一种基于图数据库的技术图谱构建方法和系统
文献发布时间:2023-06-19 11:52:33
技术领域
本发明涉及技术图谱构建技术领域,尤其是涉及一种基于图数据库的技术图谱构建方法和系统。
背景技术
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过将数据粒度从document级别降到data级别,聚合大量知识,从而实现知识的快速响应和推理。当下,知识图谱已在工业领域得到了广泛应用,如搜索领域的Google搜索、百度搜索,社交领域的领英经济图谱,企业信息领域的天眼查企业图谱等。
在知识图谱中,知识是大量的复杂、低结构化、高连接关系的数据。当这些知识被频繁地查询和更新时,关系数据库会在每次处理时产生大量的表连接,从而导致性能问题。
关系数据库在知识图谱的设计和使用上也存在一些不便,当新实体或关系到来时,添加新的表或字段会给开发和升级带来很多工作。
此外,基于关系数据库的知识存储通过实体和关系映射来达到知识获取的目的,但是其缺点在于每次进行知识访问需要进行两次翻译,当知识的查询和检索操作比较频繁时,其效率上的劣势也会凸显。并且,RDF的知识表示形式与基于SPARQL的知识查询也会带来一些使用上的不便。
技术图谱是知识图谱在技术领域内的一种应用,旨在描述技术领域中存在的各种实体或概念,以及它们之间的关联关系。技术图谱本质上是一种语义网络的技术库,从实际应用的角度出发可以简单地把技术图谱理解成多关系图。
发明内容
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种能形象地展示图谱中的实体和实体间关系信息,并且提供了良好的交互方式的基于图数据库的技术图谱构建方法和系统。
本发明的目的可以通过以下技术方案来实现:
一种基于图数据库的技术图谱构建方法,包括以下步骤:
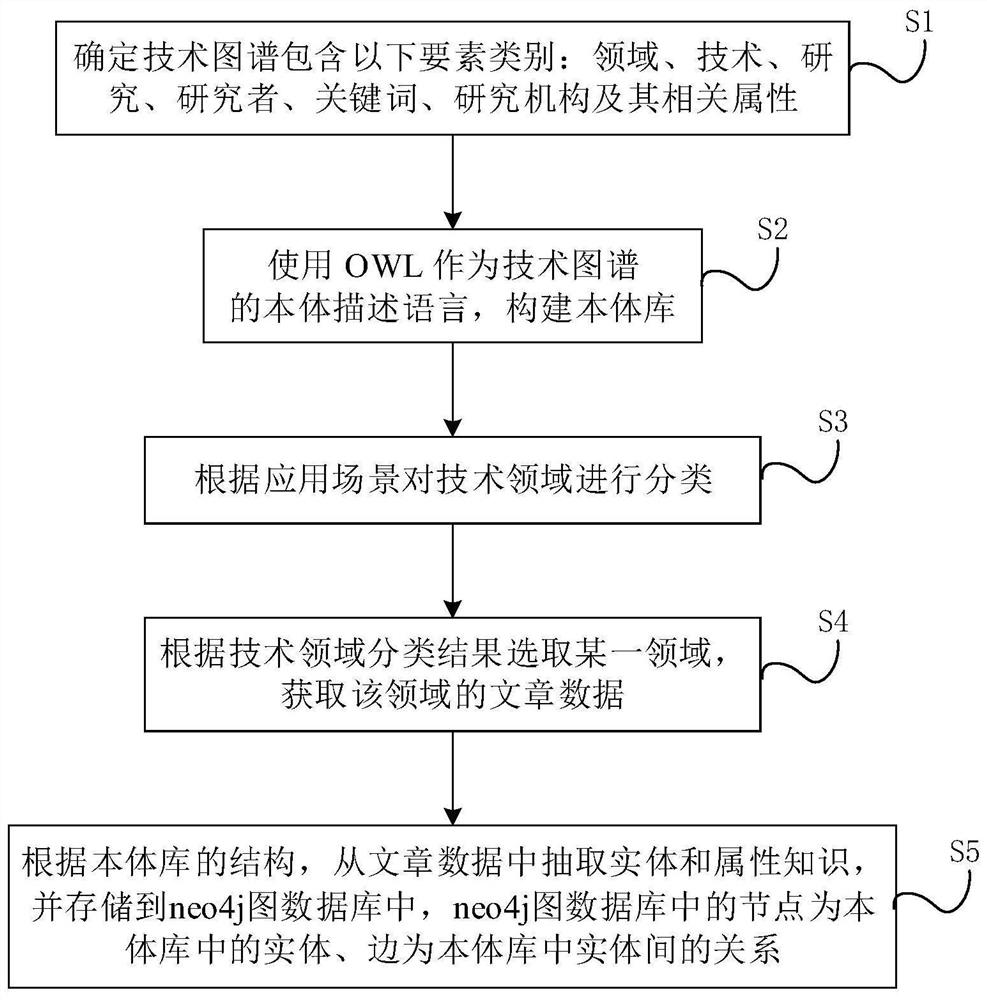
S1:确定技术图谱包含以下要素类别:领域、技术、研究、研究者、关键词、研究机构及其相关属性;
S2:使用OWL作为技术图谱的本体描述语言,构建本体库;
所述本体库的构建具体包括以下步骤:
S21:确定本体库的领域;
S22:根据步骤S1中的各个所述要素类别,确定本体库的实体及实体间的关系;
S23:根据所述要素类别和预设的指定范围,导入文章数据,形成原始数据表;
S24:对原始数据表进行数据清洗;
S25:定义用于代表领域内相关概念的类;
S26:明确定义实体的属性以及值域;
S3:根据应用场景对技术领域进行分类;
S4:根据步骤S3中的技术领域分类结果选取某一领域,获取该领域的文章数据;
S5:根据所述本体库的结构,从步骤S4中获取的所述文章数据中抽取实体和属性知识,并存储到neo4j图数据库中,所述neo4j图数据库中的节点为本体库中的实体、边为本体库中实体间的关系。
进一步地,步骤S5中,所述将文章数据存储到neo4j图数据库中,具体包括以下步骤:
将从步骤S4中获取的所述文章数据,清洗后保存为Excel格式文件;在ES中通过HTTP Restful API建立对应的实体类;遍历Excel格式文件,逐行调用HTTP Restful API将数据写入ES;批量导出ES中的数据集,以json文件形式保存,编写脚本将json文件批量导入neo4j图数据库中。
进一步地,所述neo4j图数据库以RDF形式表示的知识。
进一步地,所述本体库的实体包括领域、技术、研究、研究者、关键词和研究机构。
进一步地,步骤S26中,所述实体的属性包括对象属性和数据属性。
进一步地,步骤S26中,所述对象属性的值域为一个实体对象,所述数据属性的值域为一个数值。
本发明还提供一种基于图数据库的技术图谱构建系统,包括:
要素类别确定模块:确定技术图谱包含以下要素类别:领域、技术、研究、研究者、关键词、研究机构及其相关属性;
本体库构建模块:使用OWL作为技术图谱的本体描述语言,构建本体库;
所述本体库的构建具体包括以下步骤:
S21:确定本体库的领域;
S22:根据步骤S1中的各个所述要素类别,确定本体库的实体及实体间的关系;
S23:根据所述要素类别和预设的指定范围,导入文章数据,形成原始数据表;
S24:对原始数据表进行数据清洗;
S25:定义用于代表领域内相关概念的类;
S26:明确定义实体的属性以及值域;
技术领域分类模块:根据应用场景对技术领域进行分类;
文章数据获取模块:根据技术领域分类模块中的技术领域分类结果选取某一领域,获取该领域的文章数据;
图数据库存储模块:根据所述本体库的结构,从文章数据获取模块中获取的所述文章数据中抽取实体和属性知识,并存储到neo4j图数据库中,所述neo4j图数据库中的节点为本体库中的实体、边为本体库中实体间的关系。
进一步地,图数据库存储模块中,所述将文章数据存储到neo4j图数据库中,具体包括以下步骤:
将从步骤S4中获取的所述文章数据,清洗后保存为Excel格式文件;在ES中通过HTTP Restful API建立对应的实体类;遍历Excel格式文件,逐行调用HTTP Restful API将数据写入ES;批量导出ES中的数据集,以json文件形式保存,编写脚本将json文件批量导入neo4j图数据库中。
进一步地,所述本体库的实体包括领域、技术、研究、研究者、关键词和研究机构。
进一步地,步骤S26中,所述实体的属性包括对象属性和数据属性,所述对象属性的值域为一个实体对象,所述数据属性的值域为一个数值。
与现有技术相比,本发明具有以下优点:
本实施例首先对技术图谱的要素进行了分析,提出了领域知识图谱的本体库构建方法,并完成了本体库构建。通过分析基于关系数据库的知识图谱利弊,改进了知识的存储策略,提出了基于图数据库的知识图谱构建方法,并完成了基于Neo4j的技术图谱构建。基于结构化数据抽取的知识准确性高,覆盖面广;基于Neo4j构建的知识图谱能形象地展示图谱中的实体和实体间关系信息,并且提供了良好的交互方式;由实验结果可知,技术图谱包含的知识准确且全面,为开发后续基于图谱的决策辅助功能打下了良好的基础。
附图说明
图1为本发明实施例提供一种基于图数据库的技术图谱构建方法的流程示意图;
图2为本发明实施例提供一种技术图谱的知识框架图;
图3为本发明实施例提供一种技术图谱各实体的关联关系图;
图4为本发明实施例中对作者共现网络进行搜索的结果图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
实施例1
如图1所示,本实施例提供一种基于图数据库的技术图谱构建方法,包括以下步骤:
S1:确定技术图谱包含以下要素类别:领域、技术、研究、研究者、关键词、研究机构及其相关属性;
S2:使用OWL作为技术图谱的本体描述语言,构建本体库;
本体库的构建具体包括以下步骤:
S21:确定本体库的领域;
S22:根据步骤S1中的各个要素类别,确定本体库的实体及实体间的关系,具体地,本体库的实体包括领域、技术、研究、研究者、关键词和研究机构;
S23:根据要素类别和预设的指定范围,导入文章数据,形成原始数据表;
S24:对原始数据表进行数据清洗;
S25:定义用于代表领域内相关概念的类;
S26:明确定义实体的属性以及值域,具体地,实体的属性包括对象属性和数据属性,对象属性的值域为一个实体对象,数据属性的值域为一个数值;
S3:根据应用场景对技术领域进行分类;
S4:根据步骤S3中的技术领域分类结果选取某一领域,获取该领域的文章数据;
S5:根据本体库的结构,从步骤S4中获取的文章数据中抽取实体和属性知识,并存储到neo4j图数据库中,neo4j图数据库中的节点为本体库中的实体、边为本体库中实体间的关系。
具体地,neo4j图数据库以RDF形式表示的知识
将文章数据存储到neo4j图数据库中,具体包括以下步骤:
将从步骤S4中获取的文章数据,清洗后保存为Excel格式文件;在ES中通过HTTPRestful API建立对应的实体类;遍历Excel格式文件,逐行调用HTTP Restful API将数据写入ES;批量导出ES中的数据集,以json文件形式保存,编写脚本将json文件批量导入neo4j图数据库中。
该基于图数据库的技术图谱构建方法,在具体实施时包括以下步骤:
一、技术图谱的要素分析
电力公司所构建的技术图谱,是反映能源互联网领域相关技术及其之间拓扑关系的网状结构图谱,用于为科技创新管理与决策提供支撑。因此,技术图谱应以能源互联网领域的科技创新数据集为依托,整合并反映科技创新相关的各类要素。经过梳理,可以确定技术图谱中包含以下要素类别:领域、技术、研究、研究者、关键词、研究机构及其相关属性。知识框架如图2所示。
技术图谱的知识要素的描述内容见表1:
表1技术图谱的知识要素及描述
二、技术图谱的本体库构建
本体库的质量对于知识图谱极其重要,本体库中定义的术语及关系是否完整和准确直接影响了知识图谱构建的质量。
现有技术中本体库构建存在两种方式,即自顶向下的方式和自底向上的方式。一般来说,开放域的知识图谱多采用自底向上的方式构建本体,而领域知识图谱由于其知识范围固定,知识概念相对明确,故采用自顶向下的方式构建本体。在实际操作中,由于在开始构建知识图谱时,尚不清楚收集数据的范围,也不清楚数据使用方式,通常先把所有的数据收集起来,形成一个庞大的数据集,然后再根据数据内容总结其特点,对数据进行整理、分析、归纳、总结,最后形成数据模型。因此,在本实施例中,仍然采用自底向上的方式构建技术图谱的本体库,具体包括以下步骤:
2.1、技术图谱所使用的本体描述语言
本体通过描述知识图谱中的概念建立真实世界的抽象模型。本体描述语言用于对领域内的模型进行形式化的、清晰的描述。目前有大量学者活跃在该领域,并且产生了多种本体描述语言,例如RDF、RDFS、XOL、Ontolingua等。经过调研,本实施例决定使用OWL作为技术图谱的本体描述语言。OWL即Web Ontology Language,其具有如下优势:
1)OWL是W3C推荐的语义网技术栈的核心技术之一。基于OWL构建的本体库能够获得更多的应用场景。
2)OWL的表达能力很强。OWL本质上是RDFS语言的一个扩展,其添加了额外的预定义词汇,能够准确的描述科创领域的相关实体、实体间关系及属性。
3)OWL提供快速、灵活的数据建模能力,能够快捷地对本体库进行建模。
4)基于OWL构建的知识图谱,兼容主流的推理引擎,具备高效的自动推理能力,能对构建后的知识图谱进行更新和扩展。
综上,OWL以其标准化、优秀的表达能力、灵活的数据建模能力以及高效的自动推理能力在众多本体描述语言中脱颖而出,使得基于OWL的本体的构建更加便捷,且构建后的本体库实用性更强。
2.2、领域内本体库的构建流程
本体属于知识图谱中的概念层,以形式化地方式对概念及其之间的联系给出明确的定义和约束,规范了数据层中实体的表示。构建领域内本体库需要构建者对目标领域有一个清晰的认识,并且在构建前需要制定一套系统化的实现方式。对于领域知识图谱,本实施例采用如下的方法构建本体库:
1)明确本体的领域及构建的目的;
2)抽象出领域内实体的相关概念;
3)导入数据形成原始数据表;
4)根据原始数据表特点进行多轮数据清洗;
5)定义用于代表领域内相关概念的类;
6)定义实体的属性以及值域;
7)定义其它的约束条件。
三、技术图谱的本体库实现方法
根据上文提出的本体库构建方法,完成技术图谱概念层的构建,具体实现步骤如下:
1)明确本体的领域及构建的目的。需要构建的是一个科技创新领域的本体库,完成对科创领域相关知识的抽象,继而实现一个服务于科技创新工作的能源互联网技术图谱,并借助技术图谱提升科技创新管理和决策水平。
2)抽象出领域内实体的相关概念。按照之前章节对技术图谱的分析,该图谱应包含(技术)领域、技术、研究、研究者、关键词、研究机构等元素的信息。其中领域和技术呈层次关联关系,研究是核心元素,包含发表时间、所属领域、相关技术、发表作者、所属机构……等众多属性,并与其他元素形成不同的关系。
3)从中国知网上导入指定范围(时间和类别)的文章数据,主要是发表在期刊上的论文数据,先导入数据库形成原始数据表。
4)根据原始数据表特点进行多轮数据清洗。经过对原始数据表的分析,发现知网数据存在部分数据不规范,单位和作者之间的关系模糊等特点。因此,对原始数据进行数据清洗,剔除存在较多及明显问题的数据,尝试对单位和作者之间的关系进行梳理,形成相对较为规范的数据表。
5)定义用于代表领域内相关概念的类。结合概念模型和清洗后的数据表建立类,包括领域、技术、研究者、研究人员、关键词、机构、期刊7个类。
6)在数据清洗的基础上进一步明确定义实体的属性以及值域。本体中的实体属性分为两类,分别为对象属性(Object Properties)和数据属性(Data Properties)。对象属性用于描述对象之间的关系,其值域为一个实体对象;数据属性用于描述实体的固有属性,并且具有传递性,即上位实体拥有的数据属性,下位实体也继承该属性,数据属性的值域为一个数值。
以研究为例,其实体属性最终如表2所示。
表2技术图谱中“研究”实体的属性值
至此,完成了技术图谱的本体库构建。
四、技术领域分类
技术图谱中涉及到大量的专业技术领域和具体的技术方向,因此需要对技术领域和技术方向进行分类,便于对大量的研究成果进行检索和维护。根据应用场景,可以有不同的技术领域分类法,本实施例提供以下两种分类法。
4.1、传统技术领域分类
传统技术领域分类法主要是国家和各级指导部门提供的技术领域分类标准、指南、规范等。典型的代表是中图分类法。
《中图分类法》是《中国图书馆分类法》的简称,是我国建国后编制出版的一部具有代表性的大型综合性分类法,是当今国内图书馆使用最广泛的分类法体系。根据图书资料的特点,按照从总到分、从一般到具体的编制原则确定分类体系,在五个基本部类的基础上,组成二十二个大类。本次实施例只涉及到自然科学基本部类。
4.2、自定义技术领域分类
除了政府和专业协会等权威知道部门提供的传统技术分类之外,还有一些企业或者平台根据自身应用特点,在传统技术领域分类基础上整体提供了自定义的技术领域分类。这些分类标准往往重点关注本单位本部门重点关注的技术领域和方向。
五、知识抽取技术
本体库构建完成后,需要将本体库中的本体及属性实例化,完成对知识图谱中数据层的填充。因此,本实施例将基于经过预处理的结构化数据,从中抽取实体及属性等知识,将数据库中的数据转化为用RDF形式表示的知识。接下来具体介绍技术图谱的数据来源、数据存储方式、数据爬取流程,以及数据转化为知识的方法。
1)数据来源:本实施例的主要数据来源是中国知网过去10年间的发表在电力行业科技期刊的所有论文。
2)数据存储:本实施例的主要数据存储在neo4j图数据库中,为了进行某些特定的检索,同时也在ES中进行备份。
3)数据导入:将从知网获取的历史存量数据,清洗后保存为Excel格式;在ES中通过HTTP Restful API建立对应的实体类;遍历Excel文件,逐行调用HTTP Restful API将数据写入ES;批量导出ES中的数据集,以json文件形式保存,编写脚本将json文件批量导入neo4j。
六、基于NEO4J的知识图谱构建
6.1、关系数据库的知识存储缺陷
在知识图谱中,知识是大量的复杂、低结构化、高连接关系的数据。当这些知识被频繁地查询和更新时,关系数据库会在每次处理时产生大量的表连接,从而导致性能问题。由于图数据库独特的数据存取方式,使其在这种使用场景下比关系型数据库的性能高出几千倍以上。因此,相比于关系数据库,图数据库在处理这种知识类的数据上具有优势。
关系数据库在知识图谱的设计和使用上也存在一些不便,当新实体或关系到来时,添加新的表或字段会给开发和升级带来很多工作,而图数据库仅需要插入这些节点或边即可。图数据库利用图结构存储这些数据,既能表现出良好的性能,又便于设计和使用。
此外,基于关系数据库的知识存储通过实体和关系映射来达到知识获取的目的,但是其缺点在于每次进行知识访问需要进行两次翻译,当知识的查询和检索操作比较频繁时,其效率上的劣势也会凸显。并且,RDF的知识表示形式与基于SPARQL的知识查询也会带来一些使用上的不便。
因此,本实施例对基于关系数据库的知识存储方式进行改进,利用图数据库来存储知识图谱。
6.2、NEO4j介绍
Neo4j是一个基于图存储的NoSQL数据库。它具有图数据库的优良特性,能够完美地对知识图谱领域内的实体和关系进行映射,且对于高连接关系的数据具有良好性能。目前,市面上基于图存储的数据库众多,质量和性能参差不齐。文献显示,Neo4j在查询和存储等方面的性能均优于其他数据库,在业界具有广泛的应用。本项目选用Neo4j作为存储知识图谱的数据库。
Neo4j中包含两种基本的数据类型:节点(Nodes)和边(Edges)。其中,节点表示知识图谱中的实体,边表示知识图谱中实体间的关系。在Neo4j中,本实施例进行以下设计,实体类型如下:
1)领域:能源互联网的相关领域;
2)技术:能源互联网的相关技术;
3)研究:论文、专利及其他成果物;
4)研究者:研究人员;
5)关键词:论文的关键词;
6)研究机构:研究单位。
各实体间存在如图3所示的关联关系:
七、技术验证
在上述设计基础上,本实施例首先导入了小批量的论文数据进行技术验证,在暂时忽略发表者与发表结构之间关系的基础上,完成整个技术图谱的构建过程。最终通过neo4j对数据进行各类检索和可视化展示。
图4为对作者共现网络进行搜索。
通过以上的示例可知,本实施例已经基于本题库和知识抽取完成了技术图谱的构建工作。技术图谱中的节点类型及关系类型蕴含了本体库的设计思路,图谱中的实体信息和实体间的语义信息展现了抽取后的科技创新领域内的各类实体及关系。构建完成的知识图谱节点和关系类型设计合理,知识准确且全面,可用于科创领域内多种信息检索。因此,本实施例所提出的本体库的构建方法是可行的;基于结构化数据抽取的知识准确性高,覆盖面广;基于Neo4j构建的知识图谱能形象地展示图谱中的实体和实体间关系信息,并且提供了良好的交互方式。
综上,本实施例首先对技术图谱的要素进行了分析,提出了领域知识图谱的本体库构建方法,并完成了本体库构建。通过分析基于关系数据库的知识图谱利弊,改进了知识的存储策略,提出了基于图数据库的知识图谱构建方法,并完成了基于Neo4j的技术图谱构建。由实验结果可知,技术图谱包含的知识准确且全面,为开发后续基于图谱的决策辅助功能打下了良好的基础。
本实施例还提供一种基于图数据库的技术图谱构建系统,包括:
要素类别确定模块:确定技术图谱包含以下要素类别:领域、技术、研究、研究者、关键词、研究机构及其相关属性;
本体库构建模块:使用OWL作为技术图谱的本体描述语言,构建本体库;
本体库的构建具体包括以下步骤:
S21:确定本体库的领域;
S22:根据步骤S1中的各个要素类别,确定本体库的实体及实体间的关系;
S23:根据要素类别和预设的指定范围,导入文章数据,形成原始数据表;
S24:对原始数据表进行数据清洗;
S25:定义用于代表领域内相关概念的类;
S26:明确定义实体的属性以及值域;
技术领域分类模块:根据应用场景对技术领域进行分类;
文章数据获取模块:根据技术领域分类模块中的技术领域分类结果选取某一领域,获取该领域的文章数据;
图数据库存储模块:根据本体库的结构,从文章数据获取模块中获取的文章数据中抽取实体和属性知识,并存储到neo4j图数据库中,neo4j图数据库中的节点为本体库中的实体、边为本体库中实体间的关系。
图数据库存储模块中,将文章数据存储到neo4j图数据库中,具体包括以下步骤:
将从步骤S4中获取的文章数据,清洗后保存为Excel格式文件;在ES中通过HTTPRestful API建立对应的实体类;遍历Excel格式文件,逐行调用HTTP Restful API将数据写入ES;批量导出ES中的数据集,以json文件形式保存,编写脚本将json文件批量导入neo4j图数据库中。
本体库的实体包括领域、技术、研究、研究者、关键词和研究机构。
步骤S26中,实体的属性包括对象属性和数据属性,对象属性的值域为一个实体对象,数据属性的值域为一个数值。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 一种基于图数据库的技术图谱构建方法和系统
- 一种基于图数据库的建筑设计规范知识图谱构建方法