新型耦合共享的高光谱与LiDAR数据协同分类方法
文献发布时间:2023-06-19 18:58:26
技术领域
本发明新型耦合共享的高光谱与LiDAR数据协同分类方法属于图像分类技术领域。
背景技术
随着对地观测技术的飞速发展,目前已经实现了对地球表面进行多谱段、多角度、多尺度、多时相的立体观测。其中,高光谱(Hyperspectral Image,HSI)和激光雷达(LightDetection and Ranging,LiDAR)遥感技术是获取地表信息的重要方式。
高光谱遥感是一种被动遥感技术,高光谱影像是一个三维的立体数据,它由一个二维的空间维度和一个垂直于空间维度的光谱维度构成,能探测目标的二维几何空间与一维光谱信息,获取高光谱分辨率的连续、窄波段的数据图像,蕴含丰富的空间、辐射和光谱三重信息。高光谱图像由于其高光谱分辨率和多光谱波段的特点,能够极大程度获取地物的光谱和纹理信息。因此,依据这些特性选择合适的波段进行组合,能够有效抑制“同物异谱、同谱异物”现象,为地物分类研究提供可强有力的保障。但是,高光谱遥感影像由于缺少高程信息,难以完成复杂场景下的高精度地物分类。LiDAR是一种高效的主动遥感技术,它可以准确测量到目标物体的距离,从而生成目标物体三维点云信息。然而,受到激光光源的限制,传统的LiDAR传感器通常仅以单一波长工作,它们可以提供空间信息,但是不具备丰富的光谱信息,与能够实现数百个光谱通道的被动高光谱传感器相比,单波长LiDAR的光谱信息受到了明显的限制。
基于高光谱遥感图像和LiDAR数据的上述特点,在遥感数据智能分析中,将这两种数据进行协同、特征融合能够最大限度地发挥各自的特点,实现更高精度的分类与识别。近年来,涌现了非常多的基于高光谱图像和LiDAR数据协同的工作,并成功地应用于复杂场景地物分类、植被覆盖分析、树种分类、生物量估算、冰川地貌分析等任务,取得了较好的效果。通过整合多源遥感的个体异质性与数据多样性,提升场景观测与分类的精度,成为了当前研究的新趋势。
发明内容
本发明的目的是这样实现的:
步骤a、使用主成分分析方法去除高光谱图像光谱冗余,然后送入空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块提取多分辨率特征;
步骤b、将LiDAR数据输入到另一支路的ASPP模块,提取多分辨率特征;
步骤c、将高光谱和LiDAR两支路的多分辨率特征分别输入各支路的三个可分离卷积模块中,其中两支路之间第二个和第三个的可分离卷积模块进行参数共享;
步骤d、将高光谱和LiDAR数据两支路的特征分别输入各支路的多头自注意力中来提取更加有效的信息;
步骤e、将MHSA加权后的高光谱和LiDAR特征进行融合,并使用softmax进行分类。
上述的一种新型耦合共享的高光谱与LiDAR数据协同分类方法,步骤a具体包括以下步骤:
步骤a1、使用主成分分析方法去除高光谱图像的光谱冗余;
步骤a2、首先将去除冗余的高光谱图像输入空洞空间金字塔中,即输入到1×1卷积,池化金字塔(三个3×3空洞卷积)和空洞池化层(池化、1×1卷积、上采样操作);
步骤a3、将获得的五个特征图进行合并,并使用1×1卷积进一步提取特征,上采样操作将特征图恢复为原图大小。
上述的一种新型耦合共享的高光谱与LiDAR数据协同分类方法,步骤c具体包括以下步骤:
步骤c1、将高光谱与LiDAR两支路ASPP的输出送入各支路的第一个可分离卷积模块中;
步骤c2、将第一个可分离卷积模块输出的特征再次送入到第二个和第三个可分离卷积模块中;
步骤c3、将高光谱与LiDAR支路之间的第二个与第三个可分离卷积模块进行参数共享。
上述的一种新型耦合共享的高光谱与LiDAR数据协同分类方法,步骤d具体包括以下步骤:
步骤d1、首先按照每一时序的向量长度等分成h份;
步骤d2、然后将上面等分后的h份数据分别通过不同的权重
步骤d3、将上述映射后的h份数据计算相应的Attention的值;
步骤d4、按照之前分割的形式重新拼接,再映射到原来的向量维度,就得到了多头自注意力机制的值。
上述的一种新型耦合共享的高光谱与LiDAR数据协同分类方法,步骤e具体包括以下步骤:
步骤e1、将高光谱和LiDAR特征组合以生成新的特征表示;
步骤e2、将三个特征分别输入到输出层中;
步骤e3、三个输出结果最终通过加权求和方法组合在一起以生成最终结果。
有益效果:
本发明新型耦合共享的高光谱与LiDAR数据协同分类方法依次执行以下步骤:步骤a、使用主成分分析方法去除高光谱图像的光谱冗余,然后送入空洞空间金字塔池化模块提取多分辨率特征;步骤b、将LiDAR数据输入到另一支路的ASPP模块,提取多分辨率特征;步骤c、将高光谱和LiDAR两支路的多分辨率特征分别输入各支路的三个可分离卷积模块中,其中两支路之间第二个和第三个的可分离卷积模块进行参数共享;步骤d、将高光谱和LiDAR数据两支路的特征分别输入各支路的多头自注意力中来提取更加有效的信息;步骤e、将MHSA加权后的高光谱和LiDAR特征进行融合,并使用softmax进行分类。使用空洞空间金字塔池化,可分离卷积共享机制和多头自注意力机制组成特征学习模块,通过数据融合机制进一步增强学习特征的辨别能力,充分利用高光谱与LiDAR数据的上下文信息,得到信息更全面的特征图,提高了分类精度。
附图说明
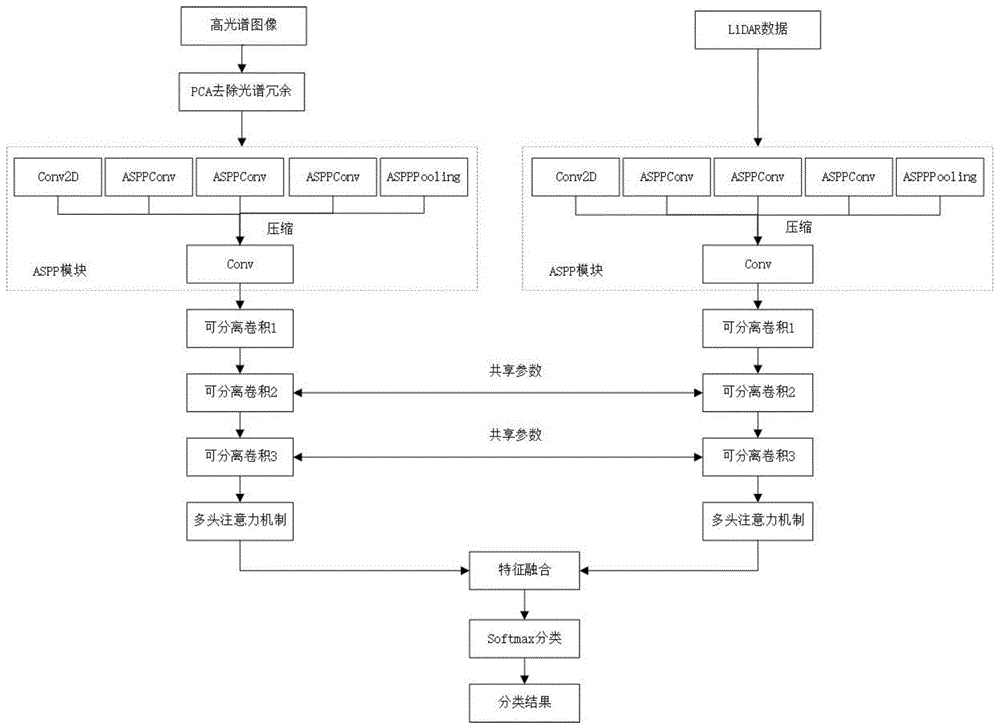
图1是本发明方法中的新型耦合共享的高光谱与LiDAR数据协同分类方法流程图。
图2是本发明方法中的新型耦合共享的高光谱与LiDAR数据协同分类方法原理示意图。
图3是本发明方法中的空洞空间金字塔池化模块的原理示意图。
图4是可分离卷积的计算过程示意图。
图5是本发明方法中的融合模块结构原理示意图。
图6是本发明方法中的多头自注意力结构原理示意图。
图7是本发明方法中的Houston2013数据集中所采用方法的分类结果图。
图8是本发明方法中的Trento数据集中所采用方法的分类结果图。
具体实施方式
下面结合附图对本发明具体实施方式作进一步详细描述。
本具体实施方式下的新型耦合共享的高光谱与LiDAR数据协同分类方法,流程图如图1所示,网络原理示意图如图2所示,包括以下步骤:
步骤a、使用主成分分析方法去除高光谱图像光谱冗余,然后送入ASPP模块提取多分辨率特征。具体为:
在本具体实施方式中,采用2个公开的数据集,分别为Houston2013数据集和Trento数据集。
(1)Houston2013数据集:由地球科学与遥感学会(IEEE GRSS)2013年数据融合竞赛提供,在休斯顿大学校园及周边地区拍摄,包括一组机载高光谱和激光雷达数据覆盖同一区域。高光谱传感器采集的平均高度为5500英尺,激光雷达传感器采集的平均高度为2000英尺。高光谱图像和激光雷达数据大小为349×1905,图像空间分辨率为2.5m。高光谱数据包含144个光谱带,波长范围从380到1050nm。该数据集中共有15种常见的地物。
(2)Trento数据集:Trento数据集是在意大利特伦托市的农村地区获得的。数据集由HSI和基于LiDAR的DSM组成,LiDAR数据由Optech ALTM 3100EA传感器获取,HSI数据由AISAEagle传感器获取,数据大小为600×166像素,由63个波段组成,范围从420.89到989.09nm,光谱分辨率为9.2nm,HSI和基于LiDAR的DSM的空间分辨率均为1m。该数据集中有6个常见的地面对象。
步骤a1、使用主成分分析方法去除高光谱图像光谱冗余。
对于采用主成分分析法,其原理是通过较少的分量来反映原始数据中的大部分特性,将原始数据中相关性较高的分量转换为彼此间不相关的新分量,新分量称之为主成分。对高光谱数据进行去除冗余,将每个波段当作一个向量来处理。
步骤a2、首先将去除冗余的高光谱图像输入空洞空间金字塔中,即输入到1×1卷积,池化金字塔(三个3×3空洞卷积)和空洞池化层(池化、1×1卷积、上采样操作)。
将去除冗余的高光谱图像输入到1×1大小的卷积核、三个空洞卷积和空洞池化层中。池化金字塔由三个3×3大小的空洞卷积核组成,扩张率分别为6、12、18,同时使用1×1大小的卷积核进行卷积处理,然后进行上采样。通过空洞池化层中池化操作先将特征图压缩至1×1以提取全局特征。
步骤a3、将获得的五个特征图进行合并,并使用1×1卷积进一步提取特征,上采样操作将特征图恢复为原图大小。
ASPP在多个采样率和有效视野下使用滤波器探测传入的卷积特征层,这相当于使用具有互补有效视野的多个滤波器探测原始图像,并在多个尺度上捕获对象和图像上下文。然后,进一步融合上述多尺度特征以生成高级语义特征。从而达到兼顾高光谱与LiDAR数据全局信息和局部细节信息的目的。ASPP的结构如图3所示。
空洞卷积可以系统地聚合多尺度上下文信息,而不会损失分辨率。空洞卷积应用于一维或二维信息输入数据x[i]。在滤波w[k]之后,获得输出y[i],如下:
其中,i是像素的位置,r是空洞卷积的扩展速率,k是卷积核的大小。可以设置不同的扩张率来调节感受野的范围。空洞卷积不会填充像素之间的空白像素,而是跳过现有像素上的一些像素,或者保持输入不变,在卷积核的参数中添加一些0的权重,以扩展感受野。
如果空洞卷积的空隙率为r,卷积核的大小为k,则获得的感受野F的大小为:
F=(r-1)(k-1)+k
在金字塔模型中使用具有不同扩展速率的平行空洞卷积层来捕获多尺度信息。对于给定的输入以不同采样率的空洞卷积并行采样,将得到的结果连接到一起,扩大通道数,然后再通过1×1的卷积将通道数降低到预期的数值。相当于以多个尺度捕捉图像的上下文。
步骤b、将LiDAR数据输入到另一支路的ASPP模块,提取多分辨率特征。
步骤c、将高光谱和LiDAR数据两支路的多分辨率特征分别输入各支路的三层可分离卷积中,其中两支路之间第二层和第三层的可分离卷积进行参数共享。具体为:
步骤c1、将高光谱与LiDAR两支路ASPP的输出送入各支路的第一个可分离卷积模块中。
可分离卷积运算是把传统的卷积运算过程分为两步,即逐个通道的卷积和逐个点的1×1大小的卷积运算。首先分析逐通道的卷积运算,对于每一个通道的输入特征,利用一个3×3大小的卷积核进行点乘求和,得到一个高宽均不变的通道输出;然后对于所有的输入通道C
高光谱和LiDAR数据通过ASPP模块后,将高级语义特征输入特征融合模块以学习特征。可分离卷积层之后依次是批量归一化(Batch Normalization,BN)层、校正线性单元(ReLU)、最大池化层。其中批量归一化层用于正则化和加速训练过程,ReLU用于学习非线性表示,最大池化层用于减少数据方差和计算复杂性。
步骤c2、将第一个可分离卷积模块输出的特征再次送入到第二个和第三个可分离卷积模块中。
步骤c3、将高光谱与LiDAR支路之间的第二个与第三个可分离卷积模块进行参数共享。
在第二层可分离卷积层中,两个支路共享参数,通过减少参数的数量来提高模型有效性。对于第三层可分离卷积层,继续使用相同的策略,在此基础上进一步提高了从第二层可分离卷积层学习表示的辨别能力。这两个可分离卷积层之后是BN、ReLU和最大池化算子。所有卷积层都有填充操作符,以使输出大小与输入大小相同。
步骤d、将高光谱和LiDAR数据两支路的特征分别输入各支路的多头自注意力中。具体为:
步骤d1、首先按照每一时序的向量长度等分成h份。
步骤d2、然后将上面等分后的h份数据分别通过不同的权重
步骤d3、将上述映射后的h份数据计算相应的Attention的值。
步骤d4、按照之前分割的形式重新拼接,再映射到原来的向量维度,就得到了多头自注意力机制的值。
多头自注意力机制的结构图如图6所示。首先,我们可以用独立学习得到的h组不同的线性投影来变换Q,K,V。然后,这h组变换后的Q,K,V将并行地送到注意力汇聚中。最后,将这h个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换以产生最终输出。这种设计被称为多头注意力,其中h个注意力汇聚输出中的每一个输出都被称作为一个头。多头自注意力机制在参数量总体不变的情况下,将Q,K,V三个参数进行多次拆分,每组拆分参数映射到高维空间的不同子空间中计算注意力权重,从而关注输入的不同部分。经过并行多次计算,最后合并所有子空间中的注意力信息,该机制可以使模型在不同位置得到不同特征信息,从而增加特征的多样性。
在多头自注意力机制中,本发明采用的是缩放点积注意力。点积操作要求查询和键具有相同长度。假设查询和键都是相互独立的随机变量,且均值为0、方差为1,则这2个向量点积均值为0,方差与键长度一致。缩放式点积注意力机制定义如下:
其中,Q和K是特征维度为d
多头自注意力机制的表达公式如下:
MultiHead(Q,K,V)=Concat(head
其中,h表示总的头数,W
步骤e、将MHSA加权后的高光谱和LiDAR特征进行融合,并使用softmax进行分类。具体为:
步骤e1、将高光谱和LiDAR特征组合以生成新的特征表示。
在提取高光谱和LiDAR的特征表示后,使用基于特征级和决策级融合的新组合策略。由
步骤e2、将三个特征分别输入到输出层中。
步骤e3、三个输出结果最终通过加权求和方法组合在一起以生成最终结果。
所有这些输出层被集成在一起得到最终结果,如下:
O=D[f
其中,
对于特征级融合F,除了广泛使用的级联方法之外,我们还使用求和最大化方法。求和融合旨在计算两种表示的和:
F(R
类似地,最大化融合的目的是执行元素最大化:
F(R
显然,F的性能取决于其输入R
同理,还可以分别导出f
其中,⊙是一个元素乘积运算符,u
为了评估我们提出的方法AMSCNet的分类性能,通过使用其他四个模型进行分类的对比分析,包括Bi-CNN、Coupled-CNN、ASPP-CNN和MHSA-CNN。在每个数据集中,训练样本的数量是样本总数的10%。表1和表2显示了所有方法在Houston2013和Trento数据集的分类实验结果。可以看出,所提出方法获得的OA、AA和Kappa值最好,在Houston2013数据集和Trento数据集上,OA分别达到95.46%和99.08%。以Houston2013数据集为例,与Bi-CNN相比,AMSCNet的OA,AA和Kappa系数分别提高了2.44%、1.68%和2.38%。以Trento数据集为例,AMSCNet与Bi-CNN、Coupled-CNN、ASPP-CNN、MHSA-CNN相比,OA分别提高了8.09%、0.67%、0.65%和0.4%。AA分别提高了7.53%、1.87%、3.81%和2.67%。
表1Houston2013数据集不同分类方法的分类精度比较(%)
表2Trento数据集不同分类方法的分类精度比较(%)
为了更清晰地显示分类结果,图7和图8分别显示了Houston2013数据集和Trento数据集五种方法的分类结果,与其他方法相比,我们提出的方法AMSCNet具有更准确的分类结果。在Houston2013和Trento数据集上,基于深度学习的Bi-CNN、Coupled-CNN、ASPP-CNN和MHSA-CNN分类方法的分类图中存在更多的噪声散点。与真值图相比,可以看出,所提的方法可以获得更准确的分类结果,这进一步证明了所提方法在高光谱和LiDAR数据协同分类中的有效性。
- 高光谱影像和LiDAR数据协同分类方法
- 一种基于双支路的高光谱和LiADR数据协同分类方法