一种随机数生成方法及装置
文献发布时间:2024-04-18 19:52:40
技术领域
本申请涉及但不限于信息安全技术,尤指一种随机数生成方法及装置。
背景技术
零知识证明(ZKP,Zero—Knowledge Proof),是由S.Goldwasser、S.Micali及C.Rackoff在20世纪80年代初提出的。零知识证明指的是证明方能够在不向验证方提供任何有用的信息的情况下,使验证方相信某个论断是正确的。零知识证明实质上是一种涉及两方或更多方的协议,换句话讲,也即两方或更多方完成一项任务所需采取的一系列步骤。在零知识证明中,证明方向验证方证明并使其相信自己知道或拥有某一消息,但证明过程不能向验证方泄漏任何关于被证明消息的信息。
流式对称加密算法,在ZKP系统中作为随机数生成器,可以保证证明方和验证方生成相同的随机数,同时随机数无法事先预测。相关技术中,流式对称加密算法在采用软件实现时,其运算数据量大,会频繁调用内存,从而增加了CPU的负担;而且,在执行ZKP加密过程中,也会使得加密时间过长。
发明概述
本申请提供一种随机数生成方法及装置,能够降低运算量,提升随机数生成速度,从而缩短执行ZKP加密过程的时长。
本申请实施例提供一种随机数生成方法,包括:
将64字节待加密信息分为16个块,每个块表示4个字节,将每4个块作为一基础块得到第一基础块、第二基础块、第三基础块和第四基础块;所述四个基础块分别存储到四个256位寄存器中;
基于四个基础块和四个256位寄存器,完成流式对称加密算法中对块进行混合运算的一次基础操作;
以块为单位,对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块;
基于四个基础块和四个256位寄存器,完成流式对称加密算法中对重排后的块进行混合运算的一次基础操作。
在一种示例性实例中,还包括:
预设轮数加一,并返回所述对块进行混合运算的一次基础操作的步骤,直到轮数到达预设轮数阈值;
对经过预设轮数阈值迭代运算后的结果和未更新前的待加密信息进行加法运算,将运算结果作为随机数。
在一种示例性实例中,所述混合运算包括:256位单指令多数据SIMD加法指令,用于实现对两个256位SIMD寄存器的加法操作;256位SIMD异或,用于实现对两个256位SIMD寄存器的异或操作,其中一个256位寄存器表示所述加法操作的结果;以及,第一SIMD循环左移指令,用于实现以32位为独立单元对表示所述异或操作的结果的256位SIMD寄存器进行N1位第一循环左移。
在一种示例性实例中,所述第一基础块包括所述16个块中的块block0,block1,block2和block3;所述第二基础块包括所述16个块中的block4,block5,block6和block7;所述第三基础块包括所述16个块中的block8,block9,block10和block11;所述第四基础块包括所述16个块中的block12,block13,block14和block15;
所述对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块,包括:
针对所述对块进行混合运算的一次基础操作后的结果,将所述第二基础块的block5循环左移到block4处,将所述第三基础块的block10循环左移到block8处,将所述第四基础块的block15循环左移到block12处。
在一种示例性实例中,所述循环左移为第二SIMD循环左移;所述第二SIMD循环左移通过SIMD128_ROL指令实现;
所述SIMD128_ROL指令的格式包括:SIMD128_ROL(S,N2,R),用于实现对S进行128位的N2位循环左移后得到R;其中,S表示执行循环左移运算的256位SIMD寄存器,N2表示循环左移的位数,且N2为32的整数倍。
本申请实施例还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述随机数生成方法。
本申请实施例再提供一种计算机设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的随机数生成方法的步骤。
本申请实施例又提供一种随机数生成装置,包括:控制单元、预处理单元、256位寄存器堆、迭代处理单元,以及尾处理单元;其中,
预处理模块,用于在控制单元的控制下,从内存中读取数据,对读取的数据进行如下预处理后存入256位寄存器堆,其中,在256位寄存器堆中存储两份预处理后的结果:将64字节待加密信息分为16个块,每个块表示4个字节,将每4个块作为一基础块得到第一基础块、第二基础块、第三基础块和第四基础块;所述四个基础块分别存储到四个256位寄存器中;
核心处理单元,用于执行如下预设轮数迭代运算:从256位寄存器堆中读取待加密信息,基于四个基础块和四个256位寄存器,完成流式对称加密算法中对块进行混合运算的一次基础操作;以块为单位,对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块,并更新256位寄存器堆中待加密信息对应的16个块;基于更新后的四个基础块和四个256位寄存器,完成流式对称加密算法中对重排后的块进行混合运算的一次基础操作;
尾处理单元,用于在控制单元的控制下,对经过预设轮数阈值迭代运算后的结果和未更新前的待加密信息进行加法运算,将结果作为随机数最为得到的随机数写入内存。
在一种示例性实例中,所述256位寄存器堆包括八个256bit寄存器SIMD_reg0至SIMD_reg7;其中,
SIMD_reg0用于保存所述第一基础块,SIMD_reg1用于保存所述第二基础块,SIMD_reg2用于保存所述第三基础块,SIMD_reg3用于保存所述第四基础块;
SIMD_reg4用于保存所述第一基础块,SIMD_reg5用于保存所述第二基础块,SIMD_reg6用于保存所述第三基础块,SIMD_reg7用于保存所述第四基础块。
在一种示例性实例中,所述尾处理单元中读取的未更新前的待加密信息为从所述256位寄存器堆中的SIMD_reg4至SIMD_reg7中读取的数据。
在一种示例性实例中,所述核心处理单元可以包括:迭代控制模块、第一处理模块、重排模块、第二处理模块;其中,
第一处理模块,用于在迭代处理模块的控制下,从所述256位寄存器堆中的SIMD_reg0至SIMD_reg3中读取的待加密信息,基于基础块和256位寄存器,完成流式对称加密算法中对块进行混合运算的一次基础操作;在一种实施例中,从256位寄存器堆中读取待加密信息为从;
重排模块,用于以块为单位,对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块,并更新预处理模块中的16个块;
第二处理模块,用于基于更新后的基础块和256位寄存器,完成流式对称加密算法中对重排后的块进行混合运算的一次基础操作。
在一种示例性实例中,所述迭代处理模块的控制用于:将预设轮数加一,并通知第一处理模块执行一次基础操作,直到轮数到达预设轮数阈值,将运算结果作为随机数。
本申请实施例又提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述随机数生成方法。
本申请实施例再提供一种计算机设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的随机数生成方法的步骤。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图概述
附图用来提供对本申请技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本申请的技术方案,并不构成对本申请技术方案的限制。
图1为相关技术中块的划分的示意图;
图2为本申请实施例中随机数生成方法的流程示意图;
图3为本申请实施例中块的划分的示意图;
图4为本申请实施例中对块进行重拍的示意图;
图5为本申请实施例中随机数生成装置的组成结构示意图;
图6为本申请实施例中第一处理模块中一次基础操作的过程实施例示意图;
图7为本申请实施例中尾处理模块加法过程的实施例示意图。
详述
为使本申请的目的、技术方案和优点更加清楚明白,下文中将结合附图对本申请的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
为了便于理解本申请,下面将参照相关附图对本申请进行更全面的描述。附图中给出了本申请的实施例。但是,本申请可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使本申请的公开内容更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本申请。
相关技术中的流式对称加密算法对64字节(byte)加密时,首先会将输入的64字节待加密信息分为16个块(block),每个块的排列索引如图1所示,每个块表示4个字节。在流式对称加密算法中,一次基础操作包括对4个块进行混合运算,每轮需要进行如下8个基础操作:
第一次基础操作:对block0,block4,block8,block12进行混合运算;
第二次基础操作:对block1,block5,block9,block13进行混合运算;
第三次基础操作:对block2,block6,block10,block14进行混合运算;
第四次基础操作:对block3,block7,block11,block15进行混合运算;
第五次基础操作:对block0,block5,block10,block15进行混合运算;
第六次基础操作:对block1,block6,block11,block12进行混合运算;
第七次基础操作:对block2,block7,block8,block13进行混合运算;
第八次基础操作:对block3,block4,block9,block14进行混合运算。
这样,一共需要运行多轮(轮数可以预先设置)后得到一个64字节的随机数。
每轮可以看作两段操作,第一段操作包括第一次基础操作到第四次基础操作,第二段操作包括第五次基础操作到第八次基础操作。
以第一次基础操作为例,一次4个块的混合运算可以包括如下运算:
block[0]=block[0]+block[4];
block[12]=ROL(block[12]^block[0],16),其中,ROL表示循环左移运算符,^表示异或运算符;
block[8]=block[8]+block[12];
block[4]=ROL(block[4]^block[8],12);
block[0]=block[0]+block[4];
block[12]=ROL(block[12]^block[0],8);
block[8]=block[8]+block[12];
block[4]=ROL(block[4]^block[8],7)。
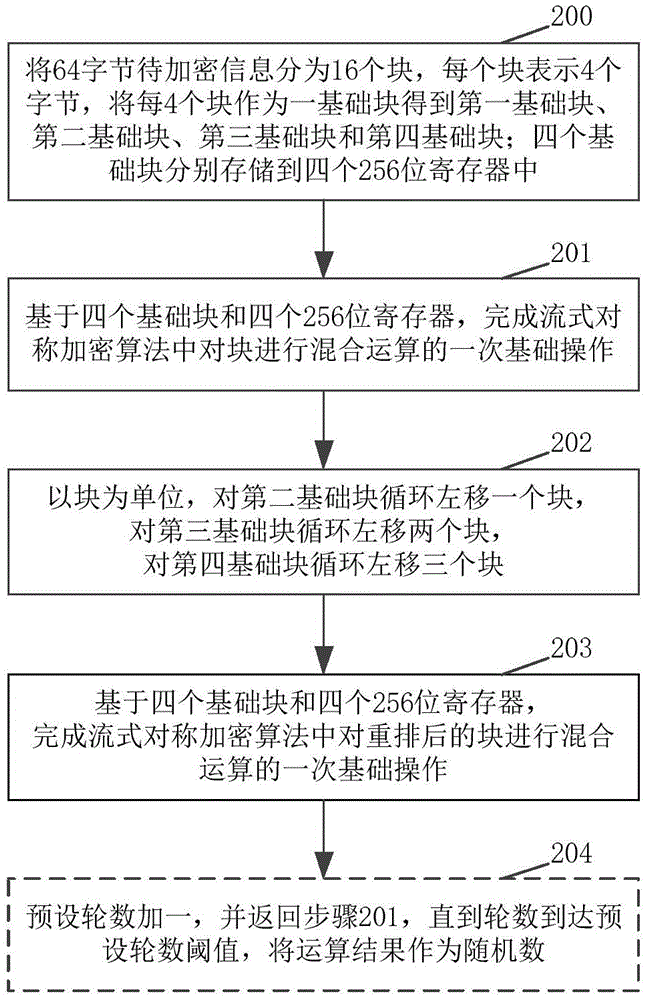
在对块进行混合运算的过程中,由于流式对称加密算法在对块运算时无需考虑进位操作,因此,第一次基础操作到第四次基础操作可以同时进行,在同时进行第一个基础操作即加法操作的过程中,流式在执行ZKP加密过程中会使得加密时间过长。为了降低运算量,提升随机数生成速度,从而缩短执行ZKP加密过程的时长,本申请实施例提出一种随机数生成方法。图2为本申请实施例中随机数生成方法的流程示意图,如图2所示,包括:
步骤200:将64字节待加密信息分为16个块,每个块表示4个字节,将每4个块作为一基础块得到第一基础块、第二基础块、第三基础块和第四基础块;四个基础块分别存储到四个256位寄存器中。
在一种示例性实例中,如果要处理的待加密信息为64字节,那么,步骤200中将该64字节的待加密信息分为16个块即可;如果要处理的待加密信息为128字节,那么,会先将该128字节的待加密信息分为2个64字节的待加密信息,然后每次按照本申请实施例提供的随机数生成方法处理64字节,然后再处理另一个64字节的待加密信息即可。也就是说,本申请实施例中的待加密信息会先分为一个或一个以上64字节的待加密信息,然后以64字节为单位,一个一个的处理即可。
在一种示例性实例中,如图3所示,将block0,block1,block2和block3作为第一基础块(如图3中斜线阴影所示),block4,block5,block6和block7作为第二基础块(如图3中竖线阴影所示),block8,block9,block10和block11作为第三基础块(如图3中菱形格阴影所示),block12,block13,block14和block15作为第四基础块(如图3中横线阴影所示)。
基于256位寄存器的场景,以RISC-V指令集架构为例,在第一个256位单指令多数据(SIMD,single-instruction multiple-data)寄存器(SIMD_reg1)中,保存第一基础块即block0,block1,block2和block3数据,第一操作数为block0,包括在256位SIMD_reg1的位[31:0]中,第二个操作数为block1,包括在256位SIMD_reg1的位[63:32]中,第三个操作数为block2,包括在256位SIMD_reg1的位[95:64]中,第四个操作数为block3,包括在SIMD_reg1的位[127:96]中。在第二个256位SIMD寄存器(SIMD_reg2)中,保存第二基础块即block4,block5,block6和block7数据,第一操作数为block4,包括在256位SIMD_reg2的位[31:0]中,第二个操作数为block5,包括在256位SIMD_reg2的位[63:32]中,第三个操作数为block6,包括在256位SIMD_reg2的位[95:64]中,第四个操作数为block7,包括在256位SIMD_reg2的位[127:96]中。在第三个256位SIMD寄存器(SIMD_reg3)中,保存第三基础块即block8,block9,block10和block11数据,第一操作数为block8,包括在256位SIMD_reg3的位[31:0]中,第二个操作数为block9,包括在256位SIMD_reg3的位[63:32]中,第三个操作数为block10,包括在256位SIMD_reg3的位[95:64]中,第四个操作数为block11,包括在256位SIMD_reg3的位[127:96]中。在第四个256位SIMD寄存器(SIMD_reg4)中,保存第四基础块即block12,block13,block14和block15数据,第一操作数为block12,包括在256位SIMD_reg4的位[31:0]中,第二个操作数为block13,包括在256位SIMD_reg4的位[63:32]中,第三个操作数为block14,包括在256位SIMD_reg4的位[95:64]中,第四个操作数为block15,包括在256位SIMD_reg4的位[127:96]中。其中,RISC-V是一种基于精简指令集(RISC)原则的开源指令集架构(ISA)。
步骤201:基于四个基础块和四个256位寄存器,完成流式对称加密算法中对块进行混合运算的一次基础操作。
本申请实施例中,由于每4个块作为一基础块,如图3所示,因此,基于256位寄存器,对块进行混合运算的第一次基础操作到第四次基础操作只需要一次基础操作即可完成,这样降低了运算量,提升了随机数生成速度,从而缩短执行ZKP加密过程的时长。以基础操作中的第一个基础操作即加法操作为例,本申请实施例在256位寄存器中,如下所示,只需做一次加法:
SIMD_reg1_block0=SIMD_reg1_block0+SIMD_reg2_block4,
SIMD_reg1_block1=SIMD_reg1_block1+SIMD_reg2_block5,
SIMD_reg1_block2=SIMD_reg1_block2+SIMD_reg2_block6,
SIMD_reg1_block3=SIMD_reg1_block3+SIMD_reg2_block7。
从图1和图3可以更为直观地看到,相关技术中,如图1所示,基于32位寄存器,第一次基础操作是对第一列进行的,第二次基础操作是对第二列进行的,第三次基础操作是对第三列进行的,第四次基础操作是对第四列进行的,四次基础操作是各自独立的。而本申请实施例中,如图3所示,基于256位寄存器,第一行的四个块是作为同一列中的一个元素,也就是第一行的四个块是一个基础块即第一基础块,同理,第二行的四个块是一个基础块即第二基础块,第三行的四个块是一个基础块即第三基础块,第四行的四个块是一个基础块即第四基础块,这样,由四个基础块构成一列,因此本申请实施例中仅对该由四个基础块构成的一列进行一次基础操作即可包括了相关技术中的四次基础操作。
也就是说,本申请实施例中,在加法、异或或第一循环左移操作时,基于256位寄存器均仅需要一次基础操作。
在一种示例性实例中,为了实现基于256位寄存器的混合运算,本申请实施例中设置用于混合运算的指令如下:
256位SIMD加法(SIMD256_ADD)指令,用于实现对两个256位SIMD寄存器的加法操作,其格式包括:SIMD256_ADD(S1,S2,R1),其中,S1表示参与加法运算的第一个256位SIMD寄存器,S2为参与加法运算的第二个256位SIMD寄存器。SIMD256_ADD(S1,S2,R1)用于实现R1=S1+S2。在一种实施例中,以256位SIMD_reg1和256位SIMD_reg2的加法操作为例,S1为SIMD_reg1(block0,block1,block2,block3),S2为SIMD_reg2(block4,block5,block6,block7),那么,R1=(S1_Block0+S2_Block4,S1_Block1+S2_Block5,S1_Block2+S2_Block6,S1_Block3+S2_Block7)。
256位SIMD异或(SIMD256_XOR)指令,用于实现对两个256位SIMD寄存器的异或操作,其格式包括:SIMD256_XOR(S1,S2,R1),其中,S1表示参与异或运算的第一个256位SIMD寄存器,S2为参与异或运算的第二个256位SIMD寄存器。SIMD256_XOR(S1,S2,R1)用于实现R1=S1^S2。在一种实施例中,以256位SIMD_reg1和256位SIMD_reg2的异或操作为例,S1为SIMD_reg1(block0,block1,block2,block3),S2为SIMD_reg2(block4,block5,block6,block7),那么,R1=(S1_Block0^S2_Block4,S1_Block1^S2_Block5,S1_Block2^S2_Block6,S1_Block3^S2_Block7)。
第一SIMD循环左移(SIMD256_32_ROL)指令,其格式包括:SIMD256_32_ROL(S,N1,R),其中,S表示执行循环左移运算的256位SIMD寄存器,N1表示循环左移的位数,SIMD256_32_ROL(S,N1,R)用于实现以32位为独立单元对S进行N1位循环左移后得到R。在本申请实施例中,N1=7、8、12、16,以对256位SIMD_reg1进行循环左移操作为例,S为SIMD_reg1(block0,block1,block2,block3),那么,R=(S1_Block0_ROL(N1),S1_Block1_ROL(N1),S1_Block2_ROL(N1),S1_Block3_ROL(N1))。
在一种示例性实例中,步骤201的执行可以包括:处理器执行SIMD256_ADD指令,SIMD256_ADD指令的结果用于执行SIMD256_XOR指令,SIMD256_XOR指令的结果用于执行SIMD256_32_ROL,这样,对基于256位寄存器,流式对称加密算法中基于输入的待加密信息的每行块即基础块执行上述算法,即可得到步骤201操作运算后的结果。
步骤202:以块为单位,对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块。
在一种示例性实例中,如图4所示,本步骤可以包括:
基于步骤201操作运算后的结果,步骤202执行下述重排运算,以实现block的重新排列:保持第一基础块不动,第二基础块的block5循环左移到block4处,第三基础块的block10循环左移到block8处,第四基础块的block15循环左移到block12处。
在一种示例性实例中,为了实现基于256位寄存器的block的重新排列,本申请实施例中设置用于block重新排列的指令如下:
第二SIMD循环左移(SIMD128_ROL)指令,其格式包括:SIMD128_ROL(S,N2,R),其中,S表示执行循环左移运算的256位SIMD寄存器,N2表示循环左移的位数,SIMD128_ROL(S,N2,R)用于实现对S进行128位的N2位循环左移后得到R。在本申请实施例中,N2=32、64、96。在一种实施例中,如图4所示,步骤202采用SIMD128_ROL指令实现可以包括:SIMD128_ROL(SIMD_reg2,32,R2),表示对图4上方的256位SIMD_reg2执行一次128位的32位循环左移操作,得到图4下方的256位SIMD_reg2;SIMD128_ROL(SIMD_reg3,64,R3),表示对图4上方的256位SIMD_reg3执行一次128位的64位循环左移操作,得到图4下方的256位SIMD_reg3;SIMD128_ROL(SIMD_reg4,96,R4),表示对对图4上方的256位SIMD_reg4执行一次128位的96位循环左移操作,得到图4下方的256位SIMD_reg4。
步骤203:基于四个基础块和四个256位寄存器,完成流式对称加密算法中对重排后的块进行混合运算的一次基础操作。
在一种示例性实例中,本步骤的具体实现如步骤201所述,这里不再赘述。需要说明的是,在经过步骤202的重排运算之后,相关技术中,基于32位寄存器,流式对称加密算法中的第五次基础操作到第八次基础操作中的block的对应形式转变成了第一次基础操作到第四次基础操作中的block的对应形式,因此,步骤203可以如步骤201,针对四个基础块构成的一列进行一次基础操作即可包括了相关技术中的第五次基础操作到第八次基础操作,这样,降低了运算量,提升了随机数生成速度,从而缩短执行ZKP加密过程的时长。
经过步骤203后即可获得流式对称加密算法中的随机数即对待加密信息的加密结果。
在一种示例性实例中,本申请实施例中的步骤201、步骤203中的对块进行混合运算,可以包括:
256位单指令多数据SIMD加法指令,用于实现对两个256位寄存器的加法操作;256位SIMD异或,用于实现对两个256位寄存器的异或操作,其中一个256位寄存器表示所述加法操作的结果;以及,第一SIMD循环左移指令,用于实现以32位为独立单元对表示所述异或操作的结果的256位SIMD寄存器进行N1位第一循环左移。
本申请实施例提供的随机数生成方法,基于256位寄存器,并在随机数产生过程中巧妙对块的重新排列,既保证了随机数的成功生成,同时降低了流式对称加密算法中对块的混合运算的运算量,提升了随机数生成速度,从而缩短执行ZKP加密过程的时长。
在一种示例性实例中,根据加密的需要,还可以预先设置加密的轮数即轮数阈值,这样,还可以包括:
步骤204:预设轮数加一,并返回步骤201,直到轮数到达预设轮数阈值;对经过预设轮数阈值迭代运算后的结果和未更新前的待加密信息进行加法运算,将运算结果作为随机数。
本申请实施例还提供一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行上述任一项所述随机数生成方法。
本申请实施例再一种计算机设备,包括存储器和处理器,其中,存储器中存储有以下可被处理器执行的指令:用于执行上述任一项所述的随机数生成方法的步骤。
图5为本申请实施例中随机数生成装置的组成结构示意图,如图5所示,至少包括:控制单元、预处理单元、256位寄存器堆、迭代处理单元,以及尾处理单元;其中,
预处理模块,用于在控制单元的控制下,从内存中读取数据,对读取的数据进行如下预处理后存入256位寄存器堆,其中,在256位寄存器堆中存储两份预处理后的结果:将64字节待加密信息分为16个块,每个块表示4个字节,将每4个块作为一基础块得到第一基础块、第二基础块、第三基础块和第四基础块;所述四个基础块分别存储到四个256位寄存器中;
核心处理单元,用于在迭代处理模块的控制下执行如下预设轮数迭代运算:从256位寄存器堆中读取待加密信息,基于四个基础块和四个256位寄存器,完成流式对称加密算法中对块进行混合运算的一次基础操作;以块为单位,对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块,并更新256位寄存器堆中待加密信息对应的16个块;基于更新后的四个基础块和四个256位寄存器,完成流式对称加密算法中对重排后的块进行混合运算的一次基础操作;
尾处理单元,用于在控制单元的控制下,对经过预设轮数阈值迭代运算后的结果和未更新前的待加密信息进行加法运算,将结果作为随机数最为得到的随机数写入内存。
本申请实施例中,在计算过程中,核心处理单元直接从256位寄存器堆中调取数据,无需访问内存操作。
在一种示例性实例中,256位寄存器堆中的SIMD_reg0至SIMD_reg7均为256bit寄存器,其中,SIMD_reg0至SIMD_reg3和SIMD_reg4至SIMD_reg7存储相同的数据,也就是说,预处理后的待加密信息在256位寄存器堆中会存储两份。以图3所示为例,SIMD_reg0保存第一基础块即block0,block1,block2和block3;SIMD_reg1保存第二基础块即block4,block5,block6和block7;SIMD_reg2保存第三基础块即block8,block9,block10和block11;SIMD_reg3保存第四基础块即block12,block13,block14和block15;SIMD_reg4保存第一基础块,SIMD_reg5保存第二基础块,SIMD_reg6保存第三基础块,SIMD_reg7保存第四基础块。
在一种示例性实例中,核心处理单元可以包括:迭代控制模块、第一处理模块、重排模块、第二处理模块;其中,
第一处理模块,用于在迭代处理模块的控制下,从256位寄存器堆中读取待加密信息,基于基础块和256位寄存器,完成流式对称加密算法中对块进行混合运算的一次基础操作;在一种实施例中,从256位寄存器堆中读取待加密信息为从256位寄存器堆中的SIMD_reg0至SIMD_reg3中读取的数据;
重排模块,用于以块为单位,对第二基础块循环左移一个块,对第三基础块循环左移两个块,对第四基础块循环左移三个块,并更新预处理模块中的16个块;
第二处理模块,用于基于更新后的基础块和256位寄存器,完成流式对称加密算法中对重排后的块进行混合运算的一次基础操作。
在一种示例性实例中,迭代处理模块的控制用于:将预设轮数加一,并通知第一处理模块执行一次基础操作,直到轮数到达预设轮数阈值,将运算结果作为随机数。
在一种示例性实例中,尾处理单元中读取的未更新前的待加密信息为从256位寄存器堆中的SIMD_reg4至SIMD_reg7中读取的数据。
本申请实施例提供的随机数生成装置,基于256位寄存器,并在随机数产生过程中巧妙对块的重新排列,既保证了随机数的成功生成,同时降低了流式对称加密算法中对块的混合运算的运算量,提升了随机数生成速度,从而缩短执行ZKP加密过程的时长。
在一种示例性实例中,图6展示了第一处理模块中一次基础操作的过程实施例示意图,图6中,a表示第一基础块,b表示第二基础块,c表示第三基础块,d表示第四基础块,如图6所示,一次基础操作的混合运算可以包括:
block[a]=block[a]+block[b];其中,+表示256位SIMD加法(SIMD256_ADD)指令;
block[d]=ROL(block[d]^block[a],16),其中,ROL表示第一SIMD循环左移(SIMD256_32_ROL)指令,^表示256位SIMD异或(SIMD256_XOR)指令;
block[c]=block[c]+block[12];
block[b]=ROL(block[b]^block[8],12);
block[a]=block[a]+block[b];
block[d]=ROL(block[d]^block[a],8);
block[c]=block[c]+block[d];
block[b]=ROL(block[b]^block[c],7)。
在一种示例性实例中,图7展示了尾处理模块加法过程实施例示意图,图7中,a表示原始的第一基础块,b表示原始的第二基础块,c表示原始的第三基础块,d表示原始的第四基础块;a′表示经过核心处理单元的预设轮数阈值迭代后的第一基础块,b′表示经过核心处理单元的预设轮数阈值迭代后的第二基础块,c′表示经过核心处理单元的预设轮数阈值迭代后的第三基础块,d′表示经过核心处理单元的预设轮数阈值迭代后的第四基础块。如图7中所示,经过预设轮数阈值迭代运算后的结果和原始的(即未更新前的)待加密信息进行加法运算,所得结果作为随机数,如图7中的结果第一基础块、结果第二基础块、结果第三基础块和结果第四基础块。
虽然本申请所揭露的实施方式如上,但所述的内容仅为便于理解本申请而采用的实施方式,并非用以限定本申请。任何本申请所属领域内的技术人员,在不脱离本申请所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本申请的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 图像处理方法和装置、电子设备、存储介质、程序产品
- 图像处理方法和装置、电子设备、存储介质、程序产品
- 目标检测方法和装置、电子设备、存储介质、程序产品
- 行人再识别方法和装置、电子设备、存储介质、程序产品
- 图像处理方法和装置、电子设备、存储介质、程序产品
- 业务系统高峰保障方法、装置、设备、介质和程序产品
- 业务处理方法、系统、装置、设备、存储介质及程序产品