一种基于贪心森林的多元数据关联分析算法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明涉及网络安全监测技术领域,尤其涉及一种基于贪心森林的多元数据 关联分析算法。
背景技术
随着大数据技术和网络安全技术的发展,网络中各类设备和系统种类日志增 多,生成的日志量、第三方告警量也急剧增加,给安全分析人员带来了新的挑战。 如何将海量结构化日志和第三方告警数据进行实时分析和关联分析,是网络分析 的一个难题。
传统关联分析软件多为完成功能为主,在实现层面缺乏科学的算法理论作为 指导,导致在处理大数据分析时,性能上没法得到保证,且随着规则数量的不断 增多,分析软件的性能也会呈线性下降。
因此,本发明提供一种基于贪心森林的多元数据关联分析算法。
发明内容
本发明的目的在于:为了解决上述问题,而提出的一种基于贪心森林的多元 数据关联分析算法。
为了实现上述目的,本发明采用了如下技术方案:一种基于贪心森林的多元 数据关联分析算法,依次包括如下内容:
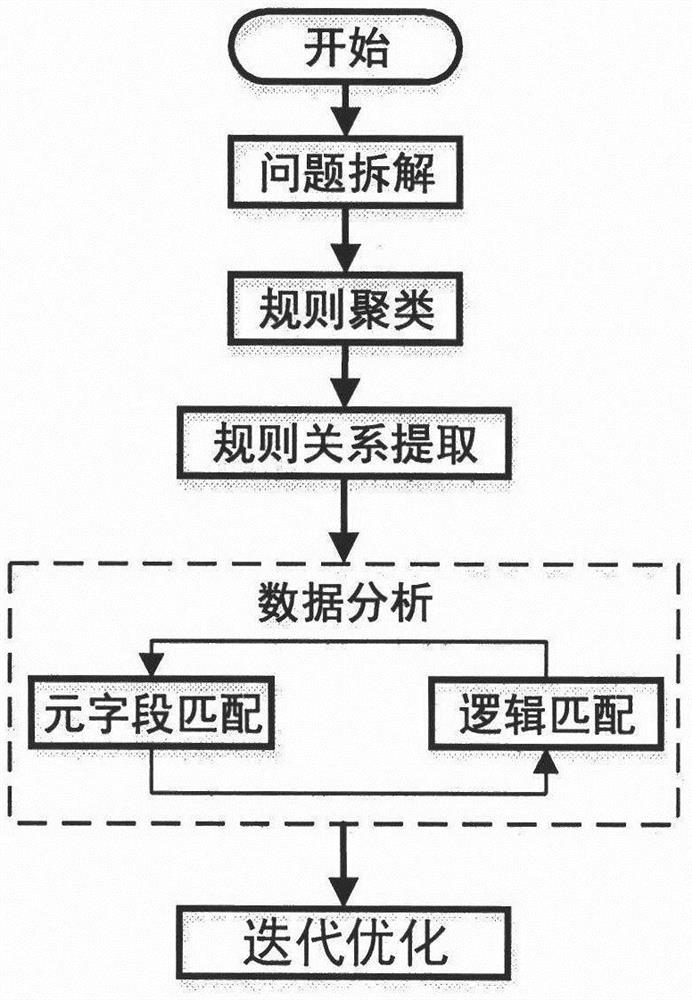
A.问题拆解单元:基于贪心算法理念将数据分析问题进行拆解,将问题拆解 为规则聚类,规则关系分类,元字段匹配以及逻辑匹配,并在每个步骤逐步应用 贪心算法进行优化;
B.规则聚类单元:将规则依据数据源类型进行聚类,形成规则树和规则森林;
C.规则关系提取单元:基于规则森林的根系关系,将规则之间的关系分为独 立关系、同根关系以及父子关系;
D.元字段匹配单元:针对关联分析过程中的元字段匹配过程进行优化;
E.逻辑匹配单元:针对AND逻辑匹配器和OR逻辑匹配器的特点,针对关联 分析过程中的逻辑匹配过程进行优化;
F.迭代优化单元:整合每个步骤优化的结果,从整体上对数据分析的性能进 行优化。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
本发明中,基于贪心森林算法,依据用户配置的关联分析规则,将整个规则 体系聚合成规则森林,依据数据源作为根系将规则树之间的关系分为独立规则 树、同根规则树以及父子规则树。针对规则匹配的过程中的元字段匹配和逻辑匹 配两类原子操作进行优化,从而极大的提高关联分析效率。
附图说明
图1示出了贪心森林的多元数据关联分析算法的流程图;
图2示出了贪心森林规则体系规则间的关系示意图,规则4和规则1,规则 4和规则2,规则4和规则3都是独立关系;规则1、规则2以及规则3间互为 同根关系;规则1和规则2为父子关系;
图3示出了贪心森林多元数据关联分析算法中逻辑匹配优化前后流程对比 图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清 楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全 部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳 动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1-3,本发明提供一种技术方案:一种基于贪心森林的多元数据关 联分析算法,依次包括如下内容:
A.问题拆解单元:基于贪心算法理念将数据分析问题进行拆解,将问题拆解 为规则聚类,规则关系分类,元字段匹配以及逻辑匹配,并在每个步骤逐步应用 贪心算法进行优化;
B.规则聚类单元:将规则依据数据源类型进行聚类,形成规则树和规则森林;
C.规则关系提取单元:基于规则森林的根系关系,将规则之间的关系分为独 立关系、同根关系以及父子关系;
D.元字段匹配单元:针对关联分析过程中的元字段匹配过程进行优化;
E.逻辑匹配单元:针对AND逻辑匹配器和OR逻辑匹配器的特点,针对关联 分析过程中的逻辑匹配过程进行优化;
F.迭代优化单元:整合每个步骤优化的结果,从整体上对数据分析的性能进 行优化。
下面结合图3进行相应的理论和公式推导,证明算法的有效性。 分别从单规则匹配和多规则匹配两个方面来分析贪心森林算法的优 化效果:
1)单规则匹配:
针对单规则匹配做以下设定:
i.每个字段匹配的时间代价为Tp;
ii.每个逻辑匹配操作的时间代价为Tc;
iii.每个规则需要匹配的字段匹配数量为m;
iv.逻辑匹配数量为n;
v.AND逻辑匹配器数量为α;
vi.OR逻辑匹配器数量为β。
a)优化前:
元字段匹配过程的时间代价为:
逻辑匹配的时间代价为:
单个安全事件的匹配的时间代价为:
在此前提下定义两类逻辑匹配器:
a.AND逻辑匹配器:匹配结果中有一个不满足则返回false,数量为α;
b.OR逻辑匹配器:匹配结果中有一个满足则返回true,数量为β。
优化前的时间匹配代价为:
其中α+β=n
T=
b)优化后:
针对优化后的单规则匹配做以下设定:
i.数据源S
ii.单个逻辑匹配操作的时间代价为Tc;
iii.AND逻辑匹配器在第α
iv.OR逻辑匹配器在第β
v.优化后字段匹配的次数为m
由流程图可得出,m
由公式得出,由于m和n是固定因子,因此影响时间优化率的因子有: α
2)多规则匹配时:
a)优化前:
传统关联分析中每条规则相互独立,因此k条规则完成匹配的时间代价为:
其中,
b)优化后:
其中,
i.共性匹配因子数量为p;
ii.每个因子的匹配次数为q;
iii.共性逻辑匹配器数量为u;
iv.规则数量为k。
综上所述,针对三种关系的规则,运用贪心森林匹配算法所优化的时间代价 ΔT分别为:
独立关系:
ΔT=0
同根关系:
ΔT=(k-1)*(Tc
继承关系:
ΔT
经过公式推导得出,贪心森林匹配算法针对关联分析过程的优化作用比较显 著,且随着规则数量的不断增加,性能的下降较为缓和。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限 于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明 的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之 内。
- 一种基于贪心森林的多元数据关联分析算法
- 一种基于正则化贪心森林算法非侵入式负荷辨识方法