一种基于混合深度可分离卷积的实时语义分割方法
文献发布时间:2023-06-19 11:08:20
技术领域
本发明属于计算机视觉中的图像实时语义分割领域,是一种利用卷积神经网络进行语义分割的方法。
背景技术
在计算机视觉领域中,图像语义分割是一个关键任务,这个任务也是研究的热点。语义分割的目的是将摄像机拍摄的场景图片分割成一系列不相交的图像区域,为图像中的每个像素赋予一个特定的类别,这些类别通常包括可数对象(如自行车、汽车、人)和不可数对象(如天空、道路、草地)。随着深度学习的兴起,图像语义分割技术为场景解析中铺平了道路,在自动驾驶、增强现实、视频监控中发挥着举足轻重的作用。
然而现有的语义分割方法主要着眼于提高性能,这些算法为了提高分割的准确率,特征编码器通常会采用较为复杂的主干网络,语义解码器也会采用密集计算型的网络结构,例如空间金字塔池化,浅层深层特征融合,设置不同扩张率的空洞卷积扩大感受野,所以网络模型规模很大,场景分割效率较低。但对于实际应用来说,算法需要保持较高的分割精度,同时实时性的要求也必须满足。而一些实时语义分割算法(例如ICNet算法)虽然速度较快,但是受局部感受野机制的限制,缺乏对场景图像中不同尺度的目标特征的充分理解,难以获得各类特征的长期记忆,导致准确率较低。因此需要突破局部感受野的限制,融合图像多尺度特征进行预测,提高场景分割的准确率,同时满足实时性。
为了解决上述问题,本方明提出了一种基于混合深度可分离卷积的实时语义分割方法,采用混合深度可分离卷积将多个不同尺寸的卷积核混合到单个的深度可分离卷积单元中,设计并行的不同尺寸的卷积来增强多尺度目标特征的表达能力,同时使用特征重排来消除通道间信息相互独立的情况,突破了局部感受野的限制,提升不同尺寸的特征提取能力,从而提高了最终特征图的质量。本发明所提出的方法在分割效率和分割准确率之间取得良好的平衡。
发明内容
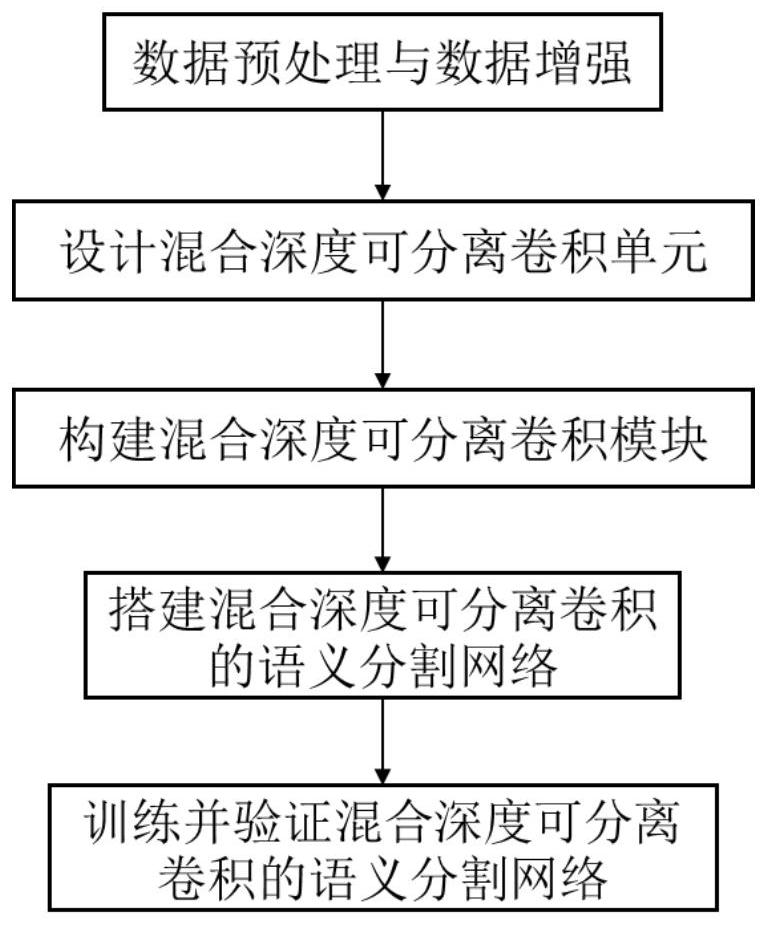
本发明针对图像语义分割领域模型分割效率和分割准确度无法平衡的问题,设计了一种基于混合深度可分离卷积的实时语义分割方法,在预测效率和预测准确率方面取得了比较好的平衡,进一步促进了语义分割的实际应用。本发明方法的整体示意图如图1所示。
一种基于混合深度可分离卷积的实时语义分割方法,包含下列步骤:
(1)数据预处理与数据增强:本发明选取了公开的城市景观数据集的3475张图片,其中2975张图像用作训练集,500张图像用作验证集;训练集用于训练网络模型,验证数据集用来挑选最佳的训练结果;从标注信息中选取出符合实际应用的类别,并剔除掉不适用的数据类别;将这些数据进行归一化处理和数据扩充,数据扩充使用了6种不同的数据增强方法,随机裁剪缩放、随机水平翻转、随机亮度、随机饱和度、随机对比度和高斯模糊。
(2)设计混合深度可分离卷积单元:为了突破普通卷积的存在局部感受野的限制,提升上述图像数据的多尺度特征表达和满足实时预测的要求,本发明的混合深度可分离卷积如图2所示,首先将待处理的特征图按通道平均分成4组并对这4组特征图的边缘用0来进行填充;其次这4组分别使用不同大小的奇数卷积核进行特征提取;然后将得到的4组特征按通道进行拼接;最后将特征映射交替重排来消除通道间信息相互独立的问题。
(3)构建混合深度可分离卷积模块:本发明的混合深度可分离卷积模块如图3所示,它由4个混合深度可分离卷积单元、4个归一化层、4个非线性激活层串联堆叠而成,模块内使用了3个跳跃连接,模块之间使用了1×1卷积残差连接缓解梯度消失的问题。
(4)搭建混合深度可分离卷积语义分割网络:本发明的网络结构图如图4所示,主干网络包括了混合深度可分离卷积、归一化层、非线性激活层,由4个混合深度可分离卷积模块串联而成,每一卷积块都会生成特征图。为了获得分辨率更高的特征图,在最后2个混合深度可分离卷积模块中移除下采样操作,使最终特征图尺寸是输入图像的1/8,从而保留特征映射的更多细节。
(5)训练并验证混合深度可分离卷积的语义分割网络:将处理好的图片输入到设计好的网络中,经过网络的前向计算输出预测的分割结果,使用交叉熵损失函数与对应的像素级标签计算损失值;采用动量随机梯度下降优化器,动量系数设为0.9,权重衰减超参因子设置为0.00005,学习率热身5次并由0递增至0.003;迭代训练直至交叉熵损失收敛并在验证集上验证性能。
本发明设计了一种混合深度可分离卷积的实时语义分割方法,在城市景观验证数据集上,使用混合深度可分离卷积构建的主干网络具有预测精度较高、参数量小,快速轻量化的优点,在预测效率和预测准确率方面取得了比较好的平衡。它能够实现高效的场景感知任务,进一步促进其在自动驾驶、增强现实、视频监控等诸多领域的应用。
附图说明
图1为本发明方法的整体示意图。
图2为本发明提出的混合深度可分离卷积单元示意图。
图3为本发明提出的混合深度可分离卷积模块结构图。
图4为本发明提出的基于混合深度可分离卷积的语义分割网络结构图。
具体实施方式
以下结合说明书附图,对本发明作进一步的描述:
本发明是一种基于混合深度可分离卷积的实时语义分割方法,如图1所示,该方法的具体流程为:首先选取公开的城市景观数据集的3475张图片,对这些数据进行预处理和数据增强;然后为了提升对这些图像数据中的多尺度特征表达和满足实时预测的要求,设计了混合深度可分离卷积单元;然后构建了混合深度可分离卷积模块,进一步提升多尺度特征表达能力同时消除多尺度特征的混叠效应;然后搭建混合深度可分离卷积的语义分割网络;最后,训练并验证混合深度可分离卷积的语义分割网络,将第一步处理好的图片输入到网络中训练,通过网络的前向推理进行性能验证并输出预测的分割结果。
本发明在公开数据集上得到了良好的分割性能验证,具体实施方式包含以下几个步骤:
第一步:数据预处理与数据增强
(1)数据准备。选取了公开的城市景观数据集的3475张图片,其中2975张图像源自训练集,其余500张图像来自验证集,这些图像包含了所应用的实际交通场景,取自于50个不同城市的驾驶场景的图像,并且拥有高质量的像素级标注信息。从标注信息中选取出符合实际应用的类别,并剔除掉不适用的类别将其设置为忽略类。
(2)归一化和数据增强。首先将RGB(红绿蓝)图像进行归一化处理,以此消除奇异样本数据可能带来的不良影响。其次为了提升模型的分割精度以及模型的泛化能力,对准备的数据使用了6种不同的数据增强方法:随机裁剪缩放、随机水平翻转、随机亮度、随机饱和度、随机对比度和高斯模糊。
第二步:设计混合深度可分离卷积单元
由于上述选取的图像中含有许多不同尺寸大小的目标,单一的卷积映射往往会缺乏多尺度特征的充分理解。为此,设计了的混合深度可分离卷积单元,它如图2所示,首先将待处理的特征图按通道平均分成4组,这4组特征图并行馈送至不同大小的奇数卷积核来提取多尺度的特征映射,这些不同大小的卷积核分别是3×3、5×5、7×7、9×9的深度可分离卷积。为了对齐输出的特征映射尺寸大小,在卷积之前需要对输入的4组特征图的边缘用0来进行填充。然后将得到的4组特征映射按通道维度进行拼接;由于深度可分离卷积属于组卷积,容易造成通道间信息相互独立的情况,缺少组间及通道间的特征融合。所以在进行拼接之后进行特征重排,将4组特征映射进行打乱,打乱的过程是按这4组特征图通道的自然顺序依次堆叠在一起,这样做的目的是为了消除通道间信息相互独立的问题,有利于特征提取能力的提升,进而提升网络对不同尺度的目标提取特征的能力。
第三步:构建混合深度可分离卷积模块
本发明构建的混合深度可分离卷积模块如图3所示。在第二步的基础上由4个混合深度可分离卷积单元、4个归一化层、4个非线性激活层堆叠而成。具体地,混合深度可分离卷积模块由混合深度可分离卷积单元、归一化层、非线性激活层依次串联堆叠4次构成,其中第一、二、三个混合深度可分离卷积单元所输出的特征映射的通道数都一致,输出的特征映射尺寸都一致;第四个混合深度可分离卷积单元输出的特征映射通道数是输入的特征通道数的2倍,输出的特征映射尺寸是输入的特征尺寸的二分之一。同时使用了3个跳跃连接的残差结构来缓解梯度消失的问题。在第一个混合深度可分离卷积单元里,这4组卷积从左至右使用的是3×3、5×5、7×7、9×9的深度可分离卷积核;第二个混合深度可分离卷积单元,这4组从左至右使用的是5×5、7×7、9×9、3×3的深度可分离卷积核;第三个混合深度可分离卷积单元,这4组从左至右使用的是7×7、9×9、3×3、5×5的深度可分离卷积核;第四个混合深度可分离卷积单元,这4组从左至右使用的是9×9、3×3、5×5、7×7的深度可分离卷积核;使用不同次序的目的是消除多尺度特征的混叠效应,进一步提升多尺度特征表达能力。
第四步:搭建混合深度可分离卷积的语义分割网络
为了在预测效率和预测准确率方面取得了比较好的平衡,本发明在上述基础上搭建了混合深度可分离卷积的语义分割网络。它如图4所示,负责提取特征的主干网络由18个卷积层串联而成。其中第1层为输入通道数3,输出通道数是64,步长为2的7×7卷积,其后紧跟归一化层和非线性激活层,第2层到第5层是第一个混合深度可分离卷积模块,它的输入通道数是64,输出通道数是128,其中第2层到第4层的输入通道数是64,输出通道数是64,步长为1的混合深度可分离卷积单元,第5层的输入通道数是64,输出通道数是128,步长为2的混合深度可分离卷积单元。第6层到第9层是第二个混合深度可分离卷积模块,它的输入通道数是128,输出通道数是256,其中第6层到第8层的输入通道数是128,输出通道数是128,步长为1的混合深度可分离卷积单元,第9层的输入通道数是128,输出通道数是256,步长为2的混合深度可分离卷积单元。第10层到第13层是第三个混合深度可分离卷积模块,它的输入通道数是256,输出通道数是512,其中第10层到第12层的输入通道数是256,输出通道数是256,步长为1的混合深度可分离卷积单元,第13层的输入通道数是256,输出通道数是512,采用的是步长为1的混合深度可分离卷积单元,目的为了提升特征的分辨率。第14层到第17层是第四个混合深度可分离卷积模块,它的输入通道数是512,输出通道数是1024,其中第14层到第16层的输入通道数是512,输出通道数是512,步长为1的混合深度可分离卷积单元,第17层的输入通道数是512,输出通道数是1024,采用的是步长为1的混合深度可分离卷积单元,目的同样是为了提升特征映射的分辨率。第18层的输入通道数是1024,输出通道大小是数据集标签的类别数,采用的是步长为1的3×3卷积作为最后的分类层。同时在每个混合深度可分离卷积模块内使用了3个跳跃连接的残差结构来缓解梯度消失,每个混合深度可分离卷积模块之间使用了1×1卷积进行连接,目的是为了提升训练效率,避免梯度消失的问题。最后利用第18层的输出结果经过一层上采样层,使用双线性插值将特征映射尺寸放大8倍。双线性插值函数如公式1所示。
f(u+i,v+j)=(1-i)(1-j)f(u,v)+i(1-j)f(u+1,v)+(1-i)jf(u,v+1)+ijf(u+1,v+1) (1)
其中f(u,v)为特征映射在(u,v)位置的像素值,对于双线性插值结果像素坐标为(u+i,v+j),其中u,v为浮点坐标中的整数部分,i,j为浮点坐标的小数部分。双线性插值结果像素表示为f(u+i,v+j),它是由四个邻近位置的像素值f(u,v),f(u,v+1),f(u+1,v),f(u+1,v+1)按比例加权计算得到。
第五步:训练并验证混合深度可分离卷积的语义分割网络
(1)初始化混合深度可分离卷积的语义分割网络参数。这些参数包括各个卷积层的参数,归一化层的参数。采用的是Xavier方法进行随机初始化。
(2)配置网络超参数。初始学习率设置成0.003,并采用学习率热身策略,热身5次之后学习率从0递增至初始学习率值;采用动量随机梯度下降优化器,动量系数设为0.9,权重衰减超参因子设置为0.00005;使用交叉熵损失函数,损失权重系数默认为1。
(3)模型训练。将第一步处理好的训练图片输入到网络中,通过主干网络的前向计算输出预测的分割结果,使用交叉熵损失函数与图片对应的像素级标签计算损失值。通过损失值的反向传播,计算各个层参数的梯度,使用动量随机梯度下降法更新这些参数。不断的进行迭代,直至交叉熵损失在某个值附近上下波动,此时模型才视为已收敛。
交叉熵损失函数如公式(2)所示:
Loss=-|y
其中y
(4)验证模型分割性能。为了验证基于混合深度可分离卷积的实时语义分割方法的分割性能,设计了一组对比实验,分别使用普通的3×3卷积、混合深度可分离卷积单元构建上述的语义分割网络,两者通过上述的迭代训练,同样在城市景观验证集上进行测试,实验结果证明,与普通卷积方式结果相比本发明的方法参数量下降了约五分之三,计算量减少了约四分之三,满足实时性的同时保持了较高的预测精度。本发明使用的混合深度可分离卷积构建的主干网络的平均交并比(MIOU)结果是73.48%,具有预测精度较高、参数量小,快速轻量化的优点,和经典的实时语义分割网络ICNet的MIOU结果71.7%相比,有1.78%的性能优势。评价指标平均交并比MIOU如公式(3)所示:
其中TO代表着真正例,FO代表着假正例,FN代表着假负例。
- 一种基于混合深度可分离卷积的实时语义分割方法
- 一种基于双分支深度卷积神经网络的实时语义分割方法