一种基于知识蒸馏的联邦学习方法及系统
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于大数据处理领域,具体的说,涉及了一种基于知识蒸馏的联邦学习方法及系统。
背景技术
大数据时代,同一行业内、不同行业间的大数据都可以联合起来产生巨大价值。在人工智能领域,传统的数据处理模式往往是集中式的,各方收集的数据将被集中至同一处进行预处理、清洗及建模。但随着大数据相关技术及人工智能的发展和应用,数据的安全性和隐私性越来越受到相关部门及企业的重视。要求愈发严格的大数据隐私性要求造成了“数据孤岛”的问题。针对这个问题,谷歌首次提出了联邦学习的概念。联邦学习是一种使得各数据拥有方在保障数据安全和数据隐私的前提下能进行协同训练的机器学习框架,可以保证不同的数据拥有方在不共享数据的情况下进行协同训练,共享数据价值但不共享数据。
然而,联邦学习中的数据由数据所有者独立产生,各参与者的数据通常具有不同分布特征,这意味着联邦学习系统中的数据分布并不一定满足传统的分布式机器学习优化算法的数据服从独立同分布(Independent-and-Identically-Distributed,IID)的前提假设。大多数情况下,联邦学习中的数据分布是非独立同分布的(Non-Independent-and-Identically-Distributed,Non-IID)。Non-IID的数据分布特征使得联邦学习中的模型训练速度变慢,模型准确率降低,模型训练需要更多的通信开销,增大模型的训练难度。因此,非独立同分布数据下的高效联邦学习算法研究具有重要的研究意义,也对联邦学习系统的应用具有重要价值。
McMahan等人提出了FederatedAveraging(FedAvg)算法,该算法极大的降低了联邦学习中的通信成本,同时在独立同分布数据下能够让联邦学习模型获得接近集中式训练的准确率,但在非独立同分布数据下该算法的性能会显著下降。
为解决非独立同分布数据对联邦学习模型的影响,Li等人将正则化的思想引入联邦学习,提出FedProx算法,该算法修改了客户端本地模型训练的损失函数,通过限制客户端本地模型更新与初始本地模型(即最新的全局模型)差距,防止本地模型过度“偏移”。但该算法只是简单地约束了本地模型的训练,没有充分利用全局信息,对最终全局模型的性能提升不明显。
Jeong等人提出FAug算法,该算法试图通过生成对抗网络对本地数据进行数据增强来防止本地模型发生“偏移”。但该算法要求客户端上传少量本地数据作为训练生成对抗网络的种子数据,这严重威胁到客户端的数据隐私安全。
Zhu等人提出FedGen算法,该算法在服务端训练一个服从全局数据分布的特征生成器,在客户端执行本地模型训练前,服务端将最新的全局模型和特征生成器同时广播给客户端,客户端在本地模型训练时利用特征生成器生成特征“纠正”本地模型的更新,防止本地模型过度“偏移”。但该算法要求客户端上传本地数据的标签,威胁到客户端的数据隐私安全。
Yao等人提出了FedGKD算法,该算法在服务端保存了最新5轮的全局模型,平均后得到一个教师模型,客户端需要同时下载最新的全局模型和教师模型,在训练本地模型的同时,利用知识蒸馏将教师模型的知识传递给本地模型,防止本地模型发生“偏移”。由于该算法要求客户端同时下载全局模型和教师模型,因此该算法相比FedAvg需要更多的通信成本。客户端在知识蒸馏时使用的数据为客户端的本地数据,在非独立同分布的场景下并不服从全局数据分布,不能将教师模型的全局知识传递给本地模型。
发明内容
本发明的目的是针对现有技术的不足,本发明提供一种基于知识蒸馏的联邦学习方法及系统,让客户端本地模型训练能够利用全局知识,使用知识蒸馏将全局知识传递给本地模型,融合全局知识与本地知识,防止本地模型发生“偏移”,从而加快全局模型的收敛速度,并提升全局模型的准确度。
为了实现上述目的,本发明所采用的技术方案是:
本发明第一方面提供一种基于知识蒸馏的联邦学习方法,包括:
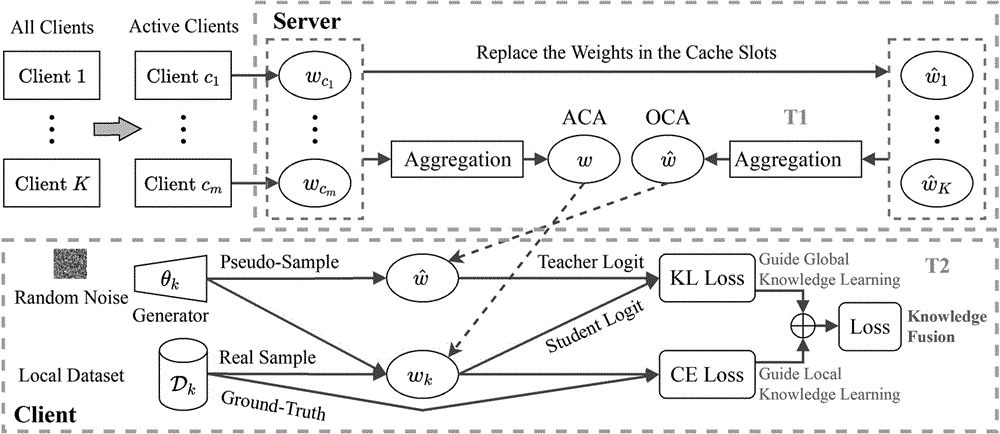
配置服务端和客户端,其中,客户端用于训练本地模型,服务端维护有K个不同的用于存储最新的本地模型的缓存槽;在每一轮训练中,只有处于活跃状态的客户端需要将本地模型上传给服务端;
服务端和客户端按以下方法实现联邦学习:
步骤1,在第t-1轮训练的最后一步,服务端整合所有当前轮处于活跃状态客户端上传的本地模型,即
步骤2,在第t轮训练中,只有处于活跃状态的客户端参与训练,用c
步骤3,接收到ACA模型和OCA模型后,每个处于活跃状态的客户端分别将ACA模型和OCA模型视为初始本地模型和教师模型,分别用w
步骤4,采用无数据知识蒸馏技术,将教师模型的知识传递给本地模型;在无数据知识蒸馏中,训练一个用于生成伪样本以实现知识蒸馏的生成器;同时,利用每个客户端的本地数据对本地模型进行训练,以将来自教师模型的全局知识Global和来自本地数据的本地知识Local融合并传递给本地模型;
步骤5,在Global-Local知识融合后,所有处于活跃状态的客户端都将本地模型上传给服务端;
步骤6,服务端接收到客户端上传的本地模型后,根据客户端的ID更新缓存槽中的本地模型,其中,当前轮不处于活跃状态的客户端对应的缓存槽的本地模型保持不变;
更新完所有处于活跃状态的客户端对应的缓存槽的本地模型后,服务端重新整合本地模型,得到新的ACA模型和新的OCA模型;
返回步骤1进行下一轮训练。
基于上述,步骤4中,用于生成伪样本以实现知识蒸馏的生成器的损失函数按下述方法训练:
定义g(·)表示生成器的输出,
设计One-Hot损失函数:
伪样本
其中,CE是交叉熵,如果L
设计信息熵损失函数:
为了使生成器生成的数据能够覆盖所有类,采用信息熵来衡量生成数据的分布的均匀性;即,给定一个概率向量p=(p
当L
设计Activation损失函数:
真实样本的特征向量倾向于获得较高的激活值,因此,Activation损失函数被定义为:
其中,‖·‖
综合以上三个损失函数,训练的生成器的总损失函数为:
L
其中,λ
基于上述,客户端采用Global-Local知识融合技术训练本地模型,按下述方法训练损失函数:
定义h(·)表示本地模型的概率向量输出;
设计KL损失函数:
为了让每个客户端使用生成器生成的数据将全局知识从教师模型传递给本地模型,同时,本地模型从本地数据中学习本地知识,则KL损失函数定义如下:
其中,KL表示Kullback-Leibler divergence散度;最小化L
设计CE损失函数:
用
其中,CE表示交叉熵,最小化L
综合以上两个损失函数,Global-Local知识融合的总损失函数为:
L=L
其中,γ是一个超参数,用于平衡两个损失函数;最小化L使得Global-Local知识融合到本地模型中。
本发明第二方面提供一种基于知识蒸馏的联邦学习系统,其特征在于,包括:服务端和客户端,其中,客户端用于训练本地模型,服务端维护有K个不同的用于存储最新的本地模型的缓存槽;在每一轮训练中,只有处于活跃状态的客户端需要将本地模型上传给服务端;
服务端与客户端通信,用以实现所述的基于知识蒸馏的联邦学习方法。本发明相对现有技术具有突出的实质性特点和显著进步,具体的说:
1、本发明通过Active-Inactive模型整合技术和Global-Local知识融合技术,设计了一个隐私保护的联邦学习方法,在数据异构(即各客户端本地数据非独立同分布)场景下,实现了高模型性能和高公平性;
2、本发明服务端模型整合时,充分利用所有客户端的本地模型,利用Active-Inactive模型整合技术,得到精确表示全局知识的OCA模型。对于大多数以前的联邦学习方法,只有处于活跃状态客户端的本地模型参与服务端的模型整合,最终得到一个全局模型,即ACA模型。相比之下,本发明除了整合处于活跃状态客户端的本地模型,还整合了所有客户端的本地模型,包括处于活跃状态的客户端和不处于活跃状态的客户端,得到OCA模型,表示全局知识。因此,Active-Inactive模型整合技术支持更精确的全局知识表达,是生成全局模型的一种简单而精确的方法。它可以和很多联邦学习方法(如FedAvg,FedProx等)结合使用,以提高其性能;
3、本发明客户端本地模型训练时,同时考虑全局知识与本地知识,利用Global-Local知识融合技术将全局知识与本地知识融合到本地模型中。想要将知识从全局模型(教师模型)传递给本地模型(学生模型),通常需要有用于训练全局模型的数据集。然而客户端只有本地数据,且分布通常与全局数据不一致。因此,本发明采用无数据知识蒸馏技术传递知识,解决了客户端没有全局数据的问题。在无数据知识蒸馏中,需要训练一个生成器,用于生成知识蒸馏的数据。值得注意的是,本发明生成的数据不需要与真实训练数据分布非常相似,唯一的要求是生成的数据可以用于促进知识传递。因此,对无数据知识蒸馏中生成器的要求和传统生成对抗网络(GAN)中生成器的要求是不同的,因为传统生成对抗网络中的生成器需要生成视觉上近似真实图片的假图片,能够达到以假乱真的效果;但是无数据知识蒸馏中的生成器只需要生成能够传递知识的假图片,对视觉上的效果不做要求。
附图说明
图1为本发明的设计示意图。
具体实施方式
下面通过具体实施方式,对本发明的技术方案做进一步的详细描述。
如图1所示,本实施例提供了一种基于知识蒸馏的联邦学习方法和一种基于知识蒸馏的联邦学习系统。
其中,联邦学习系统包括:服务端(Server)和客户端(Client),其中,客户端用于训练本地模型,服务端维护有K个不同的用于存储最新的本地模型的缓存槽;在每一轮训练中,只有处于活跃状态的客户端(ActiveClient)需要将本地模型上传给服务端;
服务端与客户端通信,用以实现所述的基于知识蒸馏的联邦学习方法。
具体的基于知识蒸馏的联邦学习方法,包括:
步骤1,在第t-1轮训练的最后一步,服务端整合所有当前轮处于活跃状态客户端上传的本地模型,即
步骤2,在第t轮训练中,只有处于活跃状态的客户端参与训练,用c
步骤3,接收到ACA模型和OCA模型后,每个处于活跃状态的客户端分别将ACA模型和OCA模型视为初始本地模型和教师模型,分别用w
步骤4,采用无数据知识蒸馏技术,将教师模型的知识传递给本地模型;在无数据知识蒸馏中,训练一个用于生成伪样本以实现知识蒸馏的生成器;同时,利用每个客户端的本地数据对本地模型进行训练,以将来自教师模型的全局知识Global和来自本地数据的本地知识Local融合并传递给本地模型。
其中,用于生成伪样本以实现知识蒸馏的生成器的损失函数按下述方法训练:
定义g(·)表示生成器的输出,
设计One-Hot损失函数:
伪样本
其中,CE是交叉熵,如果L
设计信息熵损失函数:
为了使生成器生成的数据能够覆盖所有类,采用信息熵来衡量生成数据的分布的均匀性;即,给定一个概率向量p=(p
当L
设计Activation损失函数:
真实样本的特征向量倾向于获得较高的激活值,因此,Activation损失函数被定义为:
其中,‖·‖
综合以上三个损失函数,训练的生成器的总损失函数为:
L
其中,λ
客户端采用Global-Local知识融合技术训练本地模型,按下述方法训练损失函数:
定义h(·)表示本地模型的概率向量输出;
设计KL损失函数:
为了让每个客户端使用生成器生成的数据将全局知识从教师模型传递给本地模型,同时,本地模型从本地数据中学习本地知识,则KL损失函数定义如下:
其中,KL表示Kullback-Leibler divergence散度;最小化L
设计CE损失函数:
用
其中,CE表示交叉熵,最小化L
综合以上两个损失函数,Global-Local知识融合的总损失函数为:
L=L
其中,γ是一个超参数,用于平衡两个损失函数;最小化L使得Global-Local知识融合到本地模型中。
步骤5,在Global-Local知识融合后,所有处于活跃状态的客户端都将本地模型上传给服务端。
步骤6,服务端接收到客户端上传的本地模型后,根据客户端的ID更新缓存槽中的本地模型,其中,当前轮不处于活跃状态的客户端对应的缓存槽的本地模型保持不变;
更新完所有处于活跃状态的客户端对应的缓存槽的本地模型后,服务端重新整合本地模型,得到新的ACA模型和新的OCA模型;
返回步骤1进行下一轮训练。
本发明在训练结束后会得到两个全局模型,分别是ACA模型和OCA模型,只保留OCA模型,作为最终的全局模型。
对比实验
为验证本发明方法的效果,本实验与FedAvg,FedProx,FedGen,FedGKD和q-FFL五种方法进行比较。实验在EMNIST,CIFAR-10和CIFAR-100三个数据集上进行测试,对于每一个数据集,使用迪利克雷分布Dir
表1不同方法在MNIST上的性能
表2不同方法在CIFAR-10上的性能
表3不同方法在CIFAR-100上的性能
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
- 一种基于知识蒸馏的面向设备异构的联邦学习方法
- 基于知识蒸馏的联邦图学习方法及自动驾驶方法