一种基于场景及意图识别的智能服务系统
文献发布时间:2023-06-19 11:54:11
技术领域
本发明涉及智能服务系统领域,尤其涉及一种基于场景及意图识别的智能服务系统。
背景技术
现有技术中,智能设备越来越多,如小爱音箱,小度音箱等,一些智能化操作也很常见,如,通过iPhone让siri打电话给通讯录里某个人,通过亚马逊echo音箱播放音乐等。
但是,现有的技术只针对非常有限的通用场景。并未针对场景进行服务预置及筛选;现有的技术通常不能直达服务,大多情况下需要用户进行干预,比如:小爱音箱,小度音箱等,会根据询问给出参考选项,但并不能直达服务。
发明内容
(一)发明目的
为解决背景技术中存在的技术问题,本发明提出一种基于场景及意图识别的智能服务系统,自动识别场景,语音直呼服务,降低用户使用成本,提升用户体念。
(二)技术方案
为解决上述问题,本发明提出了一种基于场景及意图识别的智能服务系统,包括以下工作步骤:
S1:针对不同场景,划分服务集合,与场景紧密结合;
S2:针对不同场景,通过与场景方合作以建立并提供常用服务集合,供用户使用;
S3:利用身份及场景识别技术,自动识别用户的身份以及用户所在场景;
S4:系统根据用户所在场景,筛选特定服务集合;
S5:系统识别用户意图;
S6:系统匹配服务集合以及用户意图,以推荐最匹配服务;
S7:系统根据用户身份信息、时间信息和地点信息匹配用户相关信息,以及其他服务需要的参数信息;
S8:系统根据服务及其所需参数,唤起服务,直接给出用户期待结果。
优选的,系统利用人脸抓拍识别技术或生物识别技术获取人的身份信息。
优选的,系统利用信号采集技术以及定位技术获取当前位置信息。
优选的,系统利用环境感知技术以及计算机视觉分析技术获取所在场景信息。
本发明中,利用相关传感器、摄像机、无线信号接收器及AI技术,识别用户身份、所在处景,推测用户潜在意图;系统针对不同场景,为用户预置常用服务集合;系统通过匹配意图与服务集合,快速为用户筛选服务;系统自动识别场景,语音直呼服务,降低用户使用成本,提升用户体念。
本发明中,针对特定场景来划分并提供服务,服务的使用场景、使用对象及使用边界均比较可控,具有更好的可实施性;系统通过与场景方进行合作的方式提供场景服务,更容易得到场景方的支持;系统针对特定场景来识别用户意图,更加准确高效;系统针对特定场景更容易获取服务依赖的信息,更容易做到直达服务结果。
附图说明
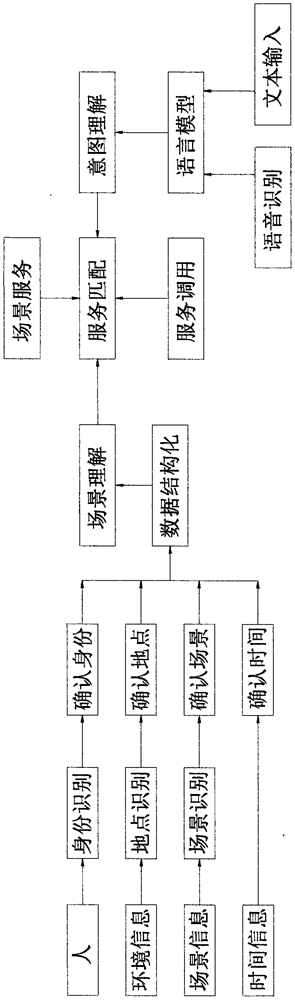
图1为本发明提出的基于场景及意图识别的智能服务系统的流程示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
如图1所示,本发明提出的一种基于场景及意图识别的智能服务系统,包括以下工作步骤:
S1:针对不同场景,划分服务集合,与场景紧密结合;
S2:针对不同场景,通过与场景方合作以建立并提供常用服务集合,供用户使用;
S3:利用身份及场景识别技术,自动识别用户的身份以及用户所在场景;
S4:系统根据用户所在场景,筛选特定服务集合;
S5:系统识别用户意图;
S6:系统匹配服务集合以及用户意图,以推荐最匹配服务;
S7:系统根据用户身份信息、时间信息和地点信息匹配用户相关信息,以及其他服务需要的参数信息;
S8:系统根据服务及其所需参数,唤起服务,直接给出用户期待结果。
本发明中,利用相关传感器、摄像机、无线信号接收器及AI技术,识别用户身份、所在处景,推测用户潜在意图;系统针对不同场景,为用户预置常用服务集合;系统通过匹配意图与服务集合,快速为用户筛选服务;系统自动识别场景,语音直呼服务,降低用户使用成本,提升用户体念。
本发明中,针对特定场景来划分并提供服务,服务的使用场景、使用对象及使用边界均比较可控,具有更好的可实施性;系统通过与场景方进行合作的方式提供场景服务,更容易得到场景方的支持;系统针对特定场景来识别用户意图,更加准确高效;系统针对特定场景更容易获取服务依赖的信息,更容易做到直达服务结果。
在一个可选的实施例中,系统利用人脸抓拍识别技术或生物识别技术获取人的身份信息。
在一个可选的实施例中,系统利用信号采集技术以及定位技术获取当前位置信息。
在一个可选的实施例中,系统利用环境感知技术以及计算机视觉分析技术获取所在场景信息。
实施例:
S11:针对不同场景划分不同服务集合,并通过与场景方合作提供相应服务;
S12:利用人脸抓拍识别等生物识别技术可以获取人的身份(可以是其他生物识别技术),利用信号采集及定位技术可以获取当前位置(可以不同的是主被动定位技术),利用环境感知及计算机视觉分析技术可以获取所在场景(可以是不同的主被动技术),再加上时间信息,可获取人物、时间、地点及场景四要素;
S13:通过语音识别、文本输入,结合语言模型,对用户的意图进行理解;
S14:针对不同场景(如机场、商场、百货、火车站、医院等)提供常用服务,如:商业场景下的停车服务、缴费服务、导航服务、查找店铺服务、抢优惠券服务、参与营销活动服务等;
S15:结合所提供服务、用户意图及四要素,自动为用户匹配最贴切的服务;
S16:根据匹配结果一键调起服务,降低操作复杂度,提升用户使用体验;
S17:在用户意图及四要素有部分缺失的情况下,仍可根据部分知识为用户匹配可能喜欢的服务;
S18:特别是针对特定场景的场景服务以及根据场景及意图的自动服务匹配技术,如机场、商场、百货、火车站、医院等场景下的差异化服务自动匹配调起,并根据用户身份、时间、地点等服务所需参数信息,直接给出预期结果。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 一种基于场景及意图识别的智能服务系统
- 一种基于深度学习的场景自适应Attention多意图识别方法