一种基于知识蒸馏的面向设备异构的联邦学习方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于数据信息隐私保护技术领域,具体涉及一种面向设备异构的联邦学习方法。
背景技术
随着数据量的快速增加,以及出于隐私保护的需求,联邦学习已经发展成为一个非常有前景的方向。联邦学习一般由许多仅能访问私有数据的客户端以及一个可以协调学习过程而不能访问任何原始数据的中央服务器构成。它的目标是在不显式地分享私有数据的前提下,利用分布存储的数据在中央服务器上训练一个全局模型。这种方法面临的一个挑战是数据异构,当各个客户端拥有的数据分布不同时模型的性能会下降。现有的解决数据异构问题的方法大多基于梯度的整合,必须在本地模型同构的条件下进行。
本发明申请专注于设备异构的联邦学习问题。在这个问题背景下,各个客户端的存储、计算和通信能力的不同,造成本地模型的结构也会不同,现有方法会遇到严峻的挑战。在一些实际的联邦学习场景中,需要在硬件差异很大的设备上训练。当模型结构设计的较复杂时,资源较少的设备无法参与训练;当模型结构较简单时,另一些资源充足的设备又未充分利用。
为此,本发明提出一种基于知识蒸馏的联邦学习算法,它允许每个客户端建立个性化模型,可以同时解决模型异构和数据异构两种挑战。算法把每轮通信分为两个阶段,在服务器训练阶段,首先以推断样本低维表示的后验分布为目标在服务器上建立生成模型,然后把训练好的生成模型传递给客户端;在本地训练阶段,客户端一方面用私有样本计算任务损失,一方面用生成模型输出的均值样本计算调优表示层的损失。这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
发明内容
本发明的目的在于提出一种面向设备异构的联邦学习方法,以便在客户端资源差异很大的场景下进行联邦学习,从而为挖掘数据信息提供有力保障。
本发明提出的面向设备异构的联邦学习方法,是基于知识蒸馏技术的;其涉及的系统包括有K个客户端、1个服务器;其中;
每个客户端上有1个根据软硬件资源设置的分类模型,客户端的分类模型划分为表示层和决策层,表示层用于把样本映射为低维表示,决策层用于把低维表示映射为概率向量;客户端之间知识蒸馏的目标函数定义式:
其中,K是客户端数量;X
所述服务器上设置1个生成模型,由共享输入的均值函数和方差函数构成。系统的目标是高效地求解(1)式,为此,本发明方法把每轮通信分为两个阶段:服务器训练阶段和本地训练阶段;在服务器训练阶段,首先以推断样本低维表示的后验分布为目标在服务器上建立生成模型,然后把训练好的生成模型传递给客户端;在本地训练阶段,客户端一方面用私有样本计算任务损失,一方面用生成模型输出的均值样本计算调优表示层的损失。这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
具体地:
在服务器训练阶段,服务器首先收集所有客户端模型的表示层;收集客户端采集的低维表示,组成集合Z。然后,用变分推断法求解后验分布
假设
其中,Z是低维表示的集合,
从
另一方面,计算
其中,f
最后,服务器把训练后的生成模型的均值函数传给所有客户端。
在本地训练阶段,客户端首先接收服务器传来的均值函数。然后,一方面用私有数据集X
其中,X
接着,客户端采集低维表示,具体地说,客户端继续执行随机梯度下降过程,每执行q轮,把这期间得到的低维表示分标签求均值,在得到至少c个低维表示均值后停止采集。
最后,客户端把分类模型表示层和采集的低维表示均值上传给服务器。
重复服务器训练阶段和本地训练阶段,这样在多轮迭代之后,各个客户端可以得到比传统训练方法精度更高的模型。
本发明的特点和优势主要有:
第一它允许不同客户端有不同分布的数据和不同结构的模型表示层,可以同时解决模型异构和数据异构两种挑战,拓展了应用场景;
第二,它允许每个客户端建立个性化模型,在数据异构的场景下,相比建立全局模型的其它方法,它可以使系统获得更高的平均精度;
第三,它基于知识蒸馏技术优化表示层,在从相关客户端获取信息的同时减少不相关客户端的干扰,使本地模型的精度比优化决策层的方法或其它传统方法更高;第四,在通信过程中,客户端不是上传低维表示的原值而是均值,不是上传整个客户端模型而是仅上传表示层,这避免了服务器利用客户端模型参数或低维表示推测客户端数据。
附图说明
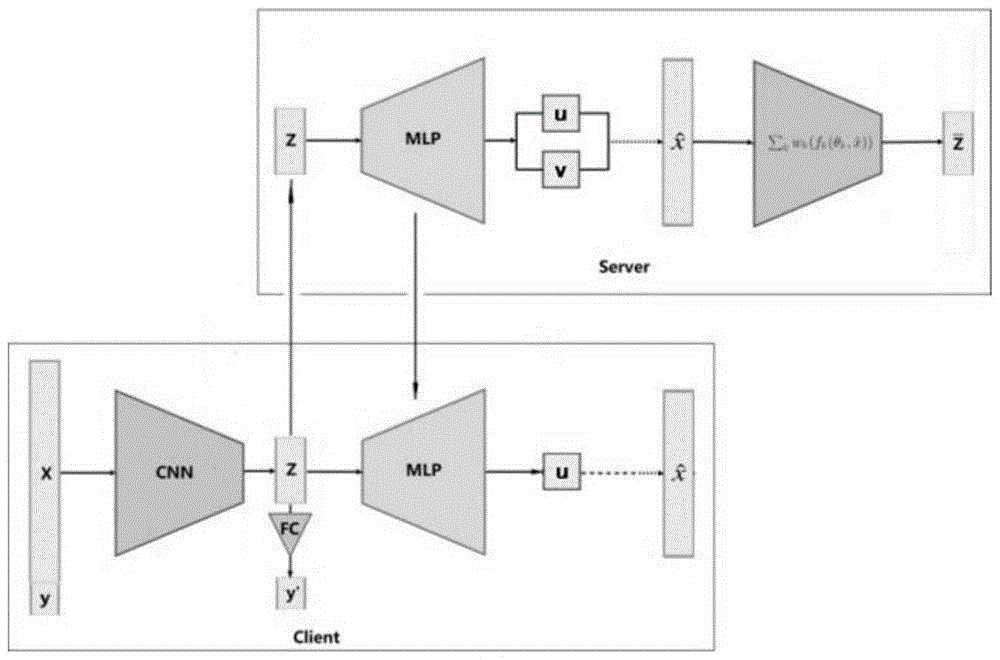
图1是本发明的网络结构图。
图2是图片数据样例。
图3是客户端采样低维表示。
图4是客户端生成全局表示。
图5是客户端CNN模型。
图6是客户端MLP模型。
图7是生成模型。
具体实施方式
下面结合附图对本发明的具体实施方式进行说明。
本发明的网络结构图,如图1所示。
首先,依据客户端的软硬件条件部署合适的分类模型,一般来说,可以在资源丰富的客户端上设置复杂模型,在资源不足的客户端上设置简单模型。
然后,客户端利用本地的图片数据训练本地模型,并在训练过程中采样低维表示。一轮训练之后,客户端将得到的低维表示和表示层参数上传至服务器。
服务器收集客户端上传的低维表示和表示层参数训练生成模型,并将训练好的生成模型发送给各个客户端。客户端更新生成模型之后,一方面利用本地的图片数据训练本地模型,另一方面,把训练过程中得到的低维表示输入生成模型得到均值样本,并用它调优模型的表示层。
下面结合MNIST数据集的分类任务来加以描述。如图2所示的图片是MNIST数据集的一部分样例。MNIST数据集包括10个数字标签,共计60000个训练样本和10000个测试样本。现将训练样本随机地分配给资源不同的100个客户端,每个客户端上有2类图片,每类图片300张;测试样本也分配给这100个客户端,并且保持分布与训练样本相同。要求以联邦学习的方式为每个客户端训练分类模型。
首先,因为100个客户端的资源不同,所以需要根据软硬件条件部署合适的分类模型。例如,对于资源比较丰富的客户端,可以设置CNN模型,模型结构如图5所示,其中Representor标识表示层,Predictor标识决策层。类似地,对于资源相对不足的客户端,设置MLP模型,模型结构如图6所示。CNN模型与MLP模型有相同的决策层,因此两者的表示层的输出向量有相同的长度。
然后,在训练开始之前,需要同步不同客户端的决策层的参数。训练时,客户端随机读取本地图片数据输入模型,每次读取50张,计算损失和梯度并更新模型参数。训练8*75/50=12次之后,客户端继续随机读取本地图片数据输入模型表示层,每次读取50张,计算低维表示并按标签分类,每读取4次计算各标签的表示均值。在得到10个表示均值后,把它们连同表示层参数一起上传至服务器。如图3所示。
假设这一轮通信中,服务器连通了100个客户端,收集客户端上传的低维表示共100*10=1000个。用这1000个表示向量和表示层参数训练生成模型。生成模型的结构如图7所示,其中,标号(f1,f21)构成均值函数,标号(f1,f22)构成方差函数,它们共享输入层f1。最后,将训练好的生成模型的均值函数部分发送给连通的客户端。
客户端更新生成模型之后,一方面利用本地的图片数据训练本地模型,另一方面,把训练过程中得到的低维表示输入生成模型得到均值样本,如图4所示,均值样本看起来像噪音,不会泄露信息。计算均值样本与本地样本的欧氏距离作为损失函数的正则项,调优模型的表示层。
重复以上训练步骤,经过10轮迭代后,客户端模型的平均精度在测试中可达到98.65%。
- 一种基于知识蒸馏的联邦学习方法及系统
- 基于知识蒸馏的联邦图学习方法及自动驾驶方法