基于自然语言处理的市长热线舆情决策支持方法及系统
文献发布时间:2023-06-19 11:08:20
技术领域
本发明属于人工智能与机器学习技术领域,尤其涉及一种基于自然语言处理的市长热线舆情决策支持方法及系统。
背景技术
随着公民维权意识不断提升,市长热线逐步成为大众利益表达、情感宣泄、思想碰撞的重要渠道。在复杂的社会环境和利益冲突的作用下,突发事件网络舆情时有发生,网络舆情在突发公共事件发生后所产生的负面效应更容易被放大,导致更多的个人问题泛化和复杂化,并加剧社会矛盾,从而引发公共危机的连锁反应。传统意义上的封杀、围堵、漠视等舆情管理方式不但根除不了舆情危机,还有可能进一步损害形象。因此对舆情爆发进行早期的预判和治理显得尤为重要。
随着信息技术的不断发展,利用人工智能与机器学习技术帮助部门进行科学决策的案例也越来越多。自然语言处理是人工智能的一个重要分支,其可以用计算机技术处理和分析自然语言。
2017年12月工信部发表《促进新一代人工智能产业发展三年行动计划(2018-2020年)》,专门提到“鼓励部门率先运用人工智能提升业务效率和管理服务水平”。在当前社会,市长热线要当好响应各方诉求的“总客服”,以群众和市场主体的便捷度、满意度为衡量标准,提高市长热线办理质效和系统智能化水平,形成快捷响应、高效办理、跟踪督办、及时反馈、分析提升的闭环。热线信息资源是及时了解民情的“窗口”,是政务工作与决策的“食粮”。
目前市长热线对数据价值的挖掘和开发利用的程度不高,对热线信息资源的利用和探索还处于初级阶段。本发明将运用大数据挖掘、机器学习等先进技术为市长热线设计一套舆情决策支持系统,对舆情危机的早期发现和及时治理提供强有力的保障。
发明内容
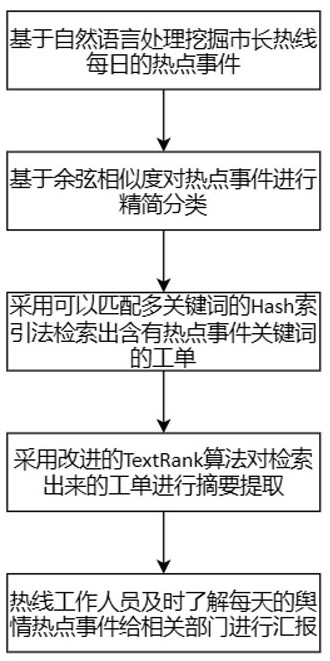
发明目的:针对以上问题,本发明提出一种基于自然语言处理的市长热线舆情决策支持方法及系统,基于自然语言处理挖掘热线每日的热点事件,并对热点事件进行精简分类,然后采用匹配多关键词的Hash索引法检索出含有热点关键词的工单,采用改进的TextRank算法对检索出来的工单进行摘要提取,将工单中最关键的信息反馈出来,热线的工作人员可以及时的了解每天的投诉热点和舆情动向,给相关部门进行汇报。
技术方案:为实现本发明的目的,本发明所采用的技术方案是:
一种基于自然语言处理的市长热线舆情决策支持方法,包括步骤:
(1)基于自然语言处理挖掘市长热线每日的热点事件;
(2)基于余弦相似度对热点事件进行精简分类;
(3)采用匹配多关键词的Hash索引法检索出含有热点事件关键词的投诉工单;
(4)采用改进的TextRank算法对检索出来的投诉工单进行摘要提取;
(5)热线工作人员根据摘要报告了解每天的舆情热点事件给相关部门进行汇报。
进一步地,所述步骤(1)具体包括步骤:
(1.1)对投诉工单进行分词和关键词提取,关键词的提取方法为TF-IDF算法;
(1.2)构造关键词FpTree;
(1.3)基于关键词FPTree挖掘关键词频繁项集。
进一步地,所述步骤(1.2)构造关键词FpTree包括步骤:
1)设定最小绝对支持度,扫描数据记录,生成关键词一级频繁项集,并按出现次数由多到少排序;
2)再次扫描数据记录,对每条记录中出现的在步骤1)中产生的关键词一级频繁项集,按步骤1)的顺序排序。
进一步地,所述步骤(1.3)基于关键词FPTree挖掘关键词频繁项集包括步骤:
1)构造条件模式基,条件模式基是要挖掘的项集的前缀路径;
2)构造条件FPTree;
3)递归的在条件FPTree上进行挖掘。
进一步地,所述步骤(2)具体包括步骤:
(2.1)设置多个热点分类标志,每个热点分类标志包括若干关键词;
(2.2)计算热点分类标志的所有关键词,与关键词频繁项集之间的余弦相似度;
(2.3)找到热点分类标志中与关键词频繁项集余弦相似度最大的热点分类标志,并为关键词频繁项集打上热点分类标志。
进一步地,所述步骤(2.2)余弦相似度计算包括步骤:
1)将关键词频繁项集处理成One-Hot编码;
One-Hot编码是分类变量作为二进制向量的表示,将分类值映射到整数值,然后每个整数值被表示为二进制向量;
2)对One-Hot编码的关键词频繁项集进行余弦相似度计算。
进一步地,所述步骤(3)中,
将市长热线投诉工单文本数据库进行预处理,获得关键词与工单号对应的hash表,再采用多关键词检索,利用工单唯一主键对工单进行检索。
进一步地,所述步骤(4)具体包括步骤:
(4.1)将工单内容处理为包含若干句子的文本,将句子转化为机器可以理解的句子向量;
(4.2)进行句子向量之间的余弦相似度计算,得到相似度矩阵,作为边权重;采用TF-IDF得分作为初始权重值;
(4.3)进行TextRank迭代,计算每个句子的TextRank值,得到句子排名;根据句子排名抽取自动摘要。
一种基于自然语言处理的市长热线舆情决策支持系统,包括基础层、数据层、支撑层、应用层、服务层和用户层;
基础层为项目实施的硬件设置,包括机房和网络环境;
数据层包括基础库和智能库;基础库为一次数据,是原始的工单文本信息;智能库为二次数据,是处理过的数据库;
支撑层是算法和应用服务,包括FP-Growth、热点问题分类、信息检索和自动摘要提取;
应用层为具体的应用服务,包括智慧舆情监督、智慧民生感知和智慧决策支持;
服务层包括web端和移动端;
用户层包括领导,业务人员和运维人员。
有益效果:本发明将基于自然语言处理,挖掘热线每日的热点数据,并对热点进行精简分类,然后采用可以匹配多关键词的Hash索引法检索出含有热点关键词的工单,采用改进的TextRank算法对检索出来的工单进行摘要提取,将工单中最关键的信息反馈出来,热线的工作人员可以及时的了解每天的投诉热点和舆情动向,给相关部门进行汇报。
本发明采用自然语言处理技术为市长热线开发一套舆情决策支持系统,系统可以通过机器学习算法自动挖掘每日舆情热点,并设置阈值进行舆情报警,指导工作人员即使做出决策支持。采用摘要自动抽取方法帮助工作人员从大量相关工单中把握最核心,最重要的问题,方便撰写舆情日报、周报和月报并自助推送给有关部门。
本决策支持系统可以把工作人员从海量投诉工单中寻找群体性事件的时间由原先的2天到现在的实时展示,系统极大的提高了工作人员的办事效率,提升了公众问题的处理速度。在本系统部署后,市长热线工作人员可以实时监控舆情信息,极大的提高工作人员的办事效率,并通过本系统及时发现小区管理混乱,微信平台诈骗、商场活动扰民等一系列民生问题并采取了积极的应对措施。
附图说明
图1是本发明所述的基于自然语言处理的市长热线舆情决策支持方法流程图;
图2是关键词FpTree构造过程图;
图3是Hash索引存储工单关键词信息示意图;
图4是BERT模型的embedding层示意图;
图5是改进的TextRank流程图;
图6是本发明所述的基于自然语言处理的市长热线舆情决策支持系统框图。
具体实施方式
下面结合附图和实施例对本发明的技术方案作进一步的说明。
如图1所示,本发明所述的基于自然语言处理的市长热线舆情决策支持方法,包括步骤:
(1)基于自然语言处理,挖掘市长热线每日的热点事件;
本发明研究对象为市长热线的投诉工单,将投诉工单的关键词看作项集,挖掘市长热线每日的热点事件,即频繁项集挖掘。
频繁项集挖掘包括步骤:
(1.1)投诉工单的存储形式为中文句子,因此首先需要对投诉工单的内容进行预处理,对投诉工单进行分词和关键词提取,关键词的提取方法为TF-IDF算法;
TF-IDF是一种统计方法,用于评估文档对语料库的重要性。
TF-IDF计算公式如下:
其中,
其中,D表示工单总数,
每个关键词的TF-IDF值为:
TF - IDF=TF×IDF
以一个数据集为例,数据集如表1所示。
表1
在表1中,OID表示投诉工单ID,Keyword Set为用TF-IDF算法从工单中提取出来的关键词集合。
(1.2)构造关键词FpTree;
本发明将FPGrowth算法应用于自然语言处理领域,挖掘当日的热点事件。FPGrowth算法引入了数据结构存储数据,主要包括项头表、FPTree和节点链表;可以减少I/O操作,提高效率。
FpTree是一种树结构,树结构定义如下:
FpTree节点数据结构
FpNode {
idName;// id号
List
FpNode parent;// 父结点
FpNode next;// 下一个id号相同的结点
count;// 出现次数
}
如图2所示,构造关键词FpTree,包括步骤:
Step 1:假设最小绝对支持度是3,扫描数据记录,生成关键词一级频繁项集,并按出现次数由多到少排序,如表2所示:
表2
可以看到,
Step 2:再次扫描数据记录,对每条记录中出现在Step 1产生的表中的项,按表中的顺序排序。初始时,新建一个根结点,标记为null;
1)第一条记录{
2)第二条记录{
3)第三条记录{
4)第四条记录{
5)第五条记录{
6)按照上面的步骤,我们已经基本构造了一棵FpTree(Frequent Pattern Tree),树中每个路径代表一个项集,因为许多项集有公共项,而且出现次数越多的项越可能是公共项,因此按出现次数由多到少的顺序可以节省空间,实现压缩存储,另外我们需要一个表头和对每一个idName相同的结点做一个线索,如图2的子图f所示。
(1.3)基于关键词FPTree,挖掘关键词频繁项集;
FPTree的挖掘过程如下,从长度为1的频繁模式开始挖掘,可以分为3个步骤:
1)构造条件模式基(CPB,Conditional Pattern Base),条件模式基CPB就是要挖掘的项集的前缀路径;
2)然后构造它的条件FPTree(Conditional FP-tree);
3)递归的在条件FPTree上进行挖掘。
关键词频繁项集挖掘算法:
procedure FP_growth(Tree, α){
if Tree 含单个路径P {
for 路径 P 中结点的每个组合(记作β){
产生模式β ∪ α,其支持度support = β中结点的最小支持度
}
}
else {
for each ai 在 Tree 的头部 {
产生一个模式β = ai ∪ α,其支持度support = ai.support
构造β的条件模式基,然后构造β的条件FP Tree Treeβ
if Treeβ ≠ ∅ then
调用FP_growth (Treeβ, β)
}
}
(2)对热点事件进行精简分类;
基于已挖掘的关键词频繁项集,由于一些关键词频繁项集代表一类热点问题,比如:
{
{
都属于关键词频繁项集,但是其相似度较高,都表示一类热点问题,因此我们需要对热点事件进行分类。
用于评价词向量相似度最常用的方法为余弦相似度,这种方法适合本发明的关键词频繁项集之间的相似度计算。词向量的余弦相似度计算公式如下:
计算一对关键词频繁项集之间的相似度步骤如下:先将关键词频繁项集对处理成One-Hot编码。One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候只有一位有效。One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。对One-Hot编码的关键词频繁项集进行余弦相似度计算。
以关键词频繁项集
余弦值接近1,表明两个向量越相似,余弦值接近于0,表明两个向量越不相似,可见关键词频繁项集
基于余弦相似度的热点事件分类,由于每天的投诉热点事件挖掘事先是不清楚当日会出现几个热点事件,因此,本发明设计一种更为简单有效的关键词频繁项集处理方法,具体包括步骤:
(2.1)设置多个热点分类标志,每个热点分类标志包括若干关键词;
(2.2)计算热点分类标志的所有关键词,与关键词频繁项集之间的余弦相似度;
(2.3)找到热点分类标志中与关键词频繁项集余弦相似度最大的热点分类标志,并为关键词频繁项集打上热点分类标志。
算法的伪代码如下所示:
关键词频繁项集分类算法:
输入:关键词频繁项集keywordset
输出:带分类标签的关键词频繁项集
hotlist为热点分类标志的列表
hotlist.add(keywordset (1))
keywordset (keywordset (1))
Foreach item in keywordset
If hotlist中所有的关键词频繁项集与item的余弦相似度都小于阈值∂
hotlist.add(item)
else
找到hotlist中与item余弦相似度最大的热点下标,并为item打上下标标签。
(3)采用可以匹配多关键词的Hash索引法检索出含有热点事件关键词的工单;
文本对舆情热点事件的挖掘主要是基于关键词频繁项集,对于具体的工单内容需要按多关键词进行匹配检索。
对于常规的关系型数据库,在海量数据中检索到关键词需要耗费大量的时间,由于索引技术的出现,对文本数据增加全文索引可以大大提高检索效率。
在本发明中我们采用的是多关键词检索,借鉴hash设计思路,将市长热线投诉工单文本数据库预处理成关键词与工单号对应的hash表,再利用工单唯一主键对工单进行检索,这样可以大大的提高检索效率。
哈希表也为散列表,又直接寻址改进而来。在哈希的方式下,一个元素
存储结构采取三元组的形式,其分别为哈希函数值、工单的id号集合和解决冲突所用的指针。
举个例子,对于关键词频繁项集{
{
(4)采用改进的TextRank算法对检索出来的工单进行摘要提取,将工单中最关键的信息反馈出来;
在检索到热点事件工单之后,对工单内容实现自动摘要提取,可以有效的帮助把握热点事件的重点方向并实现智能决策。
自动摘要抽取为自然语言处理领域的重要分支,目前较为主流是基于图模型的文本自动摘要,最具代表性的为TextRank 算法。
TextRank算法思想为对于每个句子都给出一个正实数,表示句子的重要程度,TextRank值越高,表示句子越重要,在自动摘要提取排序中越可能被排在前面。
假设一段包含若干句子的文本是一个有向图,节点是句子,每条边是转移概率,转移概率则为2个句子之间的相似度,句子以转移概率跳转到下一个句子,并且在句子间持续不断地进行这样的随机跳转,这个过程形成了一阶马尔科夫链。在不断地跳转之后,这个马尔科夫链会形成一个平稳分布,而TextRank就是这个平稳分布,每个句子的TextRank值就是平稳概率。
TextRank的计算公式如下:
其中,
在TextRank算法中最核心的部分为图中边权重的相似度计算,处理句子相似度的方法为先将句子转化为机器可以理解的句子向量再进行句子的相似度计算。考虑到原始TextRank算法在图模型构建中对于边权重相似度计算方法和节点初始权重赋值处理的不够理想,我们首先采用TF-IDF得分作为节点的初始权重值并采用BERT模型的embedding层,如图4,将句子处理为数值型的768维度的句子向量,再采用余弦相似度计算句子之间的相似度作为边权重,最后进行TextRank的迭代,算法步骤如图5所示。具体包括步骤:
(4.1)将工单内容处理为一个包含若干句子的文本;将句子转化为机器可以理解的句子向量;
(4.2)进行句子向量之间的余弦相似度计算,得到相似度矩阵,作为边权重;采用TF-IDF得分作为初始权重值;
(4.3)进行TextRank的迭代,计算每个句子的TextRank值,得到句子排名;根据句子排名抽取自动摘要。
(5)热线工作人员及时了解每天的舆情热点事件,给相关部门进行汇报;
工单数据采用MySql存储,决策支持系统主要利用工单的标题和投诉内容,将数据输入模型中心,分析得出热点事件,将热点事件存入数据库中,从报告中心可以用自助的形式拖拽热点形成日报、周报和月报,工作人员可以根据热点关键词检索出来的摘要信息自定义的生成报告模板并推送给相关的职能部门,职能部门得到报告后针对舆情反应的问题进行整改或者跟踪调研。
如图6所示,本发明所述的基于自然语言处理的市长热线舆情决策支持系统,包括6个层面:基础层、数据层、支撑层、应用层、服务层和用户层。
基础层为项目实施的硬件设置如机房和网络环境。
数据层分为基础库和智能库,基础库为一次数据包含原始的工单文本信息,地理位置信息等;智能库则为二次数据,是处理过的数据库例如热线词典库、统计词库等。
支撑层则为算法和应用服务,本发明所用的算法有FP-Growth、热点问题分类、信息检索和自动摘要提取。
应用层为具体的应用服务包括智慧舆情监督、智慧民生感知和智慧决策支持。
服务层分为2个端:web端和移动端。
用户层为领导,业务人员和运维人员。
本发明采用自然语言处理技术为市长热线开发一套舆情决策支持系统,系统可以通过机器学习算法自动挖掘每日舆情热点,并设置阈值进行舆情报警,指导工作人员即使做出决策支持。采用摘要自动抽取方法帮助工作人员从大量相关工单中把握最核心,最重要的问题,方便撰写舆情日报、周报和月报并自助推送给有关部门。
本决策支持系统可以把工作人员从海量投诉工单中寻找群体性事件的时间由原先的2天到现在的实时展示,系统极大的提高了工作人员的办事效率,提升了公众问题的处理速度。在本系统部署后,市长热线工作人员可以实时监控舆情信息,极大的提高工作人员的办事效率,并通过本系统及时发现小区管理混乱,微信平台诈骗、商场活动扰民等一系列民生问题并采取了积极的应对措施。
- 基于自然语言处理的市长热线舆情决策支持方法及系统
- 一种基于自然语言处理的舆情风险监测方法及系统