一种坐席文档知识提取问答对的智能化学习方法
文献发布时间:2024-01-17 01:27:33
技术领域
本发明涉及数据监管领域,尤其涉及一种坐席文档知识提取问答对的智能化学习方法。
背景技术
随着智能客服在各个领域的逐渐兴起,如何快速方便的构建j基于银行业的智能客服机器人,成为一个热点的研究方向。智能客服系统建设的一个重要工作就是知识的生成和获取。知识的储备量可以直接影响智能客服的智能化程度。由于现阶段银行业务问答知识都是基于人工梳理、入库,但是在大数据时代,由于每天数据信息的暴增,人工方式的数据维护会造成成本的急剧上升。并且由于人工梳理知识需要一定的工作时间,导致知识的时效性严重滞后。另外人工对知识的梳理也会由于每个人理解与看法的不同导致结果的偏差。
现有的知识库实现的方案:
①通过客户给出的知识样例、知识范围、实际场景通话录音、客服知识手册等客户内部相关资料提取相关知识问答,与客户共同确认是否留用已收集的标准知识,区分类别,确定回复话术,一般人工时间为梳理200-300/人/天;
②确认标准知识和回复话术后,需人工编写相似问,对标准问进行扩展,一般比例是1:20及以上,人工编写时间大约为400-500/人/天;
③进行知识库测试,需编写测试集,对加工好的知识库进行问答准确率测试,一般比例为1:5及以上,人工编写时间大约为400-500/人/天,对匹配错误及无法回答的case进行问题定位、问题优化,人工时间大约为优化问题条目300/人/天;
④符合上线标准后,跟客户沟通体验场景,对客户体验后提出的问题进行整理,反馈问题原因、问题结果;
⑤上线后的运营工作,一般每个月初对前一个月的对话记录进行查看,筛选出机器人未回复或回复错误的问题进行优化,一般有“语料不足”、“场景覆盖度低”、“错别字”、“语料相似”等原因引起机器人的答非所问或循环兜底回复,对语料不足的问题进行补充相似问语料,对场景覆盖度低的问题进行补充新的问答对知识,因为错别字导致的回复错误,添加纠错词文本;语料相似问题,需要对两个知识问题进行重新区分知识语料,优化时间大概为40h左右。
现有技术的缺点:需要经验丰富的业务人员维护,并且构建过程存在工作效率低、人工成本高、知识库构建实时性差等问题。知识本身存在的形式多以word、excel、ppt等非结构化数据中,虽然属于显性知识但是存在知识分散、检索困难、提炼难度大等问题,无法有效的给坐席人员进行服务支撑,更无法提供给智能机器人引擎作为有效的训练数据。
发明内容
鉴于上述问题,提出了本发明以便提供克服上述问题或者至少部分地解决上述问题的一种坐席文档知识提取问答对的智能化学习方法。
根据本发明的一个方面,提供了一种坐席文档知识提取问答对的智能化学习方法,所述智能学习方法包括:
步骤S1:获取银行内部的相关结构化或非结构化文档;
步骤S2:文档格式的统一化处理;
步骤S3:使用NLP自然语言处理模型进行文档的问答对抽取;
步骤S4:对于生成的问答对进行质检;
步骤S5:对已有数据的知识更新。
可选的,所述相关结构化或非结构化文档具体包括:相关业务报表、年报、业务政策文件。
可选的,所述步骤S2:文档格式的统一化处理具体包括:
将文档统一转换为txt文档格式;
进行文档的碎片化处理,由于文档的大小不固定,直接使用模型进行问答抽取会导致部分问答对丢失。
可选的,所述文档的碎片化处理过程中根据实际业务需求,调整文档分片大小。
可选的,所述步骤S5:对已有数据的知识更新具体包括:将抽取出来的相关问答融入到已有的知识库中。
可选的,所述步骤S4:对于生成的问答对进行质检具体包括:对于生成的问答对进行质检,将有问题的问答对和问答对得分较低的数据筛选出来,进行人工审核。
本发明提供的一种坐席文档知识提取问答对的智能化学习方法,所述智能学习方法包括:步骤S1:获取银行内部的相关结构化或非结构化文档;步骤S2:文档格式的统一化处理;步骤S3:使用NLP自然语言处理模型进行文档的问答对抽取;步骤S4:对于生成的问答对进行质检;步骤S5:对已有数据的知识更新。提升系统构建效率智能化水平,从业务角度辅助客服坐席进行知识提炼和总结,从技术角度提供结构化数据给机器人作为训练语料,有效提升服务效率和用户体验。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
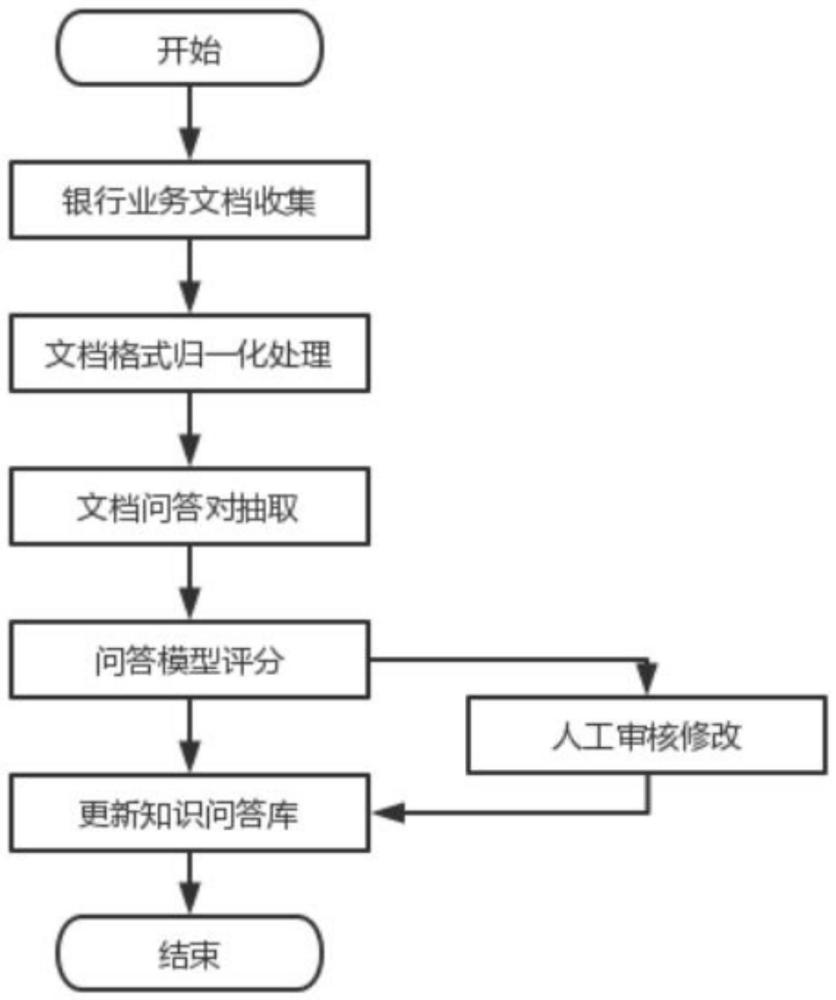
图1为本发明实施例提供的一种坐席文档知识提取问答对的智能化学习方法的流程图;
图2为本发明实施例提供的问答抽取模型示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明的说明书实施例和权利要求书及附图中的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元。
下面结合附图和实施例,对本发明的技术方案做进一步的详细描述。
如图1所示,一种基于银行客服坐席文档知识提取问答对的智能化学习装置或方法,包括以下五个步骤:
步骤S1:获取银行内部的相关业务报表、年报、业务政策文件等相关结构化或非结构化文档。
步骤S2:文档格式的统一化处理。将文档统一转换为txt文档格式。然后进行文档的碎片化处理,由于文档的大小不固定,直接使用模型进行问答抽取会导致部分问答对丢失。在此过程中也不可将文档切分太碎,否则会导致部分跨段落的问答对无法抽取,需要根据实际业务需求,调整文档分片大小。
步骤S3:使用NLP自然语言处理模型进行文档的问答对抽取。
步骤S4:对于生成的问答对进行质检,将有问题的问答对和问答对得分较低的数据筛选出来在进行人工审核。
步骤S5:接下来就是对已有数据的知识更新。将抽取出来的相关问答融入到已有的知识库中。
一站式问答抽取模型如下。
模型架构表示:
arg
其中θ为模型参数,q为问答对中的question(问题文本),a为问答对中的answer(问题答案),d为非结构化文档,被问题生成模块和答案抽取模块共享,因此两者可互相影响。
将问题生成和答案抽取整合到一个统一架构中来提升问答对的兼容性。OneStop模型对目标概率直接优化,其问题生成和答案抽取模块相互协作:答案抽取任务使问题生成模块生成更加可以回答的问题,因为根据不可回答的问题抽取答案是困难的;问题生成任务可增强答案抽取模块的表现,因此答案抽取模型会对易提问点给予更多关注。将问题生成模型和答案抽取模型统一在一个单一模型中,使OneStop比现存的至少有两个模型的pipeline方法轻量很多。
P(q,a|d;θ)=P(q|d;θ)·P(a|d;θ)
其中θ为模型参数,q为问答对中的question(问题文本),a为问答对中的answer(问题答案),d为非结构化文档,首先是给定业务文档产生问答对,第一阶段是给定document产生question,然后第二步预测该问题的答案的start和end的位置。然后把得到answer这一步,精简成了预测answer范围的start和end位置。然后可以对上述概率进行negativelikelihood。
φ=-log P(q,a|d;θ)
=φ
其中θ为模型参数,q为问答对中的question(问题文本),a为问答对中的answer(问题答案),d为非结构化文档,上述公式的第一项,因为document产生question,这个就是传统生成的一个loss。然后另外两项就是机器阅读的loss的。精简下来发现,第一项其实就是生成loss,start和end位置的预测的loss就是是机器阅读的一个loss,最终的loss形式就是生成loss和机器阅读loss的加和。
问答抽取模型模型采用基于transformer的seq2seq架构实现,由双向编码器和自回归解码器构成。编码器输入文档,解码器生成问题,答案开始和结束位置的预测基于编码器输出与解码器结尾输出。
其结构如图2所示,包括:
问答对审核模块:
构建审核模块,将从问答对是否涉及金融行业敏感词、违规词、问答对的语义相关度的角度对问答对进行审核校验。并且按照设定的规则对问答对进行打分。得分低的问答对会进行人工审核修改。
词典构建:根据金融行业规则构建敏感词、违规词词典
对抽取出来的问答对进行相关度分析,并且相得分结果。
使用语义相似度计算模型对问答对文本进行审核校验,并根据规则在前一步的得分基础上进行相应的加减。
有益效果:采用NLP相关技术,实现从非结构化文档中实现自动抽取的对抽取和审核加工、维护流程,提升系统构建效率智能化水平。从业务角度辅助客服坐席进行知识提炼和总结,从技术角度提供结构化数据给机器人作为训练语料,有效提升服务效率和用户体验。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于非结构化文档的知识提取方法及系统
- 基于非结构化文档的知识提取方法及系统