一种融合密度聚类与ERNIE的医疗文本关系抽取方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及关系抽取技术领域,具体涉及一种融合密度聚类与ERNIE的医疗文本关系抽取方法。
背景技术
在构建医疗知识图谱、开展智能诊断、病例智能分析之前,需要对非结构化的医疗文本关系抽取,以识别文本中成对实体的关系,从文本数据中自动获取结构化知识。但是由于医疗文本在构成上具有多样性、复杂性和动态性,对医疗文本关系抽取提出较大挑战。现有技术大多通过预训练模型后连接不同分类器提升关系抽取效果,并未充分使用已标注文本自身携带的先验知识,造成人工标注数据集未得到充分利用这一问题。
发明内容
为解决上述技术问题,本发明提出了一种融合密度聚类与ERNIE的医疗文本关系抽取方法,通过聚类算法提取人工标注语料中的先验知识,解决了人工标注数据集未得到充分利用这一问题,从而提升医疗文本关系抽取效果,使人工标注信息反应更多元的信息,能够降低模型对人工标注数据的依赖,并降低成本。
为了达到上述技术目的,本发明技术方案如下:
一种融合密度聚类与ERNIE的医疗文本关系抽取方法,包括如下步骤:
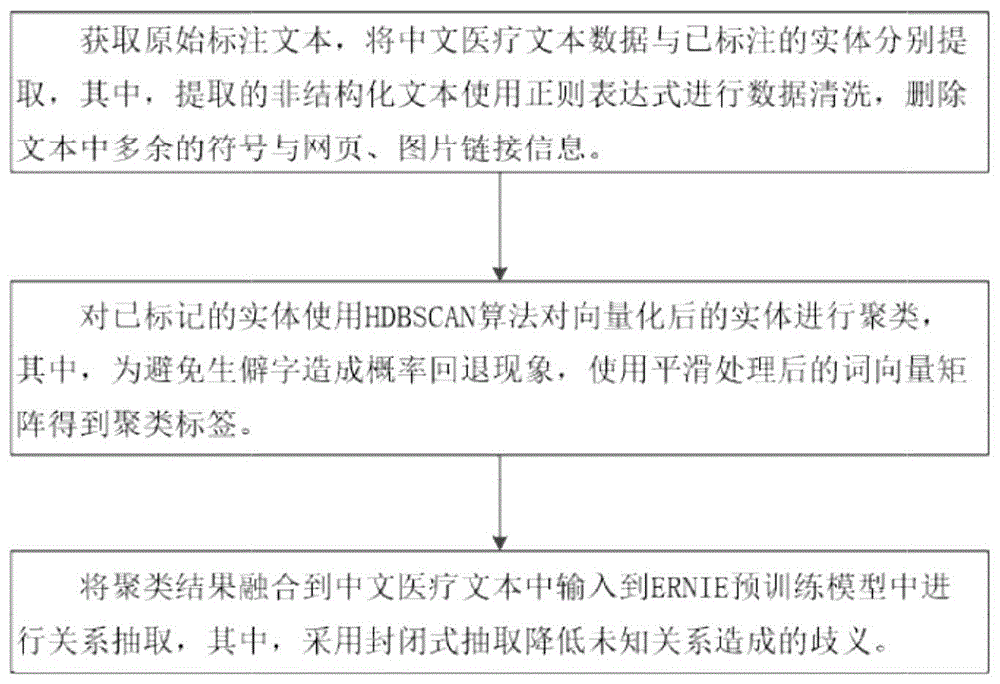
获取原始标注文本,将中文医疗文本数据与已标注的实体分别提取,其中,提取的非结构化文本使用正则表达式进行数据清洗,删除文本中多余的符号与网页、图片链接信息。
对已标记的实体使用HDBSCAN算法对向量化后的实体进行聚类,其中,为避免生僻字造成概率回退现象,使用平滑处理后的词向量矩阵得到聚类标签。
将聚类结果融合到中文医疗文本中输入到ERNIE预训练模型中进行关系抽取,其中,采用封闭式抽取降低未知关系造成的歧义。
优选地,还包括如下步骤:
对实体进行聚类前,剔除重复出现的实体数据;
对头实体与尾实体进行分别聚类;
创建关系数据集,用于关系抽取时确定关系分类数量;
聚类所使用词向量矩阵使用平滑处理后的TFIDF词向量矩阵,关系抽取使用Embedding词向量矩阵。
优选地,所述数据集选取部分飞桨公开的医疗文本数据集进行研究,对上述数据集采用完全随机采样策略进行划分,形成完全不相交的训练集与测试集。
优选地,所述数据集在完全随机采样前,已对其实体进行过聚类处理。
优选地,所述ERNIE医疗文本关系抽取模型损失函数Loss为:
式中:p
优选地,所述融合密度聚类的ERNIE医疗文本关系抽取模型包括聚类层、词嵌入层、自注意力层。
基于上述技术方案,本发明的有益效果是:
1.本发明通过构建融合密度聚类与ERNIE的医疗文本关系抽取方法,将实体进行聚类,使得实体的词频信息得到了强化,将实体加入标签,使得待预测实体的位置信息和有向性特征得到了强化,预训练模型使用具有知识整合模块的ERNIE,使得模型能更好的学习到聚类标签与实体间的联系。
2.本发明从数据集出发,除了运用传统数据清洗方法,引入聚类算法对医疗文本数据集进行处理,以达到删除干扰信息的同时,使数据集携带更多信息的目的。
附图说明
图1是一个实施例中融合密度聚类与ERNIE的医疗文本关系抽取方法流程图:
图2是一个实施例中融合密度聚类与ERNIE的医疗文本关系抽取方法的架构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
如图1所示,本实施例提供一种融合密度聚类与ERNIE的医疗文本关系抽取方法,包括如下步骤:
获取原始标注文本,将中文医疗文本数据与已标注的实体分别提取,其中,提取的非结构化文本使用正则表达式进行数据清洗,删除文本中多余的符号与网页、图片链接信息。
对已标记的实体使用HDBSCAN算法对向量化后的实体进行聚类,其中,为避免生僻字造成概率回退现象,使用平滑处理后的词向量矩阵得到聚类标签。
将聚类结果融合到中文医疗文本中输入到ERNIE预训练模型中进行关系抽取,其中,采用封闭式抽取降低未知关系造成的歧义。
本发明通过构建融合密度聚类与ERNIE的医疗文本关系抽取方法,将实体进行聚类,使得实体的词频信息得到了强化,将实体加入标签,使得待预测实体的位置信息和有向性特征得到了强化,将预训练模型替换为具有知识整合模块的ERNIE,使得模型能更好的学习到聚类标签与实体间的联系。
具体说明如下:
1.构建融合密度聚类的ERNIE医疗文本关系抽取模型
关系抽取任务是一种特殊的文本分类任务,而针对医疗文本数据集具有的多样性、复杂性和动态性的特点,通过融合密度聚类算法对数据集进行预处理,以提高关系抽取模型预训练下游微调任务的效果。在本专利ERNIE预训练模型Fine-tune语料中,将使用密度聚类后的语料,将融合了密度聚类信息的中文医疗文本数据集视为Fine-tune过程中的语料,如图2所示,融合了密度聚类信息的中文医疗文本数据集语料是对原始语料的进一步清洗。以达到删除干扰信息的同时,使数据集携带更多信息的目的。
对于聚类算法处理过后的数据集,标记出的实体具有了聚类信息,用于增强文本中待预测实体的位置信息与先验知识信息。
融合密度聚类的ERNIE医疗文本关系抽取模型由三个部分组成,分别是聚类层、嵌入层、自注意力机制层。
1)聚类层
医疗文本中的实体命名的多样性和关系的动态性干扰了关系的抽取。为让模型学习到三元组的有向性特征,使用特殊符号将待预测实体在文本中标记出,然后使用聚类算法挖掘实体内部语义相似度信息,为文本提供有效先验知识。因此,使用层次密度聚类算法HDBSCAN以找到最佳聚类解决方案。该算法具体分为如下步骤:
创建包含所有点的集合V={x
考虑到医疗文本会出现未登录的生僻字,会在向量化过程中产生回退值为零的情况,所以在对医疗实体进行向量化前进行平滑处理避免该现象的发生,
公式如下:
平滑处理:
式中:df(d,t)表示文本中所有字词的出现次数之和;n
2)词嵌入层
模型认为如果在进行随机遮盖(Mask)时仅对单个字进行遮盖,会使得模型缺少对词内部关系的理解,因此,ERNIE加入了实体和短语掩码机制,通过学习大量的分词模型,短语拼接模型,命名实体识别模型,强化模型的语法学习能力。具体掩码操作如图2所示。图中,通过不同粒度的Mask操作使ERNIE具备学习先验知识的能力。其中基础掩码阶段将句子作为一个基本语言单位的序列,随机遮盖15%的基本语言单元,使用句子中的其他基本单元作为输入,训练一个转换器来进行预测。
短语掩码阶段随机在句子中选择几个短语嵌入到编码中。最后的实体掩码阶段,认为实体在句子中包含重要信息,通过短语掩蔽阶段中的命名实体,Mask并预测实体中的所有插槽。经过三个阶段的学习,ERNIE得到了一个由更丰富的语义信息增强的单词表示。
3)自注意力层
ERNIE引入诸如基于百科类、资讯类、论坛对话类等构造具有上下文关系的句子对,在词嵌入模块使用了对话语言模型(Dialogue Language Model,DLM)提升模型语义表示能力。DLM任务帮助ERNIE学习医疗文本中的内隐关系,以提高模型学习医疗文本数据的语义表征能力。使用ERNIE预训练模型还可以缓解长距离依赖对关系抽取造成的影响,对于每个字符,首先通过ERNIE嵌入层得到a
2.损失函数的定义
所述ERNIE医疗文本关系抽取模型损失函数Loss为:
3.数据集划分
为了让模型能够学习到聚类标签与实体间的关系,且保证聚类的结果不会受聚类的样本数量的影响。首先对整个数据集的实体进行聚类。然后采用完全随机采样策略对数据集进行划分,最终得到训练集/测试集比例为8/2。
4.训练融合密度聚类的ERNIE关系抽取模型
对于已取出的实体,使用HDBSCAN算法对其聚类,其中,为体现三元组的有向性特征,对头尾实体进行分别聚类,并输出聚类结果,便于关系抽取时进行插入操作。
对于已标注的关系,创建关系类型文件,确定所有关系类别与数量,其中,增加一个“UNRELATED”关系代表未发现的关系。
对于待遇测预料,循环取出每一个训练批次的句子,将聚类标签分别插入已标注的实体前,并加入特殊符号强化待遇测实体的位置信息。具体训练过程如下:
步骤1:实体向量化表示
对于得到的实体词,首先转换为平滑处理后的TFIDF向量矩阵,使用HDBSCAN算法进行聚类,得到聚类结果标签。
步骤2:构建关系分类数据集
对于标注语料,将所有关系进行统计后形成关系分类类型,其中,为保证分类的准确性,增加一个“UNRELATED”关系代表未发现的关系。
步骤3:句子语义特征提取
将聚类结果标签融合到待遇测句子与待预测实体中,并插入特殊符号标记出实体在句子中的位置,一起作为最终训练语料输入ERNIE中进行语义特征提取,ERNIE预训练模型经过词嵌入层和自注意力层,作为ERNIE层的最终输出。
步骤4:训练关系抽取模型
将自注意力层输出的特征经过一层向量拼接和一次线性连接,进行softmax操作得到预测的向量。
步骤5:微调关系抽取模型
通过不断迭代,以损失函数变化程度最小为依据,通过调整模型学习率等其他参数对模型进行微调。
步骤6:测试模型
测试模型在已划分好的测试集上的准确率、召回率和F1值大小为依据,测试模型的整体效果。
直至模型损失函数变化程度变化微小、准确率、召回率和F1值稳定,模型训练结束。
以上所述仅为本发明所公开的融合密度聚类与ERNIE的医疗文本关系抽取方法,并非用于限定本说明书实施例的保护范围。凡在本说明书实施例的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本说明书实施例的保护范围之内。
- 基于自监督和聚类技术从文本中抽取实体间关系的方法
- 基于自监督和聚类技术从文本中抽取实体间关系的方法