用于车辆马达的热控制
文献发布时间:2023-06-19 12:14:58
技术领域
本发明涉及一种用于车辆马达的热控制方法,以及用于实现该方法的系统。本发明有利地应用于车辆电动马达的热控制。
背景技术
车辆马达的精确热控制在许多方面是有利的,因为它允许增加马达的寿命和性能。实际上,已知热会导致材料变形,这对材料的使用寿命是有害的。
例如,在电动马达的情况下,它们通过焦耳效应产生大量热量,但是电子元件对过高的温度敏感,并且具有工作温度极限。因此,暴露在不受控制的温度下会影响这些马达的寿命。
同样,当不需要马达热控制时,马达热控制的电能消耗会减小车辆的行驶里程。因此,重要的是能够优化马达的热控制,以便能够将马达保持在可接受的温度范围内,同时限制由该热控制引起的电能消耗,以便优化车辆的行驶里程。
因此,目前有两种方法被考虑用于车辆马达的热控制。它们在热系统中实施,该热系统包括马达、冷却系统和至少一个致动器,该致动器适于通过冷却装置改变冷却马达的能力。
基于规则的(rule-based)方法是使用最广泛的方法,且包括应用一组预限定的规则。因此,它们规定了取决于热系统的给定状态的控制动作。然而,这种方法太不精确,无法实现系统的最佳控制,因为系统的状态和规则对于所讨论的系统来说不够具体。此外,根据其性质,这些规则只考虑了非常少量的参数。
基于优化的第二种方法使用优化的理论模型,考虑了系统不同部分的热阻以及发生在马达和马达冷却装置之间的热交换。因此,它精确地考虑了系统的参数组。因此,该方法需要系统及其线性的完整理论知识。在复杂系统的情况下,这种方法在技术上和经济上都不可行。系统建模变得非常复杂,且设计成本太高。此外,需要进行大量调查才能在真实条件下验证理论模型,这将产生巨大成本。最后,由于这种方法涉及对包括马达及其冷却系统的特定热系统的热行为进行建模,因此它不能容易地应用于其他类型的马达和/或冷却系统。
发明内容
因此,本发明的目的是应对由上述两种方法提出的问题。
特别地,本发明的目的是提出一种用于车辆马达的热控制方法,该方法比现有技术更容易实施,并且允许马达冷却的优化控制。
为此,本发明涉及一种用于优化车辆马达的热控制的方法,该车辆包括马达冷却装置,该马达冷却装置包括至少一个致动器,该致动器适于通过冷却装置改变冷却马达的能力,
该方法由适于控制所述至少一个致动器的计算机实现,
该方法的特征在于,其包括强化学习算法的训练,其包括以下步骤的迭代实施:
1)通过对包括马达和冷却装置的热系统的当前状态应用控制函数来确定用于控制至少一个致动器的至少一个动作,并实施所述动作,
2)在实施所述动作之后,确定热系统的经修改状态,
3)通过实施马达的热力学奖励函数,基于热系统的经修改状态和所述动作来计算奖励值,
4)基于热系统的当前状态、热系统的经修改状态、动作和奖励来更新用于估计系统的热性能的函数,以及
5)基于用于估计系统的热性能的函数的更新来修改控制函数。
在一些实施例中,探索噪声(bruit d'exploration)被添加到控制动作的确定或者被添加到控制函数的参数。
根据一个实施例,马达的热力学奖励函数被配置成当基于当前状态由动作引起的热力学不可逆性的产生被最小化时,使奖励值最大化。
根据一个实施例,在动作之后的热系统的经修改状态包括至少一个参数,该参数识别所述动作之前的至少一个动作。
根据一个实施例,马达的热力学奖励函数被配置成当动作导致马达的温度超过预定阈值时对该动作进行惩罚。
根据一个实施例,马达的热力学奖励函数被配置成当实施动作而环境温度大于马达温度时对该动作进行惩罚。
根据一个实施例,热系统的状态由以下组中的至少一个参数限定:车辆周围的空气速度、马达在不久的将来的开启或关闭状态、马达的一个或多个温度、热系统的一个或多个熵值、以及在当前状态之前实施的一个或多个动作。
根据一个实施例,马达是电动马达。
根据一个实施例,用于估计热性能的函数呈以下形式:
[数学式5]
其中,γ是折旧因子,π是控制函数的一组参数,且n是针对用于估计热性能的函数的计算时所考虑的附加的时间步的数目。
根据一个实施例,折旧因子γ在0.8和1之间(含0.8和1在内)。
根据一个实施例,强化学习算法的训练的两个时间步之间的值是与值n相关联地确定的,且反之亦然。
本发明的另一个目的是一种包含编码指令的计算机程序产品,当其由计算机实现时,其用于实现上述方法。
本发明的另一个目的是一种用于车辆马达的热控制系统,该系统包括计算机,该计算机适于通过应用控制函数来实施用于控制至少一个致动器的至少一个动作,所述控制函数已经通过优化方法的实现而预先确定。
本发明的另一个目的是一种用于车辆马达的热控制系统,其包括适于实施上述方法的计算机。
因此,通过实现与奖励计算函数相结合的行动者-评价者(acteur-critique)架构(其中该架构允许优化热系统的热力学性能),本发明能够以低推理计算成本并且不需要实验结果的最佳方式对复杂系统进行热控制。更具体地,本发明基于例如由出版物《深度强化学习的连续控制》(《Continuous Control With Deep Reinforcement Learning》)(Lillicrap等人,2015)公开的自动强化学习方法,其更广为人知地被称为DDPG算法,该方法是对连续控制系统的被称为Q-学习的算法的改编,Q-学习被实施用于离散化系统。
因此,用于训练控制系统的自动强化学习方法将学会有效地控制热系统,而不需要依赖于实验数据。因此,本发明适用于不同复杂程度的热系统。
附图说明
本发明的其他特征、目的和优点将从以下描述中变得明显,该描述纯粹是说明性的而非限制性的,并且应该参考附图来阅读,其中:
图1示出了根据本发明一个实施例的车辆马达的热系统。
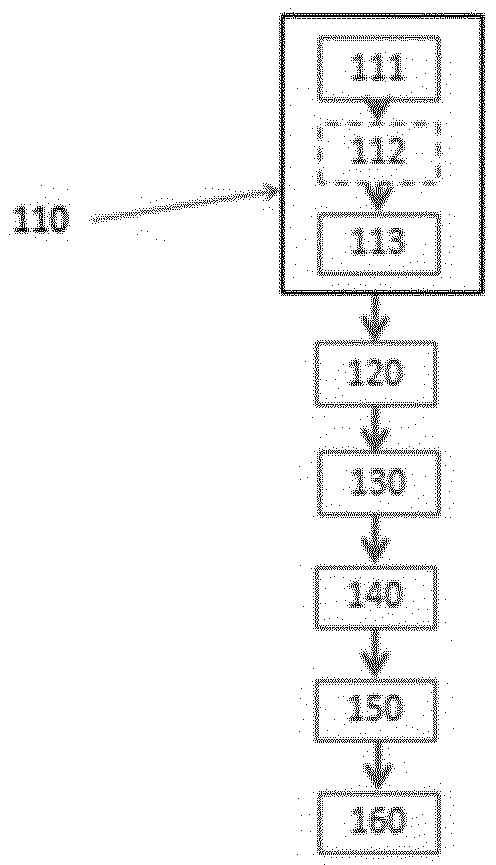
图2示出了根据本发明一个实施例的用于优化热控制的方法的主要步骤。
图3示出了根据本发明一个实施例的由计算机实施的行动者-评价者(acteur-critique)架构。
具体实施方式
参照图2,现在将描述根据本发明的一个实施例的用于优化车辆马达的热控制的方法。这种方法使得有可能管理车辆马达的冷却,从而既将车辆马达保持在可接受的温度范围内,又尽可能减少车辆冷却系统的电能消耗。
在这点上,优化方法在图1中示意性示出的车辆马达1的热系统上实施,该热系统包括马达10,例如但不限于电动马达,以及马达冷却装置30,该装置30包括至少一个致动器50,其适于改变冷却马达的能力。
在优选实施例中,马达可以是电动马达。由于电动马达不能承受对于它们所包含的各个电子元件的寿命和性能来说太突然的温度应力,并且由于它们在行驶里程方面施加了额外的限制,所以本发明可以特别有利地应用于这种类型的电动马达。
优化方法由也在图1中示出的计算机20实施,计算机20适于接收关于马达和冷却装置的状态的信息(该信息由嵌入在车辆中或车辆上的一个或多个传感器测量),并且适于通过应用控制每个致动器的控制动作u
关于由传感器获取并由计算机20接收的信息,它们是将在下面更详细地描述的系统状态的一部分。
关于一个或多个控制动作,它们取决于冷却装置的部件,这些部件可以包括以下各者中的至少一个:逆变器、电池、泵、阀、百叶板(grille)、风扇、散热器、流管、冷却剂。实际上,冷却装置可以由允许冷却车辆马达的所有类型的元件单独地或组合地组成。由于根据本发明的车辆马达的热控制的优化并不特定于一个冷却系统,所以考虑冷却装置的所有组合。
例如,如果冷却装置是向马达输送冷却剂的泵,则泵的控制动作u
在另一个示例中,冷却装置是通向外部的阀,并且其控制动作u
根据另一个实施例,控制动作还可以包括以预定速度启动风扇叶片,以冷却马达。
还可能的是控制动作包括将百叶板打开或关闭到多个可能位置中的一个位置,以便在散热器从马达排出热量时冷却散热器。
然而,本发明不排除在前面的示例中限定的控制动作被同时使用或以某一种或另一种方式组合地使用的可能性。因此,风扇、泵、阀、百叶板和散热器形成由本发明所覆盖的冷却装置的组成部分,并且不被认为是若干单独的冷却装置。
因此,计算机20可以为同一冷却装置的多个不同元件中的每一个确定控制动作u
为了实现优化方法,计算机20有利地具有行动者-评价者(acteur-critique)架构,其在出版物《Natural Acteur-critique》(Jan Peters, Sethu Vijayakumar和StefanSchaal, 2008)中有描述,计算机20的架构示意性地示出在图3中。更具体地,计算机有利地配置成实现DDPG型强化学习算法,该算法是基于上面引用的Lillicrap等人的出版物中描述的行动者-评价者(acteur-critique)架构的特定类型的算法。在下文中,所述出版物中使用的符号用于描述相同的对象或功能。
该架构包括表示行动者-评价者(acteur-critique)架构的行动者(acteur)的第一组块21。计算机20的该组块21接收热系统的状态s
热系统的状态有利地是包括若干参数的向量。根据一个实施例,系统的状态向量的参数包括由组块21针对状态s
此外,作为时间的函数的热系统的状态参数可以具有n阶的复杂度,换言之,它们可以具有针对时刻t之前的n个系统状态的值。因此,例如,具有2阶复杂度的热系统的状态向量可以如下:
其中,T对应于马达的一个或多个温度,
u
Q
BSG
V
第二组块22评估控制动作u
下面更详细地描述用于估计系统热性能的Q函数的实现和更新。
在图3中,第四组块25用于显示系统的经修改状态s
参考图2,由上述计算机实现的优化方法包括以下步骤的迭代实施。
在第一步骤110期间,计算机的组块21在子步骤111期间基于热系统的给定状态s
在第二步骤120期间,计算机的组块22确定在实施所述动作u
在第三步骤130期间,组块22基于观察到的从状态s
有利地,马达的热力学奖励函数被配置成向其中车辆马达1的热系统优化其热性能的动作分配高奖励值。
在有利的实施例中,马达的热力学奖励函数被配置成当基于给定状态s
有利地,热力学奖励函数还被配置成当控制动作u
有利地,热力学奖励函数还被配置成当实施控制动作u
在一些实施例中,当实施相应的控制动作而马达关闭时,热力学奖励函数也可以对奖励值进行惩罚。
根据一个示例性实施例,允许计算奖励值的热力学奖励函数限定如下:
[数学式1]
其中,r对应于奖励,
dS
BSG时间对应于在马达关闭之前的时间,
T
T
T
由系统转换产生的热力学不可逆性的确定当然取决于系统。作为非限制性示例,在通过与温度为T
在第四步骤140期间,组块23将奖励值r
在第五步骤150期间,组块23更新用于估计热性能的函数。为此,组块23首先估计系统在当前状态下的热性能,并且为此,它首先基于针对状态s
然后通过修改Q函数的参数(即实现该函数的神经网络的加权因子)来实现Q函数的更新,以便使用于估计系统热性能的该函数的精度最大化。有利地,通过使针对状态s
[数学式2]
其中,函数μ由应用于状态s
有利地,该更新是通过自举(bootstrap)来实现的,这是通过随机获取存储在存储器中的N个转变P
[数学式3]
根据一个实施例变型,使用例如在出版物《分布式分布确定性策略梯度》(《Distributed Distributional Deterministic Policy Gradients》)(霍夫曼等人,2018)中描述的所谓的n步返回(n-step return)方法,以便在误差L中考虑在上述误差计算中使用的每个转变之后的n个转变。在这种情况下,函数y
[数学式4]
因此,用于估算热性能的函数的表达式可简化为:
[数学式5]
根据折旧因子γ的值,在计算新的Q函数时或多或少会考虑时刻t处的函数之后的奖励rt。
在一个实施例中,由组块23实现的神经网络的输出是对应于Q函数的结果的标量。有利地,在由Q函数产生的标量的输出之前向神经网络添加一层,使得可以估计Q的分布,实际上,其使得可以根据由出版物《分布式分布确定性策略梯度》(《DistributedDistributional Deterministic Policy Gradients》)(霍夫曼等人,2018)公开的分类方法来计算Q的期望。分类允许学习算法更快地收敛,并在系统的热控制中更有效。
在一个实施例中,折旧因子γ包括在 0.80和1 之间(含0.80和1在内)。 有利地,其包括在0.97和0.99之间(含0.97和0.99在内)。实际上,由于热系统具有大的惯性,通过在计算用于估计热性能的新函数时大量考虑随后的热性能,学习是更加有效的。
同样,仍然考虑热惯性,学习算法的两个时间步之间的间隙是显著的。例如,时间步可以在0.1和2秒之间(含0.1和2秒在内)。必须在不考虑系统热惯性的太小时间步和不允许学习算法收敛的太大时间步之间找到折衷。在所谓的n步返回方法中,返回步的数目n的确定有利地适合于允许学习算法的良好收敛。如果在太短的一段时间内有过多数量的值,学习算法可能不收敛。例如,可以取包括在3和10之间的n值(含3和10在内),以覆盖包括在1和6秒之间(含1和6秒在内)的总时间段(对应于n倍的时间步)。例如,时间步可以被选择为等于0.5秒,且n被选择为等于4。因此,时间步的值和n步返回(n-Step Return)的值n是相关的,以确保算法的收敛性。
最后,在步骤160期间,组块23基于用于估计热性能的函数来更新计算机的组块21的控制函数。该步骤通过J的梯度下降来实现,J是系统初始热性能的期望值,其取决于控制函数π的参数,并由下式限定:
[数学式6]
其中
[数学式7]
并且其中,E是环境。
J的梯度在上文引用的Lillicrap等人的出版物的方程(6)中被限定。根据J的梯度的表达式,梯度的这种下降允许控制函数的参数(在这种情况下是由组块21实现的神经网络的加权因子的矩阵)被更新,以便使预期的热性能最大化。
在一个实施例中,步骤110包括将探索噪声添加到由计算机20在子步骤111期间确定的控制动作u
与不包括该子步骤的步骤110相比,添加的探索噪声使得可以通过实施探索性的训练来获得热系统的改进效率,该探索性的训练允许其学习进一步优化热系统的可选动作。探索噪声的添加在图3中由计算机的组块24示出。在一个实施例中,探索噪声可以是高斯白噪声或由Ornstein Uhlenbeck过程产生的噪声。
在一个实施例中,一旦已经使用上述方法训练了控制函数,则控制函数可以存储在存储器中,且随后由与第一计算机分离的第二计算机直接实现,该第二计算机车载在车辆中。在这种情况下,第二计算机借助于已经训练的控制函数来确定取决于热系统状态的控制动作。然而,所述控制函数不能再被更新,因为计算机在其存储器中不包含训练方法。
在另一个实施例中,实现控制函数训练的计算机20可以是目标车辆中内置的计算机,并且随着该车辆的使用而继续更新控制函数。
因此,所提出的发明允许对车辆马达的热系统进行优化控制,而不考虑为了较低的推理计算成本以及同样为了较低的经济成本而对系统建模的复杂性。此外,本发明可以适用于大量的机动车辆热系统,这使得本发明具有灵活性。
- 用于车辆马达的热控制
- 一种用于车辆的电机主动发热控制方法和系统及车辆