一种获取科学知识发现的方法及系统
文献发布时间:2023-06-19 18:58:26
技术领域
本发明涉及科技情报分析技术领域,尤其涉及一种获取科学知识发现的方法及系统。
背景技术
随着人类社会对“创新驱动发展”的日益重视,全球主要国家对科技研发投入的总额和强度也在不断攀升,这使得科学文献、科研项目与基金的数量也产生了快速膨胀。呈几何级数增长的规模庞大的科学文献给科研人员准确把握特定学科的知识结构、及时追踪相关领域的学术前沿和研究热点带来了全新的挑战。与此同时,这种科研环境为学科发展动态的全方位分析、领域知识的深入挖掘积累了海量优质的科学数据,特别是机器学习、大数据计算等技术的发展也为数据驱动视角下更加智能化、自动化的科学知识发现创造了新的研究条件。
关键词,作为科学文献基本的语义功能单元,通常是文章研究内容和学术观点的高度浓缩。基于关键词的科技情报分析对于理解学科结构,获取科学知识发现具有重要意义。
发明内容
本发明通过提供一种获取科学知识发现的方法及系统,基于对科学文献关键词的词频时间序列的演化趋势分析,获得科学知识发现。
本发明提供了一种获取科学知识发现的方法,包括:
获取科学文献关键词的词频时间序列集合;
将所述词频时间序列集合中的各词频时间序列视为数据点进行形状距离计算来构造无向加权图,得到邻接矩阵A;
将所述邻接矩阵A进行归一化得到图顶点间的相似矩阵W;
将所述相似矩阵W的每一列元素相加,放置在对角线位置上组成对角阵,得到加权度矩阵D;
根据所述相似矩阵W和所述加权度矩阵D得到拉普拉斯矩阵L,并进行特征值分解;
取所述拉普拉斯矩阵L前λ个最小特征值所对应的特征向量组成特征矩阵H;
对所述特征矩阵H进行聚类,得到相应词频时间序列的聚类标签,得到科学知识发现。
具体来说,所述将所述词频时间序列集合中的各词频时间序列视为数据点进行形状距离计算来构造无向加权图,得到邻接矩阵A,包括:
将所述词频时间序列集合中的各词频时间序列数据作为顶点,将所述各词频时间序列间的动态时间规整距离作为边权重构建所述邻接矩阵A。
具体来说,所述根据所述相似矩阵W和所述加权度矩阵D得到拉普拉斯矩阵L,包括:
根据公式
具体来说,所述λ的确定方法如下:
对所述拉普拉斯矩阵L的费德勒向量进行聚类,观察聚类个数k与该聚类误差平方和之间的变化关系,通过肘部法则来确定所述聚类个数k的大致取值范围;
将所述λ设置为k、k-1和k-2共三组值,在保证所选取的特征能够对簇与簇之间的差别进行区分的基础上,选择较小的λ取值。
本发明还提供了一种获取科学知识发现的系统,包括:
词频时间序列获取模块,用于获取科学文献关键词的词频时间序列集合;
邻接矩阵生成模块,用于将所述词频时间序列集合中的各词频时间序列视为数据点进行形状距离计算来构造无向加权图,得到邻接矩阵A;
相似矩阵生成模块,用于将所述邻接矩阵A进行归一化得到图顶点间的相似矩阵W;
加权度矩阵生成模块,用于将所述相似矩阵W的每一列元素相加,放置在对角线位置上组成对角阵,得到加权度矩阵D;
拉普拉斯矩阵生成模块,用于根据所述相似矩阵W和所述加权度矩阵D得到拉普拉斯矩阵L,并进行特征值分解;
特征矩阵生成模块,用于取所述拉普拉斯矩阵L前λ个最小特征值所对应的特征向量组成特征矩阵H;
科学知识发现获取模块,用于对所述特征矩阵H进行聚类,得到相应词频时间序列的聚类标签,得到科学知识发现。
具体来说,所述邻接矩阵生成模块,具体用于将所述词频时间序列集合中的各词频时间序列数据作为顶点,将所述各词频时间序列间的动态时间规整距离作为边权重构建所述邻接矩阵A。
具体来说,所述拉普拉斯矩阵生成模块,具体用于根据公式
具体来说,所述λ的确定方法如下:
对所述拉普拉斯矩阵L的费德勒向量进行聚类,观察聚类个数k与该聚类误差平方和之间的变化关系,通过肘部法则来确定所述聚类个数k的大致取值范围;
将所述λ设置为k、k-1和k-2共三组值,在保证所选取的特征能够对簇与簇之间的差别进行区分的基础上,选择较小的λ取值。
本发明中提供的一个或多个技术方案,至少具有如下技术效果或优点:
本发明基于谱聚类算法提出了一种时间序列趋势识别模型,根据科学文献关键词的词频时间序列在形状上的相似性实现了对关键词词频演化趋势的自动聚类识别。模型将需要进行演化趋势识别的各关键词词频时间序列视作数据点,通过动态时间规整计算它们在形状上的距离来构建无向加权图,将无向加权图的谱划分问题转化为矩阵的特征值分解,并最终通过特征矩阵的构造和聚类过程完成相关时间序列的演化趋势聚类,得到科学知识发现。
与现有技术相比,本发明还具有以下优点:
1、本发明提出的TS-TIM模型在时间序列变化趋势识别任务中具有良好的识别效果,能有效地区分具有相同演化趋势的时间序列数据。除应用于关键词词频相关时间序列的分析中,后续还可应用于引文数、发文数等科技情报领域其他类型时间序列的挖掘与分析。
2、本发明对于TS-TIM模型的实现过程具有科学性。首先,本发明使用动态时间规整算法进行时间序列数据间的形状距离计算,一方面能揭示时间序列数据间的相位畸变和振幅差异,另一方面能支持不同维度的向量间的距离计算,即可完成对不同时间跨度时间序列间的距离计算,增加了模型的鲁棒性;其次,本发明基于拉普拉斯矩阵费德勒向量进行谱聚类参数选择,避免了人为设定的主观性;最后,本发明借助Spark框架实现了模型的分布式计算,提高了识别效率。
3、本发明基于TS-TIM模型对关键词词频时间序列进行了分析,从中识别出了呈突然爆发趋势的新兴词、呈高频波动趋势的标签词、呈波动上升趋势的热点词和呈下降趋势的淡出词。
4、本发明选用对称型的归一化拉普拉斯矩阵进行图的拉普拉斯矩阵表示,防止了由于数据间量纲的不统一而出现分析误差,提高了识别的准确性。
5、本发明将时间因素纳入考量,通过对时间加权的关键词词频时间序列的分析,强化了关键词的上升和下降趋势,为科技情报分析提供了一种新的思路。
附图说明
图1为本发明实施例提供的获取科学知识发现的方法的流程图;
图2为本发明实施例提供的获取科学知识发现的系统的模块图;
图3为本发明实施例中测试数据集中六类时间序列变化趋势的数据样例;
图4为本发明实施例中案例数据集的分布统计;
图5为本发明实施例中词频时间序列呈爆发型变化趋势的部分关键词的词频变化曲线;
图6为本发明实施例中词频时间序列呈上升型变化趋势的部分关键词的词频变化曲线;
图7为本发明实施例中词频时间序列呈高频波动型变化趋势的部分关键词的词频变化曲线;
图8为本发明实施例中词频时间序列呈下降型变化趋势的部分关键词的词频变化曲线;
图9为本发明实施例中关键词时间加权效果图;
图10为本发明实施例中时间加权词频时间序列呈爆发型变化趋势的部分关键词的词频变化曲线;
图11为本发明实施例中时间加权词频时间序列呈上升型变化趋势的部分关键词的词频变化曲线;
图12为本发明实施例中时间加权词频时间序列呈下降型变化趋势的部分关键词的词频变化曲线;
图13为本发明实施例中时间加权词频时间序列呈骤降型变化趋势的部分关键词的词频变化曲线。
具体实施方式
本发明实施例通过提供一种获取科学知识发现的方法及系统,基于对关键词的词频时间序列的趋势分析,获得科学知识发现。
本发明实施例中的技术方案为实现上述技术效果,总体思路如下:
一般而言,关键词词频可以被用于衡量研究主题的热度和活跃度,而其时间趋势更是能够有效地揭示相关主题的发展动态。事实上,在一段时间窗口内的关键词词频变化是一类典型的时间序列,因此,可以借助时间趋势聚类对关键词词频的时序变化趋势进行分析。然后,再通过检测关键词词频时间序列的爆发、增长、骤降、下降等类型的演化趋势便能够对以关键词为表征的学科领域知识结构的变化情况进行揭示,从而获得科学知识发现。
本发明实施例基于谱聚类算法提出了一种时间趋势聚类模型(TS-TIM),并基于流式大数据计算框架Spark进行了该模型的分布式实现。TS-TIM模型以图论中的谱图划分为基础,将需要进行时间趋势识别的各时间序列视作数据点,通过动态时间规整方法计算各时间序列在形状上的距离来构建无向加权图。进一步地,通过构造NCut划分准则所对应的对称型拉普拉斯矩阵,将无向加权图的划分问题转化为矩阵的特征值分解,并最终通过特征矩阵的构造和聚类来完成相关时间序列的趋势聚类。
为了测试模型的有效性,本发明实施例还以Mann-Kendall检验、幂迭代聚类和近邻传播算法为基线,通过加州大学尔湾分校(UCI)中的时间序列数据集验证了模型的有效性,实验结果表明TS-TIM模型能精准地聚类具有相同演化趋势的时间序列。此外,本发明实施例还以LIS学科为例,利用TS-TIM模型对原始词频序列及时间加权词频序列的时间趋势进行分析,表明TS-TIM模型能够有效地完成词频序列的时间趋势聚类,并识别出该学科中突然爆发的新兴词、高频波动的标签词、整体上升的热点词和呈下降趋势的淡出词,本发明实施例对实现智能化、自动化地科学知识发现具有现实意义。
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明。
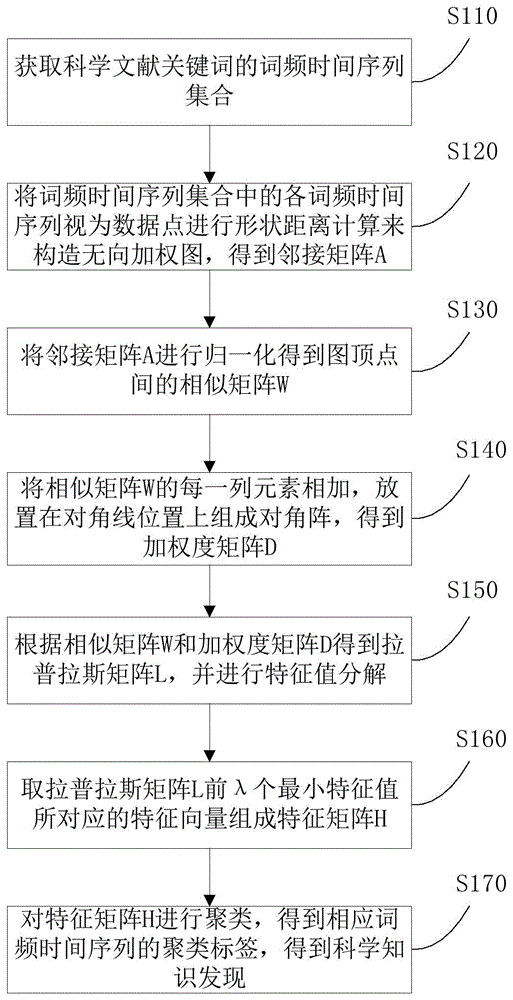
参见图1,本发明实施例提供的获取科学知识发现的方法,包括:
步骤S110:获取科学文献关键词的词频时间序列集合;
步骤S120将词频时间序列集合中的各词频时间序列视为数据点进行形状距离计算来构造无向加权图,得到邻接矩阵A;
对本步骤进行具体说明,将词频时间序列集合中的各词频时间序列视为数据点进行形状距离计算来构造无向加权图,得到邻接矩阵A,包括:
将词频时间序列集合中的各词频时间序列数据作为顶点,将各词频时间序列间的动态时间规整距离作为边权重构建邻接矩阵A。
具体地,对于包含p个数据点的时间序列TS_P和包含q个数据点的时间序列TS_Q来说,其间的动态时间规整距离的计算可按动态规划法求解,如公式(1)所示:
其中,sum(p,q)表示从起始点开始进行动态时间规整后时间序列TS_P的第p个点的时间序列TS_Q的第q个点所取得的距离累加和,Distance(p,q)表示时间序列TS_P的第p个点与时间序列TS_Q的第q个点的距离的模。
步骤S130:将邻接矩阵A进行归一化得到图顶点间的相似矩阵W;
步骤S140:将相似矩阵W的每一列元素相加,放置在对角线位置上组成对角阵,得到加权度矩阵D;
具体地,本发明实施例使用了局部尺度高斯核函数进行归一化,具体如公式(2)所示:
其中,d
步骤S150:根据相似矩阵W和加权度矩阵D得到拉普拉斯矩阵L,并进行特征值分解;
具体地,根据相似矩阵W和加权度矩阵D得到拉普拉斯矩阵L,包括:
根据公式
步骤S160:取拉普拉斯矩阵L前λ个最小特征值所对应的特征向量组成特征矩阵H;
对本步骤进行具体说明,根据本发明实施例确定的归一化拉普拉斯矩阵表示方法,本发明实施例采用NCut划分准则,其目标函数如公式(3)所示:
其中,k表示总共的子集个数,A
本发明实施例基于图拉普拉斯矩阵费德勒(Fiedler)向量的意义和性质,设计了一种新颖的图指示矩阵维度即λ的确定方法。具体地,λ的确定方法如下:
对拉普拉斯矩阵L的费德勒向量进行聚类,观察聚类个数k与该聚类误差平方和之间的变化关系,通过肘部法则来确定聚类个数k的大致取值范围;
将λ设置为k、k-1和k-2共三组值,在保证所选取的特征能够对簇与簇之间的差别进行区分的基础上(即在不同的λ取值下能够明显观察到聚类误差平方和的变化随聚类个数k的增长所出现的肘部特征),选择较小的λ取值,不仅减少了后续计算过程的时间开销和空间开销,而且还避免了使拉普拉斯矩阵L所获得的特征过度拟合。本发明实施例将此λ取值的选取方法称为就低原则。
步骤S170:对特征矩阵H进行聚类,得到相应词频时间序列的聚类标签,每一类的时间序列间有着相似形状的演化趋势,得到科学知识发现。
对本步骤进行具体说明,在完成谱图划分后,利用经典聚类算法对维数为N*λ的指示矩阵(N为原始样本的数量)进行聚类。
在本发明实施例中,基于K-means算法,将指示矩阵的每一行看作当前空间中的一个向量,对它进行聚类分析。指示矩阵聚类结果中每一行所属类别即为最初样本数据点所分别对应的所属类别,从而得到科学知识发现。
参见图2,本发明实施例提供的获取科学知识发现的系统,包括:
词频时间序列获取模块100,用于获取科学文献关键词的词频时间序列集合;
邻接矩阵生成模块200,用于将词频时间序列集合中的各词频时间序列视为数据点进行形状距离计算来构造无向加权图,得到邻接矩阵A;
具体地,邻接矩阵生成模块200,具体用于将词频时间序列集合中的各词频时间序列数据作为顶点,将各词频时间序列间的动态时间规整距离作为边权重构建邻接矩阵A。
具体地,对于包含p个数据点的时间序列TS_P和包含q个数据点的时间序列TS_Q来说,其间的动态时间规整距离的计算可按动态规划法求解,如公式(1)所示:
其中,sum(p,q)表示从起始点开始进行动态时间规整后时间序列TS_P的第p个点的时间序列TS_Q的第q个点所取得的距离累加和,Distance(p,q)表示时间序列TS_P的第p个点与时间序列TS_Q的第q个点的距离的模。
相似矩阵生成模块300,用于将邻接矩阵A进行归一化得到图顶点间的相似矩阵W;
加权度矩阵生成模块400,用于将相似矩阵W的每一列元素相加,放置在对角线位置上组成对角阵,得到加权度矩阵D;
具体地,本发明实施例使用了局部尺度高斯核函数进行归一化,具体如公式(2)所示:
其中,d
拉普拉斯矩阵生成模块500,用于根据相似矩阵W和加权度矩阵D得到拉普拉斯矩阵L,并进行特征值分解;
具体地,拉普拉斯矩阵生成模块500,具体用于根据公式
特征矩阵生成模块600,用于取拉普拉斯矩阵L前λ个最小特征值所对应的特征向量组成特征矩阵H;
具体地,根据本发明实施例确定的归一化拉普拉斯矩阵表示方法,本发明实施例采用NCut划分准则,其目标函数如公式(3)所示:
其中,k表示总共的子集个数,A
本发明实施例基于图拉普拉斯矩阵费德勒(Fiedler)向量的意义和性质,设计了一种新颖的图指示矩阵维度即λ的确定方法。具体地,λ的确定方法如下:
对拉普拉斯矩阵L的费德勒向量进行聚类,观察聚类个数k与该聚类误差平方和之间的变化关系,通过肘部法则来确定聚类个数k的大致取值范围;
将λ设置为k、k-1和k-2共三组值,在保证所选取的特征能够对簇与簇之间的差别进行区分的基础上(即在不同的λ取值下能够明显观察到聚类误差平方和的变化随聚类个数k的增长所出现的肘部特征),选择较小的λ取值,不仅减少了后续计算过程的时间开销和空间开销,而且还避免了使拉普拉斯矩阵L所获得的特征过度拟合。本发明实施例将此λ取值的选取方法称为就低原则。
科学知识发现获取模块700,用于对特征矩阵H进行聚类,得到相应词频时间序列的聚类标签,每一类的时间序列间有着相似形状的演化趋势,得到科学知识发现。
具体地,科学知识发现获取模块700,具体用于基于K-means算法,将指示矩阵的每一行看作当前空间中的一个向量,对它进行聚类分析。指示矩阵聚类结果中每一行所属类别即为最初样本数据点所分别对应的所属类别,从而得到科学知识发现。
下面对本发明实施例的识别准确性进行验证:
本发明实施例选择了加州大学尔湾分校(UCI)知识发现档案库中的时间序列数据集进行模型的测试验证,并以
测试数据集共有600条词频时间序列数据,每一百条代表一类,依次分别被标记为常规(Normal)型、周期(Cyclic)型、上升(Increasing trend)型、下降(Decreasing trend)型、上偏移(Upward shift)型、下偏移(Downward shift)型共六种变化趋势。图3中展示了测试数据集内六类时间序列变化趋势的数据样例。
由于MK检验仅能判断三类时间序列变化趋势,因此,本发明实施例按以下方式将测试数据集进一步地复制合并为三类时间序列变化趋势:第一类,无明显升降趋势,对应测试数据集中常规型和周期型的时间序列样本;第二类,上升趋势,对应测试数据集中上升型和上偏移型的时间序列样本;第三类,下降趋势,对应测试数据集中下降型和下偏移型的时间序列样本。将标记有这三类变化趋势的时间序列样本分别运行各置信度下的MK检验。当置信度为99%、95%、90%时,MK检验的识别结果混淆矩阵以及精确率(Precision)、召回率(Recall)和宏平均值(F
表1MK检验对测试数据集的实验结果(99%置信度)
表2MK检验对测试数据集的实验结果(95%置信度)
表3MK检验对测试数据集的实验结果(90%置信度)
在取得MK检验的基线结果后,基于标记有六类变化趋势的测试数据集,运行并测试了本发明实施例所提出的方法及系统,以及PIC聚类算法和AP聚类算法。由于测试数据集被分为了明确的六类样本,因此,此处将设定聚类个数k=6,并对模型不同λ取值的运行结果进行比较。在模型运行前,均设定模型的最大迭代次数为30次。
本发明实施例在得到聚类算法的结果后,检查各聚类类簇中对应实际的六类标签中哪类的结果最多,从而将该类簇判定为相应的类标签,并进一步地完成全数据集准确率(Accuracy)的计算。TS-TIM模型、PIC模型与AP模型的测试结果如下表4所示。
表4TS-TIM/PIC/AP模型对测试数据集的实验结果(聚类数k=6)
通过对聚类分析的结果进行对比,能够发现:
在本发明实施例中,当选取对称型归一化拉普拉斯矩阵的前5个最小特征值所对应的特征向量(λ=5)构建指示矩阵后相较于其他两种指示向量的维度选择而言,对测试数据集所获得的聚类个数为6个的实验结果表现最为良好,通过与表1至表4的对比,可以看出,就全数据集上的准确识别个数来说(MK检验结果中的全数据集准确个数为其对角线上的数值相加),当λ取5时所准确识别个数为578,仅略低于在95%置信度MK检验中的584个且略高于在90%置信度MK检验中的565个;PIC模型虽相较谱聚类提升了计算速度且实现较为简单,但就测试集的实验结果来看,PIC模型显然不适用于本实施例中对相关时间序列的变化趋势进行自动识别的任务。相比PIC模型而言,AP模型的表现更为良好,其优于λ取4时的TS-TIM模型效果但与λ=5时的结果相比仍有明显差异。
TS-TIM模型(λ=5)在对标记有六个类标签的测试数据集上进行时间序列变化趋势识别的效果,能够与MK检验对三类时间序列变化趋势的识别效果在全数据集准确率上相近。本发明实施例对模型(λ=5)与对应六分类问题中的混淆矩阵进行了统计,来进一步地观察模型的时间序列变化趋势的识别效果,其结果如表5所示。
表5TS-TIM模型对应测试数据集六分类问题的混淆矩阵(λ=5)
通过观察表5,能够进一步地发现,本发明实施例所提出的模型能够有效地针对测试数据集的六类时间序列变化趋势进行区分,仅在对少量时间序列数据在上升与上偏移两类变化趋势,以及下降与下偏移两类变化趋势上出现了与原始类标签所不同的聚类区分。此外,结合表3和表4来分析,通过模型对应六分类问题的宏平均值来看,模型的效果已经接近置信度为95%的MK检验的分类效果,而超越了90%置信度的MK检验。
综合上述对测试数据集的时间序列变化趋势进行识别的实验结果,能够说明:本发明实施例提出的时间序列变化趋势识别模型TS-TIM能够有效地区分具有相同变化趋势的时间序列数据,将形状相似的时间序列进行聚类识别,从而得出科学知识发现。
实施例
1、数据收集与预处理
由于研究团队成员的学科背景,本研究选取信息科学与图书馆学(InformationScience&Library Science,LIS)领域进行案例分析。本研究收集了LIS领域中被社会科学引文索引(Social Sciences Citation Index,SSCI)所收录期刊发表于2011年至2020年的科技论文,论文类型限定为研究论文(Research Article)和文献综述(Review),语种限定为英语,最终得到了包含38932条科技论文的数据集。
本研究基于作者关键词(Author Keywords,AK)进行分析,为解决作者关键词字段的同词不同形、缩略词混用现象,本研究使用python程序进行数据预处理。首先,使用nltk库对关键词字段进行词形还原;再根据关键词中存在的“(”、“)”构建缩略词-原始词映射表,将作者关键词中的常用缩略词转化成原始形式;此外还去除掉关键词中存在的乱码、HTML标签、XML标签等噪声词,数据集的分布情况如图4所示。
2、词频时序变化趋势的识别结果
本发明实施例首先对数据集中所有关键词各年度的词频进行了统计。这里需要说明的是,当词频总数过小时,可能不具备显著的时间序列变化趋势分析价值(即,可以将该类词频总数过小的关键词的词频时间序列认定为具有同一类趋势)。因此,本发明实施例在全时间跨度上的57025个不同的关键词中,筛选了词频总数大于时间跨度的关键词,保留下来的在2011至2020年度共有10篇以上文章涉及的作者关键词共有1952个。
本发明实施例首先对这1952条关键词的词频时间序列进行了时间序列变化趋势的识别。本发明实施例针对关键词词频时间序列之间的DTW距离值所构造的网络矩阵进行特征值分解,选择其费德勒向量进行K-means聚类分析后利用肘部法进行聚类数量选择。结果表明当聚类个数k=5时,误差平方和的变化趋近于平缓。因此,选择特征向量维度λ=3,4,5的三种情况,分别构造对称型归一化拉普拉斯矩阵不同维度下的指示矩阵并进行K-means聚类分析,再进一步根据各自的误差平方和曲线按照本发明实施例中的就低原则,最终选择特征向量的维度λ=3,且聚类个数k=5时的谱聚类结果作为TS-TIM模型的最终结果。
按照TS-TIM模型的时间序列变化趋势识别结果,对各类关键词词频时间序列变化趋势中的词频时间序列进行绘图,以通过可视化的形式直观地观察、总结各聚类中词频时间序列趋势的变化特征。
在关键词词频时间序列变化趋势的识别结果中,第一类变化趋势可以归纳为爆发型趋势。该类词频时间序列变化的明显特点是,在整个时间跨度的前中期关键词都只具有着较低的词频分布,而在靠近后期的3年左右中,其词频变化呈现出了急速上升态势。图5中展示了词频时间序列呈爆发型变化趋势的部分关键词的词频变化曲线,被识别为该类趋势的关键词共有30个。
在关键词的词频时间序列中,被识别出来的第二类变化趋势可以被归纳为上升型趋势。该类词频时间序列在整个时间跨度内的词频变化呈现出波动上升的总体态势,但在整个时间跨度内关键词的词频总数维持在中低位水平。图6中对词频时间序列呈上升型变化趋势的部分关键词的词频变化曲线进行了展示,在该类变化趋势中,共有关键词177个。
在关键词词频时间序列变化趋势的识别结果中,第三类变化趋势可以归纳为高频波动型趋势。该类词频时间序列变化的明显特点是,在整个时间跨度内关键词的词频总数都维持在较高位的水平,同时,随着时间的推移,词频会产生些许波动变化。图7中展示了词频时间序列呈高频波动型变化趋势的部分关键词的词频变化曲线,被识别为该类趋势的关键词共有30个。
在关键词的词频时间序列中,被识别出来的第四类变化趋势可以被归纳为下降型趋势。该类词频时间序列在整个时间跨度内的词频变化呈现出波动下降的总体态势,但它们在整个时间跨度内关键词的词频总数维持在中低位水平。图8中对词频时间序列呈下降型变化趋势的部分关键词的词频变化曲线进行了展示,在该类变化趋势中,共有关键词69个。
从识别结果可以看出,本发明实施例对突然爆发的各类学科领域新兴词具有很好的识别效果,成功地捕获了时间跨度的末期关键词词频的上升信号;在呈上升型变化趋势的关键词词频时间序列中,也较好地识别到了正逐渐受到LIS学者们广泛关注的研究热点词;对于识别到的呈下降型变化趋势的词频时间序列,也较为有效地反映了正从本学科领域学者的关注焦点中逐渐淡出的关键词。具体而言,计量类研究作为LIS学科的研究重点,“Bibliometrics”、“Scientometrics”等关键词一直处在高频波动状态,随着社交媒体发展而逐渐被研究人员关注的“Altmetrics”等也呈现了上升趋势。“Blog”、“Internet”、“Web2.0”等词汇呈现下降趋势,表明随着技术的发展和研究环境的变化,学者们对其的研究兴趣和关注可能被一下更新颖、更热门的研究对象或方法所取代。而“ArtificialIntelligence”、“Deep Learning”、“Blockchain”等新兴技术及“Cloud Computing”、“BigData Analytics”等技术相关主题大多呈现爆发或上升趋势,是近年来LIS学科被广泛关注的新兴趋势或研究热点。
这里需要说明的是,为了减少时间因素对获得科学知识发现准确性的影响,从而进一步提高分析的准确性,本发明实施例还将时间要素纳入考虑,利用TS-TIM模型对时间加权后的关键词词频时间序列进行趋势分析,时间加权的关键词词频计算方法如公式(4)所示:
其中,C
进一步地,本发明实施例基于费德勒向量确定,此时TS-TIM模型的特征向量维度λ=3,聚类个数k=5,即时间加权后的关键词词频时间序列也被划分为5个类别,分别为爆发型、上升型、下降型、骤降型及常规型,各类型包含的关键词数量分别为280、375、395、282和620,各类别关键词变化趋势如图10-13所示。
对于其中词频或时间加权词频具有明显变化趋势的部分关键词,其识别结果对比如表6所示。
表6关键词词频与时间加权词频时间序列变化趋势识别结果对比
由表6可以看出,TS-TIM模型识别出的关键词词频时间序列的变动方向与关键词时间加权词频时间序列是基本一致的,即都表现为上升趋势或下降趋势;同时,一些在关键词词频时间序列表现为波动上升或波动下降的关键词经时间加权后呈现爆发或骤降,如“BigData”、“Internet”等,即表6中标记为2的关键词;此外,时间加权后,一些原始词频时间序列波动不明显从而被识别为无趋势或高频波动型的关键词在加入时间因素的考虑后,其时间加权词频时间序列呈现了明显的上升或下降趋势,如“H-index”、“Social Media”等,即表6中标记为3的关键词。
通过与原始词频时间序列变化趋势识别结果的对比,本发明实施例发现:①原始词频时间序列变化趋势被识别为爆发型的关键词,其时间加权词频时间序列变化趋势也被识别为爆发型;②原始词频时间序列变化趋势被识别为上升型的关键词,其时间加权词频时间序列变化趋势被识别为上升型或爆发型;③原始词频时间序列变化趋势被识别为下降型的关键词,其时间加权词频时间序列变化趋势被识别为下降型或骤降型;④原始词频时间序列变化趋势呈高频波动或无趋势常规型关键词中,有一部分其时间加权词频时间序列变化趋势被识别为爆发及波动上升等上升型或骤降及波动下降等下降型。究其原因,时间加权词频是时间加权系数和相对词频的乘积,时间加权系数会降低出现旧关键词词频权重,而相对词频则会突显绝对词频更高的关键词,因而,一些旧关键词由于出现时间较长,其词频的下降将变得愈加明显因而呈现除了骤降趋势;而一些关键词虽然也出现了一段时间,但整体绝对词频在上升,同时在某些年度其绝对词频特别高则会呈现出爆发趋势。整体来看,两种词频时间序列变化趋势识别结果的对比分析进一步验证了TS-TIM模型对于自动聚类关键词词频时间序列进而挖掘学科领域知识的有效性。
本发明实施例提出了一种基于谱聚类的时间序列变化趋势识别模型TS-TIM,并基于Spark框架实现了模型的分布式计算。为有效地考量时间序列的相位畸变和振幅差异,本发明实施例利用动态时间规整算法对时间序列的变化趋势进行了基于形态的时间序列距离计算并构建无向加权图;考虑到时间序列的形态距离并不完全具备凸形状特征,选择NCut的图划分准则进行谱图划分进而完成时间序列变化趋势聚类,进一步结合趋势规律的综合分析进行学科领域科学知识发现。在广泛实验确定了词频时间序列的多种变化趋势后,可将这些变化趋势进一步固化为模式特征,即将本发明实施例提出的模型转化为时间序列变化趋势分类模型,进而实现对大规模学科领域科技文献中新兴词、热点词、标签词、淡出词等的快速识别,即实现对学科领域知识洞见的智能化、自动化预测。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 一种手机扫码自动获取硬币系统及其获取方法
- 一种植入式控制系统数据获取装置及数据获取方法
- 一种系统信息的发送方法、获取方法及相关设备
- 一种系统信息的获取方法、发送控制方法及相关设备
- 一种业务系统信息获取的方法、系统及设备
- 一种基于预训练语言模型的开放域科学知识发现方法和装置
- 一种集导航、地形获取与地表探测为一体的空间天体科学探测方法