电子装置及其控制方法
文献发布时间:2023-06-19 11:11:32
技术领域
符合本公开的装备和方法涉及电子装置及其控制方法,更具体地,涉及以下的电子装置及其控制方法,其可以控制语音识别工作在其他电子装置中连续执行,以及通过组合在每个单独的电子装置中执行的语音识别信息来获得最终的语音识别结果。
背景技术
近年来,人工智能系统被用于各个领域。与现有的基于规则的智能系统不同,人工智能系统是机器执行学习并基于学习做出决定的系统。随着人工智能系统的使用越来越频繁,可能会更准确地理解对用户需求的识别,因此,现有的基于规则的智能系统逐渐被基于深度学习的人工智能系统所取代。
人工智能技术可以包括机器学习,例如深度学习,以及使用机器学习的应用。
机器学习是通过机器对输入数据的特征进行分类和学习的算法,而原理技术(element technology)是通过利用诸如深度学习等的机器学习算法模仿人脑的诸如认知、判断等功能的技术。机器学习可应用于技术领域,诸如语言理解、视觉理解、推理/预测、知识表示、运动控制等。
语言理解是用于识别、应用和处理人类的语言/字符的技术,并且包括自然语言处理、机器翻译、对话系统、询问响应、语音识别/合成等。视觉理解是将对象标识和处理为人类视觉的技术,并且包括对象识别、对象跟踪、图像搜索、人类识别、场景理解、空间理解、图像增强等。推理和预测是一种对信息进行判断及逻辑地推理和预测的技术,并且包括基于知识/概率的推理、优化预测、基于偏好的规划、推荐等。知识表示是将人类经验信息自动处理为知识数据的技术,并且包括知识构建(例如,数据生成/分类)、知识管理(例如,数据利用)等。运动控制是用于控制车辆的自主运行和机器人的运动的技术,并且包括运动控制(例如,导航、碰撞、运行)、和操作控制(例如,行为控制)等。
另一方面,最近提供了使用配备有人工智能代理(例如Bixby
公开内容
技术问题
本公开的实施例克服了上述缺点和上文未描述的其他缺点。
本公开提供电子装置及其控制方法,该电子装置及其控制方法可以控制语音识别工作在其他电子装置中连续执行,以及通过组合在每个单独的电子装置中执行的语音识别信息来获得最终的语音识别结果。
技术方案
根据实施例,提供了电子装置,包括用于接收音频的麦克风、通信器、被配置为存储计算机可执行指令的存储器以及被配置为执行计算机可执行指令的处理器。处理器被配置为确定所接收的音频是否包括预先确定的触发字;基于确定预先确定的触发字被包括在所接收的音频中,激活电子装置的语音识别功能;在语音识别功能被激活时检测用户的移动;以及基于检测用户的移动,向第二电子装置发送控制信号,以激活第二电子装置的语音识别功能。
处理器进一步被配置为在激活语音识别功能之后基于通过麦克风获得的所接收的音频来检测用户的移动。
存储器存储关于接收音频的多个电子装置的信息,并且处理器进一步被配置为基于用户的移动来标识多个电子装置中最接近用户的一个;并且控制通信器将控制信号发送到所标识的电子装置。
处理器进一步被配置为通过对所接收的音频执行语音识别来获得第一语音识别信息;通过通信器从接收控制信号的第二电子装置接收第二语音识别信息;以及基于第一语音识别信息和第二语音识别信息获得最终的识别结果。
处理器进一步被配置为获得关于控制信号被发送到第二电子装置的时间的时间信息,并基于所获得的时间信息,将第一语音识别信息与第二语音识别信息进行匹配,获得最终的识别结果。
时间信息包括关于发送控制信号的绝对时间的信息以及基于激活电子装置的语音识别功能的时间的关于将控制信号发送到第二电子装置的相对时间的信息。
处理器进一步被配置为当从第二电子装置接收的第二语音识别信息是指示应用声学模型而不应用语言模型的信息时,通过将语言模型应用于第二语音识别信息来获得最终的识别结果;以及当从第二电子装置接收的第二语音识别信息是指示不应用声学模型和语言模型的信息时,通过将声学模型和语言模型应用于第二语音识别信息来获得最终的识别结果。
处理器进一步被配置为控制通信器向第二电子装置发送控制信号,以提供关于电子装置的最终的识别结果的反馈。
处理器进一步被配置为当从第二电子装置接收到用于激活语音识别功能的第二控制信号时,激活电子装置的语音识别功能。
处理器进一步被配置为从第二电子装置接收用户信息,并且在语音识别功能被第二控制信号激活之后,在通过麦克风接收的多个音频中标识与用户信息相对应的所接收的音频。
处理器进一步被配置为在语音识别功能被第二控制信号激活之后,通过对所接收的音频执行语音识别直到用户的话语结束,来获得语音识别信息,并且将所获得的语音识别信息发送到第二电子装置。
处理器进一步被配置为基于在多个音频中所接收的音频来标识第一用户和第二用户。
根据另一个实施例,提供了用于控制电子装置的方法。所述方法可以包括通过电子装置的麦克风接收音频;确定所接收的音频是否包括预先确定的触发字;基于确定所接收的音频中包括预先确定的触发字,激活电子装置的语音识别功能;检测到用户移动的移动,激活语音识别功能;并且基于检测用户的移动,向第二电子装置发送控制信号,以激活第二电子装置的语音识别功能。
检测用户的移动是基于在语音识别功能被激活之后通过麦克风获得的所接收的音频。
电子装置存储关于接收音频的多个电子装置的信息,并且该方法还可以包括基于用户的移动,标识多个电子装置中最接近用户的一个,并将控制信号发送到所标识的电子装置。
该方法还可以包括通过对所接收的音频执行语音识别来获得第一语音识别信息;通过通信器从接收控制信号的第二电子装置接收第二语音识别信息;以及基于第一语音识别信息和第二语音识别信息来获得最终的识别结果。
该方法还可以包括获得关于控制信号被发送到第二电子装置的时间的时间信息,并基于所获得的时间信息,将第一语音识别信息与第二语音识别信息进行匹配以获得最终的识别结果。
时间信息可以包括关于发送控制信号的绝对时间的信息和基于激活电子装置的语音识别功能的时间的关于将控制信号发送到第二电子装置的相对时间的信息。
获得最终的识别结果还包括当从第二电子装置接收的第二语音识别信息是指示应用声学模型而不应用语言模型的信息时,将语言模型应用于第二语音识别信息,以及当从第二电子装置接收的第二语音识别信息是指示不应用声学模型和语言模型的信息时,将声学模型和语言模型应用于第二语音识别信息。
根据另一个实施例,提供了电子装置,包括通信器;被配置为包括至少一条指令的存储器;以及被配置为执行至少一条指令的处理器。处理器被配置为通过通信器从第一外部装置接收用户语音的第一音频信号;控制通信器以向第二外部装置发送控制信号,用于当基于所接收的第一音频信号中包括的信息检测到用户的移动时,从位于用户移动方向的第二外部装置接收用户语音的第二音频信号;通过通信器从第二外部装置接收第二音频信号;并且匹配所接收的第一音频信号和所接收的第二音频信号以对用户语音执行语音识别。
处理器进一步被配置为对准所接收的第一音频信号和所接收的第二音频信号,使得接收到第一音频信号的时间和接收到第二音频信号的时间彼此对应,以及通过比较对准的第一音频信号和对准的第二音频信号来匹配所接收的第一音频信号和所接收的第二音频信号。
处理器进一步被配置为基于接收到第二音频信号的时间来匹配所接收的第一音频信号和所接收的第二音频信号。
处理器进一步被配置为基于所接收的第一音频信号的功率和所接收的第一音频信号的信噪比(signal-to-noise ratio,SNR)中的至少一个来标识所接收的第一音频信号的第一质量和所接收的第二音频信号的第二质量,以及基于所标识的第一音频信号的第一质量和所标识的第二音频信号的第二质量来匹配所接收的第一音频信号和所接收的第二音频信号。
处理器进一步还被配置为通过将所接收的第一音频信号和所接收的第二音频信号输入到学习人工智能模型来获得关于所接收的第一音频信号的语音识别结果的第一概率信息和关于所接收的第二音频信号的语音识别结果的第二概率信息,并基于所获得的第一概率信息和所获得的第二概率信息来匹配所接收的第一音频信号和所接收的第二音频信号。
处理器进一步被配置为基于所接收的第一音频信号的功率和所接收的第一音频信号的信噪比中的至少一个来检测用户的移动。
根据另一个实施例,提供了用于控制电子装置的方法。该方法可以包括通过通信器从第一外部设备接收用户语音的第一音频信号;向第二外部装置发送控制信号,用于当基于所接收的第一音频信号中包括的信息检测到用户的移动时,从位于用户移动方向的第二外部装置接收用户语音的第二音频信号;通过通信器从第二外部装置接收第二音频信号;以及匹配所接收的第一音频信号和所接收的第二音频信号,以对所述用户语音执行语音识别。
该方法还可以包括对准所接收的第一音频信号和所接收的第二音频信号,使得接收到第一音频信号的时间和接收到第二音频信号的时间彼此对应,并且在执行语音识别时,通过比较对准的第一音频信号和对准的第二音频信号来匹配所接收的第一音频信号和所接收的第二音频信号。
语音识别的执行还可以包括基于由第一外部设备接收的第二音频信号的时间匹配的所接收的第一音频信号和所接收的第二音频信号。
语音识别的执行还可以包括基于所接收的第一音频信号的功率和所接收的第一音频信号的信噪比(SNR)中的至少一个来标识所接收的第一音频信号的第一质量和所接收的第二音频信号的第二质量;以及基于所标识的第一音频信号的第一质量和所标识的第二音频信号的第二质量来匹配所接收的第一音频信号和所接收的第二音频信号。
语音识别的执行还可以包括通过将所接收的第一音频信号和所接收的第二音频信号输入到学习人工智能模型,来获得关于所接收的第一音频信号的语音识别结果的第一概率信息和关于所接收的第二音频信号的语音识别结果的第二概率信息;以及基于所获得的第一概率信息和所获得的第二概率信息来匹配所接收的第一音频信号和所接收的第二音频信号。
基于所接收的第一音频信号的功率和所接收的第一音频信号的信噪比中的至少一个来检测用户的移动。
附图说明
通过以下参考附图的描述,本公开的上述方面和其他方面将更加明显,附图中:
图1是示出通过多个电子装置执行语音识别的实施例的图;
图2至图5B是示出根据各种实施例的语音识别系统的框图;
图6至图9是示出在语音识别系统中执行语音识别的各种实施例的流程图;
图10是示出根据实施例的电子装置的配置的框图;
图11是示出根据实施例的集线器装置的配置的框图;
图12是示出根据实施例的服务器的配置的框图;
图13是示出根据实施例的语音识别模块的框图;
图14是示出根据实施例的人工智能代理系统的对话系统的框图;
图15至图17是示出与语音识别系统中的声学模型和语言模型的使用相关的各种实施例的图;
图18是示出根据实施例的用于在电子装置上生成位置信息的方法的示例的图;
图19是示出根据实施例的包括多个麦克风的电子装置的图;
图20是示出根据实施例的用于通过电子装置使用相机感测用户的移动方向的方法的图;
图21至图25是示出其中电子装置匹配语音识别信息的各种实施例的图;
图26是示出在多个用户发声的情况下通过多个电子装置执行语音识别实施例的图;
图27是示出与多回合方案的响应提供有关的实施例的图;
图28和29是示出根据各种实施例发生语音识别的切换的情况的图;
图30是示出根据本公开实施例的用于控制电子装置的方法的流程图。
图31是示出根据实施例的基于用户的移动来匹配从多个音频信号收集装置接收的音频信号的过程的图;
图32是示出根据实施例的用于通过边缘计算装置从多个音频信号收集装置接收的音频信号中识别触发字的方法的图;
图33是示出在根据实施例的语音识别模块中将音频信号转换为字串的过程的示例的图;
图34至图37是示出根据各种实施例的边缘计算装置中的匹配方法的图。
具体实施方式
本文将描述本公开的各种实施例。然而,可以理解,本公开的实施例不限于特定实施例,而是可以包括其所有修改、等同和/或替代物。
在本公开中,诸如“有”、“可以有”、“包括”、“可以包括”等表述可以表示对应特征的存在,例如,数值、功能、操作、诸如部件的组件等,并且不排除附加特征的存在。
在本公开中,诸如“A或B”、“A和/或B中的至少一个”、“A和/或B中的一个或多个”等表述可以包括一起列出的项目的所有可能组合。例如,“A或B”、“A和B中的至少一个”或“A或B中的至少一个”可以表示(1)包括至少一个A的情况,(2)包括至少一个B的情况,或(3)包括至少一个A和至少一个B的情况。
本公开中使用的表述“第一”、“第二”等可以表示各种组件,而不考虑组件的顺序和/或重要性,并且可以仅用于区分一个组件和其他组件,并且不限制对应的组件。例如,第一用户装置和第二用户装置可以指示不同的用户装置,而不管其顺序或重要性如何。例如,在不脱离本公开的范围的情况下,本公开中描述的第一组件可以被命名为第二组件,并且第二组件也可以类似地被命名为第一组件。
在本公开中使用的术语,诸如“模块”、“单元”、“部件”等,可以是指执行至少一个功能或操作的组件的术语,并且这样的组件可以硬件或软件实现,或者可以以硬件和软件的组合实现。此外,多个“模块”、“单元”、“部件”等可以集成到至少一个模块或芯片中,并且可以在至少一个处理器中实现,除非它们需要在单独特定硬件中实现。
当提到任何组件(例如,第一组件)与另一组件(例如,第二组件)在操作上或通信上耦合或连接到另一组件(例如,第二组件)时,可以理解,任何组件直接与另一组件耦合或可以通过另一组件(例如,第三组件)与另一组件耦合。另一方面,当提及任何组件(例如,第一组件)与另一组件(例如,第二组件)“直接耦合”或“直接连接”时,可以理解,在任何组件和另一组件之间不存在第三组件。
根据具体情况,本公开中使用的“配置(或设置)为”的表述可以替换为表述“适合”、“有能力”、“设计为”、“适合”、“制造为”或“能够”。术语“配置(或设置)为”在硬件中不一定仅指“具体设计为”。替代地,表述“装备被配置为”可意味着该装备“能够”与其它装备或组件一起。例如,“处理器被配置(或设置)为执行A、B和C”可指用于执行对应操作的专用处理器(例如,嵌入式处理器)或通用处理器(例如,中央处理单元(CPU)或应用处理器),其可通过执行存储在存储器装置中的一个或多个软件程序来执行对应的操作。
本公开中使用的术语可仅用于描述特定实施例,而不是限制其他实施例的范围。单数形式可以包括复数形式,除非上下文另有明确说明。本公开中使用包括技术术语和科学术语的术语可以具有与本公开所属领域的技术人员通常理解的术语相同的含义。在本公开中使用的术语中的通用词典中定义的术语可以被解释为与相关技术的上下文中的含义相同或相似的含义,并且除非在本公开中明确定义,否则不被解释为理想的或过于正式的含义。在一些情况下,术语可能不会被解释为排除本公开的实施例,即使它们是在本公开中定义的。
在下文中,将参考附图更详细地描述本公开。然而,在描述本公开时,当确定与本公开有关的已知功能或配置的详细描述可能不必要地模糊本公开的要点时,将省略其详细描述。在附图中,相同的组件将由相同的附图标记表示。
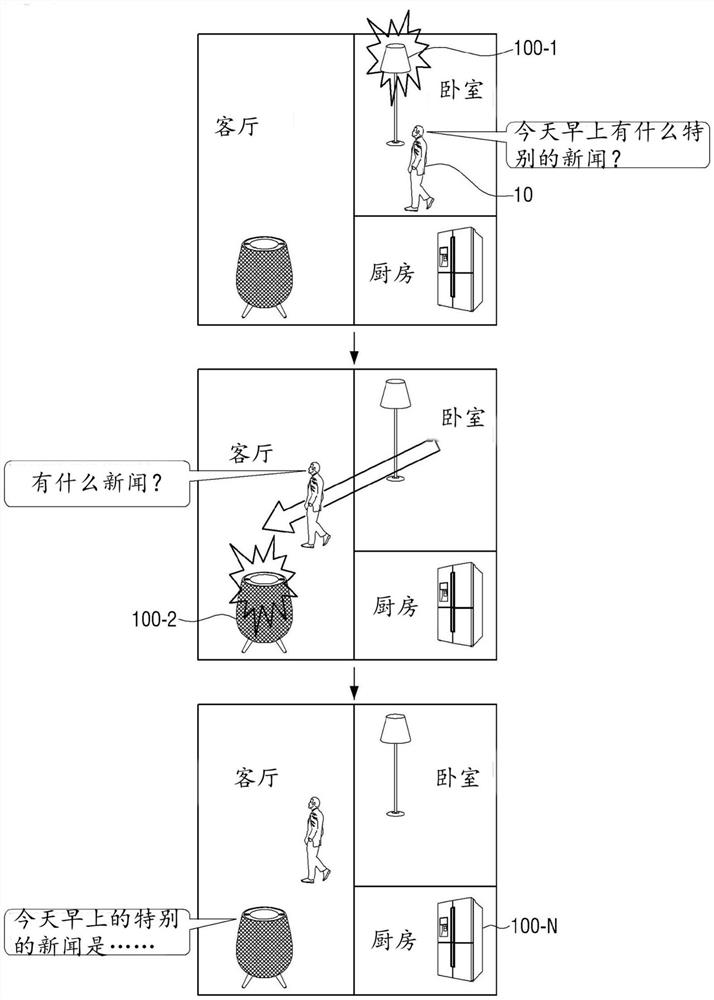
图1是示出通过多个电子装置执行语音识别实施例的图。
参考图1,可以在家庭中提供多个电子装置100-1、100-2和100-N(所有这些装置都可以被称为电子装置100)。电子装置100可以包括麦克风或者电连接到麦克风,并且通过麦克风获得用户10的语音。
在电子装置100中,语音识别功能可在语音识别待机状态下由包括触发字或唤醒字的用户语音来激活。可以通过按下电子装置100中提供的特定按钮以及通过用户所说的触发字来激活语音识别功能。
这里,语音识别待机状态是激活麦克风并识别触发字的模式。在语音识别待机状态下,可以不执行除触发字以外的识别。因此,语音识别待机状态是以较少的操作执行语音识别状态。语音识别待机状态也可以称为语音识别待机模式。
根据实施例,当在语音识别待机状态期间识别触发字时,可以激活电子装置100的语音识别功能。当激活语音识别功能时,可以对通过麦克风输入的语音执行语音识别。
可以执行一系列过程来识别语音。例如,可以包括:记录语音以获得音频信号的过程、从音频信号获得特征信息的过程、基于所获得的特征信息和声学模型获得发音信息、音素(phoneme)或字符串信息的过程,以及基于关于所获得的发音信息、音素或字符串信息的语言模型来获得文本数据的过程。具体地,电子装置可以通过对音频信号应用特征提取技术从输入语音数据中获得特征信息。在实施例中,电子装置可以通过对音频信号使用包括倒谱(Cepstrum)、线性预测系数(Linear Predictive Coefficient,LPC)、梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)和滤波器组能量(Filter Bank Energy)的特征提取技术中的任何一个来提取输入音频信号的特征。上述特征获得技术仅仅是一个示例,本公开中使用的特征获得技术不限于上述示例。
根据实施例,电子装置100可以执行一系列用于语音识别的过程中的所有过程。根据另一个实施例,电子装置100可以通过仅执行一系列用于语音识别的过程中的一些过程来获得中间结果,并且将中间结果发送到外部装置,使得剩余的过程可以由外部装置执行。例如,电子装置100可以将仅通过执行语音记录而获得的音频信号发送到外部装置,使得外部装置可以执行剩余的语音识别过程。具体地,电子装置100可以仅执行基于声学模型的获得发音信息、音素信息或字符串信息的过程,并且将发音信息、音素信息或字符串信息发送到外部,使得基于语言模型获得文本数据的过程可以由外部装置执行。
这里,电子装置100可以执行对一系列用于语音识别的过程中的一些过程的语音识别,以获得中间结果,并且将中间结果发送给外部装置。电子装置100还可以执行一系列用于语音识别的过程中的所有过程。另外,作为由电子装置100执行的语音识别的结果而获得的语音识别信息可以是指通过执行一系列用于语音识别的过程中的所有过程而获得的最终结果(例如,文本数据)、或者仅通过执行语音识别一系列过程中的某些过程而获得的中间结果(例如,音频信号、特征信息、发音信息、音素信息、字符串信息等)。
另一方面,触发字可以是预先确定的字或句子。例如,可以使用“Hi Bixby”等。例如,当用户说“Hi Bixby,今天天气怎么样?”,电子装置100可通过在语音识别待机状态下识别“Hi-Bixby”来激活语音识别功能,并且对“今天天气怎么样?”执行语音识别。
根据实施例,在语音识别可以在其他电子装置中更好地执行的情况下,电子装置100可以将语音识别工作移交给其他电子装置。语音识别工作的移交是指控制与先前已经执行语音识别的电子装置不同的电子装置来继续地执行语音识别。例如,语音识别工作的移交可以包括将激活语音识别功能的控制信号发送到其他电子装置。另外,语音识别工作的移交可以包括通过电子装置将其自身的标识信息(例如,装置ID)和与输入语音相对应的用户信息发送到其他电子装置。其他电子装置可以基于所发送的用户信息来标识用户的语音,并且可以继续地执行语音识别。或者,可以在其他电子装置中预先注册用户信息,使得可以相互比较预先注册的用户信息和从该电子装置接收的用户信息。作为其他备选方案,在用户未预先注册的情况下,可以将接收的用户信息和从当前输入语音中获得的用户信息相互比较。
参考图1,当卧室中的第一电子装置100-1在语音识别待机状态下从用户接收到包括触发字(例如,“Hi Bixby”)的语音时,第一电子装置100-1可以激活语音识别功能。在用户说出触发字之后,用户然后可以在从卧室移动到客厅时发出“今天早上有什么特别的新闻?”。卧室中的第一电子装置100-1可以感测用户的移动。例如,当用户从卧室移动到客厅并且与输入到第一电子装置100-1的语音相对应的音频信号强度逐渐降低时,第一电子装置100-1可以感测用户的移动。
因此,在客厅中的第二电子装置100-2可以更好地执行语音识别情况下,第一电子装置100-1可以将语音识别工作移交给客厅中的第二电子装置100-2。具体地,当与输入到第一电子装置100-1的语音相对应的音频信号强度降低时,第一电子装置100-1可以感测用户正在移动并广播用于搜索在用户的移动方向上的第二电子装置的信息。另外,第二电子装置可以感测与用户的语音相对应的音频,并将关于相应信号的信息发送给第一电子装置。在这种情况下,第一电子装置100-1可以向第二电子装置100-2发送用于激活语音识别功能的控制信号。因此,第二电子装置100-2可以在语音识别待机状态下激活语音识别功能并识别用户的语音。这仅仅是一个示例,并且除了通过麦克风获得的音频之外,还可以通过使用诸如相机的各种传感器获得的信息来感测用户的移动,以标识在移动方向上的其他电子装置。将参考图18至20更详细地描述用于通过电子装置100在用户的移动方向上标识其他电子装置的方法。
分别由第一电子装置100-1和第二电子装置100-2获得的语音识别信息可以进行比较和匹配以识别整个句子。例如,当用户说出“今天早上有什么特别的新闻?”,并且对应的响应或反馈可以被提供给第一电子装置100-1或第二电子装置100-2。优选的是,从靠近用户的最后位置的第二电子装置100-2提供响应。也就是说,可以通过第二电子装置100-2的扬声器提供对应的响应,诸如“今天早上的特别的新闻是……”。
当语音识别信息被发送到其他电子装置时,电子装置100可以发送用于匹配语音识别信息的附加信息。附加信息可以包括时间信息、关于记录特征的信息和关于语音识别进展情况的信息中的至少一个。
这里,时间信息可以包括语音输入到电子装置的时间。时间信息可以是关于绝对时间或相对时间的信息。执行最终匹配的装置可以基于时间信息按时间顺序匹配语音识别信息。
关于记录特性的信息可以是关于执行记录的装置的麦克风特性和周围环境(环境噪声等)的信息。执行最终匹配的装置可以基于关于记录特性的信息执行适当的噪声处理或应用适当的声学模型或语言模型。
关于语音识别进展情况的信息可以是关于正在执行的语音识别的一系列过程的信息。例如,关于语音识别进展情况的信息可以包括关于发送的音频信号的信息、从音频信号提取的特征信息(特征向量)、通过基于特征信息应用声学模型或语言模型发送的特征信息,通过应用所发送的声学模型或语言模型获得的文本数据,等等。
如上所述,最初开始语音识别的电子装置可以通过主动选择其他电子装置来辅助自身来移交语音识别工作,并且可以匹配从每个电子装置获得的语音来执行整个识别。也就是说,可以通过多个电子装置无缝地执行语音识别。
电子装置100可以实现为例如,智能手机、平板个人计算机(PC)、移动电话、图像电话、人工智能扬声器、扬声器(包括至少一个未配备有人工智能功能的麦克风的扬声器)、电子书阅读器、台式个人计算机(PC),膝上型个人计算机(PC)、上网本计算机、工作站、服务器、个人数字助理(PDA)、便携式多媒体播放器(PMP)、MP3播放器、移动医疗装置、相机或可穿戴装置。可穿戴装置可以包括附件型可穿戴装置(例如手表、戒指、手镯、脚镯、项链、眼镜、隐形眼镜或头戴式装置(HMD))、纺织品或服装整体型可穿戴装置(例如,电子服装)、身体附着型可穿戴装置(例如,皮肤垫或纹身),或活体植入型可穿戴装置(例如,可植入电路)。
在一些实施例中,电子装置100可以是家用电器。家用电器可包括例如电视、数字视频盘(DVD)播放器、音频、冰箱、空调、清洁器、烤箱、微波炉、洗衣机、空气清洁器、机器人吸尘器、机顶盒、家庭自动化控制面板、门锁、安全控制面板,电视(TV)盒(例如,三星电子有限公司的HomeSync
电子装置100可以是上述各种装置中的一个或多个的组合。此外,电子装置100不限于上述装置,而是可以包括根据技术发展的新电子装置。
多个电子装置100中的至少一些电子装置可以是相同的类型,或者各个电子装置100可以是彼此不同的类型。
如上所述,可以在根据各种实施例的语音识别系统中实现移交语音识别工作的功能和匹配从多个电子装置100获得的语音的功能。语音识别系统可以包括电子装置100,并且还可以包括可以连接到电子装置100的集线器装置、服务器等。
下文中,将参考图2至图5A描述根据各种实施例的语音识别系统。
参照图2,语音识别系统1000可以包括电子装置100-1至100-N(所有这些都可以被称为电子装置100)。
电子装置100可以以无线或有线通信方式与外部装置通信。例如,电子装置100可以连接到无线接入点,诸如无线路由器,以通过无线接入点与外部装置通信。或者,电子装置100可以通过短距离无线通信方式(诸如,Wi-Fi直连(Wi-Fi Direct)、蓝牙、紫蜂(ZigBee)、Z-Wave等)与外部装置通信。
当特定事件第一次激活第一电子装置100-1并且在激活语音识别功能的同时需要在其他电子装置上继续地执行语音识别时,第一电子装置100-1可以向第二电子装置100-2发送相关信息以继续地执行语音识别。例如,特定事件可以包括用户移动的事件、电子装置100-1周围的噪声发生超过预先确定的程度的事件、预期电子装置100-1的电源很快被关闭的事件等。基于特定事件,第一电子装置100-1可以确定要接管语音识别工作的其他电子装置。例如,接管语音识别工作的电子装置100-2可以被确定为预先注册的电子装置(例如,用户始终携带的移动装置)或在用户移动的方向上的电子装置。下文将更详细地描述接手语音识别工作的其他电子装置的确定。
当第二电子装置100-2被确定为接管语音识别工作的装置时,第一电子装置100-1可以将语音识别工作移交给第二电子装置100-2。在这种情况下,第一电子装置100-1可以向第二电子装置100-2发送用于激活语音识别功能的控制信号。
从第一电子装置100-1接收控制信号的第二电子装置100-2可以激活语音识别功能。另外,当用户再次移动到除第一电子装置100-1和第二电子装置100-2以外的其他电子装置时,第二电子装置100-2可以以与第一电子装置100-1相同的方式将语音识别工作移交给其他电子装置。
或者,当第二电子装置100-2感测到用户的话语结束时,第二电子装置100-2可以对从在激活语音识别功能时的时间到用户的话语结束所获得的用户话语来执行语音识别,并且向第一电子装置100-1发送语音识别信息作为执行语音识别的结果。
第一电子装置100-1可以对语音标识信息进行匹配,该语音识别信息是按时间顺序对由第一电子装置100-1获得的用户语音和从第二电子设备100-2接收的语音识别信息执行语音识别的结果,以及基于通过匹配过程最终获得的语音识别结果来生成对应的响应。例如,当通过第一电子装置100-1和第二电子装置100-2获得的用户的整个话语是“今天天气怎么样?”,第一电子装置100-1可以向第二电子装置100-2发送控制信号,该控制信号使得第二电子装置100-2输出语音响应,诸如“今天下午可能会有雨。”
或者,尽管在上面的示例中描述了第一次激活语音识别功能的第一电子装置100-1执行匹配,但是最终匹配可以在电子装置100-1到100-N中的任何一个中执行。根据实施例,电子装置100-1到100-N之中要执行匹配的电子装置可以在用户话语开始之前预先确定。例如,当电子装置100-1到100-N中的一个感测到用户话语的结束时,可以预先确定该电子装置来执行匹配。因此,感测用户话语结束的电子装置可以向先前的电子装置请求语音识别信息、用户信息、用于匹配的附加信息等。或者,第一电子装置100-1可以从当第一电子装置100-1将语音识别工作移交给第二电子装置100-2时起,将语音声音识别信息、用户信息、用于匹配的附加信息等一起发送。另外,当第一电子装置100-1执行匹配然后执行语音识别工作,但是用于语音识别的得分低时,第二电子装置100-2可以再次执行语音识别工作。这里,将参照图22进一步描述得分的确定。在这种情况下,还可以由第二电子装置100-2再次执行一系列用于语音识别的过程中的所有过程。或者,也可以仅再次执行一系列用于语音识别的过程中的一些。具体地,通过向应用于声学模型的语音识别信息应用语言模型,可以再次执行一系列用于语音识别的过程中的一些。
图3是示出根据另一个实施例的语音识别系统的图。
语音识别系统2000可以包括电子装置100-1到100-N(所有这些装置都可以被称为电子装置100)和服务器300。
电子装置100可以通过至少一个网络与服务器300通信。至少一个网络可以包括以下许多不同类型的网络的任意一个或组合:诸如蜂窝网络、无线网络、局域网(LAN)、广域网(WAN)、个人区域网(PAN)、因特网等。电子装置100可以连接到诸如无线路由器的接入点。
电子装置100可以通过服务器300或通过使用装置到装置(device-to-device,D2D)或对等(peer-to-peer,P2P)连接彼此通信。
服务器300可以管理和控制电子装置100。服务器300可以实现为云服务器。服务器可以包括单个服务器,或者可以实现为多个云服务器。
服务器300可以执行移交语音识别工作的功能中的至少一个,例如,匹配语音识别信息的功能,或者执行如图2所述的任务的功能。这里,任务指的是响应用户的输入的任何输出的生成。也就是说,当由电子装置100执行语音识别时,可以执行任务以生成对应于用户的语音的输出。
根据实施例,语音识别功能可以第一次在第一电子装置100-1上被激活,并且第一电子装置100-1可以对在激活语音识别功能时获得的用户语音执行语音识别,并且将语音识别信息发送到服务器300。此后,当与在第一电子装置100-1上激活语音识别功能的同时需要在其他装置上继续地执行语音识别情况相关的特定事件时,第一电子装置100-1可以确定接管语音识别执行的电子装置。
当第二电子装置100-2被确定为接管语音识别执行的装置时,第一电子装置100-1可以将语音识别工作移交给第二电子装置100-2。在这种情况下,第一电子装置100-1可以向第二电子装置100-2发送用于激活语音识别功能的控制信号。
从第一电子装置100-1接收控制信号的第二电子装置100-2可以激活语音识别功能。第二电子装置100-2可以将关于由第二电子装置100-2获得的用户语音的识别信息发送到服务器300。另外,当用户再次移动到其他电子装置时,第二电子装置100-2可以以相同的方式将语音识别工作移交给其他电子装置。
当从最后输入用户语音的第n个电子装置100-N接收到语音识别信息时,服务器300可以按时间顺序对从电子装置100-1到100-N接收的语音识别信息执行匹配,并且基于通过匹配最终获得的语音识别结果来生成响应。例如,当通过电子装置100-1到100-N获得的用户的整个语音是“今天天气怎么样?”时,服务器300可以执行发送控制信号的任务,该控制信号使得第n电子装置100-N向第n电子装置100-N输出“今天下午可能会有雨”的语音响应。
图4是示出根据又一个实施例的语音识别系统3000的图。
语音识别系统3000可以包括电子装置100-1到100-N(所有这些装置都可以被称为电子装置100)和集线器装置200。集线器装置200可以被配置为一个集线器装置,或者可以被配置为多个集线器装置并且连接到每个电子装置。例如,当存在五个电子装置和两个集线器装置时,三个电子装置可以连接到第一集线器装置并且两个电子装置可以连接到第二集线器装置。另外,五个电子装置可以连接到第一集线器装置,两个电子装置可以连接到第二集线器装置。这样的连接可以根据用户设置的方法以各种连接方法来配置。
电子装置100和集线器装置200可以以无线或有线通信方式与外部装置通信。例如,电子装置100和集线器装置200可以连接到诸如无线路由器的无线接入点以通过无线接入点与外部装置通信。或者,电子装置100和集线器装置200可以通过短距离无线通信方式(诸如,Wi-Fi直连(Wi-Fi Direct)、蓝牙、紫蜂(ZigBee)、Z-Wave等)与外部装置通信。
语音识别系统3000中的通信可以集中在集线器装置200上。例如,电子装置100可以通过集线器装置200与外部装置通信。或者,电子装置100-1到100-N也可以在不经过集线器装置200的情况下与外部装置通信。
集线器装置200可以管理和控制电子装置100。集线器装置200可以是家庭网关。集线器装置200可以实现为各种类型的装置。
集线器装置200可以实现为例如智能手机、平板个人计算机(PC)、移动电话、图像电话、人工智能扬声器、电子书阅读器、台式个人计算机(PC)、膝上型个人计算机(PC)、上网本计算机、工作站、服务器、个人数字助理(PDA)、便携式多媒体播放器(PMP)、MP3播放器、移动医疗装置、相机或可穿戴装置。可穿戴装置可以包括附件型可穿戴装置(例如手表、戒指、手镯、脚镯、项链、眼镜、隐形眼镜或头戴式装置(HMD))、纺织品或服装整体型可穿戴装置(例如,电子服装)、身体附着型可穿戴装置(例如,皮肤垫或纹身)和活体植入型可穿戴装置(例如,可植入电路)。
在一些实施例中,集线器装置200可以是家用电器。家用电器可以包括例如电视、数字视频盘(DVD)播放器、音频、冰箱、空调、清洁器、烤箱、微波炉、洗衣机、空气清洁器、机器人吸尘器、机顶盒、家庭自动化控制面板、门锁、安全控制面板,电视(TV)盒(例如,三星电子有限公司的HomeSync
集线器装置200可以执行移交语音识别工作的功能、匹配语音识别信息的功能或执行图2中描述的任务的功能中的至少一个。
根据实施例,语音识别功能可以第一次在电子装置100的第一电子装置100-1上被激活,并且第一电子装置100-1可以对在激活语音识别功能时获得的用户语音执行语音识别,并且将语音识别信息发送到集线器装置200。此后,当特定事件要求在第一电子装置100-1上激活语音识别功能的同时在其他电子装置上继续地执行语音识别时,集线器装置200可以确定接管语音识别执行的电子装置。
例如,集线器装置200可以基于从电子装置100接收的语音信号的信噪比(SNR)和/或振幅来感测用户的移动。例如,当用户在从第一电子装置100-1移动到第二电子装置100-2的同时讲话时,从第一电子装置100-1接收的语音信号的SNR和/或振幅将逐渐减小,并且从第二电子装置100-2接收的语音信号的SNR和/或振幅将逐渐增大。集线器装置200可以基于SNR和信号振幅中的至少一个来感测用户从第一电子装置100-1移动到第二电子装置100-2,并且相应地,集线器装置200可以将第二电子装置100-2确定为接管语音识别执行的电子装置。这里,SNR仅仅是用于指示语音信号的质量的示例,并且还可以使用诸如声压级(SPL)的用于评估其他语音信号的质量的参数。
当第二电子装置100-2被确定为接管语音识别执行的装置时,集线器装置200可以将语音识别工作移交给第二电子装置100-2。这样,集线器装置200可以向第二电子装置100-2发送用于激活语音识别功能的控制信号。
从集线器装置200接收控制信号的第二电子装置100-2可以激活语音识别功能。第二电子装置100-2可以将关于由第二电子装置100-2获得的用户语音的标识信息发送到集线器装置200。另外,当用户再次移动到其他电子装置时,集线器装置200可以以相同的方式将语音识别工作移交给其他电子装置。
当从最后输入用户语音的第n个电子装置100-N接收到语音识别信息时,集线器装置200可以按时间顺序对从电子装置100-1到100-N接收的语音识别信息执行匹配,并且基于通过匹配最终获得的语音识别结果来执行任务。例如,当通过电子装置100-1到100-N获得的用户的整个语音是“今天天气怎么样?”,集线器装置200可以执行向第n电子装置100-N发送控制信号的任务,该控制信号使得第n电子装置100-N输出“今天下午可能会有雨”的语音响应。
作为任务的示例,当用户给出语音命令来控制装置,例如“打开空调”时,可以生成打开空调的控制命令并将其发送到空调以便执行任务,并且空调可以提供语音响应,“空调开启”。作为另一个示例,当用户的语音命令是“打开空调”时,可以生成打开空调的控制命令并将其发送到空调以便执行任务,并且除空调以外的其他电子装置(例如,更接近用户的电子装置,语音最后输入到的电子装置或其他电子装置)可以提供语音响应,“空调开启”。
图5A是示出根据又一个实施例的语音识别系统4000的图。
语音识别系统4000可以包括电子装置100-1到100-N(所有这些装置都可以被称为电子装置100)、集线器装置和服务器300。
电子装置100、集线器装置200和服务器300可以以无线或有线通信方式与外部装置通信。例如,电子装置100可以通过集线器装置200与服务器300通信。
与图4中的语音识别系统3000相比,服务器300可以在图5A的语音识别系统4000中扮演集线器装置200的一部分角色。例如,服务器300可以执行匹配语音识别信息的功能或执行由图4中的语音识别系统3000的集线器装置200执行的任务的功能中的至少一个。
图5B是示出根据又一个实施例的语音识别系统5000的图。
图5B中的语音识别系统5000示出了图2的语音识别系统1000、图3的语音识别系统2000和图4的语音识别系统3000的组合的混合形式。
例如,参考图5B,语音识别系统5000中的电子装置的电子装置100-1可以执行一系列用于语音识别的过程中的大部分过程,其他电子装置100-2可以仅执行一系列用于语音识别的过程中的一些过程并将结果发送到集线器装置200以使集线器装置200执行剩余部分,并且其他电子装置100-3可以仅执行一系列用于语音识别的过程中的一些过程并将结果发送到服务器300使服务器300执行剩余部分。
语音识别系统5000的电子装置100、集线器装置200或服务器300中的至少一个可以执行移交语音识别工作的功能、匹配语音识别信息的功能和执行任务的功能中的至少一个。
下文中,将参考图6至图9描述根据上述各种实施例的语音识别系统中的语音识别方法。
图6是示出根据实施例的语音识别系统1000中的语音识别方法的流程图。
参照图6,语音识别系统1000可以包括第一电子装置100-1和第二电子装置100-2。
首先,第一电子装置100-1和第二电子装置100-2可以处于语音识别待机状态(S610)。此后,当用户在第一电子装置100-1附近发出包括触发字的语音时,第一电子装置100-1可以识别被包括在用户语音中的触发字(S620)。当第一电子装置100-1识别被包括在用户语音中的触发字时,第一电子装置100-1可以激活语音识别功能(S630)。在激活语音识别功能时,第一电子装置100-1可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S640)。
或者,可以通过用户的手动操作来激活语音识别功能。例如,当选择在第一电子装置100-1中提供的特定按钮时,可以激活语音识别功能。
此外,第一电子装置100-1可以感测特定事件,其中其他电子装置需要在激活语音识别功能的状态下继续地执行语音识别(S650)。例如,第一电子装置100-1可以包括多个麦克风,并且可以检测用户从一个位置移动到另一个位置的事件。这里,多个麦克风可以检测通过多个麦克风输入的用户语音的音量的差异。根据另一个实施例,第一电子装置100-1可以包括相机,并且可以通过相机获得的图像来检测事件。
此后,当检测到其他装置需要继续地执行语音识别的特定事件时,第一电子装置100-1可以发送用于激活语音识别功能的控制信号,以将语音识别工作移交给在用户的移动方向上的第二电子装置100-2(S660)。在这种情况下,第一电子装置100-1还可以向第二电子装置100-2发送附加信息和用户信息以执行匹配。
用户信息可以包括例如,各种用户信息,诸如用户标识信息(ID)、用户名、用户帐户信息、从用于扬声器所识别的语音中获得的特征信息等。用户信息可以用于区分和匹配用户的语音信息。例如,第二电子装置100-2可以将从第一电子装置100-1接收的用户信息与从当前输入到第二电子装置100-2的语音中获得的用户信息进行比较,以确定该用户是否是相同用户并匹配相同用户的语音信息。接收到控制信号的第二电子装置100-2可以激活语音识别功能(S670)。另外,第二电子装置100-2可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S680)。
在这种情况下,第二电子装置100-2可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行一系列用于语音识别的过程中的一些过程。例如,第二电子装置100-2可以仅进行执行语音记录以获得音频信号的过程。作为另一个示例,第二电子装置100-2可以最多执行基于声学模型获得发音信息、音素信息或字符串信息的过程。
当第一电子装置100-1被确定为执行最终匹配的装置时,第二电子装置100-2将根据语音识别执行获得的语音识别信息发送到第一电子装置100-1(S690)。在这种情况下,当在S680中执行一系列用于语音识别的过程的所有过程时,语音识别信息可以包括最终结果(例如,对应于用户语音的文本数据)。当在S680中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果(例如,音频信号、从音频信号获得的特征信息、发音信息、音素信息、字符串信息等)。此外,第二电子装置100-2还可以发送用于与第一电子装置100-1匹配的附加信息和用户信息。
第一电子装置100-1可以按时间顺序将通过在S640中执行的语音识别获得的语音识别信息与从第二电子装置100-2接收的语音识别信息进行匹配(S693)。在这种情况下,当从第二电子装置100-2接收的语音识别信息是中间结果时,第一电子装置100-1可以执行用于语音识别剩余过程以获得最终结果,并且可以基于最终结果执行匹配。
此外,第一电子装置100-1可以基于作为匹配结果获得的整个用户语音的最终的识别结果来执行任务(S695)。
另一方面,在图6中,尽管匹配被描述为由第一电子装置100-1执行,但是可以由第二电子装置100-2执行匹配。例如,第二电子装置100-2可以向第一电子装置100-1发送用于请求语音识别信息的发送的信号,而不是在步骤S690中第二电子装置100-2向第一电子装置100-1发送语音识别信息。因此,第一电子装置100-1可以将通过在S640中执行的语音识别获得的语音识别信息发送到第二电子装置100-2。或者,在S660中,第一电子装置100-1也可以将语音识别信息发送到第二电子装置100-2。第二电子装置100-2可以按时间顺序将从第一电子装置100-1接收的语音识别信息与通过在S680中执行的语音识别获得的语音识别信息进行匹配。另外,第二电子装置100-2可以执行任务。
尽管描述了相同的电子装置执行匹配和任务,但是执行匹配的电子装置可以向其他电子装置提供关于作为匹配结果获得的整个用户语音的最终的识别结果的信息,并且其他电子装置也可以基于关于最终的识别结果的信息来执行任务。
图7是示出根据另一个实施例的语音识别系统中的语音识别方法的流程图。
参照图7,语音识别系统2000可以包括第一电子装置100-1、第二电子装置100-2和服务器300。
首先,第一电子装置100-1和第二电子装置100-2可以处于语音识别待机状态(S710)。此后,当用户在第一电子装置100-1附近发出包括触发字的语音时,第一电子装置100-1可以识别被包括在用户语音中的触发字(S720)。
当第一电子装置100-1识别被包括在用户语音中的触发字时,第一电子装置100-1可以激活语音识别功能(S730)。
或者,语音识别功能可以通过用户的手动操作激活。例如,当选择在第一电子装置100-1中提供的特定按钮时,可以激活语音识别功能。
此外,第一电子装置100-1可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S740)。在这种情况下,第一电子装置100-1可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行一系列用于语音识别的过程中的一些过程。例如,第一电子装置100-1可以仅进行执行语音记录以获得音频信号的过程。作为另一个示例,第一电子装置100-1可以最多执行基于声学模型获得发音信息、音素信息或字符串信息的过程。
第一电子装置100-1可以将通过执行语音识别而获得的语音识别信息发送到服务器300(S745)。这里,当在S740中执行一系列用于语音识别的过程中的所有过程时,语音识别信息可以包括最终结果(例如,对应于音频信号的文本数据)。当在S740中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果。例如,中间结果可以是仅通过执行语音记录而获得的音频信号。或者,中间结果可以是从音频信号获得的特征信息。或者,中间结果可以是基于声学模型获得的发音信息、音素信息或字符串信息。在这种情况下,第一电子装置100-1还可以发送用于匹配的附加信息和用户信息。
因此,电子装置100和服务器300可以划分和执行用于语音识别过程,从而减轻电子装置100的操作负担。
此外,第一电子装置100-1可以感测特定事件,其中其他电子装置需要在激活语音识别功能的状态下继续地执行语音识别(S750)。例如,当检测到用户移动的事件时,第一电子装置100-1可以发送用于激活语音识别功能的控制信号,以将语音识别工作移交给在用户的移动方向上的第二电子装置100-2(S755)。
根据又一个实施例,代替第一电子装置100-1,服务器300可以执行移交语音识别工作的操作。例如,服务器300可以从能够检测用户的移动的第一电子装置100-1接收与用户的移动相关的信号,基于检测到的信号感测用户移动的事件,并且发送用于激活语音识别功能的控制信号以移交语音识别工作到第二个电子装置100-2。
接收控制信号的第二电子装置100-2可以激活语音识别功能(S760)。另外,第二电子装置100-2可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S765)。在这种情况下,第二电子装置100-2可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行一系列用于语音识别的过程中的一些过程。
此外,第二电子装置100-2可以将通过执行语音识别而获得的语音识别信息发送到服务器300(S770)。在这种情况下,当在S765中执行一系列用于语音识别的过程中的所有过程时,语音识别信息可以包括最终结果(例如,对应于音频信号的文本数据)。当在S765中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果(例如,音频信号、从音频信号获得的特征信息、发音信息、音素信息、字符串信息等)。在这种情况下,第二电子装置100-2还可以发送用于匹配的附加信息和用户信息。
服务器300可以按时间顺序将从第一电子装置100-1接收的语音识别信息与从第二电子装置100-2接收的语音识别信息进行匹配(S780)。例如,当从第一电子装置100-1接收的语音识别信息或从第二电子装置100-2接收的语音识别信息中的至少一个是中间结果时,服务器300可以执行用于语音识别剩余过程以获得最终结果,并且可以基于最终结果执行匹配。
另外,服务器300可以基于作为匹配结果获得的整个用户语音的最终的识别结果来执行任务(S790)。
例如,当通过第一电子装置100-1和第二电子装置100-2获得的用户的整个语音是“今天天气怎么样?”时,服务器300可以执行向第二电子装置100-2发送控制信号的任务,该控制信号使得第二电子装置100-2输出“今天下午可能会有雨”的语音响应。
另一方面,在图7中,尽管匹配被描述为由服务器300执行,但是可以由第一电子装置100-1或第二电子装置100-2执行匹配。例如,服务器300可以分别对从第一电子装置100-1和第二电子装置100-2获得的用户语音执行识别,以获得语音识别信息,以及将获得的语音识别信息发送到第一电子装置100-1或第二电子装置100-2,并且第一电子装置100-1或第二电子装置100-2可以对语音识别信息执行匹配。另外,第一电子装置100-1或第二电子装置100-2可以执行该任务。
图8A是示出根据又一个实施例的语音识别系统中的语音识别方法的流程图。
参考图8A,语音识别系统3000可以包括第一电子装置100-1、第二电子装置100-2和集线器装置200。
首先,第一电子装置100-1和第二电子装置100-2处于语音识别待机状态(S810)。此后,当用户在第一电子装置100-1附近发出包括触发字的语音时,第一电子装置100-1可以识别被包括在用户语音中的触发字(S820)。或者,可以通过用户的手动操作来激活语音识别功能。例如,当选择在第一电子装置100-1中提供的特定按钮时,可以激活语音识别功能。
当第一电子装置100-1识别被包括在用户语音中的触发字时,第一电子装置100-1可以激活语音识别功能(S830)。另外,第一电子装置100-1可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S840)。在这种情况下,第一电子装置100-1可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行一系列用于语音识别的过程中的一些过程。例如,第一电子装置100-1可以仅进行执行语音记录以获得音频信号的过程。作为另一个示例,第一电子装置100-1可以最多执行基于声学模型获得发音信息、音素信息或字符串信息的过程。
此外,第一电子装置100-1可以将通过执行语音识别获得的语音识别信息发送到集线器装置200(S845)。这样,当在S840中执行一系列用于语音识别的过程中的所有过程时,语音识别信息可以包括最终结果(例如,对应于音频信号的文本数据)。当在S840中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果(例如,音频信号、从音频信号获得的特征信息、发音信息、音素信息、字符串信息等)。在这种情况下,第一电子装置100-1还可以发送用于匹配的附加信息和用户信息。
因此,电子装置100和集线器装置200可以划分和执行用于语音识别相应过程,从而减轻电子装置100上的操作负担。
集线器装置200可以感测特定事件,其中当第一电子装置100-1的语音识别功能被激活时,其他装置需要继续地执行语音识别(S850)。例如,当检测到用户移动时,集线器装置200可以发送用于激活语音识别功能的控制信号,以将语音识别工作移交给在用户移动方向上的第二电子装置100-2(S855)。例如,集线器装置200可以从能够感测用户的移动的电子装置接收与用户的移动有关的信号,基于检测到的信号感测用户移动的事件,并且发送用于激活语音识别功能以移交语音识别工作的控制信号至第二电子装置100-2。
另一方面,代替集线器装置200,第一电子装置100-1可以执行移交语音识别工作的操作。例如,第一电子装置100-1可以通过多个麦克风和相机感测用户的移动,基于感测到的用户移动感测到用户移动的事件,并且发送用于激活语音识别功能的控制信号以将语音识别工作移交给第二电子装置100-2。
接收控制信号的第二电子装置100-2可以激活语音识别功能(S860)。另外,第二电子装置100-2可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S865)。在这种情况下,第二电子装置100-2可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行一系列用于语音识别的过程中的一些过程。
此外,第二电子装置100-2可以将通过执行语音识别获得的语音识别信息发送到集线器装置200(S870)。在这种情况下,当在S865中执行一系列用于语音识别的过程中的所有过程时,语音识别信息可以包括最终结果(例如,对应于音频信号的文本数据)。当在S865中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果(例如,音频信号、从音频信号获得的特征信息、发音信息、音素信息、字符串信息等)。在这种情况下,第二电子装置100-2还可以发送用于匹配的附加信息和用户信息。
集线器装置200可以按时间顺序将从第一电子装置100-1接收的语音识别信息与从第二电子装置100-2接收的语音识别信息进行匹配(S880)。在这种情况下,当从第一电子装置100-1接收的语音识别信息和从第二电子装置100-2接收的语音识别信息中的至少一个是中间结果时,集线器装置200可以执行用于语音识别剩余过程以获得最终结果,并且可以基于最终结果执行匹配。
另外,集线器装置200可以基于作为匹配结果获得的整个用户语音的最终的识别结果来执行任务(S890)。
例如,当通过第一电子装置100-1和第二电子装置100-2获得的用户的整个语音是“今天天气怎么样?”,集线器装置200可以执行发送控制信号的任务,该控制信号使得第二电子装置100-2向第二电子装置100-2输出“今天下午可能会有雨”的语音响应。
另一方面,在图8A中,尽管匹配被描述为由集线器装置200执行,但是可以由第一电子装置100-1或第二电子装置100-2执行匹配。例如,集线器装置200可以分别对从第一电子装置100-1和第二电子装置100-2获得的用户语音执行识别,以获得语音识别信息,以及将获得的语音识别信息发送到第一电子装置100-1或第二电子装置100-2,并且第一电子装置100-1或第二电子装置100-2可以对语音识别信息执行匹配。另外,第一电子装置100-1或第二电子装置100-2可以执行该任务。
此外,通过执行任务获得的信息也可以发送到一个电子装置,但是通过执行任务获得的信息也可以发送到两个或更多个电子装置。例如,在语音命令“打开空调”的情况下,可以向空调发送执行“打开空调”任务的控制命令,并且可以向更接近用户的电子装置发送关于任务完成的反馈。
在上述实施例中,描述了电子装置100可以识别触发字。然而,根据另一个实施例,电子装置100可以不识别触发字而仅仅将从用户语音获得的音频数据发送到外部,并且可以在外部执行用于语音识别过程。这将参考图8B和8C来描述。
图8B是示出根据另一个实施例的语音识别系统中的语音识别方法的流程图。
参考图8B,首先,第一电子装置100-1和第二电子装置100-2处于语音识别待机状态(S822)。
当第一电子装置100-1检测到人声时(S824),第一电子装置100-1可以立即将记录的或获得的音频信号发送到集线器装置200(S826)。语音活动检测(voice ActivityDetection,VAD)是通常用于语音识别领域中的技术,并且是基于频域中的响度和能量分布,使用统计模型、深度学习模型等来检测人声的技术。此外,可以使用语音端点检测(voice end point detection,EPD)来检测人声,EPD是语音识别中常用的技术。
根据另一个实施例,第一电子装置100-1可以不包括语音活动检测功能,并且在这种情况下,第一电子装置100-1可以在待机状态下继续向集线器装置200发送音频信号。
当集线器装置200识别从第一电子装置100-1接收的音频信号中的触发字时(S828),集线器装置200可以激活语音识别功能(S832)并执行语音识别(S834)。
此外,集线器装置200可以检测特定事件,其中除第一电子装置100-1之外的装置需要继续地执行语音识别(S836)。例如,集线器装置200可以检测用户的移动。这样,集线器装置200可以发送用于激活语音识别功能的控制信号以移交语音标识工作(S838)。
接收激活控制信号的第二电子装置100-2可以开始记录并将音频信号发送到集线器装置200。另外,集线器装置200可以对从第二电子装置100-2接收的音频信号执行语音识别。
集线器装置200可以将从第一电子装置100-1接收的音频信号的语音识别结果与从第二电子装置100-2接收的音频信号的语音识别结果进行匹配,以获得最终的识别结果。
当从第一电子装置100-1接收的音频信号和从第二电子装置100-2接收的音频信号来自不同的用户时,集线器装置200可以在其他会话中新执行触发字识别和语音识别。也就是说,集线器装置200可以并行地处理多个用户的语音。或者,集线器装置200还可以被配置为一次仅处理一个用户的语音。
图8C是示出根据又一个实施例的语音识别系统中的语音识别方法的流程图。与图8B相比,即使集线器装置200不向第二电子装置100-2发送移交语音识别工作的控制信号,第二电子装置100-2也可以具有与第一电子装置100-1类似的语音活动检测功能,并且可以当检测到人声时立即将音频信号发送到集线器装置200。或者,第二电子装置100-2可以不包括语音活动检测功能,并且在这种情况下,第二电子装置100-2可以在待机状态下继续向集线器装置200发送音频信号。
参照图8C,第一电子装置100-1和第二电子装置100-2可以处于语音识别待机状态(S852)。
当第一电子装置100-1检测到人声时(S854),第一电子装置100-1可以立即将记录的音频信号发送到集线器装置200(S856)。然而,第一电子装置100-1可以不包括语音活动检测功能,并且在这种情况下,第一电子装置100-1可以在待机状态下继续向集线器装置200发送音频信号。
当集线器装置200识别从第一电子装置100-1接收的音频信号中的触发字时(S858),集线器装置200可以激活语音识别功能(S862)并执行语音识别(S864)。
当第二电子装置100-2检测到人声时(S866),第二电子装置100-2可以立即将记录的音频信号发送到集线器装置200(S868)。然而,第二电子装置100-2可以不包括语音活动检测功能,并且在这种情况下,第二电子装置100-2可以在待机状态下继续向集线器装置200发送音频信号。另外,集线器装置200可以对从第二电子装置100-2接收的音频信号执行语音识别。
集线器装置200可以将从第一电子装置100-1接收的音频信号的语音识别结果与从第二电子装置100-2接收的音频信号的语音识别结果进行匹配,以获得最终的识别结果。
当语音识别已经在处理相同用户的话语时,集线器装置200可以通过确定信号的质量来切换、维持或组合信号。当信号来自不同的用户时,集线器装置200可以在其他会话中新执行触发字标识和语音识别。
这里,集线器装置200的功能也可以实现在服务器300中。
图9是示出根据又一个实施例的语音识别系统中的语音识别方法的流程图。
参照图9,语音识别系统4000可以包括第一电子装置100-1、第二电子装置100-2、集线器装置200和服务器300。
这里,第一电子装置100-1和第二电子装置100-2处于语音识别待机状态(S910)。此后,当用户在第一电子装置100-1附近发出包括触发字的语音时,第一电子装置100-1可以识别被包括在用户语音中的触发字(S920)。或者,可以通过用户的手动操作来激活语音识别功能。例如,当选择在第一电子装置100-1中提供的特定按钮时,可以激活语音识别功能。
当第一电子装置100-1识别被包括在用户语音中的触发字时,第一电子装置100-1可以激活语音识别功能(S930)。此外,第一电子装置100-1可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S940)。在这种情况下,第一电子装置100-1可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行一系列用于语音识别的过程中的一些过程。例如,第一电子装置100-1可以仅进行执行语音记录以获得音频信号的过程。作为另一个示例,第一电子装置100-1可以最多执行基于声学模型获得发音信息、音素信息或字符串信息的过程。
此外,第一电子装置100-1可以将通过执行语音识别获得的语音识别信息发送到集线器装置200(S945)。在这种情况下,当在S940中执行一系列用于语音识别的过程中的所有过程时,语音识别信息可以包括最终结果(例如,对应于音频信号的文本数据)。当在S940中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果(例如,从音频信号获得的特征信息、发音信息、音素信息、字符串信息等)。在这种情况下,第一电子装置100-1还可以发送用于匹配的附加信息和用户信息。
因此,电子装置100和集线器装置200可以划分并执行用于语音识别过程,从而减轻电子装置100的操作负担。
另一方面,第一电子装置100-1也可以向服务器300发送语音识别信息,而不是向集线器装置200发送语音识别信息。
集线器装置200可以检测特定事件,其中在激活第一电子装置100-1的语音识别功能时,其他装置需要继续地执行语音识别(S950)。
例如,当检测到用户的移动时,集线器装置200可以发送用于激活语音识别功能的控制信号,以将语音识别工作移交给在用户的移动方向上的第二电子装置100-2(S955)。例如,集线器装置200可以从能够感测用户的移动的第一电子装置100-1接收与用户的移动有关的信号,基于接收的信号标识事件,并且以及发送用于激活语音标识功能的控制信号以将语音标识工作移交给第二电子装置100-2。
根据又一个实施例,代替集线器装置200,服务器300可以执行移交语音识别工作的操作。例如,服务器300可以从能够感测用户的移动的电子装置100-1接收与用户的移动相关的信号,基于接收的信号标识事件,并且发送用于激活语音识别功能的控制信号以将语音识别工作移交给第二电子装置100-2。
另一方面,第一电子装置100-1可以执行移交语音识别工作的操作。例如,第一电子装置100-1可以通过多个麦克风和相机检测用户的移动,基于所感测到的用户移动来检测用户的移动的事件,并且发送用于激活语音识别功能的控制信号以将语音识别工作移交给第二电子装置100-2。
接收到控制信号的第二电子装置100-2可以激活语音识别功能(S960)。另外,第二电子装置100-2可以在激活语音识别功能的状态下对用户语音输入执行语音识别(S965)。在这种情况下,第二电子装置100-2可以执行一系列用于语音识别的过程中的所有过程,或者可以仅执行用于语音识别系列过程中的一些过程。
或者,第二电子装置100-2可以将通过执行语音识别获得的语音识别信息发送到集线器装置200(S970)。在这种情况下,当在S965中执行一系列用于语音识别的过程中的所有过程时,语音识别信息可以包括最终结果(例如,对应于音频信号的文本数据)。当在S965中仅执行一系列用于语音识别的过程中的一些过程时,语音识别信息可以包括中间结果(例如,音频信号、从音频信号获得的特征信息、发音信息、音素信息、字符串信息等)。在这种情况下,第二电子装置100-2还可以向集线器200发送附加信息和用户信息,以用于匹配。
另一方面,第二电子装置100-2也可以向服务器300发送语音识别信息,而不是向集线器装置200发送语音识别信息。
集线器装置200可以将从第一电子装置100-1接收的语音识别信息和从第二电子装置100-2接收的语音识别信息发送到服务器300(S980)。在这种情况下,集线器装置200可以将从第一电子装置100-1接收的语音识别信息和从第二电子装置100-2接收的语音识别信息发送到服务器300,如从第一电子装置100-1和第二电子装置100-2接收的相同。或者,当从第一电子装置100-1接收的语音识别信息和从第二电子装置100-2接收的语音识别信息是中间结果时,集线器装置200可以执行用于语音识别的剩余过程并将最终结果发送到服务器300。或者,当从第一电子装置100-1和第二电子装置100-2接收到音频信号时,集线器装置200可以将所接收的音频信号中继到服务器300。
此外,服务器300可以按时间顺序匹配接收的语音识别信息。当接收的语音识别信息是中间结果时,服务器300可以执行用于语音识别的剩余过程以获得最终结果,并且可以基于最终结果执行匹配。另外,集线器装置200可以基于作为匹配结果获得的整个用户语音的最终的识别结果来执行任务(S995)。
例如,当通过第一电子装置100-1和第二电子装置100-2获得的用户的整个语音是“今天天气怎么样?”,服务器300可以执行向第二电子装置100-2发送控制信号的任务,该控制信号使得第二电子装置100-2输出“今天下午可能会有雨。”的语音响应。
另一方面,在图9中,尽管匹配被描述为由服务器300执行,但是可以由第一电子装置100-1、第二电子装置100-2或集线器装置200执行匹配。另外,第一电子装置100-1、第二电子装置100-2或集线器装置200可以执行该任务。
如上所述,在根据各种实施例的语音识别系统中,语音识别工作可以根据用户的移动自动地移交给用户附近的电子装置100,由各个电子装置100获得的语音识别信息可以被匹配,并且可以基于匹配的结果来执行任务。另外,一系列用于语音识别的过程可以被分布到多个装置中并由多个装置执行,从而减少一个装置中的操作负担。
在下文中,将参考图10至图13描述电子装置100、集线器装置200和服务器300的配置。
图10是示出根据实施例的电子装置100的配置的图。
参考图10,电子装置100可以包括处理器110、存储器120、通信器130和麦克风140。
处理器110是用于控制电子装置100的整体操作的组件。例如,处理器110可以驱动操作系统或应用来控制连接到处理器110的多个硬件或软件组件,并且可以执行各种数据处理和操作。处理器110可以是中央处理单元(CPU)或图形处理单元(GPU)或两者。处理器110可以被实现为通用处理器、数字信号处理器、专用集成电路(ASIC)、片上系统(SoC)、微型计算机(MICOM)等中的至少一个。
存储器120可以包括内部存储器或外部存储器。存储器120由处理器110访问,并且处理器110可以执行对存储器120中的数据的读出、写入、校正、删除、更新等。
存储器120可以包括被配置为一个或多个模块的软件和/或固件。该模块可以对应于计算机可执行指令的集合。
存储器120可以包括触发字模块121、语音识别模块122、移交模块123、匹配模块124和任务模块125。模块121、122、123、124和125可由处理器110执行以执行对应的功能。
触发字模块121可以识别音频信号中的预先确定的触发字或短语。例如,触发字模块121可以识别被包括在通过麦克风140获得的用户语音中的触发字。当识别触发字时,可以激活电子装置100的语音识别功能。例如,触发字模块121可以激活麦克风140的记录功能并且激活或驱动语音识别模块122。
或者,电子装置100可以不包括触发字模块121,并且在这种情况下,电子装置100可以通过用户的手动操作来激活语音识别功能。例如,可以通过选择提供在电子装置100中的特定按钮来激活语音识别功能。作为另一个示例,电子装置100可以仅执行记录并将音频信号发送到外部装置,例如,其他电子装置100、集线器装置200、服务器300等,并且还可以通过识别这样的外部装置中的触发字来控制要在电子装置100中激活的语音识别功能。
语音识别模块122可以执行语音识别。语音识别模块122可以使用自动语音识别(automatic speech recognition,ASR)技术。
语音识别模块122可以将对应于用户语音的音频信号转换为文本数据。将参考图13描述语音识别模块122的具体功能。
参照图13,语音识别模块122可以包括特征提取器和解码器。特征提取器可以从音频信号中提取特征信息(特征向量)。此外,解码器可以基于声学模型和语言模型获得与特征信息相对应的语音识别信息。语音识别信息可以包括与基于声学模型获得的特征信息相对应的发音信息、音素信息和字符串信息,以及与基于语言模型获得的发音信息相对应的文本数据。
根据实施例,语音识别模块122可以仅包括声学模型和语言模型中的一个,或者可以仅使用声学模型和语言模型中的一个,即使它包括声学模型和语言模型两者。在这种情况下,语音识别模块122可以通过仅应用声学模型和语言模型中的一个来获得语音识别信息。例如,语音识别信息可以包括基于声学模型获得的发音信息、音素信息和字符串信息,或者基于语言模型获得的文本信息。也就是说,语音识别信息可以包括作为中间结果的发音信息、音素信息或字符串信息。或者,语音识别信息可以包括文本数据,这是最终结果。这里,可以将语音识别信息从第一电子装置100-1发送到第二电子装置100-2,并且可以从第二电子装置100-2通过应用在第一电子装置100-1中尚未应用的声学模型或语言模型来最终获得文本数据。
根据另一个实施例,语音识别模块122可以不包括声学模型和语言模型两者,或者可以不使用声学模型或语言模型,即使它包括声学模型和语言模型两者。在这种情况下,语音识别模块122可以通过至多执行提取特征信息的操作来输出包括特征信息的语音识别信息。语音识别信息可以被发送到其他装置,并且可以通过其他装置应用声学模型和语言模型来最终获得文本数据。
根据又一个实施例,电子装置100可以不包括语音识别模块自身,或者即使它包括语音识别模块也可以不使用语音识别模块。在这种情况下,电子装置100可以将通过麦克风140获得的音频信号发送到其他装置,并且其他装置可以执行语音识别。
因此,选择性地使用语音识别模块122的功能可以减轻电子装置100中的操作负担。
另外,当语音识别模块122从外部装置接收到语音识别信息(其可以是中间结果)时,语音识别模块122可以对语音识别信息执行剩余的语音识别过程。例如,当从外部装置接收的语音识别信息是应用了声学模型而不是语言模型的信息时,语音识别模块122可以通过将语言模型应用于接收的语音识别信息来获得最终的识别结果。作为另一个示例,当从外部装置接收的语音识别信息仅包括特征信息时,语音识别模块122可以通过将语言模型和声学模型应用于语音识别信息来获得最终的识别结果。
当通过语音识别模块122从音频信号获得文本数据时,可以将文本数据发送到任务模块125。
移交模块123可以执行检测其中其他装置需要继续地执行语音识别的特定事件的功能,选择语音识别工作要移交到的其他装置的功能,发送用于激活其他装置的语音识别功能的控制信号的功能,以及发送语音识别信息、用于匹配的附加信息和/或用户信息的功能。
例如,电子装置100可以包括用于检测用户的移动的多个麦克风140,并且移交模块123可以检测由于用户的移动而导致的通过多个麦克风输入的用户语音的音量的差异。根据又一个实施例,第一电子装置100-1可以包括相机,并且移交模块123可以基于通过相机获得的图像来检测用户移动。
移交模块123可以通过使用能够接收预先存储在存储器中的语音的其他电子装置的信息来选择语音识别工作要移交到的其他电子装置。例如,当移交模块123检测到用户移动的事件时,移交模块123可以获得用户的移动信息,并且可以基于存储在存储器120中的其他电子装置的信息,在其他电子装置中选择当前最接近用户的其他电子装置。另外,移交模块123可以通过通信器130将用于激活语音识别功能的控制信号发送到所选择的其他电子装置。
将参照图18至图20更详细地描述通过电子装置100使用移交模块123来标识在用户的移动方向上的其他电子装置的方法。
电子装置100可以生成网络(例如,家庭网络)中的电子装置的位置信息,以便标识哪个电子装置在用户的移动方向上。当新的电子装置进入网络时,还可以为新的电子装置生成位置信息。
将参考图18描述用于在电子装置上生成位置信息的方法的一个示例。
参照图18,由上箭头指示的流是生成位置信息的过程,而由下箭头指示的流是通过使用生成的位置信息来激活在用户的移动方向上的其他电子装置的语音识别功能的过程。
本文将描述学习位置信息的过程。如图18所示,在步骤1)中,第一电子装置100-1在激活卧室中的第一电子装置100-1的语音识别功能时开始语音识别。在步骤2-1)中,第一电子装置100-1可以基于通过多个麦克风输入的用户语音来获得关于用户的移动方向的信息。在步骤3-1)中,第一电子装置100-1可以向相同网络内能够接收语音的所有电子装置发送用于激活语音识别功能的控制信号。在步骤4)中,当第二电子装置100-2在用户移动的方向上的客厅中接收用户语音时,第二电子装置100-2可以将接收的用户语音通知给第一电子装置100-1。在步骤5)中,第一电子装置100-1可以通过将关于用户的移动方向的信息与第二电子装置100-2匹配来生成第二电子装置100-2的位置信息。通过对其他装置执行这种方法,可以生成相同网络内的每个电子装置上的位置信息,并且可以在电子装置之间共享位置信息。例如,电子装置100可以相互发送位置信息,或者可以将位置信息发送到集线器200或服务器300。
在生成位置信息之后,第一电子装置100-1可以仅激活在用户的移动方向上的特定装置。即,参照图18的下箭头所示的流程,在步骤1)中,电子装置100-1在激活卧室中的第一电子装置100-1的语音识别功能时开始语音识别。在步骤2-2)中,第一电子装置100-1可以基于通过多个麦克风输入的用户语音输入来获得关于用户的移动方向的信息。在步骤3-2)中,第一电子装置100-1可以基于第一电子装置100-1确定用户移动的方向与第二电子装置100-2在客厅中的位置匹配,向第二电子装置100-2发送用于激活语音识别功能的控制信号。
图19是示出根据实施例的包括多个麦克风的电子装置100的图。
参考图19,电子装置100可以包括扬声器和多个麦克风151和153。电子装置100可以确定使用从多个麦克风151和153接收的用户语音生成用户语音的方向。
具体地,从声源到多个麦克风151和153的距离可以彼此不同。因此,在特定点生成的语音被递送到多个麦克风151和153中的每一个所需的时间可以不同,并且在特定点生成的语音可以被递送到多个麦克风151和153中的每一个的声音的响度可以不同。电子装置100可以检测通过使用在多个麦克风151和153中的每一个中检测到相同语音的时间差或声音的响度来生成语音命令的方向。这和人的耳朵检测声音方向的原理是相同的。
用于确定使用语音的用户的移动方向的特定技术可以包括GCC-PHAT、SRP-PHAT等。
多个麦克风151和153的数量不限于两个,并且可以使用更多数量的麦克风更精确地检测方向。
根据实施例,电子装置100可以在电子装置100中提供的多个麦克风中选择一对不同组合的两个麦克风,并使用每对麦克风计算声学信号的时延。电子装置100可以基于计算出的时延和多个麦克风的位置来计算声源的三维位置。这样的方法的算法可以是具有相位变换的广义互相关(GCC-PHAT)。
此外,例如,电子装置100可以使用多个麦克风接收声学信号,并将声学信号改变为与多个麦克风中的每个麦克风对应的声学数据。假设接收的声学信号以特定的方向传播,电子装置100可以通过计算多个麦克风中的每个麦克风的时延并将多个麦克风中的每个麦克风对应的声学数据移动计算出的与声学数据对应的时延,然后添加延迟的声学数据来计算波束赋形功率输出。这里,由于当假设方向是声源的实际方向时,添加了声学数据的值被最大化,因此电子装置100可以计算所有可能方向的波束赋形功率输出,并且确定波束赋形功率输出被最大化的方向作为声源的方向。这样的方法的算法可以是具有相位变换的转向的响应功率(steered response power with the phase transform,SRP-PHAT)。
图20是示出根据实施例的用于通过电子装置100使用相机检测用户的移动方向的方法的图。
图20所示的电子装置100可以包括多个麦克风和相机160。电子装置100可以使用多个麦克风来确定用户的移动。如果确定存在用户的移动,则电子装置100可以控制以驱动电子装置100中提供的相机160,或者当相机被提供在其他装置中时,可以控制以驱动其他装置的相机。另外,电子装置100可以获得由相机160生成的图像或者接收由提供在其他装置中的相机生成的图像,并且可以基于该图像标识用户的移动方向和噪声方向(例如,来自打开的窗的声音、TV声音等)。也就是说,可以基于由相机生成的图像来检测用户的方向,并且可以去除或衰减来自其他方向的噪声,从而更准确地检测用户的方向。电子装置100还可以将关于噪声方向的信息发送到语音识别工作被移交到的其他电子装置。
例如,电子装置100可以通过使用通过统计学习算法分离原始声音的独立分量分析技术从音频信号中分离声源。此外,电子装置100可以基于通过相机160获得的关于噪声方向的信息,在分离的声源中标识用户的语音。在这种情况下,电子装置100可以包括两个或更多个麦克风,以标识由两个或更多个麦克风接收的相应声源的方向。此外,电子装置100可以将多个麦克风接收的相应声源的方向与通过相机160获得的方向信息进行比较,以在多个声源中标识与用户语音相对应的声源。当标识出与用户语音相对应的声源时,电子装置100可以衰减剩余的声源。
此外,当电子装置识别语音时,电子装置可以通过从接收的音频信号在用户方向上执行波束赋形来增加声源,并且可以在噪声方向上衰减噪声。
匹配模块124可以按时间顺序匹配关于从不同电子装置收集的用户语音的识别信息。
根据实施例,基于通过对通过麦克风140获得的用户语音执行语音识别而获得的第一语音识别信息、以及从语音识别工作被移交到的其他电子装置接收的第二语音识别信息,可以获得最终的识别结果。
在这种情况下,匹配模块124可以获得关于用于激活语音识别功能的控制信号被发送到其他电子装置的时间的信息,并且可以基于所获得的关于时间的信息来匹配第一语音识别信息和第二语音识别信息,以获得最终的识别结果。这里,所获得的关于时间的信息可以包括关于发送控制信号的绝对时间的信息。也就是说,可以基于绝对时间信息执行匹配。或者,所获得的关于时间的信息可以包括关于在电子装置100的语音识别功能被激活之后将控制信号发送到其他电子装置所花费的时间的信息。也就是说,可以基于相对时间信息来执行匹配。
将参考图21至图25描述使用匹配模块125匹配语音识别信息的电子装置100的示例。
图21是示出根据实施例的电子装置100的语音识别信息匹配方法的图。
参照图21,当用户在从第一电子装置100-1移动到第二电子装置100-2和第三电子装置100-3的同时发声时,电子装置100-1、100-2和100-3可以顺序地激活语音识别功能。例如,用户可能想知道他应该什么时候离开家才能准时参加晚餐,并且可能会问“What timeshould I leave the house to be on time for the dinner today?(我应该什么时候离开家准时参加今天的晚餐?)”。此外,用户在提问时可能会从卧室移动到厨房。具体地,当用户在第一电子装置100-1所在的卧室中时,他可以发出“What time should I leave(我应该什么时候离开)”,并且可以向客厅移动。这里,第一电子装置100-1可以识别短语“Whattime should I(我应该什么时候)”,但是由于当用户在向客厅移动时他的声音逐渐消失而可能无法清楚地识别单词“leave(离开)”。此外,第一电子装置100-1可能会错误识别术语“leave”与一些类似的发音的术语,诸如“live”。然后,在用户接近客厅中的第二电子装置100-2时,位于客厅中的第二电子装置100-2可能识别短语“I leave to be on time four(我4点准时离开)”。如果确定第二电子装置100-2从用户接收到比由第一电子装置100-1接收的音频信号更强的音频信号,则可以确定术语“离开”在句子或短语的上下文中更准确。此外,当用户向厨房移动并靠近电子装置100-3时,位于厨房中的电子装置100-3可以识别短语的剩余部分“for the dinner today?(参加今天的晚餐?)”。这里,与上述类似,第三电子装置100-2可以基于由第二电子装置100-2和第三电子装置100-3接收的音频信号的强度,将术语“for”错误识别成一些类似发音术语(诸如“four”),可以确定的是术语“for”在句子或短语的上下文中更加准确。此外,第三电子装置100-3可以检测用户话语的结束,并且组合由第一电子装置100-1、第二电子装置100-2和第三电子装置100-3所识别的每个短语并生成最终的结果。最终的结果可以是整个用户的话语,其中读出:“What time shouldI leave the house to be on time for the dinner today?(我应该什么时候离开家准时参加今天的晚餐?)”此外,电子装置100-1、100-2和100-3、集线器装置200或服务器300中的任何一个可以匹配由电子装置100-1、100-2和100-3生成的语音识别信息以生成最终的结果。在这种情况下,为了匹配语音识别信息,需要时间信息作为用于匹配的附加信息。
图22是示出基于绝对时间信息协调语音识别信息的示例的图。
参考图22,电子装置100-1、100-2和100-3可以以绝对时间形式记录激活语音识别功能的时间,并在绝对时间轴上执行匹配。在这种情况下,可以基于得分、正确执行语音识别的程度来执行匹配。在这里,黑色字母是具有高分的部分。得分可以基于SNR大小和/或ASR得分来确定。ASR得分可包括指示声学模型(AM)的应用结果的准确度的AM得分或者指示语言模型(LM)的应用结果的准确度的LM得分中的至少一个。
例如,第一电子装置100-1、第二电子装置100-2和第三电子装置100-3中的每一个可以获得关于激活每个语音识别功能的绝对时间(日期、小时、分钟、秒)的信息,并将时间信息发送到装置以执行最终匹配。当执行最终匹配的装置例如是第三电子装置100-3时,第一电子装置100-1和第二电子装置100-2可以将由第一电子装置100-1和第二电子装置100-2生成的语音识别信息和时间信息发送到第三电子装置100-3。在这种情况下,第一电子装置100-1和第二电子装置100-2可以直接向第三电子装置100-3发送时间信息,或者第一电子装置100-1可以向第二电子装置100-2发送时间信息,并且第二电子装置100-2可以收集关于由第二电子装置100-2获得的关于时间的信息和从第一电子装置100-1接收的时间信息,并且将所收集的信息发送到第三电子装置100-3。也就是说,时间信息可以以链式的方式被发送。语音识别信息也可以类似地分开发送或如同链被发送。然后,第三电子装置100-3可以基于接收的关于时间的信息和语音识别信息来执行匹配以获得最终的识别结果,并且可以基于最终的识别结果执行任务。例如,第一电子装置100-1可以记录当用户开始发出“What time should I live”时第一电子装置100-1被激活的绝对时间。第二电子装置100-2可以记录第二电子装置100-2被激活以接收一部分短语(例如,“leave the house to beon time four”)的绝对时间。此外,第三电子装置100-3可以记录激活第三电子装置100-3以接收一部分短语(例如,“for the dinner today?”)的绝对时间。第三电子装置100-3还可以检测话语的结束并基于从第一电子装置100-1和第二电子装置100-2接收的绝对时间生成最终的结果。这里,可以收集绝对时间信息并用于精确地确定用户的语音的顺序和准确度。
图23是示出基于相对时间信息协调语音识别信息的示例的图。
参考图23,电子装置100-1、100-2和100-3中的每一个可以基于用户第一次激活语音识别时间来记录语音识别功能第一次激活的时间的相对时间,并且将记录的相对时间发送到下一个电子装置,并且这样的相对时间信息可用于匹配。
例如,第一电子装置100-1、第二电子装置100-2和第三电子装置100-3中的每一个可以基于每个语音识别功能被激活的时间获得关于其他装置被激活的相对时间的信息,并且将时间信息发送到下一个装置。当执行最终匹配的装置例如是第三电子装置100-3时,第一电子装置100-1可以首先将由第一电子装置100-1获得的相对时间信息发送到第二电子装置100-2,并且第二电子装置100-2可以将由第二电子装置100-2获得的相对时间信息添加到从第一电子装置100-1接收的时间信息中,并且将收集到的信息发送到第三电子装置100-3。也就是说,时间信息可以以链式的方式被发送。语音识别信息也可以类似地如同链被传送。然后,第三电子装置100-3可以通过基于接收的相对时间信息列出语音识别信息来执行匹配,以获得最终的识别结果。另外,第三电子装置100-3可以基于最终的识别结果执行任务。例如,参照图23,第一电子装置100-1第一次被激活的时间与第二电子装置100-2第一次被激活的时间之间的相对时间差为1.3秒。第一电子装置100-1第一次被激活的时间和第三电子装置100-3第一次被激活的时间之间的相对时间差是1.5秒。另外,第一电子装置100-1第一次被激活的时间与第三电子装置100-3确定话语结束的时间之间的相对时间差为2.6秒。这里,要执行最终匹配的第三电子装置100-3可以使用从第一电子装置100-1和第二电子装置100-2发送的相对时间信息来产生最终的识别结果。
图24是示出基于相对时间信息协调语音识别信息的另一个示例的图。
参考图24,电子装置100-1、100-2和100-3中的每一个都可以记录电子装置100-1、100-2、100-3中的每一个被激活的相对时间,同时激活另一电子装置100-3的语音识别功能,并且将所记录的相对时间发送到下一电子装置,并且所述相对时间信息可以用于匹配。当执行最终匹配的装置接收到时间信息时,执行最终匹配的装置可以基于时间信息列出和匹配语音识别信息以获得最终的识别结果。
图25是示出以帧为单位协调语音识别信息的又一个示例的图。
帧是用于从音频信号中提取特征信息的间隔单元,是语音识别的单元。帧可以是滑动窗的单元。例如,一个帧可以是25ms或10ms。图25的实施例类似于图23,但是使用帧单位而不是时间。
返回参考图10,任务模块125可以分析从语音识别模块122接收的文本数据以分析含义并执行适合于该含义的任务。任务模块125可以使用自然语言处理(natural languageprocessing,NLP)技术。
任务模块125可以基于所分析的含义标识要执行的任务。可以执行各种类型的任务,诸如播放音乐、行程安排、拨打电话、响应询问等。提供对询问的响应的任务可以是用于控制电子装置100或其他装置的任务,使得任务模块125响应于例如用户语音“今天天气怎么样?”而输出响应“今天可能会有雨”。
根据实施例,用于执行任务的人工智能代理程序可以被存储在电子装置100中。
人工智能代理程序可以是用于提供基于人工智能(AI)的服务(例如,语音识别服务、秘书服务、翻译服务、搜索服务等)的专用程序,并且可以由处理器(例如,CPU)或单独的AI专用处理器(例如,GPU等)执行。处理器110可以包括通用处理器或AI专用处理器中的至少一个。
特别是,人工智能代理程序可以包括对话系统,该对话系统能够用自然语言处理用户询问和响应。对话系统可以被配置为包括语音识别模块122和任务模块125。
图14是示出根据实施例的对话系统的框图。
图14所示的对话系统1400是用于通过自然语言执行与虚拟AI代理的对话的组件。根据实施例,对话系统1400可以被存储在电子装置100的存储器120中。然而,这仅仅是一个示例,并且被包括在对话系统1400中的模块中的至少一个可以被包括在至少一个外部服务器中。
如图14所示,对话系统1400可以包括自动语音识别(ASR)模块1410、自然语言理解(NLU)模块1420、对话管理器(DM)模块1430、自然语言生成器(NLG)模块1440和文本到语音(TTS)模块1450。另外,对话系统1400还可以包括路径规划模块或动作规划模块。
自动语音识别(ASR)模块1410可以将从电子装置100接收的用户输入转换成文本数据。例如,自动语音识别(ASR)模块1410可以包括话语识别模块。话语识别模块可以包括声学模型和语言模型。例如,声学模型可以包括与发音有关的信息,并且语言模型可以包括单位音素信息和关于单位音素信息的组合的信息。话语识别模块可以通过使用与发声相关的信息和单位音素信息将用户话语转换成文本数据。关于声学模型和语言模型的信息可以例如存储在自动语音识别数据库(ASR DB)1415中。
自然语言理解模块1420可以通过执行句法分析或语义分析来确定用户的意图。句法分析可以将用户输入划分为句法单元(例如,单词、短语、词素等),并且可以确定划分的单元具有哪些句法元素。语义分析可以通过使用语义匹配、规则匹配、公式匹配等来执行。因此,自然语言理解模块1420可以获得表示用户输入的意图所需的域、意图或参数(或时隙)。
自然语言理解模块1420可以通过使用划分为域的匹配规则来确定用户的意图和参数。例如,一个域(例如,警报)可以包括多个意图(例如,警报设置、警报清除等),并且一个意图可以包括多个参数(例如,时间、重复次数、警报声音等)。多个规则可以包括例如一个或多个必需的元素参数。匹配规则可以被存储在自然语言理解数据库(NLU DB)1423中。
自然语言理解模块1420可以通过使用诸如词素和短语等语言特征(例如,句法元素)来标识从用户输入中提取的单词的含义,并且通过将所标识的单词的含义与域和意图匹配来确定用户的意图。例如,自然语言理解模块1420可以通过计算在每个域和意图中包括多少从用户输入中提取的单词来确定用户的意图。根据实施例,自然语言理解模块1420可以通过为标识意图使用自然语言理解模块1420基于的单词来确定用户输入的参数。根据实施例,自然语言理解模块1420可以通过使用自然语言识别数据库1423来确定用户的意图,该数据库中存储了用于标识用户输入的意图的语言特征。
自然语言理解模块1420可以通过使用私有知识DB 1425来理解用户的询问。私有知识DB 1425可以基于输入到电子装置100的用户交互、用户的搜索历史、由电子装置100感测的感测信息或从外部装置接收的用户信息中的至少一个来学习知识信息之间的关系。在这种情况下,私有知识DB 1425可以以本体论(ontology)的形式存储知识信息之间的关系。
当添加新知识信息时,私有知识DB 1425可以从外部服务器接收新知识信息的附加信息,并且以本体论的形式存储知识信息和附加信息。另一方面,以本体论的形式存储知识信息的私有知识DB 1425仅仅是示例,并且私有知识DB 1425可以以数据集的形式存储信息。
自然语言理解模块1420可以通过使用私有知识DB 1425来确定用户的意图。例如,自然语言理解模块1420可以通过使用用户信息(例如,优选短语、优选内容、联系人列表、音乐列表等)来确定用户的意图。根据实施例,除了自然语言理解模块1420以外,自动语音识别模块1410还可以参考私有知识DB 1425来识别用户的语音。
自然语言理解模块1420可以基于用户输入的意图和参数生成路径规则。例如,自然语言理解模块1420可以基于用户输入的意图选择要执行的应用程序(app),并且确定要在选择的应用程序中执行的操作。自然语言理解模块1420可以通过确定与所确定的操作相对应的参数来生成路径规则。根据实施例,由自然语言理解模块1420生成的路径规则可以包括关于以下的信息:要执行的应用程序,要在该应用程序中执行的操作以及执行该操作所需的参数。
自然语言理解模块1420可以基于用户输入的意图和参数生成一个或多个路径规则。例如,自然语言理解模块1420可以从路径规划模块接收对应于电子装置100的路径规则集,并且通过将用户输入的意图和参数映射到接收的路径规则集来确定路径规则。在这种情况下,路径规则可以包括关于用于执行应用程序的功能的操作的信息或者关于执行该操作所需的参数的信息。另外,路径规则可以包括应用程序的操作顺序。电子装置可以接收路径规则,根据路径规则选择应用程序,并且在所选择的应用程序中执行被包括在路径规则中的操作。
自然语言理解模块1420可以通过基于用户输入的意图和参数而确定要执行的应用程序、要在该应用程序中执行的操作以及执行操作所需的参数来生成一个或多个路径规则。例如,自然语言理解模块1420可以生成路径规则,其方式通过使用电子装置100的信息,根据用户输入的意图,以本体论或图形模型的形式布置要执行的应用程序和要在应用程序中执行的操作。生成的路径规则可以例如通过路径规划器模块被存储在路径规则数据库中。生成的路径规则可以被添加到自然语言理解数据库1423的路径规则集中。
自然语言理解模块1420可以选择多个生成的路径规则中的至少一个。例如,自然语言理解模块1420可以在多个路径规则中选择最佳路径规则。作为另一个示例,当仅基于用户话语指定一些操作时,自然语言理解模块1420可以选择多个路径规则。自然语言理解模块1420可以通过用户的附加输入来确定多个路径规则中的一个路径规则。
对话管理器模块1430可以确定由自然语言理解模块1420所标识的用户的意图是否清楚。例如,对话管理器模块1430可以基于参数的信息是否充分来确定用户的意图是否清楚。对话管理器模块1430可以确定由自然语言理解模块1420标识的参数是否足以执行任务。根据实施例,当用户的意图不清楚时,对话管理器模块1430可以执行用于向用户请求必要信息的反馈。例如,对话管理器模块1430可以执行用于请求关于用于标识用户意图的参数的信息的反馈。
根据实施例,对话管理器模块1430可以包括内容提供者模块。当内容提供者模块基于由自然语言理解模块1420所标识的意图和参数执行操作时,内容提供者模块可以生成执行与用户输入相对应的任务的结果。
根据另一个实施例,对话管理器模块1430可以使用知识数据库1435提供对用户询问的响应。在这种情况下,知识数据库1435可以被包括在电子装置100中,但是这仅仅是一个示例,并且知识数据库1435可以被包括在外部服务器中。
自然语言生成器模块1440可以将指定的信息改变为文本形式。转化为文本形式的信息可以是自然语言话语的形式。所指定的信息可以是例如关于附加输入的信息、用于指导完成与用户输入相对应的操作的信息、或者用于指导用户的附加输入的信息(例如,用于用户输入的反馈信息)。改变为文本形式的信息可以显示在电子装置100的显示器上,或者可以由文本到语音(text-to-speech,TTS)模块1450改变为语音形式。
文本到语音模块1450可以将文本形式的信息改变为语音形式的信息。文本到语音模块1450可以从自然语言理解模块1440接收文本形式的信息,并将文本形式的信息改变为语音形式,以将语音形式的信息输出给扬声器。
自动语音识别模块1410可以被实现为图10的语音识别模块122,并且自然语言理解模块1420、对话管理器模块1430、自然语言生成器模块1440和文本到语音模块1450可以被实现为图10的任务模块125。
另一方面,图10的模块121、122、123和124中的至少一个可以被提供在外部装置中,而不是在电子装置100中。在这种情况下,电子装置100可以请求其他装置执行对应模块的功能。
通信器130可以通过例如无线通信或有线通信连接到网络以与外部装置通信。例如,作为蜂窝通信协议的无线通信可以使用长期演进(long-term evolution,LTE)、LTE先进(LTE Advance,LTE-A)、码分多址(code division multiple access,CDMA)、宽带CDMA(wideband CDMA,WCDMA)、通用移动通信系统(UMTS)、无线宽带(WiBro)或全球移动通信系统(universal mobile telecommunications system,GSM)中的至少一个。此外,无线通信可以包括例如短距离通信。短距离通信可以包括例如无线保真(WiFi)直接、蓝牙、近场通信(near field communication,NFC)或紫蜂(Zigbee)中的至少一个。有线通信可以包括例如通用串行总线(universal serial bus,USB)、高清晰度多媒体接口(HDMI)、推荐标准232(recommended standard 232,RS-232)或简易老式电话服务(POTS)中的至少一个。该网络可以包括诸如计算机网络(例如,局域网(LAN)或广域网(WAN))、因特网和电话网络的通信网络中的至少一个。
麦克风140是用于接收声音的组件。麦克风140可以将接收的声音转换成电信号。麦克风140可以与电子装置100集成地实现,或者与电子装置100分离。分离的麦克风140可以电连接到电子装置100。可以提供多个麦克风140。可以通过使用多个麦克风来检测用户的移动方向。
处理器110可以通过执行存储在存储器120中的计算机可执行指令来执行各种功能。
根据实施例,处理器110通过执行存储在存储器120中的计算机可执行指令可以:通过麦克风140获得包括预先确定的触发字的用户语音,基于被包括在用户语音中的触发字激活电子装置100的语音识别功能,在激活语音标识功能时检测用户移动的事件,并且基于检测到的事件控制通信器130将用于激活其他电子装置的语音识别功能的控制信号发送到其他电子装置。
此外,电子装置100可以包括用户输入接收器。用户输入接收器可以接收各种用户输入,例如,触摸输入、运动输入、按钮操纵等。例如,用户输入接收器可以包括按钮、触摸面板等。此外,电子装置100还可以包括用于显示各种信息的显示器。显示器可以包括例如发光二极管(LED)、液晶显示器(LCD)等。此外,电子装置100还可以包括相机。由相机捕获的图像可以用于确定用户的移动方向或衰减进入麦克风140的噪声。此外,电子装置100还可以包括扬声器。可以通过扬声器提供对用户询问的响应反馈。
图11是示出根据实施例的集线器装置200的配置的图。
参考图11,集线器装置200可以包括处理器210、存储器220和通信器230。
处理器210是用于控制集线器装置200的整体操作的组件。例如,处理器210可以驱动操作系统或应用程序来控制连接到处理器210的多个硬件或软件组件,并且可以执行各种数据处理和操作。处理器210可以是中央处理单元(CPU)或图形处理单元(GPU)或两者。处理器210可以被实现为通用处理器、数字信号处理器、专用集成电路(ASIC)、片上系统(SoC)、微型计算机(MICOM)等中的至少一个。
存储器220可以包括内部存储器或外部存储器。存储器220由处理器210访问,并且存储器220中的数据的读出、写入、校正、删除、更新等可以由处理器210执行。
存储器220可以包括被配置为一个或多个模块的软件和/或固件。该模块可对应于计算机可执行指令的集合。
存储器220可以包括语音识别模块221、移交模块222、匹配模块223和任务模块224。模块221、222、223和224可由处理器210执行以执行各种功能。
语音识别模块221可以执行与上述语音识别模块122相同的功能。
特别地,当通过通信器230从电子装置100接收到没有应用语言模型或声学模型的语音识别信息时,语音识别模块221可以通过将语言模型或声学模型应用到接收的语音识别信息来获得最终的识别结果。
移交模块222可以执行与上述移交模块123的功能相同的功能。
特别地,移交模块222可以检测用户移动并确定哪个电子装置100移交语音识别工作。例如,移交模块222可以接收从电子装置100或其他装置获得的用户移动信息,并且基于接收的用户移动信息检测用户移动。或者,集线器装置200自身可以具有能够检测用户的移动的配置(例如,多个麦克风、相机等)。
匹配模块223可以执行与上述匹配模块124的功能相同的功能。例如,匹配模块223可以按时间顺序匹配从电子装置100接收的语音识别信息,以便获得最终的识别结果。
任务模块224可以执行与上述任务模块125的功能相同的功能。例如,任务模块224可以基于最终的识别结果执行向电子装置100中的至少一个发送特定控制信号的任务。例如,当最终的识别结果是“今天天气怎么样?”,任务模块224可以执行向电子装置100发送输出“今天天气晴”的语音响应的控制信号的任务。
另一方面,集线器装置200还可以包括如图10所述的触发字模块121。例如,集线器装置200可以从电子装置100接收与用户语音相对应的音频信号,以检测音频信号中的触发字,并且可以将用于激活语音识别功能的控制信号发送到当检测到触发字时已经发送了对应音频信号的电子装置100。
图11的模块221、222、223和224中的至少一个可以被提供在外部装置中,而不是在集线器装置200中。在这种情况下,集线器装置200可以请求其他装置执行对应模块的功能。
通信器230可通过例如无线通信或有线通信连接到网络以与外部装置通信。例如,作为蜂窝通信协议的无线通信可以使用长期演进(LTE)、LTE先进(LTE-A)、码分多址(CDMA)、宽带CDMA(WCDMA)、通用移动通信系统(UMTS)、无线宽带(WiBro)或全球移动通信系统(GSM)中的至少一个。此外,无线通信可以包括例如短距离通信。短距离通信可以包括例如无线保真(WiFi)直接、蓝牙、近场通信(NFC)或紫蜂(Zigbee)中的至少一个。有线通信可以包括例如通用串行总线(USB)、高清晰度多媒体接口(HDMI)、推荐的标准232(RS-232)或简易老式电话服务(POTS)中的至少一个。该网络可以包括诸如计算机网络(例如,局域网(LAN)或广域网(WAN))、因特网和电话网络的通信网络中的至少一个。
处理器210可以通过执行存储在存储器220中的计算机可执行指令来执行各种功能。
根据实施例,处理器210通过执行存储在存储器220中的计算机可执行指令可以:通过通信器230从第一电子装置接收语音识别信息,该第一电子装置基于包括预先确定的触发字的用户语音激活语音识别功能,检测使用第一电子装置的用户移动的事件,控制通信器230基于检测到的事件向第二电子装置发送用于激活第二电子装置的语音识别功能的控制信号,通过通信器230从第二电子装置接收语音识别信息,并且控制通信器230基于从第一电子装置和第二电子装置接收的语音识别信息,将控制信号发送到第一电子装置和第二电子装置中的一个。
此外,集线器装置200可以包括用户输入接收器。用户输入接收器可以接收各种用户输入,例如,触摸输入、运动输入、按钮操纵等。例如,用户输入接收器可以包括按钮、触摸面板等。另外,集线器装置200还可以包括用于显示各种信息的显示器。显示器可以包括例如发光二极管(LED)、液晶显示器(LCD)等。另外,集线器装置200可以包括至少一个麦克风。集线器装置200可以识别通过麦克风接收的用户语音以执行与用户语音相对应的操作,并且可以通过使用多个麦克风来检测用户的移动方向。另外,集线器装置200还可以包括相机。由相机捕获的图像可用于确定用户的移动方向或衰减噪声。另外,集线器装置200还可以包括扬声器。可以通过扬声器提供对用户询问的响应反馈。
图12是示出根据实施例的服务器300的配置的图。
参照图12,服务器300可以包括处理器310、存储器320和通信器330。
处理器310是用于控制服务器300的整体操作的组件。例如,处理器310可以驱动操作系统或应用程序来控制连接到处理器310的多个硬件或软件组件,并且可以执行各种数据处理和操作。处理器310可以是中央处理单元(CPU)或图形处理单元(GPU)或两者。处理器310可以被实现为通用处理器、数字信号处理器、专用集成电路(ASIC)、片上系统(SoC)、微型计算机(MICOM)等中的至少一个。
存储器320可以包括内部存储器或外部存储器。存储器320由处理器310访问,并且存储器320中的数据的读出、写入、校正、删除、更新等可以由处理器310执行。
存储器320可以包括被配置为一个或多个模块的软件和/或固件。该模块可对应于计算机可执行指令的集合。
存储器320可以包括语音识别模块321、匹配模块322和任务模块323。模块321、322和323可由处理器310执行以执行各种功能。
语音识别模块321可以执行与上述语音识别模块122的功能相同的功能。
特别地,当通过通信器330从电子装置100或集线器装置200接收到未应用语言模型或声学模型的语音识别信息时,语音识别模块321可通过将语言模型或声学模型应用于接收的语音识别信息来获得最终的识别结果。
任务模块323可以执行与上述任务模块125的功能相同的功能。例如,任务模块323可以执行基于最终的识别结果向电子装置100中的至少一个发送特定控制信号的任务。例如,当最终的识别结果是“今天天气怎么样?”,任务模块323可以执行向电子装置100发送输出“今天天气晴”的语音响应的控制信号的任务。
另一方面,服务器300还可以包括如图10所述的触发字模块121。例如,服务器300可以从电子装置100接收与用户语音相对应的音频信号,以通过使用触发字模块121来检测音频信号中的触发字,并且可以将用于激活语音识别功能的控制信号发送到当检测到触发字时已经发送了对应音频信号的电子装置100。
另一方面,服务器300还可以包括如图10所述的移交模块123。例如,服务器300可以通过使用移交模块123接收从电子装置100或其他装置获得的用户移动信息,并且基于用户移动信息将语音识别工作移交给在用户移动方向上的电子装置100。
另一方面,可以在外部装置而不是服务器300中提供图12的模块321、322和323中的至少一个。在这种情况下,服务器300可以请求其他装置执行对应模块的功能。
通信器330可以通过例如无线通信或有线通信连接到网络以与外部装置通信。例如,作为蜂窝通信协议的无线通信可以使用长期演进(LTE)LTE先进(LTE-A)、码分多址(CDMA)、宽带CDMA(WCDMA)、通用移动通信系统(UMTS)、无线宽带(WiBro)或全球移动通信系统(GSM)中的至少一个。此外,无线通信可以包括例如短距离通信。短距离通信可以包括例如无线保真(WiFi)直接、蓝牙、近场通信(NFC)或紫蜂(Zigbee)中的至少一个。有线通信可以包括例如通用串行总线(USB)、高清晰度多媒体接口(HDMI)、推荐的标准232(RS-232)或简易老式电话服务(POTS)中的至少一个。该网络可以包括诸如计算机网络(例如,局域网(LAN)或广域网(WAN))、因特网和电话网络的通信网络中的至少一个。
处理器310可以通过执行存储在存储器320中的计算机可执行指令来执行各种功能。
根据实施例,处理器310通过执行存储在存储器320中的计算机可执行指令可以:通过通信器330从第一电子装置接收语音识别信息,该第一电子装置基于包括预先确定的触发字的用户语音激活语音识别功能,使用第一电子装置检测用户的移动,控制通信器330以基于检测到的移动向第二电子装置发送用于激活第二电子装置的语音识别功能的控制信号,通过通信器230从第二电子装置接收语音识别信息,并且控制通信器330以基于从第一电子装置和第二电子装置接收的语音识别信息,将控制信号发送到第一电子装置和第二电子装置中的一个。
图15至图17示出了与语音识别系统中与声学模型和语言模型的使用相关的各种实施例的图。
图15是示出与在语音识别系统2000中与声学模型和语言模型的使用相关的各种实施例的图。
语音识别系统可以包括多个电子装置100和服务器300。这里,符号“O”和“X”表示是否提供了声学模型AM和语言模型LM。
根据示例1.1,电子装置100不包括声学模型和语言模型。相反,服务器300包括声学模型和语言模型。因此,不应用声学模型和语言模型的语音识别信息(即音频信号自身或从音频信号中提取的特征信息)可以被发送到服务器300,并且服务器300可以通过应用声学模型和语言模型来执行语音识别。因此,可以减轻电子装置100中的语音识别的操作负担。
根据示例1.2,电子装置100可以向服务器300发送应用声学模型的语音识别信息。另外,服务器300可以通过应用语言模型来执行语音识别。
根据示例1.4,电子装置100可从其他装置接收应用声学模型的语音识别信息,并应用语言模型。
此外,服务器300可以通过将电子装置100未应用的语言模型和/或声学模型应用于语音识别信息来执行语音识别。因此,由于电子装置100仅执行用于语音识别的过程中的一些过程,因此可以减轻操作负担。另外,比较示例1.1、示例1.2和示例1.4,在示例1.1中,电子装置100可以简单地将音频信号或特征信息发送到服务器300。然而,语音识别性能可能恶化,因为在这里,通过简单地连接服务器300中的语音来继续进行语音识别,同时忽略电子装置100的记录特性的差异。例如,当电子装置100是冰箱时,考虑到在冰箱自身中生成的噪声,可以优选使用所学习的声学模型和语言模型。因此,可以为每个电子装置100存储专门用于每个电子装置的情况的声学模型和语言模型。因此,当电子装置100应用声学模型或语言模型中的至少一个来生成语音识别信息并将语音识别信息发送到服务器300时,可以提高服务器300处的最终语音识别性能。
另一方面,在示例1.1的情况下,当被实现为冰箱的电子装置100向服务器300发送音频信号或特征信息时,服务器300还可以发送请求应用适合于冰箱的语言模型和声学模型的信息。
示例1.3对应于电子装置100中包括声学模型和语言模型两者的情况,并且可以将声学模型和语言模型中的至少一个应用于语音识别信息并将语音识别信息发送到服务器300。
图16是示出与语音识别系统3000中的与声学模型和语言模型的使用相关的各种实施例的图。语音识别系统3000可以包括多个电子装置100和集线器装置200。
图16的示例2.1至2.4类似于上文参考图15描述的示例1.1至1.4,因此将省略其描述。
图17是示出与语音识别系统4000中与声学模型和语言模型的使用相关的各种实施例的图。语音识别系统4000可以包括多个电子装置100、集线器装置200和服务器300。
图17的示例3.1到3.16与上面参考图15描述的实施例1.1到1.4相似,只是还包括集线器装置200。
根据图17的示例,语音识别信息可以从电子装置100发送到集线器装置200,并且从集线器装置200发送到服务器300。这里,可以将语音识别信息移交给下一装置,而不管应用的声学模型和语言模型如何,这取决于每个装置的能力。具体地,在示例3.5至3.12的情况下,可以应用专门用于记录电子装置100的特性的声学模型或语言模型,同时减少电子装置100中的语音识别中的操作负担,因此,可以提高语音识别性能。
另一方面,即使在包括电子装置100的语音识别系统1000中,一些装置可能仅使用声学模型,而一些装置可能仅使用语言模型。在这种情况下,当特定电子装置将仅应用声学模型的语音识别信息发送到其他电子装置时,其他电子装置可以将语言模型应用到语音识别信息以获得最终的识别结果。
当电子装置100和集线器装置200向其他装置发送语音识别信息时,还可以发送指示语音识别的信息是否由声学模型和语言模型中的一个或其组合处理的信息。也就是说,例如,当电子装置100向集线器装置200发送语音识别信息时,也可以发送指示语音识别的信息是仅应用声学模型的信息的信息。
在上述实施例中,已经描述一个用户在电子装置100周围移动时发出语音的情况。类似地,即使在多个用户在电子装置100周围移动并发出语音的情况下,也可以根据前述实施例执行语音识别。然而,在这种情况下,多个用户的语音可以同时输入到一个电子装置100。因此,为了区分多个用户的语音,在移交语音识别工作时可能需要一起传送用户信息。
根据实施例,第一电子装置100-1可以通过包括触发字的用户语音激活语音识别功能,并且基于用户语音的特征来获得用户信息。这里,作为基于语音的特征来标识用户的信息的用户信息可以是语音特征信息。具体地,用户信息可以包括用于基于接收的语音信号通过分析发出声音信号的用户的独特特征来自动地确定谁是接收的语音信号的说话者的信息。换言之,语音识别可以分析声音信号的特征并基于接收的声音信号的分析的特征来标识用户。例如,当检测到在激活语音识别功能期间的用户移动时,第一电子装置100-1可以将获得的用户信息以及用于激活语音识别功能的控制信号发送到在用户的移动方向上的第二电子装置100-2。在这种情况下,发送的用户信息可以是从语音信号获得的特征信息或简档(profile)信息,诸如用户的ID、用户的姓名等。另外,当第二电子装置100-2在由从第一电子装置100-1接收的控制信号激活语音识别功能之后通过麦克风140接收多个用户语音时,第二电子装置100-2可以在多个用户语音中标识与从第一电子装置100-1接收的用户信息相对应的用户语音,并且对所标识的用户语音执行语音识别。另外,第二电子装置100-2可以标识与从第三电子装置100-3接收的用户信息相对应的用户语音,并且对所标识的用户语音执行语音识别。因此,可以处理多个用户语音中的每一个。这将参照图26进一步描述。
图26是示出当存在多个用户时通过多个电子装置100执行语音识别实施例的图。
参考图26,用户A在从卧室移动到客厅时发出“今晚什么时候足球开始”,并且用户B在从厨房移动到客厅时发出“什么时候昨天订购的包裹到达?”。
当卧室中的第一电子装置100-1由用户A激活语音识别功能并且用户A移动到客厅时,第一电子装置100-1也在激活客厅中的第二电子装置100-2时发送关于用户A的用户信息。
当厨房中的第三电子装置100-3由用户B激活语音识别功能并且用户B移动到客厅时,第三电子装置100-3也在激活客厅中的第二电子装置100-2时发送关于用户B的用户信息。
在客厅中的第二电子装置100-2中,可以发生从用户A和用户B同时输入语音的情况。在这种情况下,第二电子装置100-2可以分别基于从第一电子装置100-1和第三电子装置100-3接收的关于用户A的用户信息和接收的关于用户B的用户信息来标识用户A的语音和用户B的语音。例如,第二电子装置100-2可以从所接收的音频信号中分离出与关于用户A的用户信息相对应的音频信号和与关于用户B的用户信息相对应的音频信号。
例如,电子装置100-2可以通过使用独立分量分析技术将对应于用户A的声源和对应于用户B的声源从音频信号中分离出。这里,可以使用用户A和用户B的方向来分离声源。可以使用提供在第二电子装置100-2中的两个或更多个麦克风或者使用提供在第二电子装置100-2中的相机来标识每个用户A和用户B的方向。
因此,第二电子装置100-2可以单独地对每个用户执行识别。
此外,第二电子装置100-2可以分别生成用户A的语音识别信息和用户B的语音识别信息。第二电子装置100-2可以从第一电子装置100-1接收关于用户A的语音识别信息,并且将由第二电子装置100-2生成的关于用户A的语音识别信息与接收的关于用户A的语音识别信息匹配,以获得第一最终的识别结果。另外,第二电子装置100-2可以从第三电子装置100-3接收关于用户B的语音识别信息,以及将由第二电子装置100-2生成的关于用户B的语音识别信息与接收的关于用户B的语音识别信息匹配,以获得第二最终的识别结果。
第二电子装置100-2可以基于第一最终的识别结果向用户A提供反馈。例如,第二电子装置100-2可通过扬声器输出语音响应“今晚足球9点开始”。另外,第二电子装置100-2可以基于用户B的第二最终的识别结果提供反馈。例如,第二电子装置100-2可以通过扬声器输出语音响应“昨天订购的包裹将在明天发货”。
因此,即使在多个用户在移动时发出语音的情况下,也可以分别处理每个用户语音。
此外,即使当多个用户同时发出声音时,也可以在每个装置中选择性地使用声学模型和语言模型,如参考图15至17所描述的实施例中所示。
另一方面,在上述实施例中,仅描述了用户提问并立即接收响应的单回合场景,但是这些实施例也可以应用于多回合场景。
例如,参考图27,在用户在第一电子装置100-1中结束第一话语“今天天气怎么样?”之后,第一电子装置100-1可以提供诸如“今天天气晴”的响应。此外,当用户在第一话语结束之后的特定时间内在第二电子装置100-2中发出“明天呢?”,第二电子装置100-2可以参考第一话语“今天天气如何?”提供响应“明天会有雨”,以输入到第一个电子装置100-1。
这里,第一电子装置100-1还可以当将语音识别工作移交给第二电子装置100-2时发送用户信息和用户语音的上下文信息。上下文信息可以是关于对话主题和类别的信息。例如,“今天天气怎么样?”的上下文信息可以包括诸如“天气”和“询问”的信息。参考从第一电子装置100-1接收的用户信息和上下文信息,可以确定对话继续,并且可以评估先前的对话以提供适当的下一响应。例如,第二电子装置100-2可以检查在从第一电子装置100-1中第一话语结束的时间起的预先确定时间内是否接收到与从第一电子装置100-1接收的用户信息相对应的语音,并且当接收到相应的语音时,可以基于上下文信息为对应的语音提供响应。
此外,即使在如上所述的多回合的实施例中,声学模型和语言模型也可以在每个装置中有选择地使用,如参考图15至17所述的实施例中。
尽管描述了当检测到用户移动的事件时,可以将语音识别工作移交给其他装置,当确定除了用户移动的事件以外还适合于其他装置继续地执行语音识别时,可以移交语音识别工作。
根据实施例,当确定声音输入包括高于预先确定的水平的噪声时,电子装置100可以向其他电子装置发送用于激活语音识别功能的控制信号。这里,将参照图28描述实施例。
图28是示出根据实施例的语音识别工作的切换发生的场景的图。
参照图28,TV靠近第一电子装置100-1并且在用户发出触发字并且激活第一电子装置100-1的语音识别功能时是打开的。当第一电子装置100-1检测到用户的单词由于电视的声音而不易被识别时,第一电子装置100-1可以选择语音识别工作可以移交到的装置,使得选择的装置更接近用户所在的位置,或其他外围装置。当选择第二电子装置100-2作为语音识别工作要移交到的装置时,第一电子装置100-1可以向第二电子装置100-2发送用于激活语音识别功能的控制信号。然后,第二电子装置100-2可以继续执行语音识别。
图29是示出根据另一个实施例的语音识别工作的切换发生的场景的图。
在图29中,电子装置100被实现为导航100-1和移动装置100-2。
在用户下车或停车的情况下,用户可以向导航100-1发出“Bixby,请发短信给HongGil Dong来预定今天5点在Yangjae站Hawpo餐厅的6个座位”,并且导航100-1可以识别触发字“Bixby”,并且可以开始语音识别。然而,在某些情况下,导航100-1可能不是可靠的装置,因为当车辆关闭时导航100-1的电源可能被关闭,并且因此,导航100-1可能需要在车辆关闭之前将语音识别工作移交给移动装置100-2。因此,例如,当车辆的速度低于预先确定速度并且检测到向后行驶时,导航100-1可以确定车辆处于停车模式并且将语音识别工作移交给移动装置100-2。这样,导航装置100-1可以向移动装置100-2发送语音识别信息。此外,导航100-1还可以发送用于匹配的用户信息和附加信息,诸如时间信息、记录特性、关于语音识别进展状态的信息等。
因此,在用户下车后,语音识别可以继续,并且当话语结束时,移动装置100-2可以将从导航100-1接收的语音识别信息与由移动装置100-2检测到的语音识别信息匹配,以获得最终的语音识别结果,并且可以基于最终语音识别结果执行任务。
另一方面,通过考虑装置的电池状态,也可以将语音识别工作移交给外围装置。也就是说,当装置的电池保持低于预先确定的电池寿命时,可以将语音识别工作移交给具有更长电池寿命的其他装置。
图30是示出根据实施例的用于控制电子装置的方法的流程图。
参照图30,电子装置100可以通过电子装置100的麦克风获得包括预先确定的触发字的用户语音(S3010)。基于确定用户语音包括预先确定的触发字,电子装置100可以激活电子装置100的语音识别功能(S3020)。此外,电子装置100可以检测在激活语音识别功能时用户移动的事件(S3030)。此后,电子装置100可以基于检测到的事件向其他电子装置发送用于激活其他电子装置的语音识别功能的控制信号(S3040)。
在S3030中,电子装置100可以基于在语音识别功能被激活之后通过麦克风获得的用户语音的信号来检测用户移动的事件。另一方面,事件可以基于通过麦克风获得的语音的信号来检测,但是也可以通过使用诸如相机等的其他传感器来检测。
在S3040中,电子装置100可以使用关于可以接收语音的多个其他电子装置的预存储信息来发送控制信号。例如,当检测到用户移动的事件时,电子装置100可以获得用户的移动信息,基于用户的移动信息在多个其他电子装置中标识最接近用户的其他电子装置,并且将控制信号发送到所标识的其它电子装置。
另一方面,用于控制电子装置100的方法还可以包括通过对通过麦克风获得的用户语音执行语音识别来获得第一语音识别信息的操作,从接收控制信号的其他电子装置接收第二语音识别信息的操作,以及基于第一语音识别信息和第二语音识别信息获得最终的识别结果的操作。
在这种情况下,可以获得包括控制信号被发送到其他电子装置的时间的时间信息,并且可以基于所获得的时间信息来匹配第一语音识别信息和第二语音识别信息,以获得最终的识别结果。这里,所获得的时间信息可以包括关于发送控制信号的绝对时间的信息,或者基于激活电子装置100的语音识别功能的时间的关于将控制信号发送到其他电子装置的相对时间的信息。
此外,当从其他电子装置接收的第二语音识别信息是应用声学模型而不应用语言模型的语音识别信息时,电子装置100可以将可预先存储在电子装置中的语言模型应用于第二语音识别信息,以获得最终的识别结果。当从其他电子装置接收的第二语音识别信息是不应用声学模型和语言模型两者的语音识别信息时,电子装置100可以将可预先存储在电子装置中的声学模型和语言模型应用于第二语音识别信息,以获得最终的识别结果。
此外,电子装置100可以将用于向其他电子装置提供关于最终的识别结果的反馈的控制信号发送到其他电子装置。
或者,当从其他电子装置接收到用于激活电子装置100的语音识别功能的第二控制信号时,电子装置100可以激活电子装置100的语音识别功能。
在这种情况下,电子装置100可以从其他电子装置接收用户信息,当在语音识别功能被第二控制信号激活之后通过麦克风接收到多个用户语音时,在多个用户语音中标识与从其他电子装置接收的用户信息相对应的用户语音,并且对所标识的用户语音执行语音识别。
另一方面,电子装置100可以对通过麦克风在由第二控制信号激活语音识别功能之后直到用户的话语结束所接收的语音执行语音识别以获得语音识别信息,并且可以将所获得的语音识别信息发送到其他电子装置。
此外,当通过麦克风接收到包括预先确定触发字的第一用户的语音并且激活语音识别功能的状态下,从其他电子装置接收到第二控制信号和关于第二用户的信息时,电子装置100可以分别处理通过麦克风获得的第一用户的语音和第二用户的语音。
根据上述实施例,当预期语音识别的质量可能随着用户移动或周围环境的变化而降低时,当前装置可以估计方向和距离,并向在当前装置的方向上要接管语音识别的其他装置发送信号,从而继续地执行语音识别。因此,每个装置可以执行语音识别并且组合识别结果以基于识别结果生成对应的响应。此外,当接管语音识别时,还可以发送关于记录特性等的信息以帮助生成最终的结果。
根据上述实施例,装置可以选择要主动接管语音识别的其他装置,因此即使在记录质量降低、无法进行记录,或者当用户移动时的情况下,多个装置可以协作以继续平滑地执行语音识别。
下文中,将参考图31至图37描述在用户移动的情况下处理从多个装置收集的语音的实施例。
参考图31和图32,边缘计算装置20可以匹配分别从第一音频接收装置10-1和第二音频接收装置10-2接收的音频信号,以执行语音识别。
具体地,边缘计算装置20可以从第一音频信号收集装置10-1接收根据用户的语音的音频信号。另外,当基于从第一音频信号收集装置10-1接收的音频信号中包括的信息检测到用户的移动时,边缘计算装置20可以向第二音频信号收集装置10-2发送控制信号,该控制信号用于从位于用户的移动方向上的第二音频信号收集装置10-2根据用户的语音接收音频信号。另外,边缘计算装置20可以从第二音频信号收集装置10-2接收音频信号,并且将从第一音频信号收集装置10-1接收的音频信号与从第二音频信号收集装置10-2接收的音频信号进行匹配,以对用户的语音执行语音识别。
图31是示出根据用户的移动来匹配从多个音频信号收集装置接收的音频信号的过程的图。
如图31所示,音频信号收集装置10-1至10-7以及边缘计算装置20-1和20-2可以被布置在家中。在下文中,音频信号收集装置10-1至10-7可对应于上述实施例中的电子装置100-1、100-2、…100-N。因此,电子装置100-1、100-2、…100-N的描述也可以应用于音频信号收集装置10-1到10-7。另外,边缘计算装置20-1和20-2可以对应于上述实施例中的集线器装置200。因此,上述集线器装置200也可以应用于边缘计算装置20-1和20-2。
边缘计算装置20-1至20-2是实现边缘计算技术的装置,边缘计算技术是通过现有服务器补充云计算的限制的技术。特别是,随着IoT装置中数据量的增加和实时处理变得重要,服务器的云计算有一定的局限性。在边缘计算技术中,可以执行先前在服务器上执行的一些计算任务或所有计算任务。边缘计算是一种在IoT装置附近或IoT装置自身中分布数据的技术,并且可以比现有的云计算技术更快地处理数据。因此,在其上实现边缘计算技术的边缘计算装置20-1至20-2可以更有效地本地处理从音频信号收集装置10-1至10-7接收的数据。
音频信号收集装置10-1至10-7(以下统称为“音频信号收集装置10”)和边缘计算装置20-1至20-2(以下统称为“边缘计算装置20”)是具有计算能力的装置,并且可以包括用于存储计算机可执行指令的存储器和能够执行指令以执行特定功能的处理器。因此,下面描述的音频信号收集装置10的功能由音频信号收集装置10的处理器实现,并且边缘计算装置20的功能可以由边缘计算装置20的处理器实现。
音频信号收集装置10可以包括麦克风。音频信号收集装置10可以通过麦克风接收用户的语音,并将与接收的语音相对应的音频信号发送到边缘计算装置20中的至少一个。另外,边缘计算装置20可以对从各种音频信号收集装置10接收的音频信号执行语音识别。
根据实施例,当用户在家中移动时发声时,音频信号收集装置10可以接收语音并将与接收的语音相对应的音频信号发送到边缘计算装置20中的至少一个,并且边缘计算装置20中的至少一个可以执行按照话语的顺序连接从音频信号收集装置10-1至10-7接收的音频信号的匹配处理,以获得最终的语音识别结果。
音频信号收集装置10可以在通过麦克风获得的音频信号中检测语音。例如,可以通过语音活动检测(VAD)和/或端点检测(EPD)技术来分离语音部分、噪声部分和背景噪声。VAD技术是可以基于频域中的音量或能量分布,使用统计模型、深度学习模型等来检测人的声音的技术,并且EPD技术是用于检测声音中人的声音的端点的技术。
当从通过被包括在音频信号收集装置10中的麦克风获得的音频信号中检测到语音时,音频信号收集装置10可以向边缘计算装置20中的至少一个发送音频信号。这里,当所获得的音频信号总是被发送到边缘计算装置20时,可能出现传输负担。因此,为了减轻音频信号收集装置10和边缘计算装置20两者的传输负担,可以仅在需要语音识别时才发送音频信号。
根据另一个实施例,即使在通过麦克风获得的音频信号中没有检测到语音部分,音频信号收集装置10也可以通过边缘计算装置20的控制来激活音频信号传输操作。例如,边缘计算装置20可以基于从音频信号收集装置10-1接收的音频信号的质量(诸如功率和/或信噪比(SNR)降低)来确定用户正在移动。在这种情况下,边缘计算装置20可以请求可能更接近用户的音频信号收集装置10-2发送可以具有更好质量的音频信号。
音频信号收集装置10还可以包括相机。音频信号收集装置10可以通过分析通过相机获得的图像来检测用户的移动。例如,音频信号收集装置10可以识别通过相机获得的图像中的对象,并且通过跟踪所识别的对象来检测用户的移动。
根据又一个实施例,音频信号收集装置10可以将通过相机获得的图像发送到边缘计算装置20中的至少一个。在这种情况下,边缘计算装置20中的至少一个可以通过分析图像来识别对象,并且通过跟踪所识别的对象来检测用户的移动。另外,边缘计算装置20还可以包括相机,并且可以基于所获得的图像来检测用户的移动。
此外,边缘计算装置20可以基于通过边缘计算装置20中包括的多个麦克风输入的用户语音的振幅差来检测用户移动。或者,边缘计算装置20可以基于从具有多个麦克风的音频信号收集装置10接收的音频信号中的用户语音的振幅差来检测用户的移动。
另一方面,边缘计算装置20可以获得通过被包括在音频信号收集装置10中的多个麦克风输入的用户语音信号的方向信息,并且还可以基于所获得的方向信息检测用户的移动。具体地,多个麦克风可以被实现为麦克风阵列,其中多个麦克风以相等间隔或变化的间隔对准。另外,可以通过使用麦克风阵列的到达方向(Direction of Arrival,DOA)技术来获得用户语音信号的方向信息。
这里,DOA技术可以是指使用通过麦克风阵列中包括的多个麦克风中的相应麦克风接收的语音信号之间的相关性来获得语音信号的方向信息的技术。具体地,根据DOA技术,当在多个麦克风处以特定入射角接收语音信号时,边缘计算装置20可以基于到达被包括在多个麦克风中的每个麦克风的语音信号的延迟距离和延迟时间,来获得语音信号的入射角,并且基于所获得的入射角来获得关于所接收语音信号的方向信息。
音频信号收集装置10还可以包括扬声器,并且可以通过扬声器输出对用户语音的响应。例如,边缘计算装置20可以向音频信号收集装置10发送与语音识别结果相对应的响应语音,并且响应语音可以从音频信号收集装置10输出。
边缘计算装置20可以包括触发字模块和语音识别模块。触发字模块可以识别音频信号中的预先确定的触发字或短语,并且在识别触发字时激活语音识别模块。触发字可以是预先确定的字或句子。例如,可以使用“Hi Bixby”等。
根据实施例,边缘计算装置20可以根据从多个音频信号收集装置10接收的音频信号来识别触发字。
图32是示出根据实施例的用于通过边缘计算装置20根据从多个音频信号收集装置接收的音频信号来识别触发字的方法的图。
边缘计算装置20可以包括触发字模块3210和语音识别模块3220,它们是存储在存储器中的软件模块。边缘计算装置20的处理器可以执行这样的软件模块来执行触发字识别和语音识别功能。
参考图32,当用户在从第一音频信号收集装置10-1移动到第二音频信号收集装置10-2时说“Hi Bixby”时,第一音频信号收集装置10-1和第二音频信号收集装置10-2可以检测语音并将音频信号发送到边缘计算装置20。音频信号可以以帧单位(例如,20ms)来配置。
在这种情况下,触发字模块3210可以在第一方法和第二方法之一中识别触发字。然而,在本公开中,触发字模块3210和语音识别模块3220的分离是为了更清楚地描述边缘计算装置20的操作。这里描述的第一方法和第二方法也可以由语音识别模块3220执行。
根据第一方法,边缘计算装置20的触发字模块3210可以从连接到边缘计算装置20的音频信号收集装置10-1和10-2中的每一个接收音频信号。触发字模块3210可以比较由从音频信号收集装置10-1和10-2中的每一个接收的音频信号构成的每个帧的信号的功率和/或信噪比(SNR),以标识对语音识别更好的帧,即具有更高功率和/或信噪比的帧。例如,当优选地从第一音频信号收集装置10-1接收到与“Hi”部分相对应的帧,并且优选地从第二音频信号收集装置10-2接收到与“Bixby”部分相对应的帧时,触发字模块3210可以使用与从第一音频信号收集装置10-1接收的“Hi”部分对应的帧以供语音识别,并且可以使用与从第二音频信号收集装置10-2接收的“Bixby”部分对应的帧以供语音识别。具体地,可以在从第一音频信号收集装置10-1接收的音频信号中标识适于语音识别的帧,并且可以在从第二音频信号收集装置10-2接收的音频信号中标识适于语音识别的帧,使得以时间顺序匹配所标识的帧,并且可以基于匹配的帧来识别触发字。例如,参考图32的图3230,触发字模块3210可以标识具有大于或等于预先确定的值3235的功率或信噪比的帧,匹配所标识的帧,并且基于匹配的帧识别触发字。
具体地,当从音频信号收集装置10-1和10-2接收到音频信号时,触发字模块3210可以比较从第一音频信号收集装置10-1接收的音频信号的帧和从第二音频信号收集装置10-2收集的帧的功率和/或信噪比(SNR),以标识更适于识别的帧,将所标识的帧按时间顺序进行匹配,并基于匹配的帧来表示触发字。
用于比较从音频信号收集装置接收的音频帧的单元可以是以一帧为单位的功率和/或信噪比(SNR),或者可以是以N帧为单位的功率和/或信噪比(SNR),这取决于设置。根据第二方法,当确定从第一音频信号收集装置10-1接收的音频信号中语音减少时,边缘计算装置20可以激活第二音频信号收集装置10-2。激活是请求第二音频信号收集装置100-2发送音频信号。
具体地,除了上述第一方法以外,当确定在特定时间从第二音频信号收集装置10-2接收的音频信号的帧比从第一音频信号收集装置10-1接收的音频信号的帧更好时,触发字模块3210可以匹配从第一音频信号收集装置10-1接收的音频信号的帧直到特定时间为止,并且在特定时间之后匹配从第二音频信号收集装置10-2接收的音频信号的帧。因此,可以基于匹配的帧更准确地识别被包括在音频信号中的触发字。例如,参考图32的图3240,触发字模块3210可以标识具有大于或等于预先确定的值3245的功率或信噪比的帧,匹配所标识的帧,并且基于匹配的帧识别触发字。
根据上述实施例,即使用户在移动时发出触发字,也具有可以准确识别触发字的优点。
在触发字模块3210以上述方式识别触发字之后,触发字模块3210可以激活语音识别模块3220。
当触发字模块3210被激活时,语音识别模块3220可以执行语音识别。语音识别模块3220可以将与用户语音相对应的音频信号转换成字串或文本。
参照图33,语音识别模块3220通常可以包括提取语音的特征部分的过程、将提取的特征信息传递给声学模型(AM)的过程和/或将通过声学模型传递的信息传递给语言模型的过程。
具体地,语音识别模块3220可以从音频信号中提取特征信息。例如,语音识别模块3220可以从音频信号提取包括倒谱、线性预测系数(LPC)、梅尔频率倒谱系数(MFCC)和滤波器组能量中的至少一个的特征信息。
语音识别模块3220可以通过声学模型(AM)传递特征信息来获得发音串、字符串和字串。
语音识别模块3220还可以包括语言模型(LM)。语言模型可用于补充通过声学模型获得的信息。例如,当用户说“it’s very hot please lower the temperature of theair conditioner(天气很热,请降低空调温度)”时,如果仅通过声学模型进行语音识别,“ondo”(韩语中的“温度”)可能会被错误地标识为“uundong”(韩语中的“练习”)。语言模型分析单词之间的关系,以增加组合具有较高关系的单词的似然性,从而可以防止单词被错误识别的问题。换言之,在句子或短语的上下文中更相关的词更有可能被使用或被给予更高的关系得分。
另一方面,当从第一音频信号收集装置10-1接收的音频信号的质量降低时,边缘计算装置20可以检测到用户已经移动,并且可以激活在用户的移动方向上的第二音频信号收集装置10-2。换言之,边缘计算装置20可以请求第二音频信号收集装置10-2进一步发送从用户接收的音频信号。
另一方面,边缘计算装置20可以使用人工智能模型确定哪个音频信号收集装置位于用户的移动方向。这里,人工智能模型可以包括至少一个人工神经网络,并且可以通过深度学习来学习。具体地,人工智能模型可以包括深度神经网络(DNN)、卷积神经网络(CNN)、递归神经网络(RNN)和生成对抗网络(GAN)中的至少一个人工神经网络。然而,被包括在人工智能模型中的人工神经网络模型不限于此。
例如,当从第一音频信号收集装置10-1接收的音频信号的质量降低时,边缘计算装置20可能没有信息来确定需要第一次激活哪个其他音频信号收集装置,并且可能因此激活所有音频信号收集装置。然后,当从所有音频信号收集装置接收的音频信号中,相同用户的语音在从第二音频信号收集装置10-2接收的音频信号中并且音频信号的质量更好时,可以确定用户从第一音频信号收集装置10-1移动到第二音频信号收集装置10-2。这种情况可能要学很多次。因此,当重复学习之后发生相同情况时,边缘计算装置20可以仅激活特定音频信号收集装置而不是激活所有音频信号收集装置。
尽管上面没有描述,但是可以存在使用音频信号的质量、通过多个麦克风获得的音频信号中的振幅差、通过相机获得的图像的其他方法。
边缘计算装置20可以按时间顺序匹配相同用户在从不同音频信号收集装置10接收的音频信号上的语音。具体地,边缘计算装置20可以从期望具有高语音识别准确度的不同音频信号收集装置10来收集和连接不同的音频信号。在这种情况下,也可以以帧为单位(或以固定时间为单位)来剪切和连接用户的语音,并且无论帧的单位或特定时间如何也都可以基于通过声学模型或语言模型的结果的得分来连接具有某一水平或更高得分的那些语音。这里,得分是指示通过声学模型或语言模型的音频信号的准确度的概率值。例如,得分为0.8意味着准确率为80%。将参考图34至37描述由边缘计算装置20执行的详细匹配方法。
图34至37是示出根据各种实施例的边缘计算装置20中的匹配方法的图。
在下文中,将根据以下假设描述匹配方法:边缘计算装置20分别从第一音频信号收集装置10-1和第二音频信号收集装置10-2接收音频信号,对准所接收的音频信号,并且比较对准的音频信号。这里,对准所接收的音频信号的准则可以是接收到音频信号的时间,或者发音串或字符串的相似性。将在基于接收到音频信号的时间对准所接收的音频信号的假设下详细描述图34至图36。随后将参考图37描述其中基于发音串或字符串的相似性来对准接收的音频信号的实施例。
在下文中,将根据以下假设描述匹配方法:边缘计算装置20从第一音频信号收集装置10-1接收音频信号,并且在检测到用户的移动之后从第二音频信号收集装置10-2以及第一音频信号收集装置10-1接收音频信号。因此,显然,由于边缘计算装置20基于检测到的用户的移动来激活第二音频信号收集装置10-2,因此下面描述的匹配方法是有问题的。
图34是示出基于获得音频信号的时间匹配多个音频信号的实施例的图。
参照图34,边缘计算装置20可以根据用户语音从第一音频信号收集装置10-1接收音频信号,并且当检测到用户的移动时激活第二音频信号收集装置10-2。另外,边缘计算装置20可以匹配在激活第二音频信号收集装置10-2的时间3410之前从第一音频信号收集装置10-1接收的音频信号,并且可以匹配在时间3410之后从第二音频信号收集装置10-2接收的音频信号。在这种情况下,可以以帧为单位(或以固定时间为单位)匹配音频信号。
具体地,如图34所示,当用户的语音是“it’s very hot,please lower thetemperature of the air conditioner(很热,请降低空调的温度)”(3420)时,边缘计算装置20可以从第一音频信号收集装置10-1接收与用户语音“it’s very hot(很热)”(3430)相对应的音频信号,并且可以在激活第二音频信号收集装置10-2的时间3410之后从第二音频信号收集装置10-2接收与用户语音“please lower the temperature of the airconditioner(请降低空调的温度)”(3440)相对应的音频信号。此外,边缘计算装置20可以匹配在第二音频信号收集装置10-2被激活的时间3410之前从第一音频信号收集装置10-1接收的与“it’svery hot”(3430)相对应的音频信号和从第二音频信号收集装置10-2接收的与“please lower the temperature of the air conditioner”(3440)相对应的音频信号。
在上述实施例中,多个音频信号基于激活第二音频信号收集装置的时间3410进行匹配,但更清楚地说,在第二音频信号收集装置被激活之后,边缘计算装置20根据用户语音从第二音频信号收集装置接收音频信号的时间可以是用于匹配多个音频信号的准则。不过,为了方便起见,第二音频信号收集装置被激活的时间3410和边缘计算装置20根据用户语音从第二音频信号收集装置接收音频信号的时间被称为第二音频信号收集装置被激活的时间3410。
图35是示出基于接收的音频信号的质量匹配多个音频信号的实施例的图。
根据实施例,代替简单地将在第二音频信号收集装置10-2的激活时间3510之前接收的音频信号与在第二音频信号收集装置10-2的激活时间之后接收的音频信号进行匹配,还可以基于多个接收音频信号的质量来匹配多个接收音频信号。
具体地,边缘计算装置20可以基于多个所接收的音频信号的功率和/或信噪比,在由从相应的音频信号收集装置10-1和10-2接收的音频信号构成的多个帧中标识每个信号的质量处于某一水平或更高的帧,并且可以匹配所标识的帧。
例如,如图35所示,当用户的语音是“it’s very hot,please lower thetemperature of the air conditioner”(3520)时,边缘计算装置20可以从第一音频信号收集装置10-1接收与一部分用户语音“it’s very hot”(3530)相对应的音频信号,并且可以在激活第二音频信号收集装置10-2的时间3510之后,从第二音频信号收集装置10-2接收与另一部分用户语音“hot,please lower the temperature of the air conditioner(热,请降低空调的温度)”(3540)相对应的音频信号。
此外,边缘计算装置20可以基于所接受的音频信号的功率和/或信噪比,在与从第一音频信号收集装置10-1和第二音频信号收集装置10-2两者接收的用户语音“hot(热)”相对应的音频信号中标识具有相对高质量的音频信号的音频信号。例如,当与用户语音“hot”相对应的从第二音频信号收集装置10-2接收的音频信号与从第一音频信号收集装置10-1接收的音频信号相比具有相对较高的质量信号时,边缘计算装置20可以匹配从第一音频信号收集装置10-1接收的与“it’s very(很)”相对应的音频信号和从第二音频信号收集装置10-2接收的与“hot,please lower the temperature of the air conditioner”相对应的音频信号。
图36是示出基于通过语言模型或声学模型获得的得分匹配多个音频信号的实施例的图。
边缘计算装置20可以将多个所接收的音频信号输入到声学模型或语言模型,通过声学模型或语言模型获得发音串、字符串或字串的得分,并且基于所获得的得分匹配多个音频信号。这里,得分是关于音频信号的语音识别结果的概率信息,并且具体地是指示通过声学模型或语言模型获得的音频信号的准确度的概率值。
例如,如图36所示,当用户的语音是“it’s very hot,please lower thetemperature of the air conditioner”(3620)时,边缘计算装置20可以从第一音频信号收集装置10-1接收与用户语音“it’s very”(3630)相对应的音频信号,并在激活第二音频信号收集装置10-2的时间3610之后从第二音频信号收集装置10-2接收与用户语音“hot,please lower the temperature of the air conditioner”(3640)相对应的音频信号。
另一方面,除了图34和图35以外,图36还示出了通过声学模型或语言模型获得的得分3650、3660和3670。具体地,边缘计算装置20可以获得用于从第一音频收集装置10-1接收的音频信号的得分3650和用于从第二音频收集装置10-2接收的音频信号的得分3660。另外,如果预先确定仅使用与0.6或更高的得分相对应的帧进行匹配,则可以如图36所示确定与用于匹配的音频信号相对应的得分3670。
此外,边缘计算装置20可以使用与从第一音频收集装置接收的音频信号中的一部分用户语音“it’s very hot,please”的相对应的帧、以及与从第二音频信号收集装置接收的音频信号中的另一部分用户语音“lower the temperature of the air conditioner”相对应的帧来匹配音频信号。
另一方面,边缘计算装置20可以包括多个语音识别模块,以对从多个音频信号收集装置10接收的音频信号执行快速语音识别。另外,可以在多个语音识别模块中并行地执行语音识别。
具体地,边缘计算装置20可以将从第一音频信号收集装置10-1所接收的音频信号和从第二音频信号收集装置10-2所接收的音频信号输入到边缘计算装置20中包括的多个语音识别模块中的每一个,实时比较由多个语音识别模块并行所获得的得分,并且在从多个音频信号收集装置接收的音频信号中匹配得分较高的语音识别结果。
此外,上面已经描述了在一个边缘计算装置20中执行语音识别情况,但是根据实施例,为了提高语音识别速度和效率,可以通过综合利用多个边缘计算装置20的语音识别模块来执行语音识别。
具体地,多个边缘计算装置20可以分别从第一音频信号收集装置10-1和第二音频信号收集装置10-2接收音频信号。另外,多个边缘计算装置20可以将所接收的音频信号输入到被包括在每个边缘计算装置20中的语音识别模块,并将相应地获得的得分发送到多个边缘计算装置20中的一个。多个边缘计算装置20中的从多个边缘计算装置20接收得分的一个可以实时比较从多个边缘计算装置20并行获得的得分,并且匹配从多个音频信号收集装置接收的音频信号中具有较高得分的语音识别结果,以获得语音识别结果。
另外,当边缘计算装置20的语音识别处理的结果不准确时,也可以在具有更优秀的计算能力的外部服务器(例如,上述实施例的服务器300)中再次处理语音识别。具体地,当由边缘计算装置20接收的语音信号的质量低时,或者当通过语音模型或语言模型对音频信号处理的语音识别得分低时,可以确定语音识别处理结果不准确,并且也可以在具有更优秀计算能力的外部服务器中再次处理语音标识。因此,音频信号收集装置10可以不通过边缘计算装置20而直接将音频信号发送到服务器300。
根据另一个实施例,边缘计算装置20自身还可以包括麦克风,对其自身获得的音频信号执行语音识别,并将音频信号发送到具有更好语音识别能力的其他边缘计算装置。
当在匹配之后完成语音识别时,边缘计算装置20可以对语音识别结果执行特定任务。例如,当识别到用户语音“it’s very hot,please lower the temperature of theair conditioner(很热,请降低空调的温度)”时,边缘计算装置20可以向空调发送温度控制命令,并提供语音响应“The temperature of the air conditioner has been loweredto xx degrees(空调的温度已经降低到xx度)”。
另一方面,这样的语音响应可以由接收到控制命令的装置(诸如空调)提供。或者,这样的语音响应可以由当前最接近用户的装置提供。或者,这样的语音响应可以由语音最终输入到的音频信号收集装置提供。在这种情况下,可以基于语音信号的各种质量的参数(诸如,语音的SNR、声压级和距发出语音的用户的距离)来确定提供语音的装置。
图37是示出基于发音串或字符串的相似性对准多个音频信号并且匹配多个对准的音频信号的实施例的图。
如上所述,已经完成了基于时间对准多个音频信号并进行比较和匹配的实施例。根据另一个实施例,可以基于多个音频信号之间的发音串或字符串的相似性来对准多个音频信号,并且可以比较和匹配多个对准的音频信号。
如上所述,在多个音频信号的匹配中,该描述假设的是标识多个音频信号中包括的多个帧中要匹配的帧,并且匹配所标识的帧。然而,本公开不限于此。例如,当基于多个音频信号之间的发音串或字符串的相似性来对准多个音频信号时,可以基于发音串或字符串的单位来标识要匹配的音频信号的单位。此外,发音串或字符串的单位不限于某一长度。
例如,再参考图34,当用户的语音是“it’s very hot,please lower thetemperature of the air conditioner”时,边缘计算装置20可以从第一音频信号收集装置10-1接收与用户语音“it’s very”相对应的音频信号,并且在激活第二音频信号收集装置10-2的时间3410之后从第二音频信号收集装置10-2接收与用户语音“hot,please lowerthe temperature of the air conditioner”相对应音频信号。
在图37中,对准轴线3710、3720、3730和3740可以基于一部分用户语音来标识,其中多个接收的音频信号之间的发音串3750和3760相似。具体地,当分别从音频信号收集装置10-1和10-2中的每一个接收到音频信号时,边缘计算装置20可以基于多个接收的音频信号之间的发音串3750和3760相似的一部分用户语音,来标识对准轴线3710、3720、3730和3740中的至少一个,如图37所示。另外,边缘计算装置20可以基于所标识的对准轴线3710、3720、3730和3740对准所接收的多个音频信号,并且比较多个对准的音频信号。
此外,图37示出了基于如上文参考图36所述的通过声学模型和/或语言模型获得的得分匹配多个音频信号的示例。也就是说,图37示出了通过声学模型和/或语言模型获得的得分3770、3780和3790。具体地,边缘计算装置20可以获得用于从第一音频收集装置10-1接收的音频信号的得分3770和用于从第二音频收集装置10-2接收的音频信号的得分3780。
另一方面,在参考图36的描述中,已经描述了预设为仅使用与等于或大于0.6的得分相对应的帧的情况,但是本公开不限于此。根据又一个实施例,边缘计算装置20可以将通过将从第一音频信号收集装置10-1接收的音频信号输入到声学模型和/或语言模型而获得的得分与通过将从第二音频信号收集装置10-2接收的音频信号输入到声学模型和/或语言模型而获得的得分进行比较,并且可以标识对应于更高分的帧(3790)。
具体地,如图37所示,从第一音频信号收集装置10-1和第二音频信号收集装置10-2两者接收音频信号的部分可以是对应于“hot”和“please”的部分。此外,在对应于“hat”的发音串3750和对应于“pl”的发音串3750中,对于从第一音频信号收集装置10-1接收的音频信号的第一得分3770可以更高(分别为0.7和0.6),并且在对应于“ez”的发音串3750中,对于从第二音频信号收集装置10-2接收的音频信号的第二得分3780可以更高(0.9)。
因此,边缘计算装置20可以使用从第一音频信号收集装置接收的音频信号中与用户语音“it’s very hot,pl”相对应的帧和从第二音频信号收集装置接收的音频信号中与用户语音“ease lower the temperature of the air conditioner”相对应的帧来匹配。
上述各种实施例可以用软件、硬件或其组合来实现。根据硬件实现方式,本公开中描述的实施例可以使用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理装置(DSPD)、可编程逻辑装置(PLD)、现场可编程门阵列(FPGA)、处理器、控制器、微控制器、微处理器或用于执行其它功能的电气装置中的至少一个来实现。具体地,上述各种实施例可以由电子装置100的处理器110、集线器装置200的处理器210或服务器300的处理器310来实现。根据软件实现方式,这里描述的诸如过程和功能的实施例可以由分离的软件模块实现。每个软件模块可以执行本文所述的一个或多个功能和操作。
在包括指令的软件中实现的各种实施例可以存储在机器可读存储介质(例如,计算机)中。该机器是从存储介质调用所存储的指令并且根据所调用的指令可操作的装备,并且可以包括根据本文的实施例的服务器300。
如果指令由处理器执行,则处理器可以直接或通过使用处理器控制下的其他组件来执行与指令对应的功能。指令可以包括由编译器或解释器生成或执行的代码。例如,当存储在存储介质中的指令由处理器执行时,可以执行用于控制电子装置100、集线器装置200或服务器300的上述方法。
机器可读存储介质可以以非暂时性存储介质的形式被提供。这里,术语“非暂时性”意味着存储介质不包括信号并且是有形的,但是不区分数据是半永久地还是临时地存储在存储介质中。
根据实施例,根据本文公开的各种实施例的方法可以被包括在计算机程序产品中并被提供。计算机程序产品可以作为买卖双方之间的产品进行交易。计算机程序产品可以以机器可读存储介质(例如,光盘只读存储器(CD-ROM))的形式分发,或者通过应用商店(例如,PlayStore
根据各种实施例的每个组件(例如,模块或程序)可以包括单个实体或多个实体,并且可以省略上述子组件的一些子组件,或者在各种实施例中还可以包括其他子组件。另外,一些组件(例如,模块或程序)可以集成到一个实体中,以执行在集成之前由各个组件执行的相同或类似功能。根据不同实施例由模块、程序或其他组件执行的操作可以以顺序、并行、迭代或启发式方式执行,或者可以以不同的顺序执行或省略至少一些操作,或者可以添加其他操作。
尽管上文已经说明和描述了这些实施例,但本文描述的实施例并不限于上述实施例,而是可以由本公开所属领域的技术人员在不脱离本公开要点的情况下进行各种修改。这些修改应当理解为属于本公开的范围和精神。
- 电子装置控制方法以及应用电子装置控制方法的电子装置
- 电子装置、电子装置控制方法以及电子装置系统