一种观测数据中异常值的处理方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明具体涉及一种对测量观测数据中异常值的处理方法。
背景技术
测量是人类对事物进行研究的一种基本和必须的实验手段与方法,不仅可直接通过测量数据发现事物的内在规律,也可通过测量验证提出的方法理论的正确性和适用性。测量时,由于仪器、观测条件、环境等因素的限制,不可能无限精确,物理量的观测值与真实值之间总会存在着一定测量误差(或称观测误差),一般认为任何测量都有误差,误差可以减小但不能消除。观测误差主要来源有三个方面:测量仪器、测量条件和测量人,按性质误差可分为随机误差(random error)、系统误差(systematic error)和粗大误差(parasiticerror,gross error)。
在测量中,由于某些客观或主观原因,造成某些观测样本值的大小明显偏离真实值很远(过大或过小),这些观测样本值中包含粗大误差,通常称之为异常值或“飞点”(Outlier)。对某一物理量作多次独立等精度的重复观测,如果其中部分观测值为异常值,在观测后采用如采用最小二乘法等非稳健的方法估计观测测量结果,观测异常值会导致测量结果明显偏离真实值,将可能导致不准确甚至错误的测量结论。测量观测数据中异常值的处理,就是测量中粗大误差的处理。
现代测量平差理论中,考虑粗大误差产生的原因和影响,在数据处理时可将其归为函数模型或随机模型。函数模型情况下,粗大误差表现为观测误差绝对值较大且偏离群体,可解释为均值漂移模型,处理的思想是在使用前找到并剔除含粗差的观测值,得到一组比较净化的观测值,再进行参数(如均值)估计得到测量结果。随机模型情况下,粗大误差表现为先验随机模型和实际随机模型的差异过大,可解释为方差膨胀模型,处理的思想是根据逐次迭代平差的结果来不断地改变观测值的权或方差,最终使包含粗大误差的观测值的权趋于零或方差趋于无穷大,使得所估计的参数(如均值)少受模型误差,特别是粗大误差的影响。
函数模型情况下,传统的粗大误差处理方法较为较多,一般为,先假设观测数据样本符合某种概率分布(如正态分布),再基于分布模型对观测数据样本值进行判断,具体为利用各种准则,如3σ准则、拉伊达准则、格拉布斯准则等,对不符合先验概率分布模型的观测样本点予以剔除,最终得到一个较为可信的观测数据样本,再进行参数估计得到测量结果。随机模型情况下,一般采用统计参数稳健估计方法,如M估计、L估计及R估计等,估计观测数据样本的参数,方法以迭代方式降低方差较大数据元素的权重,尽可能减小粗差的影响,最终得出正常模式下最佳或接近最佳的估计结果。
在实际运用中,如地球物理勘探电场测量观测,由于各种噪声干扰的影响,观测数据存在测量样本较小(低频段),粗大误差较大(强干扰),粗大误差较多(持续干扰),或以上条件叠加出现等情况。采用函数模型处理方法,不易确定能准确描述观测数据的理想概率分布模型(实际观测数据往往不完全服从正态分布),应用准则时易出现过度剔除或方法无效等情况。采用随机模型处理方法,也难以快速而准确地收敛,存在计算效率低,估计结果受误差影响大的情况。也就是说,传统的函数模型和随机模型处理方法在观测数据质量较差的情况下,存在方法适应性不好,功能和性能受限的情况。
发明内容
为了解决上述技术问题,本发明提供一种操作简单、适用性好,能够提高观测数据的可靠性和可信度,且计算相对简单,处理效率高的观测数据中异常值的处理方法。
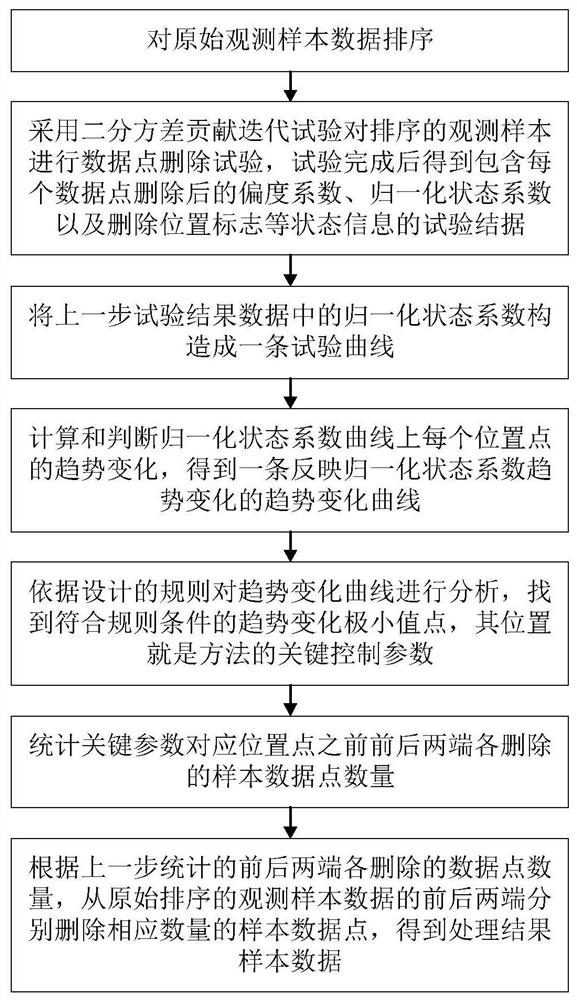
本发明采用的技术方案是:一种观测数据中异常值的处理方法,包括如下步骤:
1)对观测样本根据大小排序后进行二分方差贡献迭代试验,依次对观测数据样本中方差贡献最大的端点数据逐个删除,并计算删除后观测样本的偏度系数及归一化状态系数,试验完成后得到样本删除试验数据;
2)针对步骤1)中得到的样本删除试验数据中的归一化状态系数进行趋势变化分析,结合删除试验数据的偏度系数,确定异常值剔除的最优控制参数;
3)采用步骤2)得到的最优控制参数,对步骤1)排序后的原观测数据样本进行异常值剔除操作,完成观测数据的处理。
上述的观测数据中异常值的处理方法中,步骤1)具体操作如下:
1.1)对原始观测数据样本D
1.2)计算D'
1.3)对D'
1.4)计算D'
1.5)判断D'
所述的偏度系数,采用如下公式进行计算:
其中:SD(X)为样本X的标准差,
所述的归一化状态系数是将归一化之后的样本方差和样本偏度系数两个参数加权构造为一个状态系数,归一化状态系数按如下公式计算:
其中,
上述的归一化状态系数计算中的归一化参数,采用如下算式计算:
其中,X
上述的观测数据中异常值的处理方法中,步骤2)具体步骤如下:
2.1)对步骤1)得到的删除试验数据,以删除的样本点数量为x轴,归一化状态系数值为y轴,在笛卡尔坐标系中得到一条与样本点删除相关的归一化状态系数曲线,对曲线上的每个点判断其归一化状态系数的趋势变化类型,计算每个点趋势变化系数TVC,并将每个点的趋势变化系数TVC保存到每个点的属性中;
2.2)由步骤2.1)得到的每个点的趋势变化系数TVC数据,得到一条反映归一化状态系数曲线趋势变化的TVC曲线;在TVC曲线中寻找和选择极小值位置p
2.3)由2.2)得到的最优控制参数p
上述的观测数据中异常值的处理方法中,步骤2.1)中趋势变化系数TVC的计算,基于当前位置点分别向前和向后延拓,采用线性或非线性拟合方法进行趋势计算,根据前后趋势之间的变化,计算得到趋势变化系数TVC的值;在采用线性拟合情况下的,趋势变化系数TVC计算公式如下:
TVC(p
其中,p
上述的观测数据中异常值的处理方法中,步骤2.2)中的TVC曲线上存在多个极小值点时,最优控制参数位置p
当存在不小于偏度系数经验阈值的极值点时,在其中考查极值最小的三个极小值点,选择极值最小的三个极小值点中偏度系数最接近0或离偏度系数经验阈值最近的一个作为结果;当所有极值点都小于偏度系数经验阈值时,在其中考查极值最小的三个极小值点,选择极值最小的三个极小值点中偏度系数最接近0或离偏度系数经验阈值最近的一个作为结果。
上述的观测数据中异常值的处理方法中,步骤3)中,根据步骤2)得到的r
本发明不需要预先假设观测样本服从某种严格的统计分布模型,如正态分布、t分布等,而是以样本统计分布形态对均值结果影响大小为依据,适当放宽假设条件,仅以数据样本统计分布的方差和偏度系数等为主要指标,通过二分方差贡献迭代试验和归一化状态系数趋势变化分析等方法和步骤,获得观测样本中剔除异常值的最优控制参数,再使用控制参数进行异常值样本点剔除处理,最终获得可信的观测结果样本。
与现有技术相比,本发明的方法具有以下有益效果:1)本发明不以观测样本服从某种具体的统计分布模型为假设前提,从而具有更强的适用性,在小样本、大粗差、高粗差比等情况下功能和性能表现良好;2)本发明以测量统计理论基本原理为依据,具有良好的理论基础,处理结果可靠性和可信度高;3)本发明以观测样本自身统计特征为参数,计算得到的归一化系数及其趋势变化为分析依据,来获得方法的最优控制参数,仅需一个无量纲经验阈值外部参数辅助,使得方法具有良好的自适应性;4)本发明具有框架性,方法处理流程中的中间参数或系数的计算方法或函数,既可使用方法中设的计算式,也可根据测量应用的特点和需要,自行设计修改或改进,同样地,计算方法或规则中使用的经验参数值,既可采用推荐的默认值,也可根据应用需要自行选择或修改,使得方法具有高灵活性;5)本发明只需通过一次迭代试验和一次扫描分析即可得到方法的关键控制参数,再通过简单的删除处理,即可获得最终处理结果,具有计算量较小,处理效率高的特点。
附图说明
图1为本发明的流程图。
图2为P
图3为6种趋势变化类型示意图。
图4为本发明实例一中的两个观测样本的原始分布形态。(a)为样本1的原始分布形态,(b)为样本2的原始分布形态。
图5为本发明实例一中的两个原始观测样本排序后的分布形态。(a)为样本1的排序后的分布形态,(b)为样本2的排序后的分布形态。
图6为本发明实例一中的两个观测样本试验结果状态曲线图。(a)为样本1的试验结果状态曲线图,(b)为样本2的试验结果状态曲线图。
图7为本发明实例一中的两个观测样本试验结果分析曲线图。(a)为样本1的试验结果分析曲线图,(b)为样本2的试验结果分析曲线图。
图8为本发明实例一中的两个观测样本处理结果排序分布形态。(a)为样本1的处理结果排序分布形态,(b)为样本2的处理结果排序分布形态。
具体实施方式
下面结合附图对本发明做进一步的说明。
如图1所示,本发明包括如下步骤:
1)对观测样本根据大小排序后进行二分方差贡献迭代试验,依次对观测数据样本中方差贡献最大的端点数据逐个删除,计算删除后观测样本的偏度系数及归一化状态系数,试验完成后得到样本删除试验数据,;
其具体操作如下:
1.1)对原始观测数据样本D
1.2)计算D'
1.3)对D'
1.4)计算D'
1.5)判断D'
所述的偏度系数,采用如下公式进行计算:
其中:SD(X)为样本X的标准差,为
所述的归一化状态系数是将归一化之后的样本方差和样本偏度系数两个参数加权构造为一个状态系数,归一化状态系数按如下公式计算:
其中,
上述的归一化状态系数计算中的归一化参数,采用如下算式计算:
其中,X
2)针对步骤1)中得到的样本删除试验数据的归一化状态系数进行趋势变化分析,结合删除试验数据的偏度系数,确定异常值剔除的最优控制参数。
其具体操作如下:
2.1)对步骤1)得到的删除试验数据,以删除的样本点数量为x轴,归一化状态系数值为y轴,在笛卡尔坐标系中可得到一条与样本点删除相关的归一化状态系数曲线,对曲线上的每个点判断其归一化状态系数的趋势变化类型,计算每个点趋势变化系数TVC,并将每个点的趋势变化系数TVC保存到每个点的属性中。
趋势变化系数TVC的计算,基于当前位置点分别向前和向后延拓适当距离,采用线性或非线性拟合方法进行趋势计算,根据前后趋势之间的变化,计算得到趋势变化系数TVC的值;在采用线性拟合情况下的,趋势变化系数TVC计算公式如下:
TVC(p
其中,p
2.2)由步骤2.1)得到的每个点的趋势变化系数TVC数据,可得到一条反映归一化状态系数曲线趋势变化的TVC曲线;在TVC曲线中寻找和选择极小值位置p
TVC曲线上存在多个极小值点时,最优控制参数位置p
当存在不小于偏度系数经验阈值的极值点时,在其中考查极值最小的三个极小值点,选择极值最小的三个极小值点中偏度系数最接近0或离偏度系数经验阈值最近的一个作为结果;当所有极值点都小于偏度系数经验阈值时,在其中考查极值最小的三个极小值点,选择极值最小的三个极小值点中偏度系数最接近0或离偏度系数经验阈值最近的一个作为结果。
2.3)由2.2)得到的最优控制参数p
3)根据步骤2)得到的r
步骤2)通过对1)得到的删除试验数据进行趋势变化分析,找到剔除异常值的最优控制参数的基本原理是:对于一次合理测量观测,在对原始观测样本排序后,异常值只可能分布在样本的前后两端,较为可信的观测值会集中分布在某一个连续的范围,可认为存在一个“可信核”。
在二分方差贡献迭代试验过程中,每次均从只在前端点或后端点位置删除对方差贡献最大的观测样本点,符合异常值只可能分布在排序样本前后两端的基本假设,整个试验过程可理解为迭代地从排序样本两端逐一删除异常值样本点,逐步向观测值“可信核”逼近的过程。由于每次删除端点样本点时,均以端点样本点在二分样本中的方差贡献较大为依据,因此删除异常值样本点的过程,体现在删除样本点后的归一化状态系数会是一个快速收敛的过程,表现为归一化状态系数曲线较为陡峭;而在试验进行到“可信核”后(试验进行到仅剩3个样本点时结束),由于每个可信观测样本点均与真实测量结果接近,因此删除可信样本点后的归一化状态系数变化较小,表现为归一化状态系数曲线较为平坦。如上所述,在观测样本中存在异常值时,整个试验过程反映在归一化状态系数的变化上,会有从快速收敛到平缓稳定两个阶段,表现为归一化状态系数曲线的趋势可分为陡峭部分和平缓部分,而陡峭到平缓的分界点位置,反映的是最后一个异常值样本点被删除的状态,就是本方法的最优控制参数。
如上分析,找到归一化状态系数曲线从陡峭到平缓的分界点位置,即确定了本方法的最优控制参数。考虑到分界点位置处归一化状态系数曲线的前后趋势形态明显不同,因此必然会在此位置形成一个趋势变化的局部极值,甚至全局极值。进一步通过对归一化状态系数曲线进行趋势变化分析,通过趋势变化极值确定分界点位置,从而确定S2的最优控制参数。
以下结合一个具体的实施例对本发明进行进一步说明:
实施例1:可控源电磁勘探电场强度观测数据处理
在可控源电磁勘探应用中,一般通过多周期重复观测再取均值的方式来抑制随机干扰。由于大地是一个开放的环境,地电环境非常复杂,电场强度极易受到噪声干扰影响。本例以两个频率点的电场强度数据处理为例,说明本方法的处理过程和效果。
本实施例选择分布形态为左偏态分布和右偏态分布的两个观测数据样本,分别为样本1和样本2,如图4所示,样本1为240个数据点的观测数据集,初始分布形态为左偏态分布;样本2为384个数据点的观测数据集,初始分布形态为右偏态分布。对样本1和样本2的原始样本分别按照数据大小进行排序后,其分布形态,如图5所示,可见明显的左右偏态分布样本形态,以及分布直方图和样本分布形态之间的关系。
对样本1、样本2分别进行二分方差贡献迭代试验,逐一删除端点样本点,计算删除后样本1、样本2的偏度系数和归一化状态系数。对样本1、样本2的试验结果数据以删除的数据点数量为x轴,归一化状态系数值为y轴,得到一条归一化状态系数曲线,如图6所示,为方便分析,图中还同时显示了试验过程中得到的偏度系数、方差、均值以及删除端点标志的相关曲线和标志。
根据归一化状态系数计算并判断样本每个点的归一化状态系数的趋势变化类型和TVC值,得到一条反映归一化状态系数曲线趋势变化的TVC曲线,如图7所示,依据方法设计的规则在趋势变化TVC曲线中找到满足条件的极小值位置,如图7中“最佳控制参数位置”指示:样本1的最佳控制参数位置为30,样本2的最佳控制参数位置为78。
由上一步得到的样本1和样本2的最佳控制参数位置,结合二分方差贡献迭代试验过程中记录的数据点删除位置标志,统计在最佳控制参数位置之前前后两端各删除的数据点数量,结果为:样本1前端删除30个数据点,后端删除0个数据点;样本2前端删除0个数据点,后端删除78个数据点。
用上一步得到的控制参数结果,对样本1和样本2进行样本数据点删除处理,最终结果如图8所示,两个样本中对均值影响最大的异常值数据点基本都已剔除干净,处理后样本的分布形态基本为对称分布,效果令人满意。
- 一种观测数据中异常值的处理方法
- 一种卫星重力观测数据异常值提取方法、装置及电子设备