基于气象的城市运行管理大数据分析预测方法和系统
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及气象技术领域,特别涉及一种基于气象的城市运行管理大数据分析预测方法和系统。
背景技术
近年来,大数据技术发展迅猛,成为世界各国研究和角逐的热点。一方面,大数据技术应用的范围很广,尤其是在医疗、金融、安防、汽车等领域较为突出。气象应用也一直是高性能计算的重要领域,大数据技术给观测、预报、服务等业务的发展带来不可多得的机遇,也带来极大的挑战。因此,大数据技术的发展的特点对气象业务也产生了重大影响。另一方面,机器学习、模型训练处理以及计算机视觉等重大的大数据技术都在不同的领域对气象产生了深刻影响,并不同程度的影响到受众的生活。
发明内容
为解决现有技术中存在的上述不足之处,本发明提供了一种基于气象的城市运行管理大数据分析预测方法和系统,能够建立长时间滚动累计事件总数量以及特定事件场景的预测模型。
本发明提供如下技术方案:
第一方面,一种基于气象的城市运行管理大数据分析预测方法,其包括:
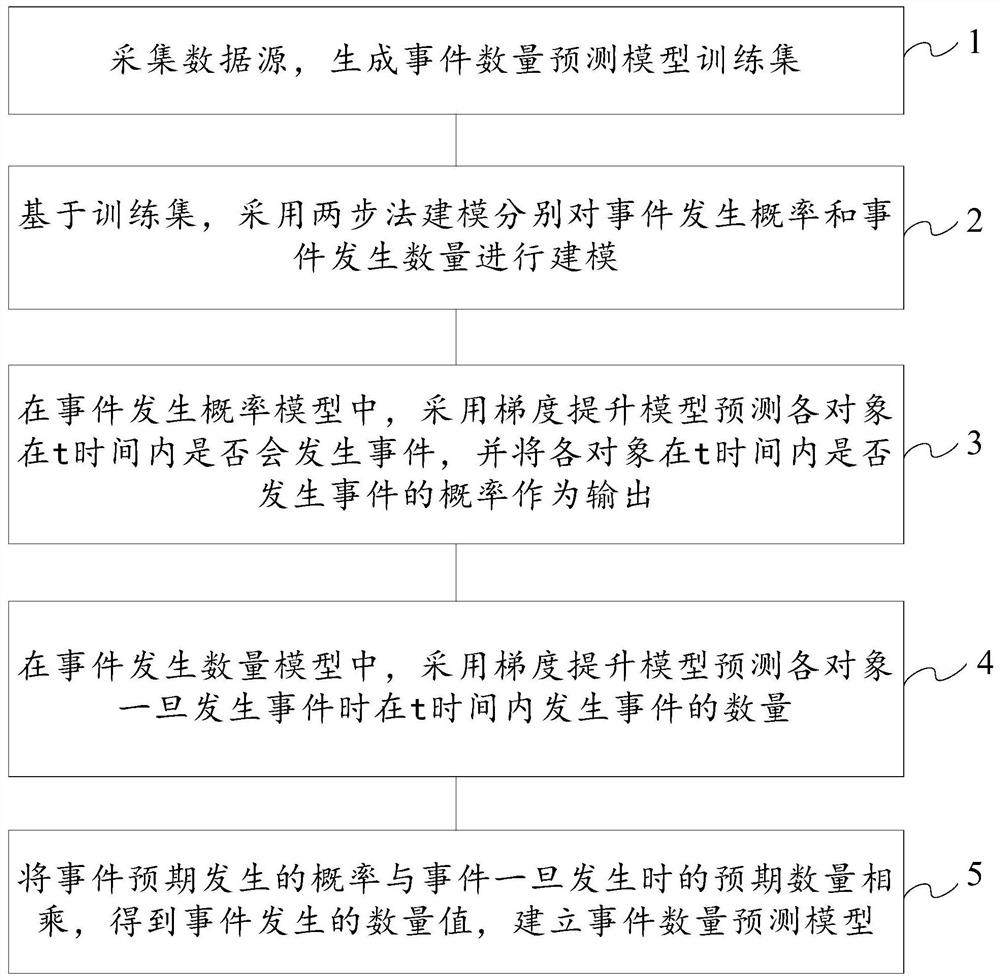
采集数据源,生成事件数量预测模型训练集;
基于所述训练集,采用两步法建模分别对事件发生概率和事件发生数量进行建模;
在事件发生概率模型中,采用梯度提升模型预测各对象在t时间内是否会发生事件,并将各对象在t时间内是否发生事件的概率作为输出;
在事件发生数量模型中,采用梯度提升模型预测各对象一旦发生事件时在t时间内发生事件的数量;
将事件预期发生的概率与事件一旦发生时的预期数量相乘,得到事件发生的数量值,建立事件数量预测模型。
作为本发明预测方法的一种优选技术方案,所述数据源包括气象自动站数据、格点化气象要素预报数据、网格事件数据、热线事件数据以及110气象灾情数据。
作为本发明预测方法的一种优选技术方案,所述梯度提升模型为基于LightGBM的梯度提升模型,在此基础上引入随机截距模型和随机效应模型对模型进行优化升级。
作为本发明预测方法的一种优选技术方案,还包括针对时间数据、历史和实况气象要素数据以及历史和实况城市运行数据(网格数据、热线数据、110气象灾情数据)进行特征挖掘,并作为所述事件数量综合预测模型的输入,加入所述模型训练。
作为本发明预测方法的一种优选技术方案,在所述历史和实况城市运行数据特征的挖掘中,采用偏自相关系数来判定事件发生数量在时间上的延后性。
作为本发明预测方法的一种优选技术方案,在历史和实况气象要素数据特征的挖掘上,考量各气象要素对事件发生数量的瞬时以及历史影响,并且,在历史气象要素对事件发生数量的影响上,采用交叉相关系数来计算事件发生数量与不同气象要素在时间上的滞后关系。
作为本发明预测方法的一种优选技术方案,在建立所述事件数量预测模型的同时,还包括采用所述两步法建模选取与气象影响密切相关的事件场景,建立场景模型。
作为本发明预测方法的一种优选技术方案,还包括建立事件风险预警模型:通过结合历史事件发生数量分位数以及事件发生数的绝对阈值,制定事件预警标准。
作为本发明预测方法的一种优选技术方案,还包括建立气象影响指数模型:
基于事件数量预测模型,计算出各个气象要素特征对于事件数量预测的百分比贡献度;
将所述气象要素特征在认定气象要素范围的百分比贡献值作为基准,计算当前气象要素特征的百分比贡献值与所述基准的绝对偏差,将所述绝对偏差作为所述气象要素特征的影响指数。
第二方面,一种基于气象的城市运行管理大数据分析预测系统,该系统用于执行上述基于气象的城市运行管理大数据分析预测方法。
由于采用上述技术方案,使得本发明能够具有以下有益效果:
事件数量预测模型基于经典的机器学习算法梯度提升模型(Gradient BoostingMachine),并使用了两步法建模、随机截距模型和随机效应模型对梯度提升模型进行了改进,得以更好的捕捉事件发生的规律。而在模型实际运行中,通过融合多类数据源(气象自动站数据、格点化气象要素预报数据、网格事件数据、热线事件数据以及110气象灾情数据),实现了48小时内分街镇,逐12小时的事件发生数量预测和对应风险预警等级。而在事件数量预测模型的基础上,通过计算气象要素对于事件数量预测值的贡献值,得到了风速、降水、气温这三类气象要素对事件数量发生的影响指数。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明基于气象的城市运行管理大数据分析预测方法的总流程图。
图2为本发明基于气象的城市运行管理大数据分析预测方法的模型技术路线图。
图3为本发明基于气象的城市运行管理大数据分析预测方法的一实施例的实施流程图。
图4为本发明基于气象的城市运行管理大数据分析预测方法的特征工程流程示意图。
具体实施方式
为让本发明的上述目的、特征和优点能更明显易懂,以下结合附图对本发明的具体实施方式作详细说明。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其它不同于在此描述的其它方式来实施,因此本发明不受下面公开的具体实施例的限制。
参阅图1~4,本发明实施例提供了一种基于气象的城市运行管理大数据分析预测方法和系统,使用了多种统计机器学习模型集成的方法,分别对城市街镇网格/热线(如上海网格、浦东网格、徐汇网格、浦东热线、徐汇热线)以建立了滑动12小时事件总数量以及特定事件场景的预测模型,预测时效为48小时;110气象灾情建立了暴雨和大风1小时事件数量预测模型,预测时效为48小时。根据事件数量预测模型,设计了由风速、降水、气温三类气象要素特征构成的气象影响指数,用于量化不同气象要素对城市运行情况的影响程度。最终根据历史事件数据分布,设计了事件预警标准,配合事件数量预测模型形成风险预警体系。
事件数量预测模型基于经典的机器学习算法梯度提升模型(Gradient BoostingMachine),并使用了两步法建模、随机截距模型和随机效应模型对梯度提升模型进行了改进,得以更好的捕捉事件发生的规律。而在模型实际运行中,通过融合多类数据源(气象自动站数据、格点化气象要素预报数据、网格事件数据、热线事件数据以及110气象灾情数据),实现了48小时内分街镇,逐12小时的事件发生数量预测和对应风险预警等级。而在事件数量预测模型的基础上,通过计算气象要素对于事件数量预测值的贡献值,得到了风速、降水、气温这三类气象要素对事件数量发生的影响。按数据类型和来源部署有全市、浦东、徐汇网格事件数量预测模型,浦东、徐汇热线事件数量预测模型以及全市110气象灾情数量预测模型。
具体来说,本发明基于气象的城市运行管理大数据分析预测方法包括如下步骤:
步骤1:采集数据源,生成事件数量预测模型训练集;
步骤2:基于训练集,采用两步法建模分别对事件发生概率和事件发生数量进行建模;
步骤3:在事件发生概率模型中,采用梯度提升模型预测各对象在t时间内是否会发生事件,并将各对象在t时间内是否发生事件的概率作为输出;
步骤4:在事件发生数量模型中,采用梯度提升模型预测各对象一旦发生事件时在t时间内发生事件的数量;
步骤5:将事件预期发生的概率与事件一旦发生时的预期数量相乘,得到事件发生的数量值,建立事件数量预测模型。
其中,步骤1中的数据源包括气象自动站数据、格点化气象要素预报数据、网格事件数据、热线事件数据以及110气象灾情数据等城市运行管理大数据。
步骤2至步骤4中的梯度提升模型为基于LightGBM的梯度提升模型。对象可以是全市、行政区或街镇。
模型在训练中以及实时线上预测时,还进行了特征挖掘,针对时间数据、历史和实况气象要素数据以及历史和实况城市运行数据(网格数据、热线数据、110气象灾情数据)进行特征挖掘,加入模型训练以及实时线上预测。下文会对特征挖掘的方法及特点做详细说明。
另外,在建立事件数量预测模型的同时,还采用了两步法建模、随机截距模型和随机效应模型对模型进行升级优化选取与气象影响密切相关的事件场景,建立场景模型。并且通过结合历史事件发生数量分位数以及事件发生数的绝对阈值,制定事件预警标准,建立事件风险预警模型。还采用了各个气象要素特征对于事件数量预测的百分比贡献度建立了气象影响指数模型。
下面针对特定的模型目的对本发明基于气象的城市运行管理大数据分析预测模型的细节之处进一步说明如下:
模型目的:对上海网格、浦东网格、徐汇网格、浦东热线、徐汇热线以建立滑动12小时事件总数量以及特定事件场景的预测模型,110气象灾情建立1小时特定事件场景的预测模型。
一、模型所用数据源:
1、气象自动站实况数据
(1)数据源结构
模型在训练中以及实时线上预测时所使用的主要气象数据来源之一为全市气象自动站数据。其中各个站点的历史数据具体包括自动站名称、自动站经纬度坐标、自动站所属地市与街道、自动站要素数等字段。各个自动站实时监测的气象要素数据则包括了温度、雨量、风向、风速、2分钟风向、两分钟风速、极大风向、极大风速等字段。而在具体的事件预测模型训练以及实时上线进行数量预测时,选取了温度、雨量、极大风速作为模型的主要输入。
(2)数据预处理过程
通过如下计算过程生成了各个街镇的对应实况气象要素数据:
◆对于区/街镇内存在自动站的情况:
①将气象自动站与街镇进行空间匹配;
②计算每个区/街镇内的自动站的平均降雨量、最大风速以及最低气温、最高气温;
③将②中所得到的降雨量、风速,以及最高最低气温作为当前街镇对应时间的气象要素特征。
◆对于区/街镇内不存在自动站的情况:
街镇通过计算每个自动站与每个区/街镇之间的最小直线距离,获取距离最近并且存在对应观测值的自动站;
计算前述步骤①和②,计算得出当前区/街镇当前时间的气象要素特征。
2、格点化气象要素预报数据
(1)数据源结构
模型在实时线上预测时所使用的另一个主要气象要素数据源则是格点化气象要素预报数据。数据所存在的主要形式为格式化的气象要素预报栅格数据,栅格的大小为51×57,覆盖了上海的市区以及郊区范围。数据存贮的格式为NetCDF的多通道栅格数据。格点化气象要素预报的更新频率为一天两次,分别为每日的早上八点以及晚上八点。每次预报则会输出48小时内逐小时的格点气象要素预报数据。而格点化气象要素预报数据包括了云层覆盖百分比,10米高度风场,地面降水,相对湿度以及气温。而在模型实际上线运行过程中,则选取了10米高度风场,地面降水,以及气温作为模型的输入特征。
(2)数据预处理过程
在模型实时上线运行时,使用了以下的步骤对格点化气象要素预报进行了预处理,并且生成全市下辖各街镇的降水、气温以及最大风速特征:
①根据格点预报数据中的地理栅格数据与街镇的边界数据进行空间连接,形成格点与街镇的对应表;
②读取NetCDF格式的地面降水、风场以及气温要素的3维(时间,经度,纬度)栅格数据;
③根据风场中的U向量以及V向量大小,计算对应格点的最大风速;
④将气温要素的单位由开尔文转为摄氏度,与气象自动站实时监测气象要素的单位统一;
⑤根据步骤1中的格点-街镇对应表,计算每个区县/街镇内的自动格点的平均降雨量、最大风速以及最低气温、最高气温;
⑥将步骤5中所得到的降雨量、风速,以及最高最低气温作为当前街镇对应时间的气象要素特征。
通过以上的计算过程,则可以得出全市街镇通过格点化气象要素预报得出的大风、降水以及气温信息,用于模型的后续气象特征输入。
3、网格实况事件数据
(1)数据源结构
上海网格数据使用2019/01/01 00:19:18至2020/02/01,2020/05/01–2020/10/19的数据作为训练集,共涉及数据4352245条。上海网格原始数据共有124个字段,根据分析需求,选取DISCOVERTIME(发现时间)、INFOSCNAME(小类名称)、STREETNAME(所属街道名称)、TASKID(任务编号)五个字段进行最终分析。
浦东网格数据使用2020/01/01 00:19:18至2020/02/01,2020/03/01–2020/10/19的数据作为训练集,共涉及数据1077230条。浦东网格原始数据共有124个字段,根据分析需求,选取DISCOVERTIME(发现时间)、INFOSCNAME(小类名称)、ISFAST(是否属于快速处置)、STREETNAME(所属街道名称)、TASKID(任务编号)六个字段进行最终分析。
徐汇网格数据使用2018/01/15至2020/10/15的数据作为训练集,共涉及数据1,054,935条。徐汇网格原始数据共有17个字段,根据分析需求,选取CREATETIME(发现时间)、SECOND_TYPE(小类名称)、THIRD_TYPE(子类名称)、STREETNAME(所属街道名称)、TASKID(任务编号)、CASEATTRIBUTE(事件类型)六个字段进行最终分析。
(2)数据预处理过程
在对网格场景模型进行训练时,使用了数据中的小类名称字段对事件类型进行了分类,并且通过这个方法确定了网格场景模型中的预测以及训练目标。
而在确定非快速处置模型的对应标签时,则选取了isfast(是否快速处置类事件)字段作为筛选条件,过滤为非快速处置类模型的预测事件对象。并与以上的场景模型达标规则结合,输出非快速处置模型总量以及场景模型的预测模型标签。
4、热线实况事件数据
(1)数据源结构
浦东热线数据使用2020/01/01 00:19:18至2020/02/01,2020/03/01–2020/10/19的数据作为训练集,共涉及数据586869条。浦东热线原始数据共有136个字段,根据分析需求,选取DISCOVERTIME(发现时间)、INFOSCNAME(小类名称)、INFOZCNAME(子类名称)、STREETNAME(所属街道名称)、TASKID(任务编号)六个字段进行最终分析。
徐汇热线数据使用2018/01/15至2020/10/15的数据作为训练集,共涉及数据144,297条。徐汇热线原始数据共有17个字段,根据分析需求,选取CREATETIME(发现时间)、SECOND_TYPE(小类名称)、THIRD_TYPE(子类名称)、STREETNAME(所属街道名称)、TASKID(任务编号)、CASEATTRIBUTE(事件类型)六个字段进行最终分析。
(2)数据预处理过程
在对热线场景模型进行训练时,使用了数据中的子类名称字段对事件类型进行了分类,并且通过这个方法确定了热线场景模型中的预测以及训练目标。
5、110事件气象灾情数据
(1)数据源结构
110气象灾情数据使用2020/01/01 00:00:00至2020/07/29 24:00:00的数据作为验证集,共涉及数据1,998条。
110气象灾情实时原始数据共有13个字段,根据分析需求,选取OBJECTID(案件id),DATETIME_DISASTER(报警时间),TELEPHONE(报警人电话),LONTITUDE(经度),LATITUDE(纬度),CASE_ADDR(报警案发地址),CASE_DESC(报警案件内容),DISTRICT(区县),这八个字段进行最终分析。
(2)数据预处理过程
在对110气象灾情场景模型进行训练时,首先对区县字段进行了简单清洗,并且对气象灾情内容字段进行了对其进行了结构化处理。使用了数据中的灾种字段对气象灾情类型进行了分类,并且通过这个方法确定了场景模型中的预测以及训练目标,最终选取事件数量最多的大风、暴雨事件进行预测建模。
二、事件数量预测模型
1、模型原理
(1)决策树模型
决策树是一种解决分类以及问题的算法,决策树算法采用树形结构,使用层层推理来实现最终的分类。决策树由下面几种元素构成:
根节点:包含样本的全集
内部节点:对应特征属性测试
叶节点:代表决策的结果
在每一个状态节点,决策树通过遍历每一个数据纬度(特征)并计算在该特征中所能得到的最大信息增益作为决策树的生长方向,并计算在该方向上中的哪个具体节点对数据进行分割会带来最大的信息增益。并以此来构造下一层级的内部节点,直至达到预设额决策树最高生长高度,或无法再通过任意方向的生长以及数据分割带来信息增益。最终构成的决策树将为一个有多个二叉条件判断规则组合而成的分类以及回归模型。而不同的信息增益函数也决定了决策树生长算法上的差异。常用的算法有基于信息熵的ID3/C4.5算法,也有基于基尼系数进行计算的CART树。而在基于气象的城市运行管理大数据分析预测模型中,使用的决策树算法则为CART树。
决策树拥有着许多的优点:这是一种易于直观理解模型内部构造的算法,并且它能够直接体现数据的特点,直观解释模型作出预测的逻辑。而且在数据的准备上,决策树是非常稳健的,能够同时处理数值型与条目型特征。然而,在实际的应用中,决策树的劣势也较为突出。当数据维度较多,且样本数量不平衡时,决策树模型在不加约束的情况会生成一个过于复杂但不稳定的判断结构。并且在数据中拥有一个样本不平衡额条目型特征时,决策树模型非常易于生长出一颗深且不平衡的结构。所以在实际项目中,使用了决策树的升级算法,梯度提升模型来减轻以上所提到决策树的劣势。
(2)梯度提升模型
梯度提升模型(Gradient Boosting Machine)为一个经典的机器学习模型算法,该算法通过将多颗简单的决策树进行集成,从而得到一个灵活且拥有优秀拟合能力的预测模型。该模型中,将每一颗决策树对目标拟合的残差作为下一棵决策树的学习目标,以此往复,直至模型收敛或决策。事件预测模型中所用的具体梯度提升模型实现则基于LightGBM。这是微软(Microsoft)所开源的一个梯度提升模型框架。它具有着训练速度快,内存使用效率高,预测精度高,以及支持多种预测场景(支持分类,回归,排序)等优点,在业界被广泛应用。
而LightGBM相对于一般的梯度提升算法实现,还拥有两项特殊的优点。首先,相对于以往的决策树按层生长的逻辑,LightGBM使用了按叶节点生成的生长逻辑。在决策树每一次生长时,从当前所有叶节点中,找到分裂增益最大(一般也是数据量最大)的一个叶节点,然后分裂,如此循环。所以在保持相同叶节点数量的情况下,这种生长策略会带来更多的信息增益提升。而在对于类别特征的处理上,LightGBM可以找出类别特征的最优切割,即many-vs-many的切分方式。这也解决了当条目型特征中类别数量较大时,树模型易于生长不平衡的现象。
而在算法的实现效率上,相对于需要遍历数据且对数据进行排序的其他决策树算法,LightGBM则采用了直方图算法对数据进行预处理,提高了模型在运行时的内存使用效率,并且由于使用了直方图算法对数据进行离散化操作,导致了树模型在生长时对于异常点的敏感性,进一步增加了模型的泛化效果。
本发明对以上介绍过的梯度提升模型进行了改动,使用了两步法建模、随机截距模型和随机效应模型来对抗样本中存在的稀疏性问题和各街镇样本不平衡的情况,最终建立了网格事件数量预测模型,参见图2、图3。
(3)两步法建模
两步法建模是一个被用于解决数据稀疏性(数据中存在大量零值)对预测模型影响的建模方法。在将网格热线数据分摊到街镇/12小时,数据中超过70%的样本事件发生数为零,即没有事件发生。而使用该数据拟合模型会使模型的预测显著性偏低。为了减轻该问题对模型造成的影响,将模型分为了事件发生概率模型以及事件发生数量模型。在事件发生概率模型中,使用梯度提升模型预测各街镇12小时内是否会发生对应的网格热线事件,并且将各街镇12小时内是否发生对应事件的概率作为主要输出。而在事件发生数量模型中,则使用梯度提升模型预测各街镇一旦发生事件时12小时内发生事件的数量。将事件预期发生的概率与事件一旦发生时的预期数量相乘,最终得到了网格热线发生的数量值。
两步法建模在经济学、社会学,以及医学中应用广泛。在经济学中,两步法建模又通常被称为栅栏模型。在经济学中,他被用于在细分定价实践中,供应由通常会设置一些硬性设置(即栅栏)。对符合该标准的顾客予以价格折扣,经济学家称之为价格歧视栅栏模型(Hurdle Model of Price Discrimination)。由于这种栅栏的存在,用户的购买数据通常也会呈现稀疏的现象,即真正消费的人群往往只占所用人群中的很小一部分。这也与网格热线场景模型中所遇到的时间稀疏性相吻合。所以在这里使用了两步法建模减轻了数据稀疏的现象。
(4)随机截距模型
在训练事件发生数量模型时,为了对抗特征中出现的街镇样本不平衡问题(事件样本多集中于少部分街镇)而造成模型易于过拟合的问题,使用了随机截距模型(Random-Intercept Model)估计了各个街镇对应事件发生的基准水平,并将估算得出的基准水平作为两步建模中事件数量预测模型的预输入。
(5)随机效应模型
随机效应模型(random effects models)是经典的线性模型的一种推广,它将固定的回归系数看作是随机变量,一般都是假设是来自正态分布。如果模型里一部分系数是随机的,另外一些是固定的,一般就叫做混合模型(mixed models)。引入随机效应可以使个体观测之间就有一定的相关性,所以对于拟合非独立观测的数据时为合适的选择。而网格热线数量数据则也是如以上所描述的一样,是一个非独立的观测的数据。而使用混合/随机效应模型时,由于随机效应拟合时的压缩(shrinkage)现象,模型拟合时样本较少的个体的估计值会向群体的中间值”靠拢”,这个现象也限制住了部分样本较少但发生较为异常的街镇在估计中不易被偶发零星出现的异常值所影响。
2、特征挖掘
配合图4,在模型输入的挖掘上,使用了时间、历史实况数据以及气象要素这三种同类型的特征作为模型的输入。
在时间特征上,所处小时,是否属于工作日,所在月份,以及是否处于节假日被用于捕捉网格事件发生数量与事件发生数量与所处时间之间的关系。
在历史实况数据特征的挖掘中,使用了偏自相关系数(Partial Auto-Correlation)这个统计指标来判定事件发生数量在时间上的延后性。通过这个指标,可以发现12小时前、24小时前、36小时前以及1周前发生的事件数在统计上与当前时间发生的事件数量在统计上有显著的相关性。于是这些特征也作为了模型的输入。
在气象要素这类特征的挖掘上,主要考量了降水、气温、风速这三类气象条件对事件发生数量的瞬时以及历史影响。在瞬时气象要素上,使用了当前小时累计降雨量、当前小时最大风速、当前小时最高温度,以及当前小时最低温度作为模型的输入。而在历史气象要素对事件发生数量的影响上,除了使用在气相标准上常用的统计量(例如用来判定是否暴雨标准的12小时以及24小时累计降雨量)外,还使用了交叉相关系数(Cross-Correlation)来计算事件发生数量与不同气象要素在时间上的滞后关系,并最终加入了6小时、36小时、48小时内的大风、降水以及气温要素的统计指标(如最大值、最小值、平均值、累计值)作为模型的输入。
偏自相关系数在时间序列分析与建模中是常见的统计指标。它通常被用于发现一个序列上的样本是否与一段时间前的样本有着相关关系。而具体的数学定义上,他度量了X
3、网格数量预测模型构建及场景模型
模型构建过程对梯度提升模型进行了改动,使用了两步法建模、随机截距模型和随机效应模型来对抗样本中存在的稀疏性问题和各街镇样本不平衡的情况,最终建立了网格事件数量预测模型。
在对网格事件数量总量进行预测之外,也选取了6个与气象影响密切相关的6个网格事件小类场景,建立了网格场景模型。以下为选取的小类场景:行道树、公共绿地、挪车求助、架空线坠落、绿地护栏以及小区绿化。对于发生数量较少以及街镇间样本不平衡的网格场景(例如小区绿化、行道树等),通过使用两步法建模以及随机截距模型,网格场景模型过拟合的现象可以被显著的降低。
与网格事件数量预测模型的总量模型(即事件发生的数量值)不同,网格场景模型中标签数据稀少的现象尤为明显。并且不同场景类型事件的稀疏程度也不近相同。所以对于不同的场景模型,也使用了不同的模型参数用于拟合与训练模型。并且在模型的训练策略上也进行了一定程度上的改变。在总量模型中,两步法建模的中心放在了事件发生数量模型上,即一旦发生事件时,预测事件发生数量的多少。而场景模型中由于数据稀疏的原因,很多情况在事件发生的情况下数量往往只有一起。所以在场景模型中,训练的中心则会向事件是否发生的方向上偏移(即中心放在了事件发生概率模型上),即当前气象条件下、时间、所处街镇中,改小类事件发生概率的大小。根据这样的模型训练策略改变,也对场景模型的训练参数进行了修改。通过交叉验证与人工结合的方式,确定了各个场景模型的训练参数,以下为各个场景模型的训练参数:
行道树:事件发生概率模型训练轮数为600轮,事件发生数量模型训练轮数为300轮;
公共绿地:事件发生概率模型训练轮数为500轮,事件发生数量模型训练轮数为500轮;
挪车求助:事件发生概率模型训练轮数为400轮,事件发生数量模型训练轮数为600轮;
架空线坠落:事件发生概率模型训练轮数为700轮,事件发生数量模型训练轮数为300轮;
绿地护栏:事件发生概率模型训练轮数为500轮,事件发生数量模型训练轮数为500轮;
小区绿化:事件发生概率模型训练轮数为400轮,事件发生数量模型训练轮数为300轮。
4、热线数量预测模型构建及场景模型
模型构建过程对梯度提升模型进行了改动,使用了两步法建模、随机截距模型和随机效应模型来对抗样本中存在的稀疏性问题和各街镇样本不平衡的情况,最终建立了热线事件数量预测模型。
在对热线事件数量总量进行预测之外,也对出租车、道路维护、故障报修、绿地绿化、排水排污管理这5个热线子类场景进行了预测建模,建立了场景模型。对于发生数量较少以及街镇间样本不平衡的网格场景(例如排水排污管理、道路维护等),通过使用两步法建模以及随机截距模型,模型过拟合的现象可以被显著的降低。
与总量模型不同,热线场景模型中标签数据稀少的现象尤为明显。并且不同场景类型事件的稀疏程度也不近相同。所以对于不同的场景模型,我们也使用了不同的模型参数用于拟合与训练模型。并且在模型的训练策略上也进行了一定程度上的改变。在热线总量模型中,两步法建模的中心放在了数量预测模型上,即一旦发生事件时,预测事件发生数量的多少。而场景模型中由于数据稀疏的原因,很多情况在事件发生的情况下数量往往只有一起。所以在场景模型中,训练的中心则会向事件是否发生的方向上偏移,即当前气象条件,时间,所处街镇中,改小类事件发生概率的大小。根据这样的模型训练策略改变,也对场景模型的训练参数进行了修改。通过交叉验证与人工结合的方式,确定了各个场景模型的训练参数,以下为各个场景模型的训练参数:
出租车:事件发生概率模型训练轮数为600轮,事件发生数量模型训练轮数为300轮;
道路维护:事件发生概率模型训练轮数为600轮,事件发生数量模型训练轮数为400轮;
故障报修:事件发生概率模型训练轮数为500轮,事件发生数量模型训练轮数为500轮;
绿地绿化:事件发生概率模型训练轮数为600轮,事件发生数量模型训练轮数为500轮;
排水排污管理:事件发生概率模型训练轮数为500轮,事件发生数量模型训练轮数为600轮。
5、110数量预测模型构建及场景模型
模型构建过程对梯度提升模型进行了改动,使用了两步法建模、随机截距模型和随机效应模型来对抗样本中存在的稀疏性问题和各街镇样本不平衡的情况,最终建立了110气象灾情数量预测模型。
和热线网格事件数量预测模型不同,只对两类灾害场景进行数量预测建模,即大风、暴雨事件。在地区范围上,有别于网格热线的分街镇预测,由于110气象灾情数量的数据稀疏问题更为严重,仅对其进行分区数量预测。在时间范围上,选择逐小时的预测。
对于发生数量较少以及街镇间样本不平衡的场景,通过使用两步法建模、随机截距模型和随机效应模型,模型过拟合的现象可以被显著的降低。针对于110气象灾情的分布规律和网格热线事件分布规律的差异性,也使用了不同的模型参数用于拟合与训练模型。根据这样的模型训练策略改变,也对场景模型的训练参数进行了修改。通过交叉验证与人工结合的方式,确定了各个场景模型的训练参数,以下为各个场景模型的训练参数:
暴雨场景:事件发生概率模型训练轮数为500轮,事件发生数量模型训练轮数为500轮;
大风场景:事件发生概率模型训练轮数为600轮,事件发生数量模型训练轮数为500轮。
三、事件风险预警模型
根据对历史事件发生数量的统计性分析以及对实际使用场景上的考量,通过结合历史事件发生数量分位数以及事件发生数的绝对阈值,制定了事件预警标准。现在将预警等为5档,分档规则如下:
①无预警:小于80%分位数或小于9起;
②蓝色预警:大于等于80%分位数且大于等于9起;
③黄色预警:大于等于90%分位数且大于等于15起;
④橙色预警:大于等于95%分位数且大于等于25起;
⑤红色预警:大于等于99%分位数且大于等于40起。
对于110气象灾情,由于事件数量较为稀少分布,较为稀疏,其预警标准修改为:
①无预警:小于80%分位数或小于9起;
②蓝色预警:大于等于80%分位数且大于等于5起;
③黄色预警:大于等于90%分位数且大于等于10起;
④橙色预警:大于等于95%分位数且大于等于15起;
⑤红色预警:大于等于99%分位数且大于等于25起。
根据这个方法,也可以将历史12小时累计事件发生数量的中位数作为事件的比较基准,计算了事件预测数量相比平日一般状态下的增减量。
四、气象影响指数模型
1、网格事件气象影响指数
由于LightGBM是以树模型为基础的梯度提升模型,所以在模型训练过程中可以得出各个特征在不同值域范围内的该特征对于模型整体所带来的信息增益。通过对不同特征所带来的信息增益进行聚合加总计算,并对所有特征贡献度进行归一化,则可以计算出不同特征所带来的百分比贡献度。从模型解释性的角度上来讲,百分比贡献度实则量化了LightGBM模型中的决策逻辑,即在当前输入条件下,哪些特征会对模型带来最大的增益,从侧面量化了特征的重要程度。
基于网格事件预测模型,计算得出了事件通过计算出各个特征对于事件数量预测的百分比贡献度。由于模型的输入中已经包括了大风、降水、气温三大类气象特征,得到了大风、降水、气温对事件的百分比贡献值;将三大气象特征在风和日丽条件(无降雨,风速为2级,气温为25摄氏度)时的百分比贡献值作为基准,计算当前气象特征的百分比贡献值与风和日丽基准的绝对偏差,而这个偏差则为三大类气象特征的影响指数。
通过对网格场景模型的气象影响指数分析,可以发现公共绿地、挪车求助受降水影响较多,架空线坠落、绿地护栏受大风影响较多,而小区绿化受气温影响较多。行道树则与大风,降水,以及气温关系都比较密切。
2、热线事件气象影响指数
与网格模型气象影响指数的计算方法类似,热线模型的气象影响指数基于热线事件预测模型。并且基于偏差方法,计算出了大风、降水、气温三大气象特征对热线总量以及子类事件的影响。
通过对热线场景模型的气象影响指数分析,可以发现排水排污管理与道路维护受降水影响较多,故障报修与绿地绿化受大风影响较多,而出租车受气温影响较多。
五、模型验证机制
为模拟模型真实上线运行时的情景,使用了滚动式交叉验证的方式对模型的预测能力进行了验证。以下为滚动交叉验证流程:
①假设现在时间为t。则使用(t-1,t-2,…,t-12)的数据作为训练集并训练事件预测模型M
②使用模型M
③更新时间t,即t=t+1;
④重复步骤①,直至t为最新时间点,统计所有预测结果的误差率。
六、模型更新优化
模型现采用自动化更新训练策略,更新频率则是日级别,即每日对模型使用最近得更新数据进行重新训练。若需要对模型的更新频率做调整,则可以在文件model_crontab中的这行命令中的cron语法作出修改。
若需要对模型进行更新替换,则可以直接将更新后的同名模型放入对应的文件夹中。若需要在部署的服务器中手动训练模型,则可以执行以下命令对模型进行手动更新。
值得一提的是,本发明还提供了一种基于气象的城市运行管理大数据分析预测系统,以支持上述基于气象的城市运行管理大数据分析预测方法的实现。该系统可存储于计算机中,当计算机运行该系统时,执行上述基于气象的城市运行管理大数据分析预测方法的步骤。
同理,应当注意的是,为了简化本申请披露的表述,从而帮助对一个或多个发明实施例的理解,前文对本申请实施例的描述中,有时会将多种特征归并至一个实施例、附图或对其的描述中。但是,这种披露方法并不意味着本申请对象所需要的特征比权利要求中提及的特征多。实际上,实施例的特征要少于上述披露的单个实施例的全部特征。
虽然本申请已参照当前的具体实施例来描述,但是本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本申请,在没有脱离本申请精神的情况下还可作出各种等效的变化或替换,因此,只要在本申请的实质精神范围内对上述实施例的变化、变型都将落在本申请的权利要求书的范围内。
本发明未详细描述的技术、形状、构造部分均为公知技术。
- 基于气象的城市运行管理大数据分析预测方法和系统
- 一种基于智慧城市的公共交通运行管理系统