一种基于混合样本与标签的数据增强的图像描述方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及人工智能领域中的图像自动描述,特别是涉及图片用自然语言对图像客观内容进行描述的一种基于混合样本与标签的数据增强的图像描述方法。
背景技术
随着计算机视觉技术的发展,完成目标检测、识别、分割等任务已经不能满足人们的生产需求,对如何自动客观的对图像内容自动描述有迫切的需求。图像自动描述(ImageCaptioning)是近年来人工智能界提出的一个机器终极智能任务,它的任务是用自然语言描述图像的视觉内容。它的主要挑战不仅在于充分理解图像中的对象和关系,还在于生成与视觉语义相匹配的流利句子。和目标检测及语义分割等任务不同,图像自动描述要将图像中的物体、属性、物体间的关系以及相应的场景等用自动语言进行整体而客观的描述,该任务是计算机视觉理解的重要方向之一,被视为人工智能的一个重要标志。
较早的图像自动描述方法主要采用基于模板的方法和基于检索的方法实现。近年来受自然语言处理发展的影响,开始使用基于编码器-解码器框架的方法,通常采用预训练卷积神经网络(CNN)的变体作为图像编码器,同时使用递归神经网络(RNN)作为解码器。并引入注意力机制以及以强化学习为基础的目标函数,使得该任务取得极大的进展。
Xu等人[1]首次在图像描述任务中引入注意力机制,以在每个生成步骤中专注于最相关的区域。Lu等人[2]开发自适应注意来确定在每个解码步骤中是依赖视觉特征还是语言模型状态。Rennie等人[3]将强化学习技术引入到图像描述任务中,极大的提升图像描述方法的性能。最近,Anderson等人[4]还提出自下而上的注意力技术,以基于图像的区域特征来找到最相关的显着区域。Huang等人[5]则首次引入自然语言处理中的transformer模型到图像描述任务中,Pan等人[6]和Cornia[7]等人都使用Transformer模型来代替递归神经网络并取得最好的性能。
在增强生成的图像描述语句的多样性方面,Dai等人[8]和Dognin等人[9]使用生成对抗网络(GAN)来生成多样且类似于人类所描述的句子。Dai等人[10]使用对比学习技术来生成独特的句子,同时保持所生成句子的整体质量。Luo等人[11]使用检索模型来创建判别度高的训练目标,以生成各种字幕。同样,liu等人[12]训练另一种检索模型来使用检索得分优化,而不是CIDEr奖励值优化在强化学习阶段训练图像描述模型。但是,这些方法过于复杂且不易训练,并且没有解决由MS COCO数据集的数据不足引起的负面语言偏置的问题。
在图像分类领域,为解决数据集的偏置问题,加强模型的鲁棒性和泛化性,Zhang等人[13]提出一种简单且与数据集无关的数据增强方法,称为Mixup,该方法通过线性插值两个图像及其标签来随机创建新的训练样本。实验表明,它可以提高模型的性能和泛化能力,从而降低过度拟合的风险。Verma等人[14]对Mixup进行改进,在隐含空间中执行插值,以获得高级信息和更平滑的决策边界。Chen等人[15]将隐含空间的Mixup应用于文本分类。Ling等人[16]在Person ReID任务中用到Mixup。然而,Mixup在上述任务中只被应用到分类任务中,而没在序列生成任务上进行尝试。
参考文献:
[1].Xu,K.;Ba,J.;Kiros,R.;Cho,K.;Courville,A.;Salakhudinov,R.;Zemel,R.;and Bengio,Y.2015.Show,attend and tell:Neural image caption generationwith visual attention.In ICML.
[2].Lu,J.;Xiong,C.;Parikh,D.;and Socher,R.2017.Knowing when to look:Adaptive attention via a visual sentinel for image captioning.In CVPR.
[3].Steven J Rennie,Etienne Marcheret,Youssef Mroueh,JerretRoss,andVaibhava Goel.2017.Self-critical sequence training forimage captioning.InCVPR.
[4].Anderson,P.;He,X.;Buehler,C.;Teney,D.;Johnson,M.;Gould,S.;andZhang,L.2018.Bottom-up and top-down attention for image captioning and visualquestion answering.In CVPR.
[5].Huang,L.;Wang,W.;Chen,J.;andWei,X.-Y.2019.Attention on Attentionfor Image Captioning.In ICCV.
[6].Yingwei Pan,Ting Yao,Yehao Li,and Tao Mei.2020.X-linear attentionnetworks for image captioning.In CVPR.
[7].Cornia,M.;Stefanini,M.;Baraldi,L.;and Cucchiara,R.2020.Meshed-Memory Transformer for Image Captioning.In CVPR.
[8].Bo Dai,Sanja Fidler,Raquel Urtasun,and Dahua Lin.2017.Towardsdiverse and natural image descriptions via a conditional gan.In ICCV.
[9].Pierre Dognin,Igor Melnyk,Youssef Mroueh,Jerret Ross,and TomSercu.2019.Adversarial semantic alignment for improved image captions.InCVPR.
[10].Bo Dai and Dahua Lin.2017.Contrastive Learning for ImageCaptioning.In NeurIPS
[11].Ruotian Luo,Brian Price,Scott Cohen,and Gregory Shakhnarovich.2018.Discriminability objective for training descriptive captions.In CVPR.
[12].Xihui Liu,Hongsheng Li,Jing Shao,Dapeng Chen,and XiaogangWang.2018.Show,tell and discriminate:Image captioning by self-retrieval withpartially labeled data.In ECCV.
[13].Hongyi Zhang,Moustapha Cisse,Yann N Dauphin,and David Lopez-Paz.2018.mixup:Beyond empirical risk minimization.In ICLR.
[14].Vikas Verma,Alex Lamb,Christopher Beckham,Amir Najafi,IoannisMitliagkas,David Lopez-Paz,and Yoshua Bengio.2019.Manifold mixup:Betterrepresentations by interpolating hidden states.In ICML.
[15].Jiaao Chen,Zichao Yang,and Diyi Yang.2020.Mixtext:Linguistically-informed interpolation of hidden space for semi-supervisedtext classification.In ACL.
[16].Yongguo Ling,Zhun Zhong,Zhiming Luo,Paolo Rota,Shaozi Li,andNicu Sebe.2020.Class-Aware Modality Mix and Center-Guided Metric Learning forVisible-Thermal Person Re-Identification.In ACM MM.
发明内容
本发明的目的在于针对传统图像描述方法生成的语句缺乏判别性与多样性,以及所用数据集数据标准不足的缺点,提供一种基于混合样本与标签的数据增强的图像描述方法。通过混合不同输入的图像特征、语句词嵌入以及对于的损失函数值,使模型通过学习更加复杂的样本与目标来提升生成的图像描述语句的质量和判别性。
本发明包括以下步骤:
1)采用目标检测器随机提取待描述图像的若干个候选区和各个候选区对应的特征V={v
2)采用随机种子生成器对每个批次的输入生成一个服从beta分布的权值λ;
3)将输入的批次中的数据顺序打乱,将原序数据和乱序数据按照权值λ和(1-λ)进行线性混合;包括图像特征的混合和语句词嵌入的混合;
4)将步骤3)的混合输入送入解码器中,生成图像的描述语句,并分别与被混合的两个图像对应的两个标签语句进行损失值计算,将损失值按照权值λ和(1-λ)进行混合得到最终的损失值,用此损失值训练更新网络参数,实现数据增强。
在步骤1)中,所述目标检测器的训练方法是:目标检测器采用Faster-RCNN框架,其骨架网络是深度卷积残差网络,首先采用端到端的方法在经典目标检测数据集PASCALVOC2007中进行训练,然后在多模态数据集Visual Genome上进一步训练微调网络参数。
在步骤2)中,所述采用随机种子生成器对每个批次的输入生成一个服从beta分布的权值λ的具体方法是:使用numpy库中的random.beta方法为每个批次的输入数据生成服从beta分布的权值λ,其中,beta分布的参数为(0.5,0.5)。
在步骤3)中,所述将输入的图像特征混合和语句词嵌入混合的具体过程为:对于每一个批次输入的图像特征V,先将其随机打乱顺序得到V
其中,v和v
对于每一个批次输入的语句,首先对训练集中的文本内容进行去停用词处理,并将所有英文词汇进行小写化;然后对文本内容按空格进行分词,对于得到的若干单词,剔除数据集描述中出现次数小于阈值的单词,使用“
其中,w
在步骤4)中,所述将步骤3)的混合输入送入到解码器中,生成图像的描述语句,并分别与被混合的两个图像对应的两个标签语句进行损失值计算,将损失值按照权值λ和(1-λ)进行混合得到最终的损失值,用此损失值训练更新网络参数的具体过程为:
在图像描述任务中,定义语言解码器为Decoder,它的第t时刻的输入由混合图像特征
p(y
其中,W
其中,T为句子长度;通过监督学习和强化学习两个阶段对模型进行训练;在监督学习阶段,采用交叉熵,对于给定的针对被混合的两个图像的两个目标句子
在强化学习阶段,采用强化学习进行训练,其损失函数的梯度定义为:
其中,
本发明的优点如下:
通过本发明所提出的方案能够获得一个简单便捷的,针对多模态数据集进行数据增强的图像描述方法。本发明针对带有负面语义偏置的图像描述数据集中,使用一种多模态的数据增强方法,通过混合不同的输入的图像特征、语句词嵌入以及它们的对应损失值,让图像描述模型可以学习更加复杂多样的数据样本,提升图像描述语句的质量与判别性。同时,本发明具有很强的迁移性,能够适用于现有大多数的图像描述模型,并都取得性能提升。
附图说明
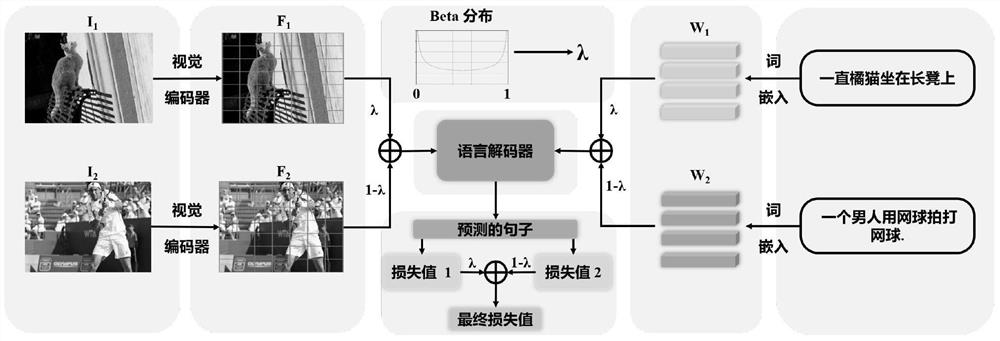
图1是本发明于混合样本与标签的数据增强的图像描述方法的流程图;其中,λ是混合的权值
图2是语句词嵌入混合并生成描述语句的流程图;其中,w
图3是混合损失值的流程图;
图4是不同的图像描述模型生成的句子对比图。其中,Baseline指的是Transformer模型,Transformer是一种经典的图像描述基线方法。(a)图中为不同的图像有相同的主语,(b)图中为不同的图像生成相同的描述句子;
图5则是DLCT模型(当前性能最好方法)和DLCT使用本发明方法训练后在生成某个单词时关注区域的可视化的对比图。
具体实施方式
以下实施例将结合附图对本发明进行详细说明。
本发明包括以下步骤:
1)对于图像库中的图像,首先使用卷积神经网络抽取相应的图像特征V;
2)对于图像对应的输入语句,转换为词嵌入矩阵;
3)将图像特征V和语句词嵌入S打乱顺序得到V
4)将前述的图像混合特征
5)将前述生成的图像描述语句Y
具体的每个模块如下:
1、深度卷积特征抽取与描述数据预处理
对所有训练数据中的文本内容进行去停用词处理,并将所有英文词汇进行小写化;然后对文本内容按空格进行分词,得到10201个单词,对数据集描述中出现次数小于五的单词进行剔除,使用“
先使用预训练好的目标检测器提取36个固定的候选区或将图像分成7×7的特征区域,并使用残差深度卷积网络提出各个候选区相对应的特征V={v
2、图像特征混合:
将每一批次的图像特征输入V打乱顺序得到V
其中,v和v
3、语句词嵌入混合:
对于每一个批次输入的语句,首先对训练集中的文本内容进行去停用词处理,并将所有英文词汇进行小写化;然后对文本内容按空格进行分词,对于得到的若干单词,剔除数据集描述中出现次数小于阈值的单词,使用“
其中,w
4、图像描述语句生成:
在图像描述任务中,定义语言解码器为Decoder,它的第t时刻的输入由混合图像特征
p(y
其中,W
其中,T为句子长度;
5、混合损失函数:
本发明通过监督学习和强化学习两个阶段对模型进行训练;在监督学习阶段,采用交叉熵,对于给定的针对被混合的两个图像的两个目标句子
在强化学习阶段,采用强化学习进行训练,其损失函数的梯度定义为:
其中,
为验证本发明提出的方法的可行性和先进性,在通用的评估图像描述方法的数据集MSCOCO进行模型的评估。其中和最新图像自动描述方法的量化比较如表1所示,可以看到在多种评估指标上以及不同的图像特征上,使用本发明所提出的方法训练原有的经典模型,在所有的指标上都有提升。此外,如图4所示,通过可视化输入图像所生成的文本描述(示例给出的描述为英文,中文描述自动生成过程同理),可以看到由于本发明的方法训练模型时采用混合的特征和损失值,和使用原本方法训练的基线模型(Transformer)相比,其在图像描述上取得很明显的增强,生成的图像描述语句判别性得到显著提升。图5为当前最好方法(DLCT)和使用本发明方法训练的DLCT对解码器关注区域的可视化的对比,该结果表明使用本发明方法进行训练后,原本模型可以更准确更具体的定位到要描述的区域,并生成对应的描述词语。
表1 本发明方法与当前最先进方法的比较
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 一种基于混合样本与标签的数据增强的图像描述方法
- 一种基于数据增强的半监督零样本图像分类方法