一种基于图文识别后的文字学习校对系统
文献发布时间:2023-06-19 12:07:15
技术领域
本发明涉及司法文献数字化处理技术领域,具体为一种基于图文识别后的文字学习校对系统。
背景技术
利用计算机对法院纸质诉讼文书进行数字化处理是当前法院信息化建设的重要工作,而保证文字识别的正确率是其中非常主要的环节,文字识别校对程序是针对目前光学文字识别程序对印刷体文件均不能达到相应正确率要求(例如:国家档案局要求的文字识别误差小于千分之二,出版业三校标准误差小于万分之二),且识别效率较低,不适用于法院海量的文书校对处理。
发明内容
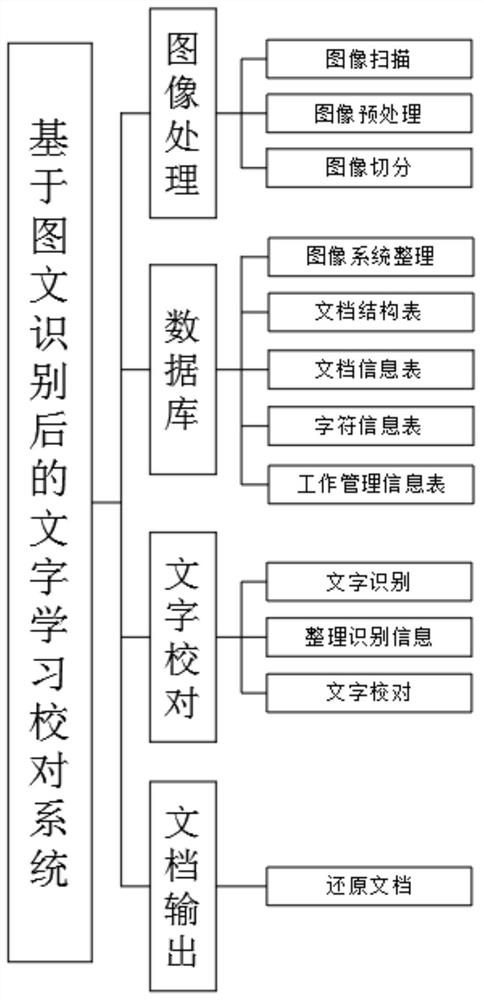
鉴于现有技术中所存在的问题,本发明公开了一种基于图文识别后的文字学习校对系统,采用的技术方案是,包括图像处理模块、数据库、文字校对模块、文档输出模块;所述图像处理模块,用于对纸质文档图像的扫描收集,对扫描图像进行系统整理并进行倾斜矫正、降噪等预处理,对图像以字符为单位进行切分,形成独立的字符图像文件,将字符图像文件信息存入所述数据库中;所述数据库,用于建立文档结构表、文档信息表、字符信息表、工作管理信息表,以及存储字符图像文件信息;所述文字校对模块,用于扫描图像及切分图像的文字识别,字符信息与切分图像的比对,对错误的字符图像进行修改和保存;所述文档输出模块,利用完成校对的字符信息表和文档信息表还原文档。
作为本发明的一种优选技术方案,所述图像处理模块扫描纸质文档形成的图像文件格式可以为TIFF、JPG等,分辨率需要达到300DPI以上。
作为本发明的一种优选技术方案,所述文字校对模块的文字识别率需要达到96%以上,识别对象可以是扫描图像文件,也可以是切分图像。
作为本发明的一种优选技术方案,所述文字校对模块按照文字信息表保存的文字信息按ASCII码进行排序,逐一列出每一个字符和对应的所有图像,对同一字符下出现的错误图像进行修改,改为实际对应字符并保存。
作为本发明的一种优选技术方案,所述文档输出模块还原文档的格式为TXT、DOC、双层PDF中的一种,可同时实现文档原件显示和全文检索、复制粘贴功能。
作为本发明的一种优选技术方案,所述系统的应用环境为B/S架构,支持网络运行,便于使用及维护。
本发明的有益效果:本发明通过先进的页面分析提取技术,将图像文件中的全部字符进行拆分,形成独立的字符文件,并利用数据库技术进行相应排序组合,将繁琐的校对程序改变为简单的图像和字符的批量对比,从而保证识别结果符合国家出版业校对标准,并且极大提高了校对效率,对提高司法效率有着积极作用。
附图说明
图1为本发明系统结构示意图;
图2为本发明工作流程结构示意图。
具体实施方式
实施例1
如图1至图2所示,本发明公开了一种基于图文识别后的文字学习校对系统,采用的技术方案是,包括图像处理模块、数据库、文字校对模块、文档输出模块;所述图像处理模块,用于对纸质文档图像的扫描收集,对扫描图像进行系统整理并进行倾斜矫正、降噪等预处理,对图像以字符为单位进行切分,形成独立的字符图像文件,将字符图像文件信息存入所述数据库中;所述数据库,用于建立文档结构表、文档信息表、字符信息表、工作管理信息表,以及存储字符图像文件信息;所述文字校对模块,用于扫描图像及切分图像的文字识别,字符信息与切分图像的比对,对错误的字符图像进行修改和保存;所述文档输出模块,利用完成校对的字符信息表和文档信息表还原文档。
作为本发明的一种优选技术方案,所述图像处理模块扫描纸质文档形成的图像文件格式可以为TIFF、JPG等,分辨率需要达到300DPI以上。
作为本发明的一种优选技术方案,所述文字校对模块的文字识别率需要达到96%以上,识别对象可以是扫描图像文件,也可以是切分图像。
作为本发明的一种优选技术方案,所述文档结构表主要内容包括处理文件的组织结构和文档层级信息。
作为本发明的一种优选技术方案,所述文档信息表的主要内容包括具体文档的信息,如文档名称、图像文件名称、页数、字符数量等。
作为本发明的一种优选技术方案,所述字符信息表主要包括所属文档的文档信息表ID值,字符位置信息、字符值。
作为本发明的一种优选技术方案,所述工作管理信息表主要记录工作流程信息,便于管理者对工作情况实时管理。
作为本发明的一种优选技术方案,所述文字校对模块按照文字信息表保存的文字信息按ASCII码进行排序,逐一列出每一个字符和对应的所有图像,对同一字符下出现的错误图像进行修改,改为实际对应字符并保存。
作为本发明的一种优选技术方案,所述文档输出模块还原文档的格式为TXT、DOC、双层PDF中的一种,可同时实现文档原件显示和全文检索、复制粘贴功能。
作为本发明的一种优选技术方案,所述系统的应用环境为B/S架构,支持网络运行,便于使用及维护。
本发明的工作原理:图像处理模块将待识别处理的纸质文档,如报纸、文件、档案等,进行扫描,形成计算机图像文件,图像文件格式可以为TIFF、JPG等,分辨率需要达到300DPI以上,如果已进行档案数字化处理工作的,可直接调取需要处理的文书内容图像,按照待处理文档的业务管理属性对扫描图像进行系统整理(此项工作可以与扫描工作同时进行),例如法院诉讼档案按照法院单位->年份->案件类型->案件程序->案件序号->卷别->卷册号->页号->文书项目等顺序进行整理,保证识别校对工作有序进行,数据库包括文档结构表、文档信息表和字符信息表,根据实际工作开展情况还需要设置工作管理信息表,文档结构表主要内容包括处理文件的组织结构和文档层级信息,文档信息表的主要内容包括具体文档的信息,如文档名称、图像文件名称、页数、字符数量等,字符信息表主要包括所属文档的文档信息表ID值,字符位置信息、字符值,工作管理信息表主要记录工作流程信息,便于管理者对工作情况实时管理,对全部文档进行文字切分处理(切分前可以对图像文件进行倾斜矫正、降噪等处理),形成独立的文字图像文件,同时利用数据库保存字符图像文件信息,利用识别率能够保证百分之九十六以上的文字识别软件,识别对象可以是扫描图像文件,也可以是切分图像,对于扫描图像文件流程形成的识别文本,需要和数据库保存的字符图像文件信息进行匹配,扫描切分图像的流程不需要此项工作,只保存识别结果,按照文字信息表保存的文字信息按ASCII码进行排序,逐一列出每一个字符和对应的所有图像,对同一字符下出现的错误图像进行修改,改为实际对应字符并保存,用完成校对的字符信息表和文档信息表还原文档,文档格式可以为:.TXT、.DOC,可根据客户需要生成双层PDF的文档,同时实现文档原件显示和全文检索、复制粘贴功能。
上述虽然对本发明的具体实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化,而不具备创造性劳动的修改或变形仍在本发明的保护范围以内。
- 一种基于图文识别后的文字学习校对系统
- 一种基于OCR的漏识文字自动检测的方法