基于规则意图表决器的D-S证据理论多模态融合人机交互方法
文献发布时间:2023-06-19 11:08:20
技术领域
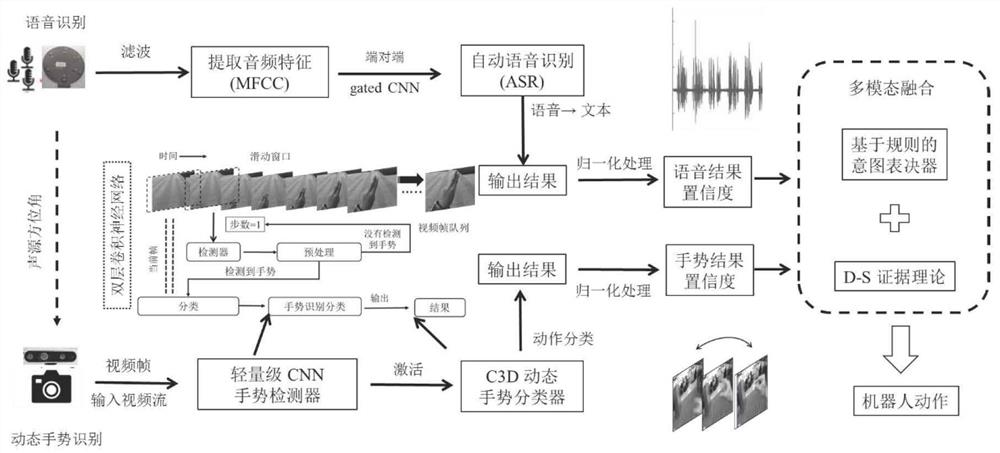
本发明涉及人机交互(Human-robot interaction,HRI)技术和多模态融合领域。具体包括:机器人听觉系统利用MUSIC算法确定声源方位,经过MFCC的语音特征预处理,利用端对端门控CNN识别语音结果;视觉系统使用双层网络来对动态手势进行检测和识别,使用3D CNN和LSTM的深度CNN框架来处理时序信息,对手势动作进行分类。对语音和手势的识别网络添加全连接层,进行归一化处理,并进行基于规则意图表决器的D-S证据理论算法对不同模态进行融合,输出机器人对于交互对象的意图理解。
背景技术
人机交互是服务机器人研究的核心问题,感知方式在人与机器人的交流中起着最基础的作用,人们可以通过手势、语言、身体、表情、触摸等方式与机器人进行交互。现有的交互方式分为设备交互方式,单一交互方式和多模态交互方式。设备交互通过交互对象佩戴上信息采集器装置用来向机器人传达信息,但这样会限制交互的灵活性和舒适度。而单一模式下的人机交互会受到周围环境的影响,交互对象自身的行为也会限制机器人识别的准确性,其次单一的感知模式限制了内容的多样性,使交互过程单一乏味,降低了舒适度。
多模态交互方式是如今的主要研究方向,不同模态下的信息具有冗余性和互补性,现有的融合方案有概率论方法和神经网络方法等,大部分关注于不同模态下的互补性,而不能解决冲突性来解决不确定信息。
证据理论又叫Dempster证据合成规则,利用上、下限概率来解决多值映射问题。具有直接表达“不确定”和“不知道”的能力,在专家系统、信息融合等领域得到了广泛应用。
发明内容
为了克服上述现有技术的不足,本发明提供了一种基于声觉和视觉的多模态人机交互机制,采用基于规则意图表决器的D-S证据理论融合算法:
(1)对音频信号进行基于MFCC技术的预处理提取出语音特征,送入到训练过的CNN端对端网络架构语音识别分类。
(2)采用双层网络结构进行对动态手势的识别,由两个网络模块构成:①检测器:轻量级的CNN体系结构,实时运行用于检测手势。②分类器:深度CNN体系结构,检测器队列始终处于分类器队列之前,在输入视频流上使用滑动窗口方法,只有检测到手势信息时,分类器才会被激活。
(3)对声觉和视觉的网络输出增加全连接层,输出每个标签的置信度,将两个网络的结果输出到基于规则的意图表决器中来判断不同模态之间的联系,共有无模态响应,单一模态,双模态相互补充和两个模态冲突四种情况,前三种情况输出指向结果,当出现两种模态冲突时经改进的D-S证据理论解决冲突和关联性输出正确结果。
本发明的具体步骤如下:
Step1语音识别
Step1.1本发明中语音采集装置为六麦环形阵列,对音频的输入增加了空间域和时域属性,判断语音对象方位角的同时可以实现硬件降噪,对语音输入信号加强。确认方位角采用高分辨率谱估计法,麦克风之间的距离为d,空间中信号的波长为λ,第k个源信号到第m个麦克风的波前信号为f
谱函数极大值所对应的θ就是信号源方向的估计值,即声源定位的结果。本发明中最初六个麦克风的权重相同:V
Step1.2本发明中使用梅尔倒谱系数(Mel-scaleFrequency CepstralCoefficients,MFCC)对语音输入信号进行滤波,降低噪声的影响,基于预处理,分帧,加窗和快速傅里叶变换,并经过三角带通滤波器滤波后得到的功率归一化音频的频谱图作为语音识别网络模型的输入,每个带通滤波器输出的信号能量能够作为信号的基本特征,送入到语音识别网络中。
Step1.3本发明专注于语音识别的速度,基于Wav2letter设计了一个完全基于CNN的端对端网络架构,共有12层卷积结构,模型第一层提取经MFCC滤波后的语音关键特征,全网络可以看作一个非线性卷积,核宽为31280,步长为320,使用门控线性单元(GLU)作为激活函数,并将损失函数设为Connectionist temporal classification(CTC),网络在预测模型时不需要预先对数据做语音对齐工作。
Step2动态手势识别
Step2.1使用双层网络结构来进行对动态手势的识别,由两个模块构成:①检测器:轻量级的CNN体系结构,实时运行用于检测手势。②分类器:深度CNN体系结构。在输入视频流上使用滑动窗口方法,检测器队列始终处于分类器队列之前,不会错过手势信息,步幅s=1,只有检测到手势信息时,分类器才会被激活。
Step2.2检测器结构为ResNet,将检测器预测到的原始概率添加到一个长度为k的队列(q
Step3多模态融合策略
Step3.1对声觉和视觉的网络输出都加上全连接层,并进行归一化处理,可以得到对所有标签的置信度{label(i),Con(V
S={label(i,j),Con(V
T为设计存储数据的容器,同一标签下两种模态输出结果相对应。
Step3.2设置上下阈值ULN和UCL,能够提现出模型对事件的预测强度,分别设置为80%和20%,设立标志位flag表明两个模态之间的信息联系情况,意图表决器会对当前两个模态的预测结果进行逻辑运算,并输出flag值来表示当前两个模态之间的联系。共有无模态响应(flag=0),单一模态(flag=1),双模态相互补充(flag=2),两个模态冲突(flag=3)四种情况。
Step3.2.1无模态响应时即视觉和听觉系统都没有检测到对应模板的输入信号只有label(0)有确切数值,而其他标签label对应的输出置信度小于UCL,此时机器人无相应动作:
Step3.2.2单一模态是说只存在一种模态,视觉或者听觉作用,而另外一种模态并没有检测到输入交互信号,此时机器人运行到单一模态机制,输出结果即为此模态识别结果:
Step3.2.3双模态相互补充即为多模态的大多应用情况,视觉和听觉同时对相同label的输入信号进行识别和检测,能有效加强对交互对象的意图理解:
Step3.2.4两个模态冲突,是多模态融合机制种的不确定事件,此时两种模态预测结果为不同的标签值。
Step3.3根据标志位flag当前的值来判断机器人当前工作的模式以及两种模态的联系,当flag=0时,表示并没有输入,或输入的信号不在机器人的理解范围内,此时对应的机器人无动作,当flag=1,2时,为单一模态工作模式以及多模态工作模式下的信息具有互补性,此时意图表决器会输出唯一确切值,当flag=3时,表示工作在多模态机制下,不同模态的识别结果具有冲突性,针对这种情况,本发明引入了D-S证据理论并对它进行改进使其更适宜于人机交互多模态冲突问题。
Step3.4设立的标签label都是相互独立的,满足D-S证据理论的先验条件,label的所有值构成识别框架Θ,当出现不确定事件的时候,视觉和听觉的输出归一化处理为基本概率分配,简称BPA,{Con(V
信任函数Bel(A)和似然函数Pl(A)组成信任区间[Bel(A),Pl(A)],用以表示对某个假设的确认程度。证据理论关键的部分是证据合成公式,由于数据来源不同,同样的证据会存在多个数量的基本概率分配函数(本文中运用了视觉和听觉多模态,所以有两个分配函数)。证据理论合成公式对多个基本概率分配函数进行了正交和运算的合成方法,组合规则如下:
其中,K为归一化常数,表现出了不同证据中的冲突程度:
传统D-S证据理论中在标签数量比较大的情况下会有指数爆炸的情况发生,同时为了使融合算法更适合于人机交互,对机器人的指令只能是输出一种单一指令,不会存在输出指令合集而造成机器人困扰的情况发生,所以针对Dempster合成规则进行了改进,由合成规则可以看出,当所有的焦元都是单个假设集,且这些焦元都满足Bayes独立条件时。Dempster证据合成公式就退化为Bayes公式,所以当在合成规则时只关注于识别框架中的单一元素,忽略其他多个假设组成的子集,并将单个元素使用mass函数的Bayes近似来计算更新:
与现有技术相比,本发明具有以下优点:
(1)本发明从机器人的视觉和听觉出发,让两种模式以并行协助的方式来实现人机交互的通信过程,解决了单一模式下的局限性,能够接受更多信息,做出准确的意图理解,视觉和听觉更容易被人接受,并在交互机制上做出改进,能够显著提升交互过程的舒适度。
(2)本发明对于多模态融合过程中不同模态信息之间的冗余性和互补性,设计了基于规则的意图表决器,能够将不同模态对当前信息输入的输出判断结果一一对应,并利用标志位flag来表明它们之间的联系,如果出现冲突则使用改进的D-S证据理论进行信息融合。这样的合成结果更为关注深层次的信息之间的联系,很好的解决多模态之间的融合,也能适应不同模态之间的证据冲突问题,并且关注于标签中的单一结果,更适用于的人机交互工作。
附图说明
图1为基于视觉和听觉的多模态人机交互技术流程图;
图2为端对端的语音识别网络结构图;
图3为语音信号的预处理和注意力机制流程;
图4为3D CNN和LSTM构成的动态手势识别结构图;
图5为本发明的实施流程图。
具体实施方式
本发明具体实验是在带有六麦环形阵列以及深度相机,实验室自主研发的机器人平台上进行,上位机为Intel旗下的高运算处理器TX2,操作系统为Ubuntu,使用conda安装环境配置Pytorch框架下的深度CNN完成语音和手势识别任务,整个程序是在机器人分散控制框架——ROS下运行,实验场景在室内进行。结合图1和图5具体说明本发明实施方式。
Step1网络模型的预训练和微调
Step1.1语音识别网络的预训练数据集为公开的中文数据集THCHS-30,训练后在自身定义的数据集进行训练,并设立5个labels。并将网络的输入端进入到MFCC的语音特征输出端,滤波去除高频段和低频段语音特征,符合的交流需求。
Step1.2动态手势识别双层网络:数据集采用公开动态手势数据集EgoGesture,训练后在自身数据集上进行微调,并使用裁剪缩放,视频帧循环等方式进行数据加强,检测器输出有无手势两种labels,分类器设立训练标签与语音相对应labels=5,输入112x112的图像。
Step1.3将语音识别和动态手势识别网络添加全连接层,并进行归一化处理,可以得到全部标签的置信度。
Step2数据的采集
Step2.1语音信号的获取:六麦环形阵列下语音信号的输入为:V
Step2.2机器人根据声源方向角定位调整自身姿态,使自身位置正对于交互对象,获取交互对象视野和手势信息,视觉系统可以工作,同时提升了舒适度。
Step2.3相机传感器开始工作,检测器和分类器队列同步进行,为了避免错过手势,检测器处于分类器的队列前,以步幅s=1滑动视频帧,检测器预测到的原始概率添加到一个长度为k的队列(q
Step3多模态下的识别
Step3.1语音信号输入后经过MFCC对输入音频信号进行滤波,基于预处理,分帧,加窗和快速傅里叶变换,并经过三角带通滤波器滤波后得到的功率归一化音频的频谱图作为语音识别网络模型的输入,每个带通滤波器输出的信号能量能够作为信号的基本特征。
Step3.2将提取的语音特征送入到端对端CNN中识别,GLU作为激活函数,损失函数为CTC。
Step3.3视频下的动态手势识别:当检测器识别到手势时,分类器开始工作,输入到分类器网络中的图像大小为112*112,开始帧和结束帧为检测器识别到手势开始和消失的帧数和设置最大帧数之间的最小值。优化器为随机下降梯度法(SGD),阻尼因子为0.9,权重衰减为0.001。
Step4对语音和手势的识别网络中添加全连接层,并经归一化处理后输出全部标签的预测概率值:{label(i),Con(V
Step5多模态融合
Step5.1将两个网络的结果输出到的基于规则的意图表决器中,在T中每组数据都是会包含一个标签和对应的手势或者语音置信度:S={label(i,j),Con(V
Step5.2上下阈值ULN和UCL分别设置为80%和20%,设立标志位flag表明两个模态之间的信息联系情况,意图表决器会对当前两个模态的预测结果进行逻辑运算,并输出flag值来表示当前两个模态之间的联系。
Step6若Flag值为0,则代表无对应输入,则对应无输出,机器人无动作。
Step7若Flag值为1,则代表单一模式下作用;若为2则是两种模态相互补充,指向同一个结果。
Step8若Flag为3则代表两种模态下有冲突,为不确定事件,这时需要用改进的D-S证据理论来计算融合结果。
Step8.1{Con(V
Step8.2将单个元素使用mass函数的Bayes近似来计算更新:
Step9将多模态融合的输出结果输入到机器人中,机器人通过ROS接口输出参数到电机中,机器人做出相应动作。
- 基于规则意图表决器的D-S证据理论多模态融合人机交互方法
- 一种基于LSTM与D-S证据理论的舰船编队意图融合识别方法