基于改进WGAN-GP和Alxnet的轴承故障诊断方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及轴承故障诊断技术领域,具体涉及一种基于改进WGAN-GP和Alxnet的轴承故障诊断方法。
背景技术
在工业生产中,旋转机械被广泛地应用于压缩机、风机、汽轮机、涡轮机、发电机、燃气轮机、航空发动机及各种电动机等机械装置中。机械设备的安全运行是工业生产过程中的核心要求。轴承作为机械装置和电力系统中必不可少的零件,其运行状态影响整个设备的安全性与可靠性。而滚动轴承长时间在复杂工况中运行,容易发生剥落、磨损、断裂失效、压痕失效和胶合失效等故障,往往会造成巨大的经济损失和工作人员的损伤。因此有必要对滚动轴承进行可靠的检测和诊断。
随着人工智能技术不断发展,将深度学习应用于轴承故障诊断中的方法越来越多。但是多数研究的应用场景是基于平衡的数据集,考虑到轴承长时间运行在正常状态下,采集高质量的故障状态的样本成本高,难度大。真实场景下正常样本和故障样本往往严重不平衡的情况给故障诊断带来了巨大的障碍。
传统解决数据不平衡的方法可以归类为样本采样和改进诊断模型,样本采样分为下采样和上采样,其中过采样即大量复制少数样本中的数据,进而促使其样本数量和多数样本数量达到平衡,会导致分类器倾向过度拟合。而欠采样技术与过采样相反,即减少多数样本的数量,使其数量和少数样本基本一致,重要信息可能会丢失,从而导致信息空间扭曲与不完整。算法方面,改进诊断模型的方式从诊断模型本身出发,常通过调整分类器敏感度来提高诊断精度,提升的程度往往有限且较难获得最优权重。
上述这些针对数据不平衡提出来的数据增强方法虽然能在固定场合取得不错的效果,但是这些方法并没有对数据的多样性产生质变,且会出现学习能力较弱,诊断精确度达到一定的值很难有较高的提升等问题,因此效果仍有待进一步提升。
发明内容
针对轴承故障诊断中部分故障类别难以获取从而导致的数据集不平衡的情况。本发明提供一种基于改进WGAN-GP和Alxnet的轴承故障诊断方法,该方法基于改进WGAN-GP生成的数据更贴近真实数据,解决了数据不平衡的问题,使得故障诊断网络提取更加有效的特征来获取更好的分类精确度,并且在不同故障类别下均有良好的分类精度。
本发明采取的技术方案为:
基于改进WGAN-GP和Alxnet的轴承故障诊断方法,包括以下步骤:
步骤1:利用振动采集设备获取轴承原始振动信号,使用小波变换,将原始振动信号转换成不同故障类别的时频域信号;
步骤2:将步骤1获取的时频域信号按照8:2分为训练集和测试集,并且构造四个非平衡数据集;
步骤3:构建改进的WGAN-GP网络,在生成器中融合自注意模块和DenseNet模块,以自动学习重要的全局信息,并且在判别器中加入了可切换归一化,增强网络的泛化能力;
步骤4:将非平衡数据集的训练集作为改进的WGAN-GP网络的输入,重复迭代生成器及判别器,至达到纳什均衡后,将生成器生成的故障数据添加到非平衡数据集中进行数据扩充,最终得到四个平衡数据集;
步骤5:在平衡数据集的基础上,对Alxnet分类器进行训练,并检测故障诊断性能。
所述步骤1包括如下步骤:
S1.1:将振动加速度传感器安装在轴承上,通过振动加速度传感器获取轴承不同故障状态下的一维振动信号,形成包含原始振动信号的数据集;
S1.2:由于小波变换具有强大的时频特征提取能力,能得到包含更多有用信息的二维时频图像;所以本发明采用小波变换对原始振动信号进行预处理,将小波变换后的时频域信号作为判别器的输入数据,小波变换的公式如下:
式中,x(t)是输入的振动信号;s为尺度因子;μ为平移因子;t表示时间变量;
所述步骤2中,为验证Alxnet模型在不同非平衡数据集下的泛化性能,将训练集数量进行限制,且设置了四个比较实验数据集,其中不平衡率分别为1:1、2:1、5:1和10:1,分别对应于数据集A、B、C和D。
所述步骤3中,判别器由四个卷积层以及二个全连接层组成;生成器由四个反卷积层和二个全连接层组成;所述步骤3包括以下步骤:
步骤S3.1:在生成器中,每个反卷积层后都设有一个批量归一化(BatchNormalization,BN)和Relu激活函数;
在判别器中,由于改进的WGAN-GP网络对每个样本独立的施加了梯度惩罚效果,将BN改为可切换归一化(witchable Normalization,SN),增加模型的泛化能力,同时将激活函数改为LeakyRelu;其中SN使用可微分学习,为深度网络中的每一个归一化层确定合适的归一化操作,SN通过六个权重组合BN、层归一化(Layer Normalization,LN)和实例归一化(InstanceNormalization,IN),并在训练过程中自动找到合适的归一化方法;N操作的输出可以定义为:
y
式中,y
步骤S3.2:为加强生成器中特征传递,减少网络中的参数和梯度消失,在生成器第一个卷积层后面增加了DenseNet网络;其中DenseNet由密集块(dense block)和过渡块二部分组成,密集块定义了输入输出之间的密集连接关系,它通过引入任何层到后续所有层的直接连接,缓解了梯度消失问题,加强了特征传播,大幅减少参数数量;其中本发明的DenseNet结构使用三个dense block,在一个dense block中,其第i层的特征通过下式进行表示:
x
式中,[x
步骤S3.3:为了解决长距离中相互依赖的特征难以捕获的问题,在生成器和判别器网络中增加自注意力机制;
在自注意力机制层中,通过一系列注意力权重系数突出或强调目标对象的重要信息,抑制一些无关的细节信息,对全局信息进行关联,灵活且一步到位地捕捉局部和全局的联系;自注意力机制的公式如下:
式中,输入自注意力层的向量被三个不同权重的卷积操作生成Q(Query),K(Key),V(Value)三个矩阵,首先将Q与K之间的点乘,然后为了防止其结果过大,除以一个尺度标度
步骤S3.4:将随机梯度下降的双时间尺度更新规则(two time scale updaterule,TTUR)应用到改进的WGAN-GP网络中,对判别器和生成器设置不同的学习率,解决网络训练过程中出现的不稳定性问题以及训练时间太长的情况。
上述步骤3主要是构建生成对抗网络结构。
下面的步骤4为对生成对抗网络的训练以及构建平衡数据集的过程。
所述步骤4中,构建好改进的WGAN-GP网络后,交替训练生成器和判别器n次,达到纳什平衡时停止训练,提取生成器网络依次生成不同故障类别的样本来补充不平衡的数据集。
所述步骤4中,改进的WGAN-GP网络具体的训练步骤包括:
S4.1:在生成对抗网络中引入了一种新的分布距离度量方法Wasserstein距离,并且在原有的损失函数中添加梯度惩罚项来使判别器的权重满足1-Lipschitz条件限制,即对于两个图像x
接下来固定生成器,将生成器的生成数据和真实数据一起输入判别器,得到的诊断结果与真实结果进行比较,通过判别器损失函数L
式中,||·||
S4.2:在生成器中引入类别标签作为额外的输入层,与生成器的噪声输入相结合,形成一个联合隐层表达式,从而促使生成器有条件式地监督生成具有特定类别特征的样本;再将L
式中,y代表真实数据图片;Z是输入生成器的噪音向量;C是每个噪音对应的类别标签;n为输入样本的批量数;
所述步骤5中,通过设计Alxnet网络进行故障诊断,Alxnet主要由五个卷积层和三个全连接层组成,并且在网络中增加了Dropout层,解决网络层数过多时产生的梯度消失问题并且提升了特征的丰富性,减少了信息的丢失。
所述步骤5包括如下步骤:
S5.1:以扩充后的平衡数据集作为输入,经过卷积层,Relu激活函数和最大池化层,抽取深层特征;抽取深层特征就是通过卷积层,激活函数,最大池化层得来的。
S5.2:根据Adam优化器和Alxnet分类器的损失函数来优化网络权重,使其能最大程度提高诊断效果;其中Alxnet分类器采用交叉熵损失函数,损失函数公式如下:
式中,y
S5.3:将测试集输入训练后的Alxnet模型,输出故障诊断结果。
本发明一种基于改进WGAN-GP和Alxnet的轴承故障诊断方法,技术效果如下:
1)本发明将基于改进的WGAN-GP数据增强方法与Alxnet诊断网络相结合,促使生成器有条件式地监督生成具有特定类别特征的样本平衡数据集,并且平衡后的数据集可以在Alxnet网络中取得很好的诊断效果。
2)本发明在基于改进的WGAN-GP网络模型的构建中,将自注意力机制和密集卷积块相融合到生成器中,使生成器网络充分提取特征,能够生成真实的故障样本;判别器中使用可切换归一化对判别器的权重进行归一化,从根本上解决了训练过程中的不稳定和过拟合问题。
3)随着改进的WGAN-GP网络深度加深,本发明将TTUR策略应用到改进的WGAN-GP网络模型中,该改进不仅可以改善网络的稳定性,而且相比于原模型,能进一步减少改进的WGAN-GP网络的收敛时间,更快的生成质量高的样本。
附图说明
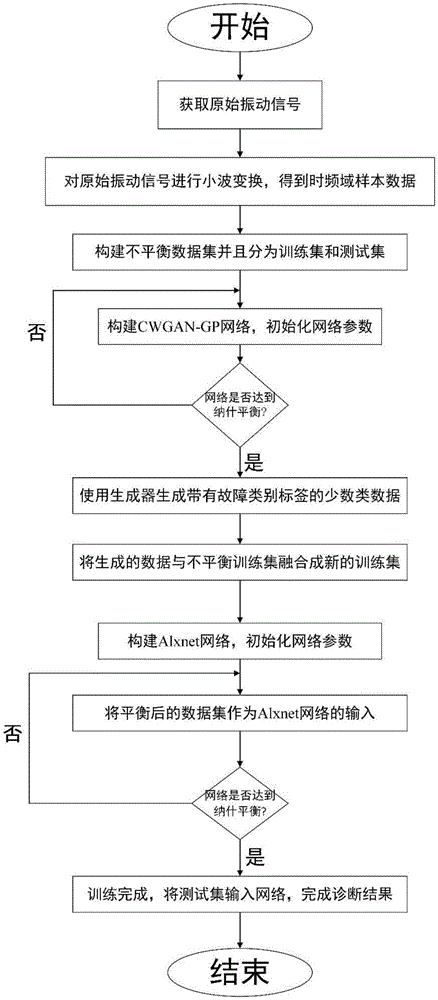
图1是本发明方法的整体流程图。
图2是本发明的生成器的结构示意图。
图3是本发明的判别器的结构示意图。
图4是本发明的分类器的结构示意图。
图5是本发明在四个数据集下用训练集生成的图像与原始图像的对比图。
图6(a)是本发明在平衡数据集下生成图像和原始图像分布经过t-SNE可视化降维后的示意图;
图6(b)是本发明在不平衡数据集下生成图像和原始图像分布经过t-SNE可视化降维后的示意图。
图7(a)是本发明在平衡数据集上,分类器模型训练损失、测试精度和迭代次数的曲线图;
图7(b)是本发明在平衡率为2:1的数据集上,分类器模型训练损失、测试精度和迭代次数的曲线图;
图7(c)是本发明在平衡率为5:1的数据集上,分类器模型训练损失、测试精度和迭代次数的曲线图;
图7(d)是本发明在平衡率为10:1的数据集上,分类器模型训练损失、测试精度和迭代次数的曲线图。
图8(a)是本发明在平衡数据集上将测试集输入到分类模型后获得的混淆矩阵图;
图8(b)是本发明在平衡率为2:1的数据集上将测试集输入到分类模型后获得的混淆矩阵图;
图8(c)是本发明在平衡率为5:1的数据集上将测试集输入到分类模型后获得的混淆矩阵图;
图8(d)是本发明在平衡率为10:1的数据集上将测试集输入到分类模型后获得的混淆矩阵图。
具体实施方式
本发明公开了一种融合改进的Wasserstein生成对抗网络(WGAN-GP)和Alxnet的电机轴承故障诊断方法。首先从传感器获得不同状态下的振动信号,再经过小波变换获得时频信号并且按照实际情况创建不同平衡率下的数据;将数据集输入WGAN-GP网络,训练WGAN-GP网络达到纳什平衡后,再从生成器中生成带有特定标签的数据来补充不平衡数据;最后将平衡后的数据带入故障诊断网络中进行特征提取、故障分类,实现不同故障类别的特征学习。
下面结合附图对本发明的具体实施步骤做详细说明:
如图1所示,为本发明的整体流程图,其中:包括数据预处理,生成模型和故障诊断模型。数据预处理包含获取原始振动信号、小波变换处理原始信号以及按比例分为训练集和测试集这三部分,生成模型主要是利用改进WGAN-GP相互对抗的机制,将少数样本作为网络输入生成数据,用于补充数据集。故障诊断模型主要是将平衡后的样本作为训练集对Alxnet网络进行训练,然后将测试集输入训练好的网络中进行故障诊断。
在本发明中,分析了凯斯西储大学(CWRU)轴承实验数据集。其目的是诊断具有不同故障程度的轴承。实验设备包括一个2hp的电动机,一个扭矩传感器译码器,一个功率测试仪,电子控制器。轴承转速为1750r/min,样本采用频率为12kHz,在电机负载为1.5kW下,分别选取轴承状况为正常(NC)、内圈故障(IR)、滚动体故障(B)、外圈故障(OR)的数据,故障尺寸大小分别为0.007、0.014、0.021mm。因此,可以获取10种不同状态下的轴承故障样本,按照故障类型和故障尺寸可以标记为NC、B007、B014、B021、IR007、IR014、IR021、OR007、OR014、OR021,并且将以上类型的故障样本标签依次标记为0到9。
在本发明中,采用了0hp负载场景下驱动端轴承外壳的数据集。振动信号以每秒12000个样本的速度采集,间隔300个点取样,各个状态取1000个样本进行实验。为了验证模型在不同不平衡率数据集下的泛化性能,本发明设置了四个不同的平衡率数据集。平衡比率分别为1:1、2:1、5:1和10:1,对应于数据集A、B、C和D;不平衡比率定义为正常样本数与每种故障类型样本数的比率;以5:1的不平衡率为例,每个正常状态包含1000个样本,则每个故障类型的样本数为200;最后按照8:2的比例来构建训练集和测试集。更多数据集的细节如表1所示。
表1不同平衡率下的滚动轴承数据集
根据表1,可以得到四种数据集下每种故障类别,作为训练集的样本个数以及每个数据集的测试集样本数;然后,通过改进的生成对抗网络训练少数类样本并且生成新样本。平衡的少数样本与大多数样本相结合,将平衡后的数据集输入故障诊断分类器进行训练,训练完成的分类器通过输入测试集后输出故障诊断结果。
如图2所示,为本发明的生成器模型结构图,主要由四个卷积层和二个全连接层组成,利用卷积层可以更好的提取图像中的特征,并且在每一个反卷积层和全连接层后加一个批归一化,批归一化将特征层的输出归一化到一起,加快了网络的训练速度,提升了训练的稳定性。在第一个反卷积后面加入了一个Densenet层,Densenet由3个Denseblock(密集块)组成,在密集块中,每层特征图大小一致,密集块中由BN、ReLU、Conv(Convolution)组成,从而加强了特征传播,极大地减少了网络中的参数量,缓解了梯度消失问题。将自注意力机制加入生成器的目的是促使生成模型在生成图像过程中,生成模型高效地获取特征内部的全局依赖关系,提高生成图像的质量和清晰度,使图像的纹理细节更加明显,从图像纹理、亮度、清晰度等方面提升图像美感。
生成器执行流程:设定批处理样本个数为64,输入噪声维度为100,卷积核的大小为4×4,步长为2,输入类别标签的维度是10,把噪声标签和类别标签融合后组成四维向量并且输入生成器网络,经过二层全连接再将向量重构为512×8×8的特征图,前后经过5层反卷积层升维;通过三个密集块进行深层特征提取保持网络,一次self-attention运算使生成器输出图像的大小为3×128×128。其中卷积核的个数分别为256、128、64、3,全连接的输出节点个数分别为512和32768。
如图3所示,为本发明的判别器模型结构图,判别器需要判别输入的数据是来自真实图片还是生成的图片。主要由4个卷积层和二个全连接层组成,激活函数选择LeakyRelu。由于改进的WGAN-GP网络中的梯度惩罚机制要独立的施加于每个样本,使用批归一化会引入同一批样本的不同样本之间的依赖关系,所以本发明将批归一化改为可切换归一化,解决了批归一化存在的问题同时使模型具有更强的泛化能力。
判别器执行流程:将真实数据与生成器生成的数据一起输入到判别器中,卷积核的大小为4×4,步长为2,输入的向量维度是3×128×128,前后经过四个卷积层降维,和一个自注意力模块用远距离细节约束当前合成图像的细节,最后通过二个全连接层输出判别图片类别真假的概率值。其中卷积核的个数分别为64、128、256、512,全连接的输出节点个数分别为512和1。
如图4所示,为本发明的分类器模型结构图,主要由五个卷积层和三个全连接层组成,每个卷积层后面增加Relu激活函数,在全连接层的部分增加了Dropout层,Dropout作用是在全连接层中随机去掉了一些神经节点,防止过拟合的现象出现。
分类器的执行流程:将扩充完的训练集作为分类器的输入,输入图片的尺寸为128×128×3,经过卷积核为11×11,步长为4的卷积层输出尺寸为31×31×48的特征图,经过最大池化层输出尺寸变为15×15×48,紧接着通过卷积核为5×5,步长为1的卷积层和最大池化层变为7×7×128,连续通过三个卷积核为3×3,步长为1的卷积层提取特征,再通过最大池化层让维度减半至3×3×128,最后连接着三个全连接层后输出诊断分类结果。
如图5所示,为本发明的原始图像与生成器在不同平衡率下生成的图像对比图,利用每个数据集的训练集训练改进WGAN-GP后,随机选择5种不同的生成故障样本与原始图像进行对比。当平衡率为1:1和2:1的时候,生成的图片特征明显,纹理,清晰度,亮度等细节与原始图像相似,达到了很好的生成效果。当平衡率为5:1和10:1时,生成的效果与原始图像相比,在一些局部的特征细节上有细小的差别,但是总体来说生成的数据保持了原始数据的关键特征,同时具有良好的多样性。因此,认为,本发明所提出的方法生成的数据与原始样本相似,模型能够学习数据的分布特征,并具有扩展原始数据集的能力。因此本发明的数据增强方法可以用解决数据不平衡的问题。
如图6(a)~图6(b)所示,分别本发明在平衡数据集和不平衡数据集下生成图片和原始图片分布经过t-SNE可视化后的结果对比图。使用t-SNE进行降维可视化以提取数据特征,并对10种类型的生成数据和原始数据进行特征可视化。在每种故障类型中,原始的数据被分配为10种不同颜色的点,生成的数据被分配为10种不同颜色的米形。
可见,不论是在平衡数据集如图6(a)所示,还是不平衡数据集如图6(b)所示,在同一故障类型中,除了个别类别的特征存在离散的现象,大部分生成样本的特征与原始数据的特征非常一致,因此特征可以很好地聚类。验证所提出的数据增强方法可以通过对抗性训练生成与原始数据具有相似概率分布的合成数据,从而补充不平衡数据集。同时,生成数据的不同故障类型的数据特征在图中也可以清晰区分,这证明了数据扩充方法生成的数据可以用于轴承故障分类测试。
如图7(a)~图7(d)所示,为本发明4种平衡率的数据集经过分类器分类后的损失函数,曲线展示的是训练集的损失以及测试集的分类精确度。模型训练结果在每个数据集中都是令人满意的。图7(a)~图7(d)中精确度的曲线一开始上下震荡,是因为网络还处于学习阶段,没有掌握原始样本的特征,但随着迭代次数的增加,测试集的分类精度可以在短时间内达到较高的精度并最后趋于收敛,训练集的损失函数平滑地减小最后在0附件趋于稳定。
这些结果表明,该模型具有良好的诊断效果,可以用在不平衡数据集的故障诊断领域中。同时,可以观察到,随着数据集不平衡率的增加,准确率和损失率曲线波动程度也在逐渐增大。原因是当数据极度不平衡时,原始数据有限以及提取的有用特征较少,导致模型生成的图片在细节中体现较差,从而影响模型的稳定性。从四种不平衡的图像中可以看出,本发明方法可以在低损失的同时保证高精确的诊断结果。
如图8(a)~图8(d)所示,为本发明4种平衡率的数据集的测试集经过分类模型获得的混淆矩阵,为了便于对结果进行分析,本发明采用了各数据集第1次计算结果的分类混淆矩阵进行定量描述。图中,混淆矩阵的横坐标是预测故障类型,纵坐标是实际故障类型,位于第i行和第j列的项目表示第i个状态的比例,被分类为第j个状态。因此,对角线值表示每个条件的正确分类比例,而非对角线值等于将一个条件分类为其他条件时的错误比例。
从图8(a)~图8(d)中四种不同的数据集看出来,不同平衡率中大部分类别的诊断精确度均可达到100%,平衡率为1:1、2:1时,所有类别的故障诊断精确度均98%以上,当数据集平衡率为5:1,Alxnet分类器错误分类了2.44%的B024样本以及4.76的IR007样本,当数据集平衡率为10:1,分类器错误分类了5.00%的B014样本、5.00%的IR0014样本和4.76%的IR0021样本。可以发现随着数据集不平衡率的增大,轴承滚动体故障和内圈故障容易发生较大误判,这是由于内圈故障数据和滚动体故障数据分布更复杂和更难捕获所导致。但总的来说本发明方法可以在四种数据集的不同故障类别下达到高精确度的效果。
- 基于改进二叉树支持向量机的泵轴承故障诊断模型的构建方法及诊断方法
- 一种基于改进VMD的滚动轴承故障诊断方法