基于自适应注意力机制的图像描述生成方法
文献发布时间:2023-06-19 13:49:36
技术领域
本发明涉及人工智能领域中的视觉和语言多模态任务,具体是涉及对给定图像中视觉内容进行建模并用自然语言描述出来的一种基于可区分视觉词和非视觉词的自适应注意力机制的图像描述生成模型。
背景技术
图像描述旨在自动地生成自然语言来描述给定图像的视觉内容,这就要求图像描述模型不仅要能够确定给定图像中有哪些视觉对象,还要能够用捕获到这些视觉对象之间的关系并用自然语言表示出来。图像描述相当于模仿人类将大量显著的视觉信息压缩为描述性语言的非凡能力,因此是人工智能领域研究的一个重要的挑战。结合图像和语言理解,图像描述持续地启发很多突破计算机视觉和自然语言处理的界限的研究。
源自于机器翻译领域的编码器-解码器框架在众多图像描述模型[1,2]中得到广泛的应用。其中,编码器通常是一个基于卷积神经网络[3]的图像特征提取器,解码器通常是一个基于循环神经网络[4]的序列模型。此外,注意力机制[1,5,6,7]也被引入来帮助模型在序列化生成自然语言序列时关注相关联地图像位置。例如,[1]将软注意力和硬注意力引入到基于长短期记忆单元的解码器模块,[6]提出动态注意力机制在基于循环神经网络的解码器模块上动态地决定生成当前词时是否关注视觉信号,Anderson et al.[7]提出自底向上和自顶向下地注意力机制来关注区域级别的视觉内容,此外,[8,9,10,11,12]将transformer结构引入到图像描述模型中并且取得最优异的性能。
基于编码器-解码器框架,改进图像描述模型主要通过以下两种途径,一是优化从给定图像中提取的视觉特征,二是改进用于处理这些视觉特征的模型结构。对于目前最受欢迎的基于transformer结构的图像描述模型,有两个严重的问题尚未解决,一是将网格特征送入transformer结构前需要做展平处理,这两不可避免地造成空间信息的损失,二是在transformer结构中,单词序列堆叠在一起,所有单词的预测都按照相同的方式进行,没有有效的措施来区分视觉词和非视觉词。
涉及的参考文献如下:
[1].Xu,K.,Ba,J.,Kiros,R.,Cho,K.,Courville,A.C.,Salakhudinov,R.,Zemel,R.,Bengio,Y.:Show,attend and tell:Neural image caption generation with visualattention.In:ICML.pp.2048{2057(2015).
[2]A.Karpathy and L.Fei-Fei.Deep visual-semantic alignments forgenerating image descriptions.In CVPR,2015.1,4,5.
[3]Simonyan,K.,Zisserman,A.:Very deep convolutional networks forlarge-scale image recognition.arXiv preprint arXiv:1409.1556(2014).
[4]Hochreiter,S.,Schmidhuber,J.:Long short-term memory.NeuralComputation 9(8),1735{1780(nov 1997).
[5]Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser,L.,Polosukhin,I.:Attention is all you need.In:NeurIPS.pp.5998{6008(2017).
[6]Jiasen Lu,Caiming Xiong,Devi Parikh,and Richard Socher.Knowingwhen to look:Adaptive attention via a visual sentinel for image captioning.InProceedings of the IEEE conference on computer vision and patternrecognition,pages 375–383,2017.1,2,4.
[7].Anderson,P.;He,X.;Buehler,C.;Teney,D.;Johnson,M.;Gould,S.;andZhang,L.2018.Bottom-up and top-down attention for image captioning and visualquestion answering.In CVPR.
[8]Simao Herdade,Armin Kappeler,Kofi Boakye,and Joao Soares.Imagecaptioning:Transforming objects into words.In Advances in Neural InformationProcessing Systems,pages 11137–11147,2019.1,3,4,7.
[9]Lun Huang,Wenmin Wang,Jie Chen,and Xiao-Yong Wei.Attention onattention for image captioning.In Proceedings of the IEEE InternationalConference on Computer Vision,pages 4634–4643,2019.2,3,7,8.
[10]Guang Li,Linchao Zhu,Ping Liu,and Yi Yang.Entangled transformerfor image captioning.In Proceedings of the IEEE International Conference onComputer Vision,pages 8928–8937,2019.3,8.
[11]Marcella Cornia,Matteo Stefanini,Lorenzo Baraldi,and RitaCucchiara.Meshed-memory transformer for image captioning.In Proceedings oftheIEEE/CVF Conference on Computer Vision and Pattern Recognition,pages 10578–10587,2020.1,2,3,6,7,8.
[12]Yingwei Pan,Ting Yao,Yehao Li,and Tao Mei.X-linear attentionnetworks for image captioning.In Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition,pages 10971–10980,2020.1,2,3,7,8.
[13]Steven J Rennie,Etienne Marcheret,Youssef Mroueh,Jerret Ross,andVaibhava Goel.Self-critical sequence training for image captioning.InProceedings of the IEEE Conference on Computer Vision and PatternRecognition,pages 7008–7024,2017.6,7,8.
[14]Wenhao Jiang,Lin Ma,Yu-Gang Jiang,Wei Liu,and TongZhang.Recurrent fusion network for image captioning.In Proceedings of theEuropean Conference on Computer Vision(ECCV),pages 499–515,2018.1,7,8.
[15]Ting Yao,Yingwei Pan,Yehao Li,and Tao Mei.Exploring visualrelationship for image captioning.In Proceedings ofthe European conference oncomputer vision(ECCV),pages 684–699,2018.7,8.
[16]Xu Yang,Kaihua Tang,Hanwang Zhang,and Jianfei Cai.Auto-encodingscene graphs for image captioning.In Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,pages 10685–10694,2019.1,7,8.
发明内容
本发明的目的在于提供一种基于自适应注意力机制的图像描述生成方法。针对之前的基于transformer结构的图像描述模型存在的视觉特征空间信息损失问题以及不能区分视觉词和非视觉词的缺陷,一方面构建网格增强模,将网格与网格之间的相对几何关系作为特征的空间信息引入到网格特征中用以弥补空间信息的损失,另一方面,构建一个自适应注意力模型,在预测每个词前,充分度量视觉信息和语言信息的贡献,最终生成更加准确和更有区分度的图像描述。
本发明包括以下步骤:
1)给定一张图片,使用ResNext101作为特征提取器提取特征,并且将与Faster-RCNN提取区域特征完全相同结构的网格特征作为这张图片的特征表示;
2)根据网格特征的尺寸构造一个二维坐标系,对坐标系做归一化处理得到每个网格的相对位置;
3)根据网格的相对位置计算出网格与网格之间的相对几何关系特征,用来作为网格特征的空间信息表示;
4)将网格特征展平,送入到transformer的编码器结构中,并用网格与网格之间的相对几何关系特征来弥补特征展平操作造成的空间信息损失;
5)将已经生成的序列(初始为一个开始字符)送入到一个预训练的语言模型,提取生成序列的语言信息表示;
6)在transformer的解码器结构上方,使用一个注意力模型度量视觉信息和语言信息对当前词预测的贡献,以便有区分地生成视觉词和非视觉词;
7)用visualness指标对单词的视觉化程度进行量化。
在步骤1)中,所述与Faster-RCNN提取区域特征完全相同结构的网格特征,直接提取网格特征,不需要生成候选区域,以提高特征提取速度。
在步骤2)中,所述二维坐标系构造完成后,每个网格的位置由其左上角和右下角的坐标唯一确定。
在步骤3)中,所述网格与网格之间的相对几何关系特征包括每个网格的相对中心位置、相对长度和宽度等。
在步骤5)中,所述提取生成序列的语言信息表示,首先预训练一个基于BERT的语言模型,固定其参数,然后用该语言模型提取已生成的序列的语言信息。
在步骤6)中,所述transformer的解码器结构上方,可构建一个自适应注意力模块,基于transformer解码器输出的隐含状态,度量视觉信息和语言信息对当前词预测的贡献,有区分地生成视觉词和非视觉词。
在步骤7)中,所述用visualness指标对单词的视觉化程度进行量化,基于自适应注意力模块的输出。
本发明的突出优点如下:
(1)本发明提出一个网格增强模块作为经过展平操作的网格特征的一个扩展,通过集成提取自给定图像的原始视觉特征的空间几何信息来弥补网格特征空间信息的损失,生成更加准确的注意力图谱,提升图像描述模型的性能。
(2)本发明提出一个自适应注意力模块,在预测每个单词之前,充分度量视觉信息和语言信息对当前预测的贡献,促进生成更有区分度,更加细粒度的图像描述。
(3)本发明提出一个量化词典中每个词视觉性的指标visualness,并基于这个量化指标挑选出测试集中高视觉性的图片和低视觉性的图片。
(4)本发明把网格增强模块和自适应注意力模型应用到原始的transformer结构上构建图像描述模型RSTNet,在基准数据集的线上和线下测试中均取得最先进的性能。
附图说明
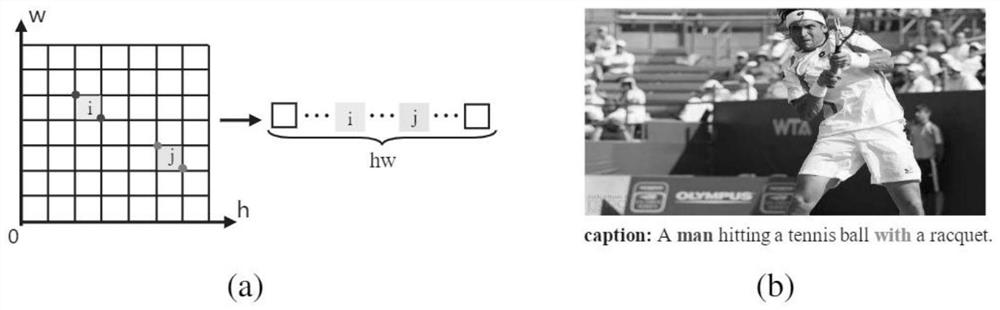
图1是本发明所需解决的问题展示。(a)表示视觉特征的空间信息损失,(b)表示图像描述中既有视觉词又有非视觉词的例子。
图2是本发明构建的基于transformer结构的图像描述模型RSTNet的总体结构图。
图3是本发明构建的用于提取序列语言信息的语言模型结构图。
图4是本发明构建的用于度量视觉信息和语言信息贡献的自适应注意力模块的结构图。
图5是基于本发明中提出单词视觉程度量化指标visualness在Karpathy划分的MS-COCO测试集中挑选出的代表性图片。
图6是本发明提出的RSTNet和原始transformer结构生成图像描述的对比。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
本发明的目的是针对之前的基于transformer结构的图像描述模型存在的两个缺陷:视觉特征展平造成的空间信息损失和不能区分视觉词和非视觉词,提出引入相对空间几何关系的网格增强模块和度量视觉信息和语言信息贡献的自适应注意力模块,生成更加准确,更有区分度的图像描述,极大生成图像描述模型的性能。
本发明实施例基于自适应注意力机制的图像描述生成方法包括以下步骤:
1)给定一张图片,使用ResNext101作为特征提取器提取特征,并且将与Faster-RCNN提取区域特征完全相同结构的网格特征作为这张图片的特征表示。在与Faster-RCNN完全相同的结构中,直接提取网格特征,不需要生成候选区域,能显著提高特征提取速度。
2)根据网格特征的尺寸构造一个二维坐标系,对坐标系做归一化处理便可以得到每个网格的相对位置。二维相对位置坐标系构建完成以后,每个网格的位置由其左上角和右下角的坐标唯一确定。
3)根据网格的相对位置计算出网格与网格之间的相对几何关系特征,用来作为网格特征的空间信息表示。所述相对几何关系特征包括每个网格的相对中心位置,相对长度和宽度,
4)将网格特征展平,送入到transformer的编码器结构中,并用网格与网格之间的相对几何关系特征来弥补特征展平操作造成的空间信息损失。网格特征和网格之间的相对几何关系一起参与到transformer中注意力的计算,用于生成更加准确的注意力图谱。
5)将已经生成的序列(初始为一个开始字符)送入到一个预训练的语言模型,提取生成序列的语言信息表示。首先预训练一个基于BERT的语言模型,固定其参数,然后用这个语言模型提取已生成的序列的语言信息。
6)在transformer的解码器上方,构建一个自适应注意力模块,基于transformer解码器输出的隐含状态,度量视觉信息和语言信息对当前词预测的贡献,有区分地生成视觉词和非视觉词。
7)基于自适应注意力模块的输出,提出量化单词的可视化程度的指标visualness,用visualness指标对单词的视觉化程度进行量化。
基于上述基于自适应注意力机制的描述方法,本发明提供一种图像描述生成模型,图2是本发明构建的基于transformer结构的图像描述模型RSTNet的总体结构图,所述图像描述生成模型依次包括网格增强模块、语言特征表示模块、自适应注意力模块和视觉化程度指标四个部分。
1、网格增强模块
这一部分主要包含步骤1)~4)。首先,在一个与Faster-RCNN完全相同的结构中提取网格特征,这个特征提取过程以ResNext101作为特征提取器。然后,根据网格特征的尺寸构建一个如图1(a)所示的二维坐标系,并确定每个网格的左上角坐标和右下角坐标,比如第i个网格的左上角坐标为
其中,是第i个网格的左上角坐标,是第i个网格的。
然后基于网格的相对中心位置,相对宽度和相对高度,计算出两两网格之间的相对空间几何关系r
为了应用网格之间的相对几何关系r
G
其中,公式(5)中的FC一个神经网络全连接层,将相对空间几何关系转化为相对空间几何特征。公式(6)中
其中Q,K,V是transformer编码器的注意力模块中的查询,键和值,d
2、语言特征表示模块
这一部分主要包含步骤5),首先,基于目前自然语言处理领域最受欢迎的BERT模型构建一个语言模型,用于获取单词序列的语言信息,如公式(8)所示。在做序列中每个单词的预测时,只知道已经生成的单词序列的信息,因此在BERT模型的上方添加一个遮蔽自注意力模块,如公式(9)所示。然后,使用MS-COCO训练集中的图像描述序列通过优化交叉熵的方式训练发明中的语言模型,如公式(10)所示。最后,使用遮蔽自注意力模块的输出作为语言信息的表示,如公式(11)所示。
lf=BERT(W),
(8)S=MaskedAttentionModule(FF1(lf)+pos), (9)
其中,BERT是预训练的语言模型,MaskedAttentionModule是遮蔽子注意力模块,BBLM是本专利中使用的基于BERT的语言模型,其结构是BERT上方添加MaskedAttentionModule,log_softmax是一个神经网络激活函数,W是单词序列,lf表示单词序列对应的语言特征,FF1和FF2为两个线性变换层,pos为序列中单词的位置信息,S为遮蔽自注意力模块输出的序列特征,s
3、自适应注意力模块
这一部分主要包含步骤6),之前基于transformer结构的图像描述模型都是直接使用解码器输出的单词的隐含状态来做单词预测,隐含状态的计算过程如公式(12)所示:
h
而本发明在transformer的解码器上方构建一个自适应注意力模型,如图4所示,使得模型在做单词预测前,再思考一次,度量视觉信息和语言信息对当前单词预测的贡献,以便动态地生成视觉词或者非视觉词。本发明的自适应注意力模块是一个多头注意力模块,其输入有三个:transformer编码器输出的视觉特征U,语言模型输出的语言信息w
head
att=Concate(head
其中,
4、视觉化程度指标部分
这一部分主要包含步骤7),本发明基于自适应注意力模块输出的视觉信息和语言信息的权重,提出visualness量化每个单词的视觉化程度,计算过程如下:
γ
其中,α
具体实验结果如下:为验证提出的模型的可行性和先进性,本发明在图像描述的基准数据集MS-COCO上对提出的模型进行评估。为证明本发明提出的方法具有通用性,实验分别在ResNext101和ResNext152两种特征提取器提取的特征下进行。
本发明中不同模块的分解实验如表1和表2所示,可以看到本发明提出的两个模块均能有效提高图像描述的性能,融合两个模块可以带来更大的性能提升。
表1本发明中不同模块在ResNext101特征上的分解实验
表2本发明中不同模块在ResNext152特征上的分解实验
本发明中的RSTNet与其他最先进方法在线下测试的对比实验如表3所示。
本发明中的RSTNet与其他最先进方法在同一特征下的对比实验如表4所示。本发明中的RSTNet与其他最先进方法在线上测试的对比实验如表5所示。
图5和图6展示定性分析的结果。
表3本发明方法与其他先进方法线下测试的比较
表4本发明方法与其他先进方法在ResNext101特征下的比较
表5本发明方法与其他先进方法线上测试的比较
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 基于自适应注意力机制的图像描述生成方法
- 一种基于深度注意力机制的图像描述生成方法