五次上采样,并且每次上采样得到的结果会与编码器同尺度的特征图进行拼接。在本方法中,为了尽可能让所提出的语义分割模型在每次下采样后,会在下采样前使用高斯低通滤波器,去除其中的高频信息,防止因特征图原频率过高,出现混叠现象,导致特征图出现偏差。同时,被去除的高频信息中蕴含了原图的细节信息,这些细节信息对带钢小型缺陷的检测至关重要,直接舍弃会影响效果。因此本方法将这些高频信息进一步加回到模型解码器的特征图上,产生更精细的分割效果。
本方法中,模型训练与测试所用的数据来自于钢铁公司Severstal开源的带钢图像数据。在对模型进行训练前,首先对数据集划分为训练集与测试集。训练时使用训练集训练模型,为了增强模型的鲁棒性,训练时输入的训练集图像会进行数据增强。为了缓解数据集各类缺陷之间数量不均衡的问题,训练模型的损失函数为FocalLoss损失函数。最终用测试集测试模型的精度,检测模型的训练效果。
为个实现上述目的,本发明采用以下技术方案:为实现带钢缺陷检测的方法,首选Python语言进行编写。模型的实现与训练主要使用了机器学习库PyTorch进行实现。模型的编码器采用了在ImageNet上预训练好的ResNet50。解码器部分由5个连续解码器模块堆叠组成。数据集中的带钢图像为长条形,分辨率为256×1600,直接输入模型训练尺寸过大,因此在训练前会裁剪为4张256×400的图像。训练时的数据增强使用OpenCV实现图像的随机翻转、旋转、添加高斯噪音、直方图均衡以及图像锐化。
一种基于深度学习的带钢缺陷检测方法主要包括:
步骤1、收集带钢的图像数据集,并对数据集中的数据进行清洗。
步骤2、将数据集中的带钢图像随机划分为训练集和测试集,并使用ImageNet数据集的方差与均值进行正则化。
步骤3、仿照U-Net的架构构建模型。其中编码器使用在ImageNet数据集上预训练好的ResNet50网络,并在每次下采样之前插入高斯低通滤波器。解码器为5个解码器模块堆叠而成。
步骤4、对步骤3构建的模型进行训练。训练时输入的数据会进行随机的数据增强。训练结束后,在测试集上进行测试,检测模型的训练结果是否满足要求。
作为优选,步骤2采取以下步骤:
步骤2.1、随机地震图像将数据集划分为训练集和测试集;
步骤2.2、将训练接的每张分辨率为256×1600的带钢图像,切分为四张256×400的小图像;
作为优选,步骤3具体包括以下步骤:
步骤3.1、构建编码器部分。使用在ImageNet数据集上训练好的ResNet50作为模型解码器。在ResNet50的每次下采样操作前插入高斯低通滤波器模块。在该模块中,首先使用高斯低通滤波器降低特征图的频率,使下采样后的特征图更为清晰。之后让高斯低通滤波器处理前的特征图与处理后的特征图做差,计算出损失的高频信息,为解码器部分的输入做准备。
步骤3.2、构建解码器部分。该解码器以U-Net的解码器结构作为主体结构,由5个解码器模块组成。这5个解码器模块会将编码器输出的特征图进行连续的上采样,直到特征图恢复至原图大小,最终输出的结果即为缺陷的识别结果。前4个解码器模块的输入会与编码器的输出特征图进行拼接,综合利用高层级与低层级的语义信息,以获得更好的分割结果。在原U-Net解码器的基础上,前四个解码器模块的输入还会加上编码器中对应高斯低通滤波器去除的高频信息,以避免细节信息的损失。最后一个解码器除了不会接受编码器的输入,其他部分与前4个解码器模块相同。
作为优选,步骤4具体包括以下步骤:
步骤4.1、对构建好的模型进行训练,使用标准的Adam优化算法对模型进行训练。模型总共训练100个epoch,batchsize为10。训练的初始学习率为0.01,随着训练的epoch线性衰减。训练使用的损失函数为FocalLoss损失函数,缓解数据集类别不均衡的问题。
步骤4.2、训练时对输入的数据进行数据增强,以增加数据多样性。数据增强会随机使用以下一种策略进行:不做增强、随机进行竖直方向或水平方向的翻转,顺时针或逆时针在5°范围内的随机旋转,随机的高斯噪声,直方图均衡、图像锐化。之后使用数据集的均值与标准差,对图像进行标准化处理。
步骤4.3、在训练到80个epoch后,每个epoch训练完毕后,会使用五折交叉验证的方法测试模型精度。选择其中精度最高的模型作为结果。
步骤4.4、训练结束后,在测试集上验证模型是否有效。
与现有技术相比,本发明具有以下优势:
本发明对传统的U-Net架构进行了改造,在编码器中的下采样操作前添加了高斯低通滤波器,以保证模型的下采样结果更为精细,提高了卷积层提取图像特征的准确性。同时,在解码器中,除了会与编码器的特征图进行拼接,还会将高斯低通滤波器去除的高频信息加回特征图中,防止了带钢图像不同尺度下微小细节的流失。总体上来讲,本发明的方法可以比较高效准确的对带钢图像的缺陷进行检测。
附图说明
图1为本发明所提出模型的主体架构图;
图2为本发明中编码器的结构图;
图3为本发明设计的高斯低通滤波模块结构;
图4为本发明设计的解码器模块结构;
具体实施方式
以下结合具体实施例,并参照附图,对本发明进一步详细说明。
本发明提供一种基于深度学习带钢缺陷检测方法,具体包括以下步骤:
本发明所用到的硬件设备有PC机1台、GTX1080显卡1张;
步骤1、收集带钢的图像数据集,并对数据集中的数据进行清洗。
步骤2、将数据集中的带钢图像随机划分为训练集和测试集,并使用ImageNet数据集的方差与均值进行正则化。
步骤2.1、随机地震图像将数据集划分为训练集和测试集;
步骤2.2、将训练接的每张分辨率为256×1600的带钢图像,切分为四张256×400的小图像;
步骤3、如图1所示,构建模型结构,其中编码器使用在ImageNet数据集上预训练好的ResNet50网络,并在每次下采样之前插入高斯低通滤波器。解码器为5个解码器模块堆叠而成。
步骤3.1、构建编码器部分。使用在ImageNet数据集上训练好的ResNet50作为模型解码器。如图2所示,之后在ResNet50的每次下采样操作前插入高斯低通滤波器模块。高斯低通滤波器模块的结构如图3所示。该模块首先会通过高斯低通滤波器降低特征图的频率,使下采样后的特征图更为清晰。之后让高斯低通滤波器处理前的特征图与处理后的特征图做差,计算出损失的高频信息,为解码器部分的输入做准备。
步骤3.2、构建解码器部分。该解码器以U-Net的解码器设计作为主体结构,由5个解码器模块堆叠组成。这5个解码器模块会将编码器输出的特征图进行连续的上采样,直到特征图恢复至原图大小,最终输出的结果即为缺陷的识别结果。前4个解码器模块的结构如图4所示,这四个解码器的输入会与编码器输出的特征图进行拼接,综合利用高层级与低层级的语义信息,以获得更好的分割结果。在原U-Net解码器的基础上,前4个解码器模块的输入还会加上编码器中对应高斯低通滤波器去除的高频信息,以避免细节信息的损失。最后一个解码器除了不会接受编码器的输入,其他部分与前4个解码器模块相同。
步骤4、对步骤3构建的模型进行训练。训练时输入的数据会进行随机的数据增强。训练结束后,在测试集上进行测试,检测模型的训练结果是否满足要求。
步骤4.1、对构建好的模型进行训练,使用标准的Adam优化算法对模型进行训练。模型总共训练100个epoch,batch size为10。训练的初始学习率为0.01,随着训练的epoch线性衰减。训练使用的损失函数为Focal Loss损失函数,缓解数据集类别不均衡的问题。
步骤4.2、训练时对输入的数据进行数据增强,以增加数据多样性。数据增强会随机使用以下一种策略进行:不做增强、随机进行竖直方向或水平方向的翻转,顺时针或逆时针在5°范围内的随机旋转,随机的高斯噪声,直方图均衡、图像锐化。之后使用数据集的均值与标准差,对图像进行标准化处理。
步骤4.3、在训练到80个epoch后,每个epoch训练完毕后,会使用五折交叉验证的方法测试模型精度。选择其中精度最高的模型作为结果。
步骤4.4、训练结束后,在测试集上验证模型是否有效。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 一种基于深度学习的带钢缺陷检测方法
- 一种基于深度学习的热轧带钢表面缺陷检测方法及装置