相似度计算装置、记录介质以及相似度计算方法
文献发布时间:2023-06-19 12:24:27
技术领域
本申请说明书所公开的技术涉及相似度计算装置、相似度计算程序以及相似度计算方法。
背景技术
以往,使用如下技术:例如以吸收文件内的表述偏差为目的,创建由多个同义词组成的同义词组(例如,参照专利文献1)。
专利文献1:日本特开2016-224482号公报。
然而,当使用专利文献1中所示的技术等创建同义词组时,有时会创建有相互相似的多个同义词组。在该情况下,由于存在多个可使用的同义词组,因而,难以统一术语。另一方面,用人工汇总这些同义词组的作业非常耗时。
发明内容
本申请说明书所公开的技术鉴于上述情况而提出,其是即使在创建有多个同义词组的情况下,也有效地实现术语的统一的技术。
本申请说明书所公开的技术的第一方式的相似度计算装置,计算多个同义词组之间的相似度,其中,各个所述同义词组由相互为同义词的多个单词组成,所述相似度计算装置包括:名称获取部,获取至少一个第一组名称和至少一个第二组名称,所述第一组名称是属于多个所述同义词组中的第一同义词组的各个所述单词所属的所述同义词组的名称,所述第二组名称是属于多个所述同义词组中的第二同义词组的各个所述单词所属的所述同义词组的名称;名称集合生成部,生成以至少一个所述第一组名称为元素的第一组名称集合和以至少一个所述第二组名称为元素的第二组名称集合;以及相似度计算部,计算所述第一组名称集合与所述第二组名称集合之间的相似度。
本申请说明书所公开的技术的第二方式的相似度计算装置与第一方式相关联,所述相似度计算装置还包括结合部,当所述相似度在阈值以上时,所述结合部将所述第一同义词组与所述第二同义词组结合。
本申请说明书所公开的技术的第三方式的相似度计算装置与第一或第二方式相关联,所述相似度计算部使用Dice系数来计算所述相似度。
本申请说明书所公开的技术的第四方式的相似度计算装置与第一至第三方式中的任一方式相关联,所述相似度计算部根据所述第一组名称集合中的能够获取的所述第一组名称只有一个的所述单词的个数,使所述第一组名称集合的元素个数增加,并且根据所述第二组名称集合中的能够获取的所述第二组名称只有一个的所述单词的个数,使所述第二组名称集合的元素个数增加。
本申请说明书所公开的技术的第五方式的记录介质,存储有相似度计算程序是计算多个同义词组之间的相似度的相似度计算程序,各个所述同义词组由相互为同义词的多个单词组成,通过在计算机中安装所述相似度计算程序并执行,使所述计算机获取至少一个第一组名称和至少一个第二组名称,所述第一组名称是属于多个所述同义词组中的第一同义词组的各个所述单词所属的所述同义词组的名称,所述第二组名称是属于多个所述同义词组中的第二同义词组的各个所述单词所属的所述同义词组的名称,使所述计算机生成以至少一个所述第一组名称为元素的第一组名称集合和以至少一个所述第二组名称为元素的第二组名称集合,使所述计算机计算所述第一组名称集合与所述第二组名称集合之间的相似度。
本申请说明书所公开的技术的第六方式的相似度计算方法,计算多个同义词组之间的相似度,其中,各个所述同义词组由相互为同义词的多个单词组成,所述相似度计算方法包括以下工序:获取至少一个第一组名称和至少一个第二组名称的工序,所述第一组名称是属于多个所述同义词组中的第一同义词组的各个所述单词所属的所述同义词组的名称,所述第二组名称是属于多个所述同义词组中的第二同义词组的各个所述单词所属的所述同义词组的名称;生成以至少一个所述第一组名称为元素的第一组名称集合和以至少一个所述第二组名称为元素的第二组名称集合的工序;以及计算所述第一组名称集合与所述第二组名称集合之间的相似度的工序。
根据本申请说明书所公开的技术的第一方式至第六方式,即使在创建多个同义词组的情况下,也能够通过计算与同义词组对应的组名称集合之间的相似度,从而有效地实现术语的统一。
另外,根据以下所示的详细说明和附图,进一步明确与本申请说明书所公开的技术相关的目的、特征、技术方案和优点。
附图说明
图1是表示与实施方式相关的相似度计算装置的硬件结构的例子的图。
图2是表示与实施方式相关的相似度计算装置的功能结构的例子的图。
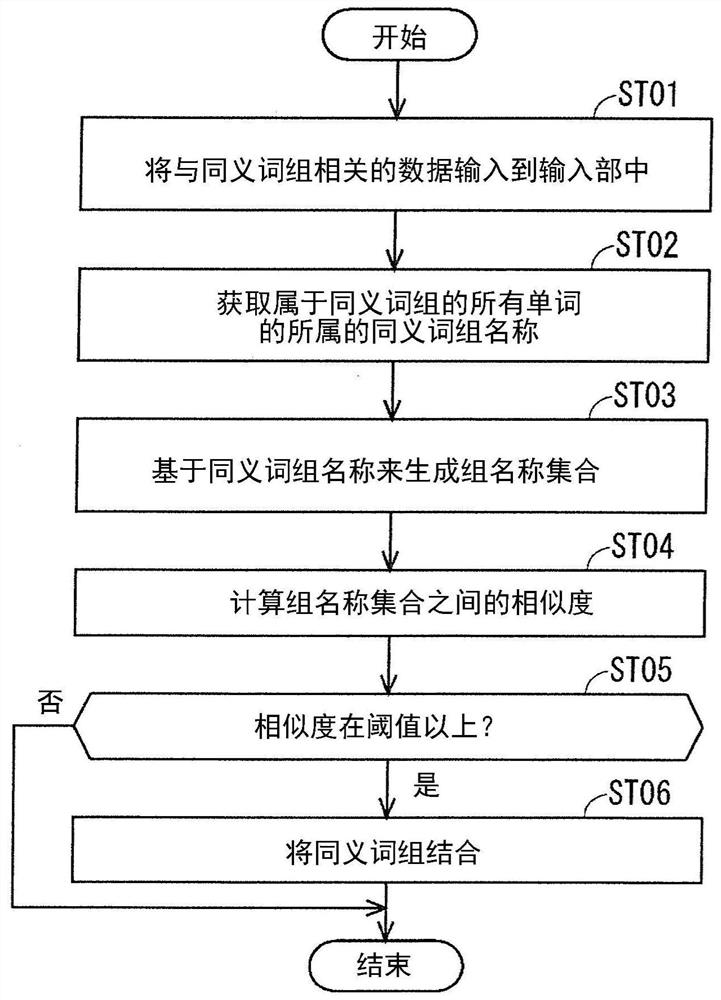
图3是表示计算相似度的动作的例子的流程图。
图4是表示某个单词所属的同义词组和属于该同义词组的单词的例子的图。
附图标记的说明:
10:名称获取部
12:名称集合生成部
14:相似度计算部
16:结合部
18:输入部
20:输出部
22:存储部
100:相似度计算装置
101:显示器
102:CPU
103:存储器
104:HDD
105:程序
106:外部存储介质
107:网络
具体实施方式
以下,参照附图来说明实施方式。在以下的实施方式中,虽然为了说明技术而示出了详细的特征等,但这些是示例性的,这些所有的特征并不都是为了能够实施实施方式的必要的特征。
需要说明的是,附图是概略表示的图,为了便于说明,在附图中适当省略结构或者简化结构。另外,在不同的附图中分别示出的结构等的大小以及位置的相互关系未必被准确地记载,能够适当地进行变更。另外,即使在不是剖视图的俯视图等的附图中,为了容易理解实施方式的内容,有时也标注阴影线。
另外,在以下的说明中,对相同的结构构件赋予相同的附图标记,这些构件的名称以及功能也相同。因此,为避免重复有时省略对这些构件的详细说明。
另外,在以下记载的说明中,在记载为“具备”、“包括”或“具有”某结构构件等的情况下,只要没有特别说明,就不是将其他的结构构件的存在除外的排他性的表现。
另外,在以下记载的说明中,即使在使用“第一”、“第二”等序数的情况下,这些术语也是为了容易理解实施方式的内容而使用的术语,并不限定于由这些序数产生的顺序等。
<实施方式>
以下,对与本实施方式相关的相似度计算装置、相似度计算程序以及相似度计算方法进行说明。
<关于相似度计算装置的结构>
图1是表示与本实施方式相关的相似度计算装置100的硬件结构的例子的图。
如图1的例子所示,相似度计算装置100至少是安装有用于同义词组之间的相似度的计算动作的程序105的计算机,并且该相似度计算装置100具有:中央运算处理装置(central processing unit,即CPU)102、存储器103、硬盘驱动器(Hard disk drive,即HDD)104以及显示器101。
在相似度计算装置100中,对应的程序105被安装在HDD104中。程序105的安装可以通过将从光盘(compact disc,即CD)、数字多功能光盘(digital versatile disc,即DVD)、通用串行总线(universal serial bus,即USB)存储器等的外部存储介质106读取的数据写入HDD104来执行,或者通过将经由网络107接收到的数据写入HDD104来执行。
另外,HDD104也可以置换为其他种类的辅助存储装置。例如,HDD104也可以置换为固态驱动器(solid state drive,即SSD)、随机存取存储器(random access memory,即RAM)磁盘等。
在相似度计算装置100中,安装在HDD104中的程序105被加载到存储器103中,并且由CPU102执行已加载的程序105。由此,计算机执行程序105,并作为相似度计算装置100发挥功能。
需要说明的是,CPU102执行的处理的至少一部分也可以由CPU102以外的处理器执行。例如,由CPU102执行的处理的至少一部分也可以由图像处理装置(GPU)等执行。另外,由CPU102执行的处理的至少一部分也可以由不执行程序的硬件来执行。
图2是表示与本实施方式相关的相似度计算装置100的功能结构的例子的图。
如图2的例子所示,相似度计算装置100至少具有:名称获取部10、名称集合生成部12以及相似度计算部14。另外,相似度计算装置100能够具有结合部16、输入部18、输出部20以及存储部22。输入部18以及输出部20通过图1的显示器101等来实现。另外,存储部22例如通过图1的存储器103以及HDD104中的至少一方来实现。另外,名称获取部10、名称集合生成部12、相似度计算部14以及结合部16例如通过使图1的CPU102执行程序105来实现。
名称获取部10获取属于同义词组的各个单词所属的同义词组的名称(以下,称为同义词组名称)。
其中,同义词组是由相互为同义词的多个单词组成的集合。另外,同义词是指词形、发音或表述等不同,但具有相同语义的单词。
另外,除了后述的专业术语之外,假设本实施方式中的各个单词属于至少两个同义词组,后述的专业术语仅属于一个同义词组。
名称集合生成部12生成以同义词组名称为元素的组名称集合。生成的组名称集合被存储在存储部22中。
相似度计算部14计算多个组名称集合之间的相似度。然后,基于计算出的组名称集合之间的相似度,来判断对应的同义词组之间的相似度。计算出的组名称集合之间的相似度以及对应的同义词组之间的相似度被存储在存储部22中。
当多个组名称集合之间的相似度(或者,同义词组之间的相似度)在阈值以上时,结合部16将与这些组名称集合对应的同义词组相互结合。通过结合而生成的同义词组被存储在存储部22中。
在输入部18中输入与同义词组相关的数据。另外,输出部20输出计算出的组名称集合之间的相似度(或者,同义词组之间的相似度),或者输出与通过结合而生成的同义词组相关的数据。
<关于相似度计算装置的动作>
接下来,参照图3以及图4,对相似度计算装置100的动作,具体来说对计算多个同义词组之间的相似度的动作进行说明。需要说明的是,图3是表示计算相似度的动作的例子的流程图。
其中,以下所提及的多个同义词组可以是所有同义词组根据共同的基准而创建的同义词组,也可以是几个同义词组根据与其他不同的基准而创建的同义词组。具体来说,可以混合由用户单独创建的同义词组和根据在外部词典(例如,WordNet)等中采用的基准而创建的同义词组。
首先,将与两个同义词组(同义词组G1以及同义词组G2)相关的数据分别输入到输入部18中(图3的步骤ST01)。其中,假设同义词组G1是包含(end、finish、stop)的同义词组,同义词组G2是包含(cease、terminate、finish)的同义词组。
另外,假设在与上述的同义词组相关的数据中至少包括同义词组中包含的各个单词的数据以及这些单词所属的同义词组名称的数据。同义词组名称能与对应的单词相关联。
图4是表示某个单词所属的同义词组和属于该同义词组的单词的例子的图。需要说明的是,图4中所示的同义词组表示对应的单词的一部分。
如图4的例子所示,单词design属于同义词组design.n.01和同义词组purpose.n.01。其中,design以及designing属于同义词组design.n.01,purpose、intent、intention、aim以及design属于同义词组purpose.n.01。
同样地,单词paper属于同义词组composition.n.08和同义词组newspaper.n.01。其中,composition、paper、report以及theme属于同义词组composition.n.08,newspaper以及paper属于同义词组newspaper.n.01。
接下来,名称获取部10针对输入到输入部18中的各个同义词组的数据,获取属于各个同义词组的所有单词的所属的同义词组名称(图3的步骤ST02)。
接下来,名称集合生成部12基于在名称获取部10中获取的同义词组名称,生成组名称集合(图3的步骤ST03)。生成的组名称集合被存储在存储部22中。
在本实施方式的例子中,获得end.n.01、end.v.04、finish.n.08、stop.v.01、period.n.07等53个同义词组名称,作为同义词组G1中的单词end、finish以及stop各自所属的同义词组名称的集合。将这些集合作为组名称集合G11。需要说明的是,以下也同样地,假设在同义词组名称的集合中不包括相同的同义词组名称(即,不允许相同的同义词组名称的重复)。另外,在组名称集合G11中也可以包括同义词组G1自己的名称。
同样地,获得cease.n.01、complete.v.01、finish.n.08等20个同义词组名称,作为同义词组G2中的单词cease、terminate以及finish各自所属的同义词组名称的集合。将这些集合作为组名称集合G12。需要说明的是,在组名称集合G12中也可以包括同义词组G2自己的名称。
在上述中,假设在组名称集合G11和组名称集合G12的两者中共同的同义词组名称为18个。
接下来,相似度计算部14计算组名称集合之间的相似度(图3的步骤ST04)。在本实施方式的例子中,相似度计算部14使用Dice系数来计算组名称集合之间的相似度。计算出的组名称集合之间的相似度被存储在存储部22中。
具体来说,使用以下的数学式(1),来计算组名称集合G11与组名称集合G12之间的相似度。
其中,|G11|表示组名称集合G11的元素个数,|G12|表示组名称集合G12的元素个数,而G11∩G12表示在组名称集合G11和组名称集合G12两者中共同的元素个数。
如上所述,组名称集合G11是具有53个元素的集合,组名称集合G12是具有20个元素的集合。另外,在组名称集合G11和组名称集合G12两者中共同的元素个数是18个。
因此,组名称集合G11与组名称集合G12之间的相似度能够大概表示为0.493。基于计算出的组名称集合之间的相似度,例如能够由相同的数值表示对应的同义词组G1与同义词组G2之间的相似度。
其中,假设另一个同义词组G3。同义词组G3是包括(complete、accomplish、finish)的同义词组。
关于同义词组G3,也与同义词组G1以及同义词组G2同样地被输入到输入部18中(图3的步骤ST01),通过名称获取部10获取属于同义词组G3的所有单词的所属的同义词组名称(图3的步骤ST02)。然后,通过名称集合生成部12基于获取的同义词组名称生成组名称集合(图3的步骤ST03)。
在本实施方式的例子中,获得achieve.v.01、complete.v.01、finish.n.08等26个同义词组名称,作为同义词组G3中的单词complete、accomplish以及finish各自所属的同义词组名称的集合。将这些集合作为组名称集合G13。需要说明的是,在组名称集合G13中也可以包括同义词组G3自己的名称。
在上述中,假设组名称集合G11和组名称集合G13两者中共同的同义词组名称为15个。
接下来,与计算组名称集合G11和组名称集合G12之间的相似度的情况同样地,相似度计算部14计算组名称集合G11与组名称集合G13之间的相似度(图3的步骤ST04)。计算出的组名称集合之间的相似度被存储在存储部22中。
如上所述,组名称集合G11是具有53个元素的集合,组名称集合G13是具有26个元素的集合。另外,组名称集合G11与组名称集合G13两者中共同的元素个数为15个。
因此,通过将上述的数学式(1)中的|G12|置换为|G13|(组名称集合G13的元素个数),将G11∩G12置换为G11∩G13(组名称集合G11与组名称集合G13两者中共同的元素个数)并进行运算,从而组名称集合G11与组名称集合G13之间的相似度能够大概表示为0.379。基于计算出的组名称集合之间的相似度,例如,能够由相同的数值表示对应的同义词组G1与同义词组G3之间的相似度。
如上所述,通过计算组名称集合之间的相似度,即使在对于一个单词创建了多个同义词组的情况下,也能够通过在组名称集合之间的相似度较高的同义词组之间进行后述那样的结合等,从而有效地实现术语的统一。
在本实施方式的例子中,虽然在同义词组G1、同义词组G2以及同义词组G3中共同包含有finish,但通过参照属于各个同义词组的单词的所属的同义词组名称,从而在构成同义词组的单词的语义倾向相似的同义词组G1与同义词组G2之间,计算出在组名称集合之间相对较高的相似度,另一方面,在构成同义词组的单词的语义倾向不同的同义词组G1与同义词组G3之间,计算出在组名称集合之间相对较低的相似度。
因此,根据本实施方式,通过一边考虑构成同义词组的单词的语义倾向,一边计算与同义词组对应的组名称集合之间的相似度,从而能够以较高的精度判断对应的同义词组之间的相似度。然后,例如,通过仅使用相似度较高的同义词组,从而能够有效地实现术语的统一。
另外,即使在同义词组中包含有多义词的情况下,由于反映该多义词所具有的多个语义的同义词组名称包含在组名称集合中,因此,能够通过考虑多义词的语义的扩展来计算组名称集合之间的相似度。
接下来,结合部16判断在相似度计算部14中计算出的组名称集合之间的相似度(或者,同义词组之间的相似度)是否在预先确定的阈值以上(图3的步骤ST05)。然后,当组名称集合之间的相似度(或者,同义词组之间的相似度)在预先确定的阈值以上时,即,当与从图3的例子所示的步骤ST05分支的“是”对应时,进入图3的例子所示的步骤ST06。另一方面,当组名称集合之间的相似度(或者,同义词组之间的相似度)不在预先确定的阈值以上时,即,当与从图3的例子所示的步骤ST05分支的“否”对应时,结束动作。
在图3的步骤ST06中,结合部16将与计算出组名称集合之间的相似度的组名称集合对应的同义词组相互结合。在本实施方式中,例如,将阈值设为0.4,将对应的同义词组G1与同义词组G2进行结合,并将同义词组G1中包含的所有单词与同义词组G2中包含的所有单词包括在一个同义词组中。此时,以使单词不重复的方式对单词进行结合。另一方面,由于与组名称集合G11和组名称集合G13对应的组名称集合之间的相似度小于阈值,因此,不将这些同义词组进行结合。需要说明的是,上述的阈值能够由用户任意地设定。
<关于仅属于一个同义词组的情况>
接下来,对在计算对应的组名称集合之间的相似度的多个同义词组中的至少一个中,包含有仅属于一个同义词组的单词的情况的动作进行说明。需要说明的是,以下,将仅属于一个同义词组的单词,即,不属于自己所属的同义词组以外的任何同义词组的单词称为专业术语。
在任一个同义词组中包含有专业术语的情况下,使用以下的数学式(2),来调整组名称集合的元素个数。
其中,G
如上所述,在调整组名称集合的元素个数之后,进行图3的步骤ST04所示的组名称集合之间的相似度的计算。进一步地,根据需要,在图3的步骤ST05的基础上进而进行步骤ST06所示的同义词组的结合。
具体来说,针对包含专业术语的同义词组G4以及同义词组G5,来计算对应的组名称集合之间的相似度的情况如下所示。
假设同义词组G4是包含(terminate_job、terminate、finish)的同义词组,同义词组G5是包含(complete_job、accomplish_job、finish)的同义词组。其中,terminate_job是专业术语。
获得end.v.03、complete.v.01、finish.n.08等18个同义词组名称,作为同义词组G4中的单词terminate_job、terminate以及finish各自所属的同义词组名称的集合。将这些集合作为组名称集合G14。需要说明的是,在组名称集合G14中可以包含同义词组G4自己的名称。
同样地,获得end.v.01、complete.v.01、finish.n.08等15个同义词组名称,作为同义词组G5中的单词complete_job、accomplish_job以及finish各自所属的同义词组名称的集合。将这些集合作为组名称集合G15。需要说明的是,在组名称集合G15中可以包含同义词组G5自己的名称。
在上述中,假设在组名称集合G11与组名称集合G14两者中共同的同义词组名称为17个。另外,假设在组名称集合G11和组名称集合G15两者中共同的同义词组名称为15个。
在该情况下,对在计算与同义词组G1对应的组名称集合G11和与同义词组G4对应的组名称集合G14之间的相似度时的、组名称集合G14的元素个数通过进行如下调整来增加。
同样地,对在计算与同义词组G1对应的组名称集合G11和与同义词组G5对应的组名称集合G15之间的相似度时的、组名称集合G15的元素个数通过进行如下调整来增加。
因此,通过将上述的数学式(1)中的|G12|置换为|G14|(组名称集合G14的元素个数),将G11∩G12置换为G11∩G14(在组名称集合G11和组名称集合G14两者中共同的元素个数)并进行运算,从而组名称集合G11与组名称集合G14之间的相似度能够大概表示为0.425。基于计算出的组名称集合之间的相似度,例如,能够由同样的数值表示对应的同义词组G1与同义词组G4之间的相似度。
同样地,通过将上述的数学式(1)中的|G12|置换为|G15|(组名称集合G15的元素个数),将G11∩G12置换为G11∩G15(在组名称集合G11和组名称集合G15两者中共同的元素个数)并进行运算,从而组名称集合G11与组名称集合G15之间的相似度能够大概表示为0.306。基于计算出的组名称集合之间的相似度,例如,能够由同样的数值表示对应的同义词组G1与同义词组G5之间的相似度。
这样,通过针对包含有专业术语的同义词组来调整对应的组名称集合的元素个数,从而通过仅考虑专业术语以外的元素来计算相似度,能够抑制计算出的相似度过高的情况。因此,能够提高组名称集合之间的相似度计算的精度。
<关于通过以上记载的实施方式产生的效果>
接下来,将示出由以上记载的实施方式产生的效果的例子。需要说明的是,在以下的说明中,虽然基于在以上记载的实施方式中所例示的具体结构来描述该效果,但在产生相同的效果的范围内,也可以置换为本申请说明书中所例示的其他具体结构。
根据以上记载的实施方式,相似度计算装置具有:名称获取部10、名称集合生成部12以及相似度计算部14。名称获取部10获取至少一个第一组名称(同义词组名称)和至少一个第二组名称(同义词组名称),所述第一组名称是属于多个同义词组中的第一同义词组(例如,同义词组G1)的各个单词所属的同义词组的名称,所述第二组名称是属于多个同义词组中的第二同义词组(例如,同义词组G2)的各个单词所属的同义词组的名称。名称集合生成部12生成以至少一个第一组名称(同义词组名称)为元素的第一组名称集合(例如,组名称集合G11)和以至少一个第二组名称(同义词组名称)为元素的第二组名称集合(例如,组名称集合G12)。然后,相似度计算部14计算第一组名称集合(例如,组名称集合G11)与第二组名称集合(例如,组名称集合G12)之间的相似度。
根据这种结构,即使在创建多个同义词组的情况下,也能够通过计算与同义词组对应的组名称集合之间的相似度,从而一边考虑构成同义词组的单词的语义倾向一边来判断同义词组之间的相似度。因此,例如,能够通过汇总相似度较高的同义词组彼此,从而有效地实现术语的统一。需要说明的是,在同义词组中包含多义词的情况下,若在不考虑单词的语义倾向的情况下仅基于有无共同的单词等来计算同义词组之间的相似度,则虽然存在即使在同义词组中包含的单词的语义倾向不同的同义词组之间也计算出具有较高的相似度的情况,但根据上述的结构,能够抑制这样的不良情况。
需要说明的是,在上述结构中适当添加了本申请说明书中所例示的其他的结构的情况下,即,即使在适当添加了未提及的本申请说明书中的其他结构作为上述结构的情况下,也能够产生同样的效果。
另外,根据以上记载的实施方式,相似度计算装置100具有结合部16,当组名称集合之间的相似度在阈值以上时,该结合部16将对应的第一同义词组和第二同义词组进行结合。根据这种结构,能够使组名称集合之间的相似度较高的对应的同义词组相互结合。因此,通过使构成同义词组的单词的语义倾向相似的同义词组相互结合,如果使用结合后的该同义词组,则能够有效地进行术语的统一。另外,由于用于判断组名称集合之间的相似度的阈值可以调整,因此,能够根据用途来调节结合判断的严格度。
另外,根据以上记载的实施方式,相似度计算部14使用Dice系数来计算相似度。根据这种结构,基于使用Dice系数计算出的组名称集合之间的相似度,能够判断对应的同义词组之间的相似度。
另外,根据以上记载的实施方式,相似度计算部14根据第一组名称集合中的能够获取的第一组名称只有一个的单词(即,专业术语)的个数,使第一组名称集合的元素个数增加,并且,根据第二组名称集合中的能够获取的第二组名称只有一个的单词(即,专业术语)的个数,使第二组名称集合的元素个数增加。根据这种结构,通过仅考虑专业术语以外的元素来减少表观上的组名称集合的元素个数,能够抑制计算出的组名称集合之间的相似度过高的情况。因此,能够提高组名称集合之间的相似度的计算的精度。
根据以上记载的实施方式,通过在计算机(例如,CPU102)中安装相似度计算程序并执行,使CPU102获取至少一个第一组名称和至少一个第二组名称,所述第一组名称是属于多个同义词组中的第一同义词组的各个单词所属的同义词组的名称,所述第二组名称是属于多个同义词组中的第二同义词组的各个单词所属的同义词组的名称。然后,使CPU102生成以至少一个第一组名称为元素的第一组名称集合和以至少一个第二组名称为元素的第二组名称集合。然后,使CPU102计算第一组名称集合与第二组名称集合之间的相似度。
根据这种结构,即使在创建多个同义词组的情况下,由于通过计算与同义词组对应的组名称集合之间的相似度,也能够一边考虑构成同义词组的单词的语义倾向一边判断同义词组之间的相似度,因此,例如,通过仅使用相似度较高的同义词组,从而能够有效地实现术语的统一。
需要说明的是,上述程序也可以存储在磁盘、软盘、光盘、压缩光盘、蓝光(注册商标)盘或DVD等计算机可读取的移动记录介质中。并且,存储有实现上述功能的程序的移动记录介质也可以在商业上流通。
根据以上记载的实施方式,在相似度计算方法中,包括以下工序:获取至少一个第一组名称和至少一个第二组名称的工序,所述第一组名称是属于多个同义词组中的第一同义词组的各个单词所属的同义词组的名称,所述第二组名称是属于多个同义词组中的第二同义词组的各个单词所属的同义词组的名称;生成以至少一个第一组名称为元素的第一组名称集合和以至少一个第二组名称为元素的第二组名称集合的工序;以及计算第一组名称集合与第二组名称集合之间的相似度的工序。
根据这种结构,即使在创建多个同义词组的情况下,由于通过计算与同义词组对应的组名称集合之间的相似度,也能够一边考虑构成同义词组的单词的语义倾向一边判断同义词组之间的相似度,因此,例如,通过仅使用相似度较高的同义词组,从而能够有效地实现术语的统一。
需要说明的是,在没有特别限制的情况下,可以改变执行各个处理的顺序。
<关于以上记载的实施方式的变形例>
在上述的实施方式中,虽然使用Dice系数来计算同义词组之间的相似度,但计算相似度的方法并不限定于该方法,例如也可以使用Jaccard系数或者Simpson系数等来计算同义词组之间的相似度。
因此,在本申请说明书所公开的技术的范围内,设想没有例示的无数个变形例以及等价物。例如,在对至少一个结构构件进行变形的情况下,包括追加的情况或省略的情况。
另外,以上记载的实施方式所记载的各个结构构件即使作为软件或者固件,也被设想为与其对应的硬件,在其双方的概念中,各个结构构件被称为“部”或者“处理电路”(circuitry)等。
- 相似度计算装置、相似度计算方法和记录程序的记录介质
- 相似度计算装置、相似度计算方法以及相似度计算程序