基于深度学习的雷达辅助相机标定方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明属于多传感器数据融合技术领域,主要涉及雷达点迹数据与图像目标位置信息的转换,具体是一种基于深度学习的雷达辅助相机标定方法,可用于雷达与相机摄像头同时存在时的相机标定任务。
背景技术
随着自动驾驶、无人监测等新技术的迅速发展,由于单一传感器自身不可避免的局限性的存在,利用单一传感器进行目标检测的准确性、稳定性能性能较低。因此为了提高目标检测的准确性、稳定性,工业领域多采取多传感器融合的方案。相机摄像头和雷达是目前主要的测距传感器元件,相机摄像头价格低廉,并能够快速捕捉环境信息并进行数字图像处理完成目标检测,但对于远距离的小目标检测能力较差;雷达能够准确捕获物体在三维空间的位置信息,测量速度快并且具备远距离测量的能力,但容易产生虚警,因而相机摄像头与雷达被广泛应用于多传感器数据融合中。在这种相机摄像头和雷达共用的方案中,相机标定在保障其自动化、智能化、高效化的领域内发挥着越来越重要的作用。
由于相机和雷达的安装位置不同,其坐标系具有空间差异,因而需要对相机和雷达进行空间标定,相机标定是将三维世界中的目标位置转换为图像中对应的目标位置的过程,是传感器数据融合的前提。为了保障自动驾驶、无人检测中的智能化目标检测的功能,精准可靠的相机标定已经成为不可或缺的环节。
传统的相机标定法需要在特定辅助标定板和标定设备的配合下,通过建立标定物上坐标已知的点与其图像目标点之间的对应关系,获得相机模型的内外参数,例如《二维激光雷达与可见光相机外参标定方法研究》通过利用两种传感器在不同位姿下的测量数据,利用拟合参数的方式求取摄像机摄像头的外部参数;《基于视觉标记板的自动驾驶车辆激光雷达与相机在线标定研究》利用经典的定向求解方法计算得到相机与激光雷达之间的刚性转换关系,在两种传感器中获取的摄像机的外部参数,与张正友标定法、伪逆法、最小二乘拟合法等类似,这些传统的相机标定方法均需建立复杂且专有的数学模型,并通过繁琐的计算完成。
在基于深度学习的相机标定方法中,例如《一种毫米波雷达与相机的自动标定方法》利用深度学习的方法将毫米波雷达点迹与图像目标点坐标进行标定,减小了标定工作量,将相机内参标定与传感器外参标定结合于一体,但其深度神经网络的参数量和计算量较大;《一种基于深度学习的相机标定方法及系统与流程》中,解决了现有视觉测量系统中相机位置及姿态必须保持不变的问题,避免相关数学模型、物理变量的繁杂计算和对专有固定的辅助结构的依赖,但其仍具有较为复杂的流程和较大的计算量。
在工业应用中,与传统的相机标定方法相比,基于深度学习的相机标定方法虽然解决了传统的相机标定的复杂数学模型和繁杂计算,但仍有较大参数量和计算量,不利于工业应用,并且传统的相机标定方法和基于深度学习的相机标定方法只能将雷达点迹数据转换为图像中的目标点,然而在图像目标检测过程中,目标在图像中均以目标框的形式出现,仅将雷达点迹数据转换为图像中的目标点会出现若干雷达点迹数据对应同一个图像目标框的情况,因而导致系统的准确性较差。
在现有相机标定技术中,大多需要复杂的数学模型和繁杂计算,仅只能对相机内部参数或相机外部参数其中一个参数进行标定,模型的灵活性和泛化能力较低。在相机标定过程中,均为雷达点迹到图像目标点的转换,没有将雷达点迹转换到图像目标框信息,多传感器融合任务的精度较低,不便于后续的雷达与相机摄像头的数据关联任务和多传感器融合目标检测任务。
发明内容
本发明的目的在于克服上述已有技术的缺点,提出一种雷达点迹到图像目标框的且采取跨层链接的基于深度学习的雷达辅助相机标定方法。
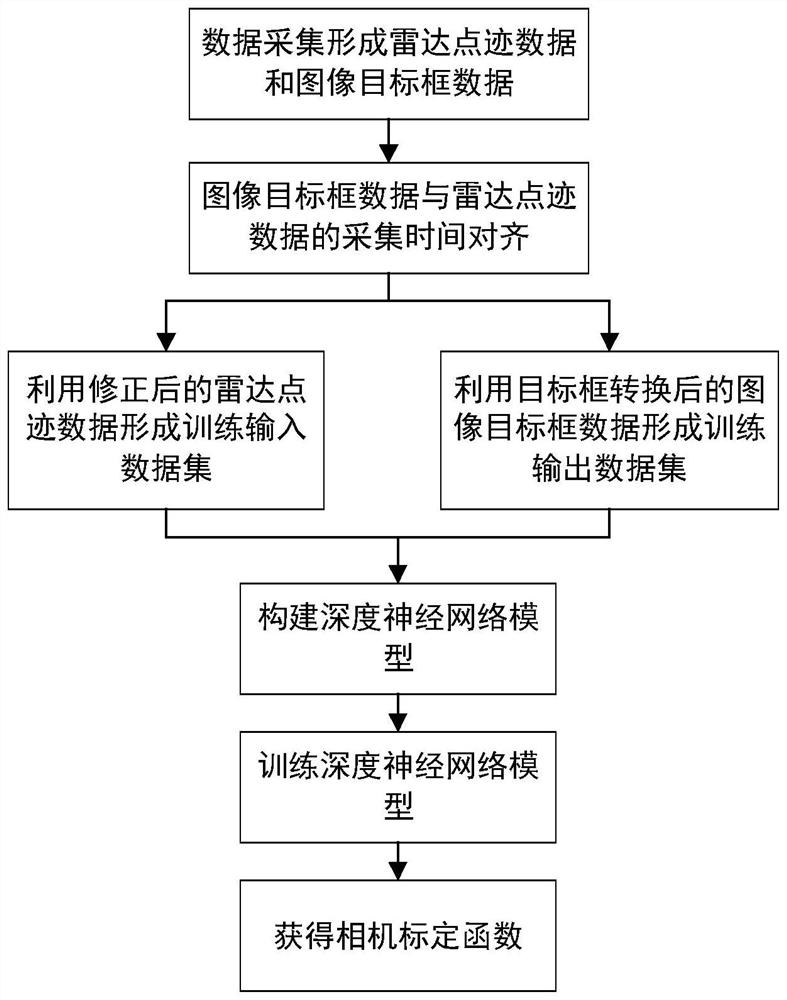
本发明是一种基于深度学习的雷达辅助相机标定方法,其特征在于,通过雷达进行标定辅助,利用含有跨层链接的深度神经网络模型获得从雷达点迹到图像目标框的相机标定函数,用于多传感器融合的目标跟踪检测任务,包括有如下步骤:
步骤1:数据采集形成雷达点迹数据和图像目标框数据:将雷达与摄像头组成的雷摄设备放置在需要进行目标检测的场景中,利用该雷摄设备分别采集M个雷达点迹数据
步骤2:图像目标框数据与雷达点迹数据的采集时间对齐:在图像目标框数据中的第i个图像目标框的采集时间
步骤3:利用修正后的雷达点迹数据形成训练输入数据集:通过修正时间对齐后的雷达点迹数据中与前后雷达点迹不连续的数据,得到修正后的雷达点迹数据,利用修正后的雷达点迹数据形成训练输入数据集
步骤4:利用目标框转换后的图像目标框数据形成训练输出数据集:将图像目标框中心点坐标
步骤5:构建深度神经网络模型:将雷达点迹数据集构建的训练输入数据集
步骤6:训练深度神经网络模型:将训练输入数据集
步骤7:获得相机标定函数:利用完成训练的深度神经网络模型,结合需要进行目标检测场景与场景中的相机姿态获得一个标定函数f:x→y,该标定函数f将输入数据x转换为输出数据y,其中x为雷达点迹数据(R,θ),y为图像目标框数据(x,y,h,w),并且应用此标定函数设置相机,应用于相机摄像头与雷达数据关联任务和多传感器融合的目标跟踪检测任务。
本发明解决了相机标定复杂的数学模型和繁杂计算以及从雷达点迹到图像目标框的转换的技术问题。
本发明与现有的技术相比,具有以下优点:
提高相机标定的灵活性和效率:本发明利用雷达与相机摄像头同时进行相机标定,改善了相机标定对专有辅助标定板与标定设备的局限性,将相机标定过程中分别对内外参数估计改为对相机标定的标定函数的估计,减小了利用辅助标定板与标定设备在标定过程中的人为误差和标定过程的额外工作,提高了相机标定的灵活性和效率;
采取跨层连接的深度神经网络模型,避免构建相机标定的复杂模型,减小深度神经网络模型计算量:本发明构建深度神经网络模型,将相机摄像头的内外参数进行整体建模,避免了传统相机标定过程中复杂的数学模型和繁杂计算,通过RC层的设计,避免了模型训练过程中的梯度爆炸问题,在保证准确率的前提下,减小了深度神经网络模型的参数量和计算量;
构建雷达点迹数据到图像目标框数据的标定函数,提高相机标定准确率:本发明通过设计点到框的IOA损失函数,构建点到框的深度神经网络模型总损失函数,通过对深度神经网络进行训练,得到雷达点迹数据到图像目标框之间的关系,避免多个雷达点迹数据对应一个图像目标框数据,提高了相机标定的准确率,有利于后续雷达与相机摄像头的数据关联任务和多传感器融合目标检测任务。
实验证明,本发明适用于各种目标检测场景下的雷达与相机摄像头同时存在时的相机标定任务,通过本方法进行相机标定后,标定结果的位置与目标大小均有较好结果,提高了相机标定的准确率。
附图说明
图1是本发明的总流程图;
图2是本发明采用的网络基本模块RC层结构图;
图3是本发明采用的网络结构图;
图4是利用本发明获得的图像目标框和人为标记的真实图像目标框在目标距离雷摄设备小于50米的情况下的可视化对比图;
图5是利用本发明获得的图像目标框和人为标记的真实图像目标框在目标距离雷摄设备50米到100米的范围内的可视化对比图;
图6是利用本发明获得的图像目标框和人为标记的真实图像目标框在目标距离雷摄设备大于100米的情况下的可视化对比图;
图7是利用本发明获得的图像目标框和人为标记的真实图像目标框在目标高速行驶情况下的可视化对比图;
图8是利用本发明获得的图像目标框和基于伪逆法获得的图像目标框的可视化对比图;
图9是利用本发明获得的图像目标框和基于最小二乘曲面拟合的相机标定方法获得的图像目标框可视化对比图。
下面结合附图对本发明详细说明:
具体实施方法
实施例1:
随着自动驾驶、无人监测等新技术的迅速发展,由于单一传感器自身不可避免的局限性的存在,工业领域多采取多传感器融合的方案。相机摄像头和雷达作为目前主要的测距传感器元件,被广泛应用于多传感器数据融合中。由于相机和雷达的安装位置不同,其坐标系具有空间差异,因而需要对相机和雷达进行空间标定。
传统的相机标定法需要在特定辅助标定板和标定设备的配合下,通过建立标定物上坐标已知的点与其图像目标点之间的对应关系,获得相机模型的内外参数,例如张正友标定法、伪逆法、最小二乘拟合法等,这些传统的相机标定方法均建立复杂且专有的数学模型,并通过繁琐的计算完成。
在基于深度学习的相机标定方法中,利用深度学习的方法将雷达点迹与图像目标点坐标进行标定,将相机内参标定与传感器外参标定结合于一体,避免相关数学模型、物理变量的繁杂计算和对专有固定的辅助结构的依赖,减小了标定工作量,但其深度神经网络的参数量和计算量较大,且在多传感器融合目标检测任务中会出现传感器目标不匹配的现象,影响多传感器融合目标检测精度。
在现有相机标定技术中,与传统的相机标定方法相比,基于深度学习的相机标定方法虽然解决了传统的相机标定的复杂数学模型和繁杂计算,但仍有较大参数量和计算量,不利于工业应用,并且传统的相机标定方法和基于深度学习的相机标定方法只能将雷达点迹数据转换为图像中的目标点,然而在图像目标检测过程中,目标在图像中均以目标框的形式出现,将雷达点迹数据转换为图像中的目标点这一过程会出现若干雷达点迹数据对应同一个图像目标框的情况,导致系统的准确性较差,在多传感器数据融合任务时会出现目标不匹配的现象,不便于后续的雷达与相机摄像头的数据关联任务和多传感器融合目标检测任务的精度的提升。本发明针对这些问题展开了研究与探讨,提出一种基于深度学习的雷达辅助相机标定方法。
本发明是一种基于深度学习的雷达辅助相机标定方法,参见图1,本发明中通过雷达进行标定辅助,利用跨层链接的深度神经网络模型获得从雷达点迹到图像目标框的相机摄像头标定函数,用于多传感器融合的目标跟踪检测任务,包括有如下步骤:
步骤1:数据采集形成雷达点迹数据和图像目标框数据:将雷达与相机摄像头组成的雷摄设备放置在需要进行目标检测的场景中,利用该雷摄设备分别采集M个雷达点迹数据
步骤2:图像目标框数据与雷达点迹数据的采集时间对齐:在图像目标框数据中的第i个图像目标框的采集时间
步骤3:利用修正后的雷达点迹数据形成训练输入数据集:通过修正时间对齐后与前后雷达点迹不连续的数据,得到修正后的雷达点迹数据,利用修正后的雷达点迹数据形成训练输入数据集
步骤4:利用目标框转换后的图像目标框数据形成训练输出数据集:将图像目标框中心点坐标
步骤5:构建深度神经网络模型:将雷达点迹数据集构建的训练输入数据集
也可以这样描述,将雷达点迹数据集构建的训练输入数据集
步骤6:训练深度神经网络模型:将训练输入数据集
步骤7:获得相机标定函数:利用完成训练的深度神经网络模型,结合需要进行目标检测场景与场景中的相机姿态获得一个标定函数f:x→y,该标定函数f将输入数据x转换为输出数据y,其中x为雷达点迹数据(R,θ),y为图像目标框数据(x,y,h,w),并且应用此标定函数设置相机,应用于相机摄像头与雷达数据关联任务和多传感器融合目标跟踪检测任务多传感器融合目标检测任务和数据关联任务。
本发明给出了一种在雷达与相机摄像头共同作用进行目标检测时更加精准的一种相机标定方法的整体技术方案。
现有相机标定方法利用辅助标定板或标定设备,构建具有复杂的数学模型,通过较大的计算量,获取相机摄像头的内外参数,也有方法将相机摄像头内外参数进行整体建模,获取雷达点迹数据和图像目标点数据的转换关系,本发明建模雷达点迹数据和图像目标框的转换关系,本发明思路是通过深度神经网络模型,将相机摄像头的内外参数进行整体建模,构建雷达点迹数据和图像目标框的转换关系,减小了利用辅助标定板与标定设备在标定过程中的人为误差和标定过程的额外工作,提高了相机标定的灵活性和准确率,避免了传统相机标定过程中复杂的数学模型和繁杂计算。
实施例2:
基于深度学习的雷达辅助相机标定方法同实施例1,步骤5中构建深度神经网络模型,包括有如下步骤:
5.1:构建深度神经网络模型整体框架:深度神经网络模型的输入为通过雷达点迹构建的训练输入数据集
5.2:构建深度神经网络模型中RC层:深度神经网络模型中RC层的输入为一个p维向量,将这一p维向量输入到一个输入为p、输出为q的全连接层中,获得一个q维向量,接着利用Sigmoid激活函数对这一q维向量进行非线性变换,紧接着对非线性变换后的q维数据进行批标准化,再将批标准化后的q维数据输入到输入维q、输出p的全连接层中,获得一个p维向量,接着利用Sigmoid激活函数对该p维向量进行非线性变换,再对非线性变换后的p维向量进行批标准化,将经过批标准化的p维向量与RC层输入的p维向量跨层连接,即这两个向量相加即为RC层的输出,其中RC层的宽度q≥4,q为整数,q的取值可以根据输入的数据量进行改变。
现有基于深度学习的相机标定方法,连续搭建若干全连接层或者若干卷积层作为深度神经网络模型,需要较大的网络宽度或深度,参数量和计算量较大,本发明通过构建RC层,在深度神经网络模型中设置较小的网络深度和网络宽度,即p、q和K,就可达到较好的效果,因而本发明的在拥有较小的参数量和计算量时依然能够达到可观的效果;通过设置RC层的跨层连接,避免了深度神经网络模型训练过程中的梯度爆炸的问题,在保证准确率的前提下,减小了深度神经网络模型的参数量和计算量。
实施例3:
基于深度学习的雷达辅助相机标定方法同实施例1-2,步骤6中所述的训练深度神经网络模型,包括有如下步骤:
6.1:深度神经网络模型的前向传播:将通过雷达点迹构建的训练输入数据集
6.2:构建点到框的IOA损失函数:在深度神经网络模型中,构建点到框的IOA损失函数IOA,在N个一一对应的深度神经网络模型输出
具体地说,第i个深度神经网络模型输出与训练输出数据集目标框交集的宽为
6.3:构建点到框的深度神经网络模型总损失函数:点到框的深度神经网络模型总损失函数L描述如下:L=λ
6.4:深度神经网络模型的反向传播:利用6.3中的点到框的深度神经网络模型总损失函数,通过神经网络的反向传播算法,计算深度神经网络中权重的梯度,利用神经网络更新策略更新神经网络的参数,通过epoch次迭代,获得一个训练好的深度神经网络模型。
现有将相机摄像头内外参数进行整体建模的相机标定技术,通过数学模型或者深度神经网络模型,获取雷达点迹数据与图像目标点之间的转换关系,本发明设计点到框的IOA损失函数,构建点到框的深度神经网络模型总损失函数,通过对深度神经网络进行训练,得到雷达点迹数据到图像目标框之间的关系,避免多个雷达点迹数据对应一个图像目标框数据,提高了相机标定的准确率,有利于后续雷达与相机摄像头的数据关联任务和多传感器融合目标检测任务。
下面给出一个综合性的例子,对本发明进一步说明:
实施例4:
基于深度学习的雷达辅助相机标定方法同实施例1-3,
本发明是一种基于深度学习的雷达辅助相机标定方法,参见图1,本发明对雷达辅助相机标定包括有如下步骤:
步骤1:数据采集形成雷达点迹数据和图像目标框数据:将雷达与摄像头组成的雷摄设备放置在需要进行目标检测的场景中,利用该雷摄设备分别采集M个雷达点迹数据
步骤2:图像目标框数据与雷达点迹数据的采集时间对齐:在图像目标框数据中的第i个图像目标框的采集时间
其中步骤2中的将雷达点迹采集时间和图像采集时间进行对齐,包括有如下步骤:
2.1:根据雷达点迹数据的时间
2.2:利用二次插值的方法估计采集时间
步骤3:利用修正后的雷达点迹数据形成训练输入数据集:通过修正时间对齐后与前后雷达点迹不连续的数据,得到修正后的雷达点迹数据,利用修正后的雷达点迹数据形成训练输入数据集
其中步骤3中的对雷达点迹数据进行修正,包括有如下步骤:
3.1:对时间对齐后雷达点迹数据
3.2:利用
3.3:将图像目标框数据集合
步骤4:利用目标框转换后的图像目标框数据形成训练输出数据集:将图像目标框中心点坐标
步骤5:构建深度神经网络模型:将雷达点迹数据集构建的训练输入数据集
其中步骤5中的构建深度神经网络模型,包括有如下步骤:
5.1:构建深度神经网络模型整体框架:深度神经网络模型的输入为通过雷达点迹构建的训练输入数据集
5.2:构建深度神经网络模型中RC层:深度神经网络模型中RC层的输入为一个p维向量,将这一p维向量输入到一个输入为p、输出为q的全连接层中,获得一个q维向量,接着利用Sigmoid激活函数对这一q维向量进行非线性变换,紧接着对非线性变换后的q维数据进行批标准化,再将批标准化后的q维数据输入到输入维q、输出p的全连接层中,获得一个p维向量,接着利用Sigmoid激活函数对该p维向量进行非线性变换,再对非线性变换后的p维向量进行批标准化,将经过批标准化的p维向量与RC层输入的p维向量跨层连接,即这两个向量相加即为RC层的输出,其中RC层的宽度q≥4,q为整数,q的取值可以根据输入的数据量进行改变。
步骤6:训练深度神经网络模型:将训练输入数据集
其中步骤6中的训练深度神经网络模型,包括有如下步骤:
6.1:深度神经网络参数设置:设置网络的RC层数量K,隐藏层宽度p,RC Layer宽度q,学习率lr,迭代次数epoch,批标准化大小b,损失权重参数λ=[λ
6.2:深度神经网络模型的前向传播:将通过雷达点迹构建的训练输入数据集
更详细地说,假设深度神经网络模型共K+2层,每一层的输出结果为h
6.3:构建点到框的IOA损失函数:在深度神经网络模型中,构建点到框的IOA损失函数IOA,在N个一一对应的深度神经网络模型输出
具体地说,第i个深度神经网络模型输出与训练输出数据集地目标框有交集时,深度神经网络模型输出与训练输出数据集目标框交集的宽为
6.4:构建点到框的深度神经网络模型总损失函数:点到框的深度神经网络模型总损失函数L描述如下:L=λ
6.5:深度神经网络模型的反向传播:利用步骤6.3中的点到框的深度神经网络模型总损失函数,通过神经网络的反向传播算法,计算深度神经网络中权重的梯度,利用神经网络更新策略更新神经网络的参数,即:
步骤7:获得相机标定函数:利用完成训练的深度神经网络模型,结合需要进行目标检测场景与场景中的相机姿态获得一个标定函数f:x→y,该标定函数f将输入数据x转换为输出数据y,其中x为雷达点迹数据(R,θ),y为图像目标框数据(x,y,h,w),R为雷达点迹数据距离,θ为雷达点迹数据角度,x为图像目标框横轴坐标,y为图像目标框纵轴坐标,h为图像目标框高度,w为图像目标框宽度,并且应用此标定函数设置相机,应用于相机摄像头与雷达数据关联任务和多传感器融合目标跟踪检测任务。
本发明的效果可以通过以下实验进一步说明:
实施例5:
基于深度学习的雷达辅助相机标定方法同实施例1-4,
实验条件与环境:采用毫米波雷达和8毫米相机摄像头放置在作用面上作为雷摄设备,软件python作为网络训练工具,CPU是AMD A8-5550M,主频为2.10GHz,内存16G,操作系统为Windows 10旗舰版。
实验内容:
将本发明的方法获得的图像目标框结果与通过人为标定获得的真实图像目标框数据进行比较。通过毫米波雷达与相机摄像头组成的雷摄设备获得若干雷达点迹数据和图像数据。利用人为标注获取图像数据的真实目标框数据,利用本发明获得的标定函数,将这些雷达点迹数据转换为图像目标框数据,将本发明获得的图像目标框数据和真实目标框数据同时画在对应图像数据上进行可视化分析。
实验结果与分析:
在本发明获得的图像目标框数据和真实目标框数据可视化分析中,如图4、图5、图6、图7所示,图中虚线框为通过人为标定得到的真实目标框,实线框为本发明相机标定方法获得的目标框。
在校园内空旷地方进行实验,目标为一位行人,参见图4。图4是一位行人在距离雷达与相机摄像头组成的雷摄设备小于50米的情况下相机摄像头获得的背影图,将雷达点迹通过本发明获得的图像目标框用实线框可视化在图4中,同时将通过人为标注获得的真实图像目标框用虚线框可视化在图4中,得到本发明获得的图像目标框和人为标记的真实图像目标框在目标距离雷摄设备小于50米的情况下得到的可视化对比图。
从图4中两个目标框的结果可以看出,本发明获得的目标框的底边边框与人为标注得到的目标框的底边边框几乎重合,本发明获得的目标框的底部中点位置与人为标注得到的目标框的底部中点位置也相近。也可以从图4中看出,本发明获得的目标框的高度与人为标注得到的目标框的高度相差较小,但是本发明获得的目标框的宽度与人工标记得到的目标框宽度相比较宽。总体而言,本发明获得的目标框将人为标注得到的目标框大部分包含在内,并且本发明获得的目标框大小适宜。
实施例6:
基于深度学习的雷达辅助相机标定方法同实施例1-4,实验条件与环境和实验内容同实施例5。在校园内空旷地方进行实验,目标为一位行人,参见图5。
图5为一位行人在距离雷达与相机摄像头组成的雷摄设备50米到100米的范围内相机摄像头获得的侧身图,将雷达点迹通过本发明获得的图像目标框用实线框可视化在图5中,同时将通过人为标注获得的真实图像目标框用虚线框可视化在图5中,得到本发明获得的图像目标框和人为标记的真实图像目标框在目标距离雷摄设备50米到100米的范围内的可视化对比图。
从图5中两个目标框的结果可以看出,本发明获得的目标框的底边边框与人为标注得到的目标框的底边边框几乎重合,并且本发明获得的目标框的底部中点位置与人为标注得到的目标框的底部中点位置几乎一致。也可以从图5中看出,本发明获得的目标框的高度与人为标注得到的目标框的高度相差较小,并且本发明获得的目标框的宽度与人工标记得到的目标框宽度相比较宽。总体而言,本发明获得的目标框将人为标注得到的目标框大部分包含在内,也可以说图5中的目标全部包含在本发明获得的目标框内,并且本发明获得的目标框大小适宜。
实施例7:
基于深度学习的雷达辅助相机标定方法同实施例1-4,实验条件与环境和实验内容同实施例5,参见图6。
在校园内空旷地方进行实验,目标为一位行人,参见图6。图6为一位行人在距离雷达与相机摄像头组成的雷摄设备大于100米的情况下相机摄像头获得的背影图,将雷达点迹通过本发明获得的图像目标框用实线框可视化在图6中,同时将通过人为标注获得的真实图像目标框用虚线框可视化在图6中,得到本发明获得的图像目标框和人为标记的真实图像目标框在目标距离雷摄设备大于100米的情况下的可视化对比图。
从图6中两个目标框的结果可以看出,本发明获得的目标框的底边边框与人为标注得到的目标框的底边边框完全重合,并且本发明获得的目标框的底部中点位置与人为标注得到的目标框的底部中点位置相近。也可以从图6中看出,本发明获得的目标框的高度与人为标注得到的目标框的高度相差较小,并且本发明获得的目标框的宽度与人工标记得到的目标框宽度相比较宽。从目标框整体大小的角度看,本发明获得的目标框大小与人为标注获得的目标框大小相比较大,但本发明完成捕获到目标,获得的目标框将人为标注得到的目标框包含在内,且将目标的外轮廓均包含在内,目标框中心偏差较小,相机标定精度较高。
当目标为微小目标时,可以将本发明获得的目标框裁剪下来进行目标检测,提高图像中小目标的检测准确率,进而提高多传感器融合目标跟踪检测任务的精度。
实施例8:
基于深度学习的雷达辅助相机标定方法同实施例1-4,实验条件与环境和实验内容同实施例5,参见图7。
在校园内空旷地方进行实验,目标为一位骑自行车的行人,参见图7。图7为一位骑自行车以较高速度行驶的行人在雷达与相机摄像头组成的雷摄存在时相机摄像头获得的正面图,将雷达点迹通过本发明获得的图像目标框用实线框可视化在图7中,同时将通过人为标注获得的真实图像目标框用虚线框可视化在图7中,得到利用本发明获得的图像目标框和人为标注获得的真实图像目标框在目标高速行驶情况下的可视化对比图。
从图7中两个目标框的结果可以看出,本发明获得的目标框的高度与人为标注得到的目标框的高度相差较小,但是本发明获得的目标框的宽度与人工标记得到的目标框宽度较宽。也可以从图7中看出,本发明获得的目标框的底边边框与人为标注得到的目标框的底边边框距离较小,本发明获得的目标框的底部中点位置与人为标注得到的目标框的底部中点位置也具有一定偏差,并且本发明获得的目标框大小与人为标注获得的目标框大小相比较大,但本发明获得的目标框将大部分人为标注得到的目标框包含在内,同时图7中的目标也全部包含在本发明获得的目标框内,目标框的中心位置偏差较小,相机标定准确度较高。
上述实例均为本发明相机标定方法图像目标框数据和真实目标框数据的对比结果,由上述实验得到的可视化对比图可见,本发明能够捕捉到完整的目标,可以直观地看到本发明标定方法能够将图像数据中的目标的全部放在目标框中。并且与真实目标框数据相差较小,实验证明本发明的相机标定精度较高。
实施例9:
基于深度学习的雷达辅助相机标定方法同实施例1-4,实验条件与环境同实施例5,
实验内容:
通过毫米波雷达与相机摄像头组成的雷摄设备获得若干雷达点迹数据和图像数据,通过人为标注获取图像数据的真实目标框数据,本例中,在同等条件下利用本发明的方法和基于伪逆法的相机标定方法进行相机标定,将这些雷达点迹数据转换为图像目标框数据,将获得的图像目标框数据可视化在对应的图像数据上进行比较。
实验结果与分析:
在校园内空旷地方进行实验,目标为一位侧身行走的行人,参见图8。图8为一位行人在雷达与相机摄像头组成的雷摄存在时相机摄像头获得的侧身图,将雷达点迹通过本发明获得的图像目标框用实线框可视化在图8中,将雷达点迹通过基于伪逆法获得的图像目标框用点线框可视化在图8中,同时将通过人为标注获得的真实图像目标框用虚线框可视化在图8中,得到利用本发明获得的图像目标框数据和基于伪逆法获得的图像目标框数据的可视化对比图。
从图8中的三个目标框可以看出,基于伪逆法获得的目标框位置与通过人为标注得到的真实目标框位置相比有较大偏差,而利用本发明方法获得的目标框的位置与通过人为标注得到的真实目标框的位置的偏差较小,并且本发明方法获得的目标框的底边边框与通过人为标注得到的真实目标框的底边边框几乎重合。基于伪逆法获得的目标框宽高与通过人为标注得到的真实目标框宽高相比均有较大差异,而本发明方法获得的目标框的高度与通过人为标注得到的真实目标框的高度相比较小,并且本发明方法获得的目标框的宽度与通过人为标注得到的真实目标框的宽度相比较宽。总体而言,基于伪逆法获得的目标框与真实目标框有较大偏差,而本发明方法获得的目标框的位置和大小虽有一定偏差,但目标完全包含在本发明方法获得的目标框内。因此,与基于伪逆法的相机标定方法相比较,本发明的相机标定方法获得的图像目标框更准确,相机标定结果更精准。
实施例10:
基于深度学习的雷达辅助相机标定方法同实施例1-4,实验条件与环境同实施例5。
实验内容:
通过毫米波雷达与相机摄像头组成的雷摄设备获得若干雷达点迹数据和图像数据,通过人为标注获取图像数据的真实目标框数据,本例中,在同等条件下利用本本发明的方法与基于最小二乘曲面拟合法的相机标定方法,将这些雷达点迹数据转换为图像目标框数据,将获得的图像目标框数据可视化在对应的图像数据上进行比较。
实验结果与分析:
在校园内空旷地方进行实验,目标为一位行走的行人,参见图9。图9为一位行人在雷达与相机摄像头组成的雷摄设备存在时相机摄像头获得的背影图,将雷达点迹通过本发明获得的图像目标框用实线框可视化在图9中,将雷达点迹通过基于最小二乘曲面拟合获得的图像目标框用点划线框可视化在图9中,同时将通过人为标注获得的真实图像目标框用虚线框可视化在图9中,得到利用本发明获得的图像目标框数据和基于伪逆法获得的图像目标框数据的可视化对比图。
从图9中的三个目标框可以看出,基于最小二乘曲面拟合法获得的目标框位置与通过人为标注得到的真实目标框位置相比偏差较小,而利用本发明方法获得的目标框的位置与通过人为标注得到的真实目标框的位置的偏差更小。基于最小二乘曲面拟合法获得的目标框的高度与通过人为标注得到的真实目标框的高度相比较小,但基于最小二乘曲面拟合法获得的目标框的宽度与通过人为标注得到的真实目标框的宽度相比较为相似,而本发明获得的目标框宽高与通过人为标注得到的真实目标框宽高相比均偏大。总体而言,基于最小二乘曲面拟合法获得的目标框与真实目标框有一定偏差,但目标并未完全包含在基于最小二乘曲面拟合法获得的目标框内。而本发明方法获得的目标框的位置和大小虽有一定偏差,但目标完全包含在本发明方法获得的目标框内。因此,与基于最小二乘曲面拟合的相机标定方法相比较,本发明的相机标定方法获得的图像目标框更准确,相机标定结果具有更高的精度。
实施例11:
基于深度学习的雷达辅助相机标定方法同实施例1-4,实验条件与环境同实施例5。
实验内容:
通过毫米波雷达与相机摄像头组成的雷摄设备以及本发明中的步骤1、步骤2、步骤3、步骤4获得K个训练输入数据
平均交集占比即IOA值:
足底点横轴坐标均方误差:
足底点纵轴坐标均方误差:
图像目标框宽高比:
表1不同特征下重构结果的数值指标
实验结果与分析:
表1中的横向表头为本实验中的四种量化指标,分别为:平均交集占比即IOA值、足底点横轴坐标均方误差、足底点纵轴坐标均方误差、图像目标框宽高比。在这四种量化指标中,平均交集占比和图像目标框宽高比两种指标越大,也就是说这两种指标越趋于1越能表明相机标定方法越准确;足底点横轴坐标均方误差和足底点纵轴坐标均方误差两种指标越小越能表明相机标定方法越精准。
纵向表头为本实验中的三种方法,分别为本发明的相机标定方法、基于伪逆法的相机标定方法、基于最小二乘曲面拟合法的相机标定方法。由于可视化结果存在主观因素的影响,视觉效果并不能精确的说明重构效果的好坏,用量化的指标能够更准确的反映相机标定效果,相机标定结果评价指标参见表1。对于同一雷达坐标的输入,在四种不同量化指标中,本发明的平均交集占比趋于1,足底点横轴坐标均方误差较小,足底点纵轴坐标均方误差较小,并且目标框宽高比较大,表明本发明的结果比较精准。相比于本发明,伪逆和最小二乘方法的平均交集占比较小,足底点横轴坐标均方误差较大,足底点纵轴坐标均方误差较大,并且目标框宽高比较小,表明这两种方法的较差。本发明相较于基于伪逆和基于最小二乘方法的相机标定方法,在足底坐标均方误差、平均交集占比和目标框宽高比方面有很大的提高,表明本发明的效果显著优于其他的方法,本发明的相机标定具有更好的准确率。
综上所述,本发明的基于深度学习的雷达辅助相机标定方法,解决了相机标定复杂的数学模型和繁杂计算以及从雷达点迹到图像目标框的转换的技术问题。实现步骤为:数据采集形成雷达点迹数据和图像目标框数据;图像目标框数据与雷达点迹数据的采集时间对齐;利用修正后的雷达点迹数据形成训练输入数据集;利用目标框转换后的图像目标框数据形成训练输出数据集;构建深度神经网络模型;训练深度神经网络模型;获得相机标定函数。本发明在雷达与相机摄像头同时进行目标检测的情况下进行相机标定,将相机标定过程中分别对内外参数估计改为对相机标定的标定函数的估计,将雷达点迹数据转换为图像目标框数据构成标定函数,减小了利用辅助标定板与标定设备在标定过程中的人为误差和标定过程的额外工作,提高了相机标定的灵活性和效率;利用深度神经网络模型避免构建相机标定的复杂模型,减小深度神经网络模型计算量,构建雷达点迹数据到图像目标框数据的标定函数,提高相机标定准确率。用于多传感器融合的目标检测任务中,更具体地用在雷达和相机摄像头同时进行目标检测的情况下的相机标定。
- 基于深度学习的雷达辅助相机标定方法
- 一种基于深度学习的相机标定方法及系统