移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明涉及流行度预测技术领域,特别是涉及移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法。
背景技术
移动边缘计算技术将缓存和计算资源同时部署在网络边缘,是提供物联网,车联网和智慧城市等业务的有效框架,可以缓解数据中心不断增长的流量负担。移动边缘计算网络中边缘节点的密集部署,例如无线电接入点或微基站等,能够允许对用户近端接入并访问移动边缘计算服务器上的丰富计算资源与缓存资源。但是,缓存资源的有效利用还得进一步依赖于一个有效地缓存策略。边缘缓存被认为是一种经济有效的方法,可以解决回程瓶颈问题并减少内容检索和切换延迟。一个边缘缓存策略的性能很大在很大程度上取决于流行数据的选择机制,该选择必须能够从巨大的数据洪流中选择出值得被缓存的内容,这就需要依赖于对用户的主观兴趣或需求进行一个精准的预测,也称之为流行度预测。
近年来,许多研究工作对动态流行度预测进行了研究,并提出了包括时序预测,社交驱动的预测和基于统计信息的预测等多种流行度预测方法。但是这些预测方法往往都非常依赖于用户的隐私数据,因而会对用户的隐私安全保护带来巨大的隐患。事实上,在当今很多行业,特别是在电子医疗和自动驾驶等相关行业,用户私有数据泄漏可能会导致灾难性的后果,如危及用户生命安全以及或者给数据提供商造成严重的财产损失。以此,充分利用移动边缘计算网络的计算优势,在保护用户隐私的进行下进行流行度预测将是真正可用于实际的研究方向。针对以上描述,本发明提出了一种移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法。
发明内容
有鉴于此,本发明的目的在于提供一种移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法,用以解决背景技术中提及的技术问题,本发明通过对每个用户的局部动态流行度模型的构建,以及对全局动态流行度模型的推导,将系统中的内容流行度预测问题建模成一个分布式预测问题;通过结合循环神经网络、自编码器以及联邦学习架构,提出了一种无监督循环联邦学习,最后通过迭代训练,获得了隐私保护约束下的流行度预测方案设计。
为了达到上述目的,本发明采用如下技术方案:
移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法,所述预测方法基于移动边缘计算系统,该系统包括服务器端和多个用户端,所述服务器端和所述用户端之间实现通信连接;所述预测方法包括如下步骤:
步骤S1、构建用户端的文件请求概率模型,通过考虑用户端主观兴趣的变化性来构建每个用户端文件请求的动态流行度模型,根据每个用户端的局部流行度得到服务这些用户端的服务器端的动态全局流行度模型;
步骤S2、利用用户端的历史请求,在保护用户的隐私约束下,构建局部流行度和全局流行度的分布式预测模型;
步骤S3、采用联邦学习框架,训练学习迭代得出在用户隐私保护约束下的各流行度分布式预测方案。
进一步的,考虑一个典型的单接入节点服务I个用户的移动边缘计算系统,其中服务内容库包含N个文件,表示为
公式(1)中,
进一步的,在所述步骤S1中,通过动态变化的α
公式(2)中,
进一步的,在所述步骤S1中,所述每个用户端文件请求的动态流行度模型的表达式为:
公式(3)中,
进一步的,在所述步骤S1中,所述动态全局流行度模型在时刻t的表达式可以推导得出:
进一步的,在所述步骤S2中,在每个用户端,以长短期记忆神经元作为最小单元,搭建一个结构完全相同的自编码器神经网络。第i个用户端所部署的神经网络的网络参数可表示为
在服务器端,部署与所述自编码器神经网络中的编码器结构相同的网络作为全局流行度的预测网络模型。
进一步的,在所述步骤S2中,任意一个用户端i在t+1时刻的局部流行度预测值的表达式为:
公式(5)中,R
服务器端在时刻t+1的全局流行度预测值的表达式为:
公式(6)中,
进一步的,所述保护用户的隐私约束具体包括:所述服务器端在时刻t结束之前必须删除所收到的用户内容请求信息R
进一步的,所述步骤S3具体包括;
步骤S301、每个用户端的历史请求数据表示为
步骤S302、在用户端,每个用户端部署的神经网络预测模型进行独立训练;
步骤S303、对于用户端i,每次训练,通过提取器R
公式(7)中,
步骤S304、每个用户端在进行了T次训练之后,就向服务器端上传一次最近的网络模型参数Θ
步骤S305、在服务器端,服务器端将所有收到的用户端的网络模型参数堆叠成
公式(8)中,ω
步骤S306、更新全局流行度预测网络的模型参数,表达式为:
公式(9)中,Θ
步骤S307、一旦步骤S305中的参数聚合操作完成,服务器端将通过边缘节点将新的参数Θ
步骤S308、用户端在收到参数Θ
本发明的有益效果是:
本发明提供的移动边缘计算网络中一种基于无监督循环联邦学习的隐私保护流行度预测方法,能够在保护用户隐私数据的同时,有效地降低流行度的预测误差。仿真结果表明,相比于其它预测算法,本发明提出的移动边缘计算网络中一种基于无监督循环联邦学习的隐私保护流行度预测方法能提供额外的预测准确度增益。
附图说明
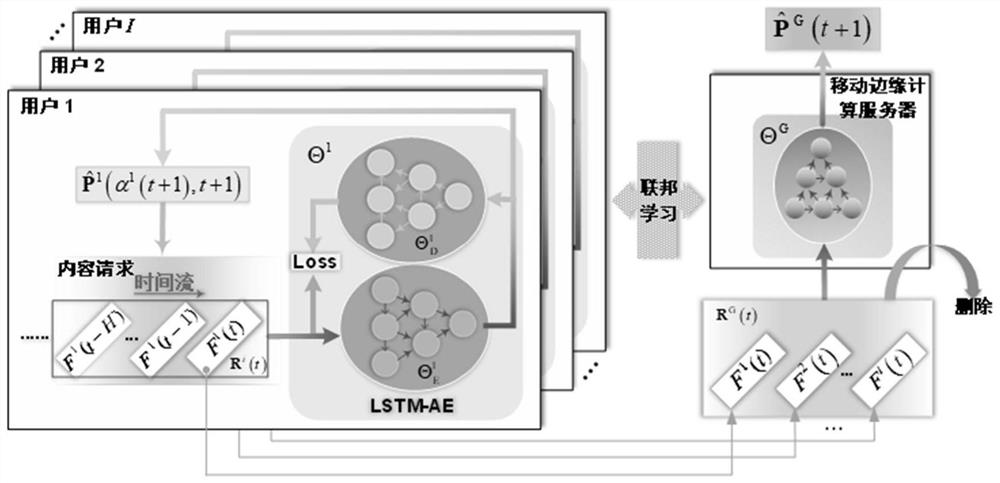
图1为本发明实施例中提出的无监督循环联邦学习算法的网络架构图。
图2为本发明实施例中提出的基于长短期记忆元的自编码器神经网络的架构图。
图3为本发明实施例中各个用户端的局部流行度预测误差结果示意图。
图4为不同算法在移动边缘计算服务器端的全局流行度预测性能的对比示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
参见图1-图4,本实施例提供一种移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法,具体步骤如下:
考虑一个典型的单接入节点服务I各用户的移动边缘计算系统,其中服务内容库包含N个文件,表示为
此外,接入节点上配备有移动边缘计算服务器,能够进行一定量的内容缓存,假设能缓存M
假设任意用户i在时刻t的产生内容请求
其中,
用向量
用动态变化的α
因此,α
其中,
用向量
因此,时刻t的全局流行度可以表示为:
可以看出,局部流行度的动态性涉及到α
因此,本实施例考虑隐私保护约束下的局部和全局流行度分布式预测,以帮助提升系统中的缓存资源利用效率。
具体地,任意用户i在t+1时刻的局部流行度预测值可以表示为
其中,R
在本实施例中,采用基于自编码器神经网络来构建预测模型从而解决训练过程中训练标签P
其中
具体的说,在本实施例中,所有用户的局部流行度预测问题以及服务器端的全局流行度预测问题是在用户隐私保护约束下进行分布式并行预测的,因此,本实施例提出一种无监督循环联邦学习(Unsupervised recurrent federated learning,URFL)算法来进行解决。
具体地,系统中UFRL算法的网络架构图,如图1所示。其中,在每个用户的本地设备端,分别部署网络结构完全一样的、基于长短期记忆元的自编码器神经网络(Long short-term memory auto encoder,LSTM-A)用于实时预测各自的局部流行度。
在移动边缘计算服务器端,则只部署与LSTM-AE中编码器相同结构的神经网络作为全局流行度实时预测网络。
具体的说,循环神经网络(Recurrent neural network,RNN)能够对复杂的时间任务执行分层处理,因此,它能够自然地捕捉时间序列中的底层时间依赖关系。而长短期记忆元(Long short-term memory,LSTM)作为循环神经网络中的一个重要基本单元,被用于本实施例中的自编码器框架下,能够挖掘出长历史请求序列R
更具体的说,LSTM-AE网络地详细架构,如图2所示。其中x
更具体的说,本实施例中采用的基于联邦学习的分布式训练具体步骤为:
每个用户的历史请求数据表示为
对于用户i,通过提取器R
公式中,
在移动边缘计算服务器端,服务器将所有收到的用户本地模型参数堆叠成
其中ω
更新全局模型参数,表达式为:
一旦参数聚合操作完成,移动边缘计算服务器将会通过边缘节点将新的参数Θ
本地用户在收到参数Θ
算法总结如下表
综上,针对本实施例中考虑隐私保护约束的移动边缘计算通信系统,本实施例限制所有用户的历史请求数据均不可被外界访问。同时移动边缘计算服务器每次所接收到的用户请求信息,也必须被及时删除,不允许保留超过一个时隙。基于此,本实施例在考虑用户隐私保护限制条件下,解决了局部与全局内容流行度的分布式预测问题。本实施例通过结合循环神经网络在时序相关信息挖掘上的优势,自编码器在无监督学习上的去标签训练优势以及联邦学习架构在隐私保护上的优势,提出了一种在无监督循环联邦学习算法。最后通过分布式的迭代训练得到隐私保护下的流行度预测方法。
仿真示例
本发明实施例中,对于一种移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法,本实施例采用python进行仿真。仿真中,内容文件总数N=24,用户的请求信息提取器窗口长度H=10,所有学习算法训练时的学习率统一设置为10
图3描述了本发明所提出的一种移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法在用户端地实验结果。从图3左侧可以发现所提出的流行度预测方法下,每个用户预测自己局部流行度时,预测误差都能够稳定收敛与一个满意的水平。同时,我们从图3左侧可以观察到,在所提方法下,不同用户在各自局部流行度预测误差上存在一定的差异。这是因为在本实施例提出的系统中,每个用户的兴趣都是非独立同分布的,体现在每个用户的流行度模型参数
但是,通过图3右侧的仿真结果可以发现,所提流行度预测方法在任意用户(图中以用户7为例)上的预测性能,依旧始终是优于用户的自我训练(Self-train)方案。这表明,本实施例所提方法在进行用户端的流行度预测时,能够保护用户隐私的同时,提高局部流行度的预测准确率。
图4仿真对比了不同算法在在移动边缘计算服务器端的全局流行度预测性能。从图4可以发现,所提出的基于无监督循环联邦学习流行度预测方法在实现隐私保护的同时,其预测准确率还优于其它所有的基线流行度预测算法。这是因为,所提流行度预测方法的参数聚合过程推动了移动边缘计算服务器深入而准确地学习其覆盖范围内所有用户的底层特征。相比之下,基线方法不仅需要大量的用户私有数据,而且还无法从大量的、混合所有用户在时间和空间上的历史请求数据中精确地提取有用特征。
综上,本实施例分别从用户本地的局部流行度预测和移动边缘服务器端的全局流行度预测两个角度进行仿真验证。同时,本实施例仿真对比了所提算法同奇异值分解(SVD,singular value decomposition)算法、单层全连接自编码器联邦学习(SDAEFL,singledense auto-encoder federated learning)算法、深度全连接自编码器联邦学习(DDAEFL,deep dense auto-encoder federated learning)算法和深度循环自编码器学习(DRAEL,deep recurrent auto-encoder learning)算法之间性能差异。其中,SVD和DRAEL集中式地部署在移动边缘计算服务器上,没有任何隐私保护约束。对于SDAEFL和DDAEFL,都采用联邦学习架构进行数据隐私保护,但是这两个基线分别采用单层全连接的自编码器神经网络结构和深度全连接的自编码器神经网络结构来证明所提出的URFL中LSTM单元所带来的性能增益。
本发明未详述之处,均为本领域技术人员的公知技术。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 移动边缘计算网络中基于无监督循环联邦学习的隐私保护流行度预测方法
- 移动边缘计算网络中基于分布式强化学习的隐私保护动态边缘缓存设计方法