一种基于ShuffleNet改进的MTCNN人脸检测方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明涉及深度学习目标检测领域,特别是涉及一种基于ShuffleNet改进的MTCNN人脸检测方法。
背景技术
随着机动车保有量的迅速增长,给人们的生活和出行带来了很大的便利,但由此带来的道路交通事故每年都给各个国家的人民生命财产和国民经济造成巨大的损失,而疲劳驾驶是导致交通事故的重要原因和主要原因之一。如果能实现人脸面部疲劳的高效识别,通过对驾驶员实时面部表情状态的检测,可有效预防并提醒驾驶员的疲劳驾驶现象,从而降低交通事故发生的可能性,因此该系统具有潜在的经济价值和广泛的应用前景。
现有的驾驶员疲劳检测方法存在一系列的问题:基于生理参数的检测方法需要驾驶员穿戴侵入式实验设备,不仅影响舒适性,还会对实际驾车状态下的驾驶员造成干扰。基于驾驶员操作行为的驾驶员疲劳检测方法受驾驶习惯、驾驶熟练度等个体差异性因素影响较大,存在鲁棒性较差、检测精度较低等问题。基于车辆运行参数的疲劳检测方法对行车环境有要求,在非结构化的道路上的检测鲁棒性差。基于面部行为的疲劳检测方法具有非侵入性、成本低,实时性好等优点,但该方法受驾驶环境及个体差异性影响较大。
近些年来,深度学习技术不断发展并取得了巨大的突破,通过卷积神经网络自动提取出目标特征。得益于卷积神经网络强大的特征提取能力,人脸检测算法的检测准确度大幅提升,并且具有更强的鲁棒性,可以适应更加复杂的识别场景。
2012年AlexNet的提出拉开了深度学习的发展大幕,之后2014年的VGGNet的提出使得深度神经网络的实现成为可能,但在网络加深的同时会出现梯度消失的问题。2015年ResNet的提出,通过残差连接的方法解决了上述问题,减少了模型收敛时间,使得网络更深而不容易出现梯度消失的问题。
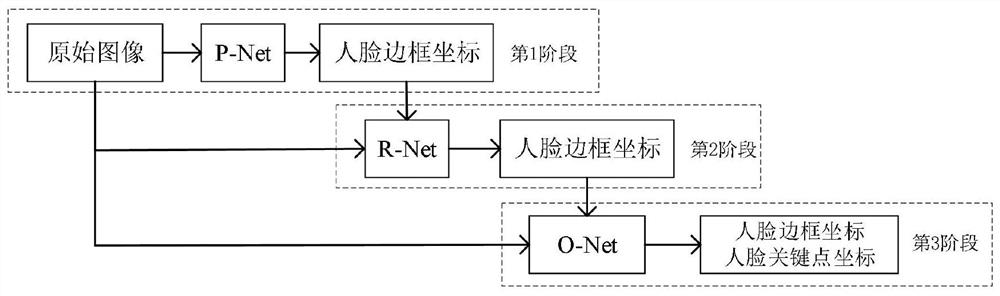
多任务级联卷积神经网络(Multi-task Cascaded Convolutional Networks,MTCNN)是一个基于由粗到精(Coarse-to-fine)思想并同时实现人脸检测与人脸关键点检测的级联结构模型,是目前在人脸检测领域应用较为广泛的检测器。其利用人脸检测和人脸关键点检测的内在关联性来提升两者的检测性能,是少数能在传统硬件上落地的检测器,在人脸检测任务上有着较高的检测精度。由于MTCNN输出的仅仅是5个标定的人脸关键点,而驾驶疲劳检测需要更多的关键点来精确的定位人脸部件(如眼睛、嘴部等)及计算其疲劳特征,因此,本发明只利用MTCNN的人脸检测功能。整个级联结构包括三个CNN模型:P-Net(Proposal Network)、R-Net(Refinement Network)及O-Net(Output Network)。其中,P-Net是一个全卷积神经网络(Fully Convolutional Network,FCN)[5],用于快速产生一系列的人脸候选窗口;R-Net用于过滤掉P-Net生成的绝大部分非人脸候选窗口并对可能是人脸的候选窗口的边界框(Bounding Box)坐标位置进行进一步的纠正;O-Net与R-Net的功能类似,不同的是O-Net有更多的特征输入和复杂的网络结构,具有更好的性能,生成最终的人脸窗口及人脸关键点的位置。
MTCNN模型在检测速度上的瓶颈主要有:第1阶段P-Net的输入图像分辨率越大耗时越多;图像中的人脸越多第2和第3阶段O-Net和R-Net的耗时也就越长。
针对以上问题,本发明根据MTCNN模型的基础上加入了ShuffleNet的混合通道与逐点组卷积,在保证人脸检测精度的同时,提高了检测速度。
发明内容
为解决上述问题,本发明实例提供了一种基于ShuffleNet改进的MTCNN人脸检测方法,目的是提高人脸检测精度与速度,包括以下形成步骤:
步骤一,将图像进行不同尺度的变换,构建图像金字塔;
步骤二,将图像金字塔所有图片输入到P-Net,经过三次卷积,一次池化,两次通道混洗,输出大量Boundingbox坐标;
步骤三,根据Boundingbox坐标去原图截出图片,resize为24*24;
步骤四,将size为24*24的图片输入R-Net,经过三次常规卷积,两次池化,两次通道混洗,一次逐点组卷积后,输出纠正后更加精确的Bounding box坐标;
步骤五,根据Boundingbox坐标去原图截出图片,resize为48*48;
步骤六,将size为24*24的图片输入O-Net,经过四次常规卷积,三次池化,三次通道混洗,一次逐点组卷积后,输出准确的Bounding box坐标;
优选的,步骤二、四、六中进行卷积操作时采用通道混洗思想改进模型,在不同的组里平均分配特征通道,这样在进行卷积操作时每组的特征都能得到其他组的信息,增强了不同通道的特征图之间的关联性。此策略既尽可能的减少了计算量,又可以保证模型的检测精度。;
优选的,步骤四、六中进行逐点组卷积。逐点组卷积为组卷积(GroupConvolution)与逐点卷积(Pointwise Convolution)的组合应用,组卷积的作用是减少参数量,组卷积可以看成是结构化稀疏(Structured Sparse),逐点卷积的公式如下:
其中k在核所支持的所有子域上进行迭代,p
与现有技术相比,本发明实例中在MTCNN网络的基础上改进,加入了ShuffleNet的混合通道与逐点组卷积,在保证人脸检测精度的同时,提高了检测速度。
附图说明
图1为本发明的一种基于ShuffleNet改进的MTCNN人脸检测方法的形成步骤的推理流程图;
图2为本发明的一种基于ShuffleNet改进的MTCNN人脸检测方法P-Net改进示意图;
图3为本发明的一种基于基于ShuffleNet改进的MTCNN人脸检测方法R-Net改进示意图;
图4为本发明的一种基于ShuffleNet改进的MTCNN人脸检测方法O-Net改进示意图;
图5为本发明的一种基于ShuffleNet改进的MTCNN人脸检测方法改进所采用的通道混洗技术示意图;
图6为本发明的一种基于基于ShuffleNet改进的MTCNN人脸检测方法所采用的分组卷积示意图;
图7为本发明的一种基于基于ShuffleNet改进的MTCNN人脸检测方法所采用的逐点卷积示意图;
图8为本发明的一种基于基于ShuffleNet改进的MTCNN人脸检测方法检测效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中模型方案进行完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种基于ShuffleNet改进的MTCNN人脸检测方法,该发明实例形成步骤为:
步骤一,将图像进行不同尺度的变换,构建图像金字塔;首先对图片不断进行Resize,得到图片金字塔。按照resize_factor(如0.70,这个具体根据数据集人脸大小分布来确定,基本确定在0.70-0.80之间会比较合适,设的比较大,容易延长推理时间,小了容易漏掉一些中小型人脸)对图片进行resize,直到大等于P-net要求的12*12大小。这样子你会得到原图、原图*resize_factor、原图*resize_factor^2...、原图*resize_factor^n。注意,这些图像都是要一幅幅输入到Pnet中去得到候选的。
步骤二,图片金字塔输入Pnet,如图2所示,得到大量的候选(candidate)。根据上述步骤得到的图片金字塔,将所有图片输入到P-net,得到输出map形状是(m,n,16)。根据分类得分,筛选掉一大部分的候选,再根据得到的4个偏移量对bbox进行校准后得到bbox的左上右下的坐标(根据偏移量矫正先埋个坑,描述训练阶段的时候补),对这些候选根据IOU值再进行非极大值抑制(NMS)筛选掉一大部分候选。详细的说就是根据分类得分从大到小排,得到(num_left,4)的张量,即num_left个bbox的左上、右下绝对坐标。每次以队列里最大分数值的bbox坐标和剩余坐标求出iou,干掉iou大于0.6(阈值是提前设置的)的框,并把这个最大分数值移到最终结果。重复这个操作,会干掉很多有大量overlap的bbox,最终得到(num_left_after_nms,16)个候选,其中在卷积后加入通道混洗步骤,具体原理如图5;
步骤三,根据Boundingbox坐标去原图截出图片,resize为24*24;
步骤四,根据P-net输出的坐标,去原图上截取出图片(截取图片有个细节是需要截取bbox最大边长的正方形,这是为了保障resize的时候不产生形变和保留更多的人脸框周围细节),resize为24*24,输入到R-net,如图3所示,进行精调。R-net仍旧会输出二分类one-hot2个输出、bbox的坐标偏移量4个输出、landmark10个输出,根据二分类得分干掉大部分不是人脸的候选、对截图的bbox进行偏移量调整后(说的简单点就是对左上右下的x、y坐标进行上下左右调整),再次重复P-net所述的IOU NMS干掉大部分的候选。最终P-net输出的也是(num_left_after_Rnet,16),加入逐点层卷积步骤,加快检测速度,具体原理如图6、图7所示;
步骤五,根据bbox的坐标再去原图截出图片输入到O-net,同样也是根据最大边长的正方形截取方法,避免形变和保留更多细节;
步骤六,经过R-net干掉很多候选后的图片输入到O-net,如图4所示,输出准确的bbox坐标和landmark坐标。大体可以重复P-net的过程,不过有区别的是这个时候我们除了关注bbox的坐标外,也要输出landmark的坐标。(之所以也有landmark坐标的输出,主要是希望能够联合landmark坐标使得bbox更精确,换言之,推理阶段的P-net、R-net完全可以不用输出landmark,O-net输出即可。)经过分类筛选、框调整后的NMS筛选,至此我们就得到准确的人脸bbox坐标和landmark点。
通过测试,相比于传统的MTCNN网络,本发明实例在WIDERFACE数据集上有很好的检测效果,平均精度达到了90.3%,平均速度达到了232FPS,相较于MTCNN的25FPS,能满足实时检测的要求。
综上所述,本发明实例中的一种根据MTCNN模型的基础上加入了ShuffleNet的混合通道与逐点组卷积,在保证人脸检测精度的同时,提高了检测速度。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 一种基于ShuffleNet改进的MTCNN人脸检测方法
- 一种基于MTCNN的多方位人脸检测方法及系统