一种基于GPU端加速的粒子群优化方法、系统、设备及介质
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及智能进化领域中的群智能算法技术领域,具体涉及一种基于GPU端加速的粒子群优化方法、系统、设备及介质。
背景技术
粒子群优化(particle swarm optimization,PSO)算法于1995年由J.Kennedy和R.C.Eberhart提出,它是一种利用种群智能建立的随机优化模型,它具有算法实现简单、调整参数少、容易收敛、稳定性高等特点。但是,在面对大规模、高复杂的循环优化问题时,由于在循环优化中反复初始化算法导致初始化时间的叠加,使得算法整体的寻优效率十分低下,收敛速度也会大幅下降。
伴随着GPU并行计算能力的快速提升和通用并行计算架构(Compute UnifiedDevice Architecture,CUDA)的开发和适用,很多应用程序已经开始利用GPU的可用性、并行性、统一计算的特点来减少程序本身的执行时间。又基于PSO算法固有的可并发的特点,于是如何利用GPU来加速PSO算法以获得较高的加速比,一直以来都是算法研究者们的研究热点。
使用CUDA编程模型来实现CPU+GPU这种异构计算架构,对于实现大量数据的并行计算有很大的优势。蔡勇等人在论文《基于CUDA的并行粒子群优化算法的设计与实现》中根据PSO算法的本质并行性,将粒子个体与CUDA线程一一对应,在求解收敛性一致的前提下,他们设计的基于CUDA架构的并行PSO求解方法取得了90倍的计算加速比。在此之后,基于CUDA的PSO算法加速比就达到了一个瓶颈,始终无法有更高的突破。究其原因,主要在于所设计的算法难以充分调度CPU与GPU资源,另外数据IO与GPU端的众多线程管理均造成大量开销。
发明内容
针对上述背景技术中存在的技术问题,本发明的目的在于提供一种基于GPU端加速的粒子群优化方法、系统、设备及介质,基于传统PSO算法的异步模型,把各个粒子的循环迭代行为作为一个独立的寻优过程,采用粗粒度并行的方式使粒子与线程一一对应,同时粒子内部对每个维度的顺序计算由线程复用来优化,利用了PSO算法所具有的并发特点,在GPU端初始化的方式来最大化数据吞吐量,减少不必要的数据IO以优化内存使用;并设计了一种包括线程自适应和线程复用模块的线程调度方式,以充分利用GPU端多核并行的优势来优化线程使用。
为了达到上述目的,本发明采用以下技术方案实现:
一种基于GPU端加速的粒子群优化方法,包括以下步骤:
S1、CPU端进行必要变量的初始化,其余数据的初始化迁移到GPU端进行;
S2、CPU端根据问题规模和粒子群规模自适应地调整执行参数,给核函数1和核函数2分配线程资源;
S3、CPU端调用核函数1在GPU端初始化粒子群,得到粒子的初始速度和位置,并计算出粒子个体历史最优和全局最优;
S4、CPU端调用核函数2在GPU端更新粒子的速度和位置,计算粒子的适应值,并通过比较得出粒子个体历史最优和全局最优;
S5、GPU端在满足结束条件前,循环步骤S4;
S6、GPU端终止循环,并将全局最优解拷贝至CPU端。
所述的步骤S1中必要变量的初始化,必要变量包括群维度和粒子数,初始化后将它们拷贝至GPU;其余数据包括粒子的速度、位置和适应值,需要先在CPU端创建相应的空数组再拷贝至GPU,然后在GPU端对它们执行具体的赋值初始化操作。
所述的步骤S2,具体为:在CPU端调用
kernel<<
Kernel(GridDim,BlockDim)=Kernel((S/N/BlockDim,N),(n,WarpSiz
e))
式中,GridDim为网格大小,即其中所含线程块数;BlockDim为线程块大小,即其中所含线程数;S表示粒子规模,即粒子数;N表示问题规模,即求解问题的维度;WarpSize表示一个warp的大小;通过自适应调整n的大小,尽可能扩大每个Block中的线程数,将BlockDim设置为warp的倍数。
所述的步骤S3中,CPU端调用核函数kernel1()在GPU端初始化粒子群相关变量,包括各粒子的初始速度和初始位置,并根据所给问题函数自动求解粒子个体初始最优和全局最优;问题函数如下:
式中,f1为问题函数Rosenbrock的求解公式;f2为问题函数Sphere的求解公式;f3为问题函数Rastrigrin的求解公式;f4为问题函数Griewangk的求解公式,X
所述的步骤S4中,CPU端调用核函数kernel2()在GPU端更新粒子的速度和位置,根据所给问题函数计算粒子新的适应值,基于以下公式更新粒子的速度和位置:
式中,i=1,2,…,M;d=1,2,…,N。
所述的步骤S4中,更新粒子的速度和位置的过程需要在GPU端反复创建线程来实现,采取网格跨步的方法来实现线程复用,即在每一个线程中添加循环,使得一个被创建出来的线程可以重复使用。
所述的步骤S5中,结束条件为达到指定迭代次数或者指定精度。
一种基于GPU端加速的粒子群优化系统,包括用于执行上述一种基于GPU端加速的粒子群优化方法中各个步骤的处理指令模块。
一种基于GPU端加速的粒子群优化设备,包括存储器和处理器;
存储器:存储上述一种基于GPU端加速的粒子群优化方法的计算机程序,为计算机可读取的设备;
处理器:用于执行所述的一种基于GPU端加速的粒子群优化方法。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时能够实现所述的一种基于GPU端加速的粒子群优化方法。
与现有技术相比,本发明具有如下创新点:
(1)本发明步骤S1只将必要的变量初始化,而其余数据的初始化迁移到GPU端进行。这样的方式能够保证数据在初始与后续的迭代以及比较过程中的所有运算都由GPU核心承担,大大节省了IO资源。特别是当问题规模达到百万甚至更大级别时,在GPU端初始化可以有效提高PSO算法的运行速度;
(2)本发明步骤S2增加了线程自适应模块,这种自适应策略让核函数在设定执行参数时通过尽可能扩大每个Block中的线程数,并把Block大小设置Warp的倍数,同时考虑到问题规模和粒子规模的大小,动态调整与之相匹配的线程数量,避免了GPU上内存资源的浪费,提高了程序性能;
(3)本发明步骤S4中,粒子群的循环迭代过程中采用网格跨步来提高GPU中线程的复用率。该策略通过在线程中添加循环来实现,以使每个线程可以被多次利用。减少了线程重复启动和销毁的开销,扩大了CUDA并行处理问题的规模。
附图说明
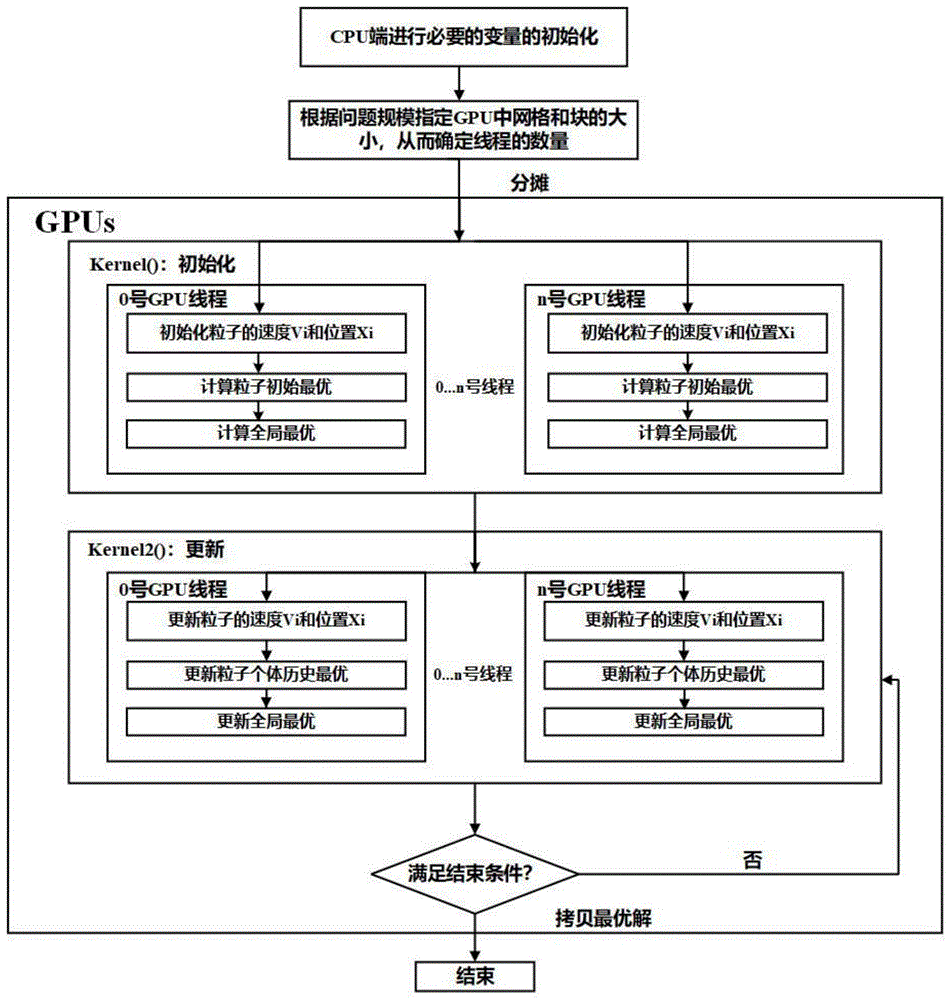
图1为本发明方法的流程图。
图2为在CPU端和GPU端初始化不同数量粒子群进行一次IO所需的时间对比图。
图3为线程通过网格跨步实现复用的示意图。
图4为Rosenbrock函数等粒子数等迭代次数的运行时间对比图。
图5为Sphere函数等粒子数等迭代次数的运行时间对比图。
图6为Rastrigrin函数等粒子数等迭代次数的运行时间对比图。
图7为Griewangk函数等粒子数等迭代次数的运行时间对比图。
图8为四个基准测试函数的加速比对比图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
如图1所示,为本发明算法的流程图,具体步骤如下:
S1、CPU端进行必要变量的初始化,其余数据的初始化工作迁移到GPU端进行;
所述的步骤S1中必要变量的初始化,必要变量包括群维度和粒子数,初始化后将它们拷贝至GPU;其余数据包括粒子的速度、位置和适应值,需要先在CPU端创建相应的空数组再拷贝至GPU,然后在GPU端对它们执行具体的赋值初始化操作。
当数据被初始化时,常规的做法是在CPU端执行初始化操作,随后将数据拷贝至GPU端进行后续计算,然而这个常规的IO过程会耗费大量的无效时间。经实验测试,如图2所示,横轴为问题规模,纵轴为初始化所需时间,当问题规模达到百万级别时,平均一次IO操作会造成至少6秒的时间损耗,这大大降低了算法的执行效率。因此本方法考虑只在CPU端进行必要变量的初始化,而将其余大量数据的初始化工作迁移到GPU端进行。
S2、CPU端根据问题规模和粒子群规模自适应地调整执行参数,以给核函数1和核函数2分配恰当的线程资源;
在CPU端调用kernel<<
自适应过程公式如下:
Kernel(GridDim,BlockDim)=Kernel((S/N/BlockDim,N),(n,WarpSiz
e))
式中,GridDim为网格大小,即其中所含线程块数;BlockDim为线程块大小,即其中所含线程数,通常一个Block最多可包含1024个线程,但考虑到当Block中线程数使用太多可能会导致拥堵使效率降低,这里限制BlockDim最大为512。S表示粒子规模,即粒子数;N表示问题规模,即求解问题的维度。WarpSize表示一个warp的大小,通常GPU以HalfWarp为单位计算,所以这里将WarpSize定义为16。通过自适应调整n的大小,尽可能扩大每个Block中的线程数,将BlockDim设置为warp的倍数。
S3、CPU端调用核函数Kernel1()在GPU端初始化粒子群,得到粒子的初始速度Vi和位置Xi(i=0,1,...,n),并根据所给问题函数计算出粒子个体初始最优Fi和全局最优Fgb;
本实施例中选用以下四个基本测试函数来验证加速效果:
式中,f1为问题函数Rosenbrock的求解公式;f2为问题函数Sphere的求解公式;f3为问题函数Rastrigrin的求解公式;f4为问题函数Griewangk的求解公式。X
S4、CPU端调用核函数Kernel2()在GPU端更新粒子的速度Vi和位置Xi(i=0,1,...,n),根据所给问题函数计算粒子的适应值Fitness,并通过比较得出粒子个体历史最优Fi和全局最优Fgb;
基于以下公式更新粒子的速度Vi和位置Xi:
式中,i=1,2,…,M;d=1,2,…,N。
所述的步骤S4中,粒子循环更新速度和位置的过程需要在GPU端反复创建线程来实现。为了节省线程反复创建和销毁产生的开销,在基于GPU端CUDA编程模型的基础上采取网格跨步的方法来实现线程复用,即在每一个线程中添加循环,使得一个被创建出来的线程可以重复使用。
图3为网格跨步示意图,图中要并行处理的数据大小为12,创建一个可以并行启动4<<<2,2>>>个线程的网格,添加循环后,跨步大小设置为网格中的线程总数4,就可以在1号线程中,处理第1、5、9号数据。
S5、GPU端在满足结束条件前,循环步骤S4;结束条件为达到指定迭代次数或者指定精度;
S6、GPU端终止循环,并将全局最优解拷贝至CPU端。所述的步骤S6中,通过记录整个程序运行所消耗的时间,并与传统CPU和GPU上粒子群算法运行的时间相比,来作为评价本方法加速程度的指标。
效果对比
以下通过测试传统GPU-PSO算法和本发明方法的运行时间,并基于以下两种评价指标来评价本方法的加速程度:
(1)等粒子数等迭代次数的加速比:当粒子数相同时,不同算法程序上循环结束的条件均为达到相同指定迭代次数,定义此时参考算法程序和目标算法程序的运行时间比为:
评价指标(1)忽略了优化求解过程中函数收敛精度的差异,这可能会导致实验中出现一方停止迭代而另一方仍在运行的情况,这时得到的加速比在某种程度上是靠使CPU程序性能下降而获得的,是不真实的加速比。因此提出评价指标(2)。
(2)函数收敛后的加速比:不同算法程序上循环结束的条件均为函数收敛到相同指定迭代精度,定义此时参考算法程序和目标算法程序的最小运行时间比为:
实验结果如下:
(1)采用评价指标(1),设定初始粒子数为128,初始迭代次数为10000,四个基准测试函数的维度N均为16。在实验中,通过增加
粒子数和随之动态减少迭代次数来减少CPU端的执行时间。最终结果如下表1-4,图4-7所示。
Rosenbrock函数的S
Sphere函数的S
Rastrigrin函数的S
Griewangk函数的S
四个基准函数的等粒子数等迭代次数加速比如图8。
与CPU-PSO相比,本发明方法在Rosenbrock、Sphere、Rastrigrin和Griewangk上最大分别取得了583.6、225.4、158.3和147.2的等粒子数等迭代次数的加速比。
与传统GPU-PSO相比,本发明方法在Rosenbrock、Sphere、Rastrigrin和Griewangk上最大分别取得了6.68、5.06、3.88和3.42的等粒子数等迭代次数的加速比。
分析实验结果可知,在几个测试函数中,本发明方法在复杂函数Rosenbrock中取得了最好的等粒子数等迭代次数的加速比。与CPU-PSO算法相比,它的性能提高了至少580倍;与GPU-PSO算法相比,它的性能提高了至少6倍。可以证明本发明方法具有更好的优化效果,且函数越复杂,问题维度越大,优化效果越好。
(2)采用评价指标(2),设定四个基准测试函数的维度N均为16。最终结果如下表5所示。
分析实验结果可知,本发明方法在四个基准测试函数上最大分别取得了3.81、2.67、2.34和2.01的以函数收敛到指定精度为迭代结束条件的加速比。以上指标能更客观的反映本发明方法效率的提升。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 一种基于GPU加速连续粒子群优化的三维物体跟踪方法
- 基于GPU加速水平集进行逆光刻掩膜优化的方法、计算机系统及介质