一种基于文本摘要的政策要点抽取方法与提取系统
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及人工智能和自然语言处理领域,特别涉及一种基于文本摘要的政策要点抽取方法与提取系统。
背景技术
近年来,由于互联网用户每天在互联网上分享和传递大量以文本形式展现的信息,互联网上的文本信息出现爆发式增长。当用户浏览海量的互联网文本数据时,很难快速准确地获取其中的关键信息。这导致用户需要花费很多的时间和精力去自行概括文本中的重要内容。因此,如何能够从这些海量的长文本中提取出用户最关注的内容,提升对于信息处理的效率,成为了当下自然语言处理领域迫在眉睫的研究工作。
一个好的摘要内容需要满足摘要内容重要性高、多样性高、冗余度低和可读性高等多方面的要求。对文本摘要按照生成方式的不同进行分类,可分为抽取式文本摘要(Extractive Summarization)和生成式文本摘要(Abstractive Summarization)。其中,抽取式文本摘要能够直接从原文中抽取句子,并对其进行重要性排序,形成最终的摘要。生成式文本摘要在对原文进行语义理解的基础上,对信息进行压缩,生成包含新的词汇与具有不同描述风格的摘要内容。
这两种方法各有其优点与局限性。抽取式文本摘要虽然能够抽取原文中的重要句子,但是受摘要长度的限制,其所抽取的句子可能不能完全覆盖原文内容。相较而言,生成式文本摘要在直观上更符合人类摘要书写的习惯,可以生成原文中没有的单词,灵活性更强。但其描述内容容易出现事实性错误以及存在连贯性差等问题。
“智慧政务”是文本摘要技术应用的重要场景,为了从每年各级政务服务部门发布的大量政策文件中抽取出关键信息,为企业提供政策解读的辅助能力,在政策服务领域,政策要点抽取是抽取式文本摘要技术的一个重要应用场景。从长篇幅的政策原文中抽取出重要的内容与政策要求对于提升政策的易理解性与传播效率具有重要作用。
发明内容
发明目的:本发明提出了一种基于文本摘要的政策要点抽取方法与提取系统,充分利用文本摘要技术解决政策服务领域的政策要点抽取难题。
为了实现上述目的,本发明提出的技术方案为:
一种基于文本摘要的政策要点抽取方法,其特征在于,该方法包括如下步骤:
S1.构造政策要点抽取数据集,对政策数据集和解读内容进行标签构造;
S2.抽取基于文本摘要的政策要点,对政策要点数据集进行抽取式文本摘要算法模型构建;
S3.基于关键单词进行候选政策要点抽取,通过对步骤S2中得到的候选政策要点通过关键词进行二次筛选,作为最终的政策要点抽取结果。
进一步地,步骤S1中所述构造政策要点抽取数据集的具体方法是:
S11.对于一篇政策文档
S12.初始化每个句子标签为
S13.当预测摘要集合
S14.如果该句子加入预测摘要集合
进一步地,步骤S2中所述抽取基于文本摘要的政策要点的具体方法是:
S21.参数定义:对于一篇给定的政策文档
S22.词性标注:给定一篇包含
1)对输入的政策文档
2)将前向和后向LSTM的输出隐状态拼接后得到每个单词的隐状态
3)将每个单词的隐状态
S23.设计基于多任务学习的抽取式文本摘要模型,该模型包含输入层、词性标注层、单词层、句子层、文档层和预测层这六个部分,具体地:
1)输入层:将政策文档中的每条句子
2)词性标注层:将每条句子的词嵌入示表示结果
其中,
3)单词层:将词性标注中每个单词的隐状态
其中,
4)句子层:采用将句内单词的单词层隐状态
其中,
5)文档层:通过随机初始化文档级别的语义信息
6)预测层:结合单词层、句子层、文档层的语义信息对政策中的句子进行分类,计算每个句子抽取出来作为要点内容的概率
其中,
其中,
其中,
S24.联合训练步骤S22中的基于神经网络搭建的词性标注模型和步骤S23中的抽取式文本摘要模型,这两个模型优化目标都采用交叉熵损失函数,这两个模型的联合损失函数为:
其中,
S25.阈值选择,待模型训练结束后,利用模型推理出每篇文档中每个句子成为候选摘要句子的概率,设定一个阈值,将概率高于阈值的句子抽取出来作为候选政策要点内容。
进一步地,步骤S3中所述基于关键单词进行候选政策要点抽取的具体方法是:
使用词频逆文档频率
统计一篇政策文件内容中句子数目(
其中,分母加1示为了防止分母出现为0的情况,然后计算
选取
本发明还提供一种基于文本摘要技术的政策要点抽取系统,该系统包括:
数据库层:数据库主要用来存储本系统的政策文档及其结果,提供用户层所需要的数据;
用户层:用于基于Web技术实现与用户交互,给用户提供政策采集、辅助解读、政策管理、政策抽取以及政策查询功能;
人机交互模型预测层:用于通过用户层提供的政策采集接口采集新的政策文档并对这些政策文档进行预处理后,通过训练好的模型进行推断得到候选政策要点,然后后台管理员对候选政策要点进行辅助解读,将解读结果保存在数据库中;
算法训练层:利用现有的政策文档及解读内容作为数据集来训练文本摘要模型;然后,通过人机交互模型预测层中管理员提供的新的政策文件作为新的训练数据;最后,对这些新的数据进行预处理,构造政策要点标签,来训练基于多任务学习的抽取式,提升算法精度。
有益效果:
相对于现有技术,本发明的优点在于:(1)结合多任务学习框架,克服了现有抽取式文本摘要算法覆盖不全和容易过拟合的问题;(2)基于关键单词的候选政策要点抽取过程有助于在文本摘要的基础上更进一步的抽取政策文本的核心内容。
附图说明
图1为本发明的基于多任务学习的抽取式文本摘要模型流程图;
图2为基于神经网络搭建的词性标注模型框架图;
图3为本发明的政策要点系统工作流程框架图;
图4为本发明的多任务学习文本摘要神经网络架构图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
如图1所示,本发明公开的基于文本摘要的政策要点抽取方法,该方法包括如下步骤:
S1.构造政策要点抽取数据集,对政策数据集和解读内容进行标签构造;
S2.抽取基于文本摘要的政策要点,对政策要点数据集进行抽取式文本摘要算法模型构建;
S3.基于关键单词进行候选政策要点抽取,通过对步骤S2中得到的政策要点通过关键词进行二次筛选,作为最终的政策要点抽取结果。
由于国内外尚无公开的政策要点数据集,本发明首先整理了一个百篇规模的政策要点数据集,然后对该数据集使用pyltp工具进行分句、分词、构建词表、词性标注等操作。
然后,为了构造适合抽取式文本摘要算法的数据集,对中文政策解读数据集进行句子标签构造。即:如果当前句子在政策文件中比较重要,则将该句子标注为“1”,表示该句子出现在政策解读内容中;否则,将该句子标住为“0”,表示该句不出现在政策解读内容中。
具体操作过程为:步骤S1中所述构造政策要点抽取数据集的具体方法是:
S11.对于一篇政策文档
S12.初始化每个句子标签为
S13.当预测摘要集合
S14.如果该句子加入预测摘要集合
所述的基于文本摘要的政策要点抽取方法,步骤S2中所述抽取基于文本摘要的政策要点的具体方法是:
S21.参数定义:对于一篇给定的政策文档
S22.词性标注:目前的抽取式文本摘要算法存在着重要性不足与覆盖原文内容不全的问题,并且存在着模型容易过拟合、泛化性差等问题。为解决上述问题,本发明基于多任务学习,针对文本内容具备的“单词-句子-篇章”层次化结构进行学习,解决了抽取式文本摘要重要性不足与覆盖原文内容不全的问题,同时,提升了模型的泛化性。其中,词性标注任务是从“单词”层面对文本信息的捕获,所以本文引入词性标注任务作为辅助任务。
给定一篇包含
1)对输入的文档进行嵌入式词表示,向量维度为300;然后,输入到前向和后向LSTM中进行特征提取;
2)将前向和后向LSTM的的输出隐状态拼接后(如图2中的concat所示)得到每个单词的隐状态
3)将每个单词的隐状态
S23.设计基于多任务学习的抽取式文本摘要模型,该模型包含输入层、词性标注层、单词层、句子层、文档层和预测层这六个部分,具体地:
1)输入层:将政策文档中的每条句子
2)词性标注层:将每条句子的词嵌入示表示结果
其中,
3)单词层:将词性标注中每个单词的隐状态
其中,
4)句子层:采用将句内单词的单词层隐状态
其中,
5)文档层:通过随机初始化文档级别的语义信息
6)预测层:结合单词层、句子层、文档层的语义信息对政策中的句子进行分类,计算每个句子抽取出来作为要点内容的概率
其中,
其中,
其中,
S24.联合训练步骤S22中的基于神经网络搭建的词性标注模型和步骤S23中的抽取式文本摘要模型,这两个模型优化目标都采用交叉熵损失函数,这两个模型的联合损失函数为:
其中,
S25.阈值选择,待模型训练结束后,利用模型推理出每篇文档中每个句子成为候选摘要句子的概率,设定一个阈值,阈值采用经验设置,将概率高于阈值的句子抽取出来作为候选政策要点内容。
所述的基于文本摘要的政策要点抽取方法,步骤S3中所述基于关键单词进行候选政策要点抽取的具体方法是:
使用词频逆文档频率
统计一篇政策文件内容中句子数目(
其中,分母加1示为了防止分母出现为0的情况,然后计算
选取
以上是本发明提出的基于多任务学习的抽取式文本摘要算法的具体实施过程。为了更好的评估算法模型的性能,本发明采用了文本摘要算法经典的ROUGE评价指标,其中R-1,R-2,R-L的指标越高说明抽取出来的内容重要程度越高,结果越准确。其实验结果如表1所示。
表1政策要点数据集ROUGE分数
表1中算法Lead-10表示取每篇政策的前10句话作为要点内容。可以看出,本文的方法相较于经典的Lead算法,可以实现更高ROUGE分数,说明本文方法可以抽取到政策文本中的核心内容,覆盖更全面的内容。
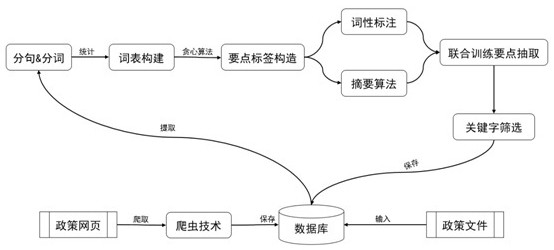
如图4所示,本发明公开的基于文本摘要技术的政策要点抽取系统是基于上述提出的基于文本摘要技术的政策要点抽取算法进行系统设计的。该系统主要包括数据库、用户层、人机交互模型预测层、算法训练层。
数据库:数据库主要用来存储本系统的政策文件及其结果,提供用户层所需要的数据。该过程是一个动态交互过程,当用户从用户层触发一个功能,意味着对数据库的一次读写操作。
用户层:该层主要为系统用户提供政策采集、辅助解读、政策管理、政策抽取以及政策查询等核心功能。上述系统功能基于Web技术实现与用户交互,系统从数据库读取已经分析过的政策文件及其结果,然后展示在Web页面上,提供给用户进行查询、管理。
人机交互模型预测层:具体流程为(1)后台管理员不断利用用户层提供的政策采集接口采集新的政策文件,如图4中的①所示。即:用户通过Web页面输入新的政策文件内容或者通过录入功能上传政策文件;(2)对这些政策文件进行预处理后,通过训练好的摘要系统模型进行推断得到候选政策要点,如图4中的②③④所示。其中,预处理主要包括对政策文件内容进行提取、分句、分词等,预处理结束后输入到算法模型中进行推断,生成候选政策要点内容;(3)后台管理员对候选政策要点进行辅助解读,将解读结果保存在数据库中,如图4中的⑤⑥所示。
算法训练层:利用现有的政策文件及解读内容作为数据集来训练文本摘要任务模型(初始阶段,数据集内带有标注的数据规模较少)如图4中的⑦所示;然后,通过人机交互模型预测层中管理员提供的新的政策文件作为新的训练数据;最后,对这些新的数据进行预处理,构造政策要点标签,来训练多任务文本摘要算法模型,提升算法精度如图4中的⑧⑨⑩所示。
该系统是人机交互的过程。首先,利用现有的政策文件及解读内容作为数据集来训练文本摘要任务模型;然后,管理员不断提供新的政策文件到摘要系统,使用训练好的摘要模型进行推断得到候选政策要点;其次,管理员对与本专利发明自动生成的候选政策要点内容进行人工调整之后,再次作为训练数据保存到数据库中,成为下一次模型训练的数据。通过人机交互的方式不断地扩充数据来提升本专利发明提出的政策要点抽取算法模型的准确度。因此,该人机过程由管理员、摘要系统、数据库3个实体一起构成一个不断学习与数据集扩充的闭环。
在本申请所提供的实施例中,应该理解到,所揭露的方法,在没有超过本申请的精神和范围内,可以通过其他的方式实现。当前的实施例只是一种示范性的例子,不应该作为限制,所给出的具体内容不应该限制本申请的目的。例如,多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种基于文本摘要的政策要点抽取方法与提取系统
- 一种基于文本摘要的政策要点抽取方法与提取系统