一种层级孪生网络的实时目标跟踪方法
文献发布时间:2023-06-19 18:27:32
技术领域
本发明涉及计算机视觉技术领域,具体涉及一种层级孪生网络的实时目标跟踪方法。
背景技术
目标跟踪作为计算机视觉领域中基础且具有挑战性的研究课题之一,在视频监控、自动驾驶、人机交互以及医疗诊断等领域有着广泛的应用。目标跟踪是指,给定视频序列中目标的初始位置,在后续帧中能够准确预测目标的位置和大小等关键信息。随着深度学习的发展,研究人员逐渐将其应用到目标跟踪方法中。一种方式是将预训练的深度网络特征应用到传统的相关滤波跟踪器中,但在提升跟踪准确率的同时往往会降低跟踪速度,导致无法实现实时跟踪。另一种是孪生网络跟踪方法,由于其平衡了准确率和速度,逐渐成为一个主流的研究方向,其成果在科研领域和应用中发挥了越来越重要的作用。
虽然基于孪生网络的跟踪方法取得了长足的发展,但面对相似干扰、快速运动和遮挡等复杂场景时仍然可能跟踪失败:首先,现有方法往往使用最后一层卷积特征进行目标的特征表示,深层特征具有较丰富的语义特性但没有充分探索低层特征的空间特性,有些方法虽然使用多层特征进行特征表示,但单独使用不同层特征以及采用插值等融合方式可能导致不同层级的特征信息丢失,未能充分利用较深网络结构中多级特征的特性以获得较强的特征表示能力;其次,在位置预测过程中现有方法通常使用目标和真实值之间的交并比损失来进行位置回归,此类方法往往依赖于较高的交并比但难以处理与目标重叠较小或不重叠的困难样本学习问题。因此,如何设计一种能够充分利用深度网络的多级特征以提高目标特征表示以及提高模型准确定位能力的目标跟踪方法是亟待解决的问题。
发明内容
针对上述现有技术的不足,本发明提供一种层级孪生网络的实时目标跟踪方法。该方法提出融合多级层次特征的金字塔特征融合模块,在保持高层特征语义特性的同时通过自顶向下的结构引入相同分辨率的浅层特征并平滑融合后的特征,可以减轻由于单独使用不同层特征或者简单插值融合导致的特征信息丢失问题;提出位置感知的预测模块,该模块从高层特征级联到低层特征并利用位置感知损失进行困难样本学习。通过训练优化充分挖掘孪生网络在跟踪中的潜力,提升模型性能并提高跟踪的准确性和鲁棒性。
本发明是通过如下技术方案实现的:一种层级孪生网络的实时目标跟踪方法,其特征在于:包括以下步骤:
S1:将视频帧序列的模板图像和搜索图像利用孪生子网络进行特征提取;
在视频序列的初始帧中以目标物体为中心裁剪出模板帧图像z,并在当前帧中裁剪出搜索帧图像x,将模板帧图像和搜索帧图像分别送入到孪生子网络中的模板分支和搜索分支进行特征提取;
S2:构建融合多级层次特征的金字塔特征融合模块
利用步骤1中的孪生子网络,提取卷积三、四和五层的特征用于金字塔特征融合模块,从而构建了拥有不同层次信息的特征金字塔,三四五层卷积特征首先使用1×1的卷积操作降低通道数,得到处理后的特征φ
S3:构建层级位置感知预测模块
位置感知预测模块包括多个位置感知预测头,每个位置感知预测头包括两个子任务,一个是将目标从背景中分类出来的分类分支,另一个是提供目标框回归的回归分支;
对于单个位置感知预测头,将步骤S2中由金字塔特征融合模块获得的搜索图像x和模板图像z的三四五层融合特征Φ
由于单级预测头在面对相似干扰或者较大目标变化时可能导致跟踪性能退化,因此使用多级预测头构成位置感知预测模块以依次细化目标位置和变化,由此可得到位置感知预测模块的分类分支和回归分支的特征图,
S4:模型训练与在线跟踪
在模型训练中,使用大型数据集进行端到端训练,集中裁剪模板图像和搜索图像训练对,以训练层级孪生网络,训练时采用随机梯度下降方法优化网络参数,并逐渐减少所提的层级孪生网络的整体损失,直到模型的性能不再提升;
在在线跟踪中,给定待跟踪的视频序列,按照步骤1的方式获取模板帧图像并通过孪生子网络提取模板特征,在随后的序列帧中,根据前一帧的跟踪结果提取搜索帧特征,获取到模板帧和搜索帧图像特征后送入到金字塔特征融合模块分别获得融合后的低层、中层和高层特征,将获取到的融合特征分别对应输入到层级位置感知预测模块的三个位置感知预测头中,得到三个分类特征图和三个回归特征图;将三个分类特征图和三个回归特征图分别进行加权融合,得到融合后的分类结果和回归结果,由此得到当前帧的目标预测框,选择得分最高的预测框作为当前帧的预测结果。
进一步地,所述步骤S1中,模板帧图像z大小为127×127×3,搜索帧图像x大小为255×255×3。
进一步地,所述步骤S1中,孪生子网络以改进后的ResNet-50作为骨干网络,ResNet-50改进方式为:卷积四层和卷积五层的步长设置为1以增加特征图的空间大小并保留更多的细节信息,同时分别使用2和4的扩张率以增加感受野,由此基于孪生子网络分别得到模板帧和搜索帧的第i个卷积层特征
进一步地,所述步骤S2中,卷积四层其融合后的特征计算公式为:
进一步地,所述步骤S3中,在生成的分类特征图中,每个点代表正负样本的置信度;在生成的回归特征图中,每个点代表预测值与真实标注边界框的偏移值,根据偏移值计算预测值A和真实标注B的交并比(IoU),根据交并比则回归损失函数定义为
进一步地,所述步骤S3中,对于单个预测头,其损失函数表示为L=λ
进一步地,所述步骤S4中,大型数据集包括COCO、ImageNet DET和ImageNet VID。
进一步地,所述步骤S4中,采用随机梯度下降方法优化网络参数,并逐渐减少所提的层级孪生网络的整体损失的具体方式包括:训练时采用随机梯度下降方法优化网络参数并一共进行20次迭代,每次以批量28进行计算和估计,在前5次迭代中,使用的学习率从0.001增加到0.005;在后15次迭代中,学习率从0.005衰减到0.0005,这样逐渐减少所提的层级孪生网络的整体损失,直到模型的性能不再提升。
进一步地,所述步骤S4中,得到融合后的分类结果和回归结果,分类结果代表每一个位置上的分类得分,回归结果代表预测到的目标框描述,选择分类得分最大值对应的回归位置即为当前帧的目标预测框。
本发明的有益效果在于:
发明提供了一种层级孪生网络的实时目标跟踪方法,该方法通过级联架构可以有效地利用多层级特征并进行困难样本学习以实现准确定位,能够很好地适应相似背景干扰、快速运动和遮挡等复杂情况。特别地,本发明的金字塔特征融合模块实现了多级特征融合,在保持高层语音信息的同时以自顶向下的方式融合相同分辨率的低层特征且平滑融合后的特征,保证了不同层级特征的有效融合;且由于其结构简单,没有造成大的计算损失而保持了实时的跟踪速度。同时,本发明利用位置感知预测模块可以进行困难样本的学习,进一步提高了跟踪的定位准确性。
附图说明
下面结合附图对本发明作进一步的说明。
图1为本发明整体网络架构图;
图2为本发明金字塔特征融合模块架构图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
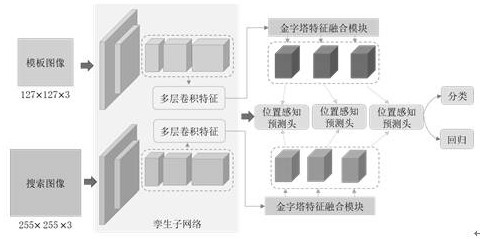
本发明提供了一种层级孪生网络实时跟踪方法,其整体网络架构如图1所示,一共包含三个部分:孪生子网络(Siamese subnetwork),金字塔特征融合模块(Pyramidfeature fusion module)和位置感知预测模块(Location-aware prediction module)。孪生子网络主要负责提取模板帧和搜索帧的浅层和深层特征;金字塔特征融合模块主要负责融合多层次特征以获得判别性目标表示;位置感知预测模块负责级联每个位置感知预测头以依次细化目标位置和目标变化,并引入位置感知损失实现对困难样本的学习,保证目标跟踪的定位准确性。下面结合附图和具体实施方式对本发明作进一步详细说明。
一、将视频帧序列的模板图像和搜索图像利用孪生子网络(Siamese subnetwork)进行特征提取;
在视频序列的初始帧中以目标物体为中心裁剪出127×127×3的模板帧图像z,并在当前帧中裁剪出255×255×3的搜索帧图像x。孪生子网络包含模板分支和搜索分支,两个分支具有相同的网络结构且共享相同的参数,模板帧图像和搜索帧图像分别送入到模板分支和搜索分支进行特征提取,并在后面的跟踪任务中被送到共同的嵌入空间(Embeddingspace)中进行相似性学习(Similarity learning)。
本实施例,孪生子网络以改进后的ResNet-50作为骨干网络(Backbone network),为了使ResNet-50适用于本发明提出的层级孪生网络跟踪方法,本实施例减少了步长(Stride)以获得更高的空间分辨率(Spatial resolution)并采用扩张卷积(Dilatedconvolutions)增加感受野,由此基于孪生子网络可以分别得到模板帧和搜索帧的不同卷积层特征。具体操作如下:
卷积四层和卷积五层的步长(stride)设置为1以增加特征图的空间大小并保留更多的细节信息,同时分别使用2和4的扩张率(Dilation rate)以增加感受野。由此基于孪生子网络可以分别得到模板帧和搜索帧的第i个卷积层特征
二、构建融合多级层次特征的金字塔特征融合模块(Pyramid feature fusionmodule)
利用步骤1中的孪生子网络,提取卷积三、四和五层的特征用于金字塔特征融合模块,从而构建了拥有不同层次信息的特征金字塔,从这些特征图中可以得到层次表示。
这三层特征利用孪生子网络的扩张卷积等操作获得了相同的空间分辨率,但根据感受野的不同可以捕获不同的深浅层信息。在保留高层特征语义信息的同时,金字塔特征融合模块引入具有相同分辨率的低层信息,并对融合后的特征进行平滑处理,借此缓解由于简单的插值融合策略或者单独使用不同层特征带来的不同层级之间的信息鸿沟。
金字塔特征融合模块如图2所示。三四五层卷积特征首先使用1×1的卷积操作降低通道数,得到处理后的特征φ
以卷积四层为例,其融合后的特征计算公式为:
该金字塔特征融合模块结构简单,不会造成大的计算负担,因此可以保证跟踪的实时性。由此,通过逐级融合多级层次特征的金字塔特征融合模块,可分别得到卷积三四五层的融合特征图。
三、构建层级位置感知预测模块(Cascaded location-aware predictionmodule)
位置感知预测模块包括多个位置感知预测头(Location-aware predictionhead),每个位置感知预测头包括两个子任务,一个是将目标从背景中分类出来的分类(Classification)分支,另一个是提供目标框回归的回归(Regression)分支。
对于单个位置感知预测头,本发明将步骤2中由金字塔特征融合模块获得的搜索图像x和模板图像z的三四五层融合特征Φ
由于单级预测头在面对相似干扰或者较大目标变化时可能导致跟踪性能退化,因此使用多级预测头构成位置感知预测模块以依次细化目标位置和变化,由此可得到位置感知预测模块的分类分支和回归分支的特征图,
在生成的分类特征图中,每个点代表正负样本的置信度(Confidence score);在生成的回归特征图中,每个点代表预测值与真实标注(Ground-truth)边界框(Boundingbox)的偏移值(Offset values),根据偏移值可以计算预测值A和真实标注B的交并比(Intersection of union,IoU)。根据交并比则回归损失函数定义为
层级位置感知预测模块通过级联多个预测头以利用金字塔特征融合模块中获得的多层特征,第一阶段直接利用孪生子网络的最后一层特征,第s阶段接收某一层和高层的融合特征,以此类推。由此层级孪生网络的整体损失函数为L=λ
四、模型训练与在线跟踪
在模型训练中,本发明使用提供高质量标注的大型数据集COCO、ImageNet DET和ImageNet VID大规模数据集进行端到端训练。在这些视频数据集的视频帧图像进入本发明的网络训练之前需要进行裁剪,以得到127×127的模板帧图像大小和255×255的搜索帧图像大小。训练时采用随机梯度下降(Stochastic gradient descent)方法优化网络参数并一共进行20次迭代,每次以批量28进行计算和估计。在前5次迭代中,本发明使用的学习率从0.001增加到0.005;在后15次迭代中,学习率从0.005衰减到0.0005,这样逐渐减少所提的层级孪生网络的整体损失,直到模型的性能不再提升。
在在线跟踪中,给定待跟踪的视频序列,通过优化好的层级孪生网络进行自动跟踪获得跟踪结果。将给定视频序列的第一帧目标区域作为模板帧图像,并将后续视频帧序列图像作为搜索帧图像送入到权重共享的孪生子网络中进行多层特征提取。获取到模板帧和搜索帧图像特征后送入到金字塔特征融合模块分别获得融合后的低层、中层和高层特征。将获取到的融合特征分别对应输入到层级位置感知预测模块的三个位置感知预测头中,得到三个分类特征图和三个回归特征图;将三个分类特征图和三个回归特征图分别进行加权融合,得到融合后的分类结果和回归结果,分类结果代表每一个位置上的分类得分,回归结果代表预测到的目标框描述,选择分类得分最大值对应的回归位置即为当前帧的目标结果。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于孪生卷积网络和长短期记忆网络的实时视觉目标跟踪方法
- 基于孪生网络的深层特征聚合的实时视觉目标跟踪方法