生成式大模型训练方法、基于模型的人机协同交互方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及人工智能技术领域,特别涉及生成式大模型训练方法、基于模型的人机协同交互方法。
背景技术
大型语言模型(LLM,LargeLanguageModel,其本质是生成式模型,因此也可以被简称为:生成式大模型,本公开后续将统一此表述来指代此类模型),如ChatGPT(ChatGenerativePre trainedTransformer,是OpenAI机构研发的聊天机器人程序),能够为许多下游任务(例如面向任务的对话和问题解答)生成类似人类的流畅响应。然而,将LLM应用于现实世界中的任务解决型应用仍然具有挑战性,其在对话过程中无法模仿他人的对话速度,不同的人适应语速程度不同,不能满足较好的对话体验感。
发明内容
本申请的目的在于提供生成式大模型训练方法、基于模型的人机协同交互方法,以解决上述背景技术中提出的问题。
为实现上述目的,本申请提供如下技术方案:生成式大模型训练方法、基于模型的人机协同交互方法,包括获取智能对话中的问答语句;
基于预先训练的语速分类器,对所述智能对话中的用户的问答语句通过语速分类器进行速度标记,得到具有语句速度标签的问答语句,形成第一训练集;
利用第一训练集对预先训练好的第一生成式大模型进行监督微调训练,得到第二生成式大模型;
语速分类器,其对问答的语句进行语速分类,对不同的语速标签的问答语句进行编码,并将编码存储至编码存储数据库里,利用预训练好的第三生成式大模型调取编码存储数据库编码数据进行有监督训练;
提取用户对话语句中问题中的关键词及对应的回答中的关键词、回答的语速,以及提取对应的上下文信息,根据提取的关键词和上下文信息,生成预测模型,其包括第一生成单元和第二生成单元;
第一生成单元,用于当接收到对话生成请求时,将请求生成对话的问题语句输入至所述对话控制模型中的编码部分,得到上下文语义编码;第二生成单元,用于将请求生成对话的语速分类标签以及所述上下文语义编码共同输入至对话控制模型中的解码部分,得到与所述语速分类标签相匹配回答语句表示,组成后输出相应的回答语句。
优选的,在所述基于预先训练的语速分类器,对所述智能对话中的问答语料进行语速标记,得到携带有语速标签的问答语料之前,所述方法还包括:对所述智能对话中的问答语料进行编码,得到未知语速的问答向量,得到第一训练集;所述基于预先训练的语速分类器,对所述智能对话中的问答语料进行语速标记,得到携带有语速标签的问答语料。
优选的,根据所述用户输入语音和匹配的输出结果生成新人机对话序列;将所述新人机对话序列中的首项用户输入语音和首项输出结果作为起始样本对;将所述新人机对话序列中位于非首项输出结果前的所有对话内容和所述非首项输出结果作为非起始样本对;基于包含所述起始样本对和所述非起始样本,构建所述第一训练集。
优选的,还包括,提取人类对话语句中问题中的关键词及对应的回答中的关键词,根据提取的关键词生成映射关系,根据所述映射关系生成预测模型。
优选的,对还包括所述预测模型的输出答复进行匹配度排序,根据所述候选回答的匹配度大小对每个所述候选回答进行排序,得到初始排序结果;根据预设的处理规则对所述初始排序结果进行顺序调整,得到所述候选回答的最终排序结果;其中,所述预设的处理规则包括以下中的一种或多种:候选回答的来源优先级、候选回答的长度、候选回答与对话问题的重复度、候选回答的来源占比、候选回答中包含的词语序列的联合概率。
优选的,所述候选回答中的候选回答包括至少一个检索回答和/或至少一个生成回答。
综上,本发明的技术效果和优点:
本发明中,通过对用户的语速变化进行实施的识别并通过预测模型进行预测语速和语义,将语速和语义结合出来进行输出,这样便可以针对不同人进行不同语速的对话交流,提高用户的体验感。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅是本申请的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
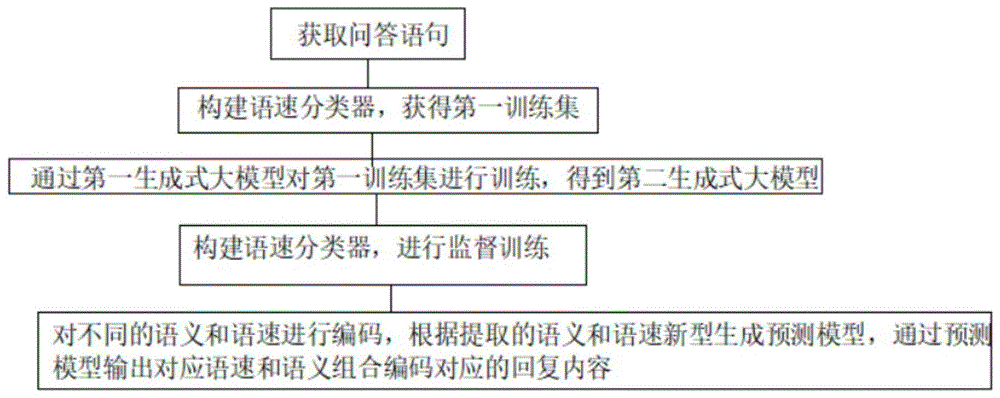
图1为本申请实施例中生成式大模型训练方法、基于模型的人机协同交互方法的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本公开的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”、“顶部”、“底部”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本公开和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本公开的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
还需要说明的是,本申请文件中使用到的标准零件均可以从市场上购买,而且根据说明书和附图的记载均可以进行订制。除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本公开中的具体含义,并且,未做明确限定的情况下,机械、零件和设备均可以采用现有技术中常规的型号。
在本文中,术语“包括”意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
实施例:参考图1所示的生成式大模型训练方法、基于模型的人机协同交互方法,包括获取智能对话中的问答语句;
基于预先训练的语速分类器,对所述智能对话中的用户的问答语句通过语速分类器进行速度标记,得到具有语句速度标签的问答语句,形成第一训练集;
利用第一训练集对预先训练好的第一生成式大模型进行监督微调训练,得到第二生成式大模型;
语速分类器,其对问答的语句进行语速分类,对不同的语速标签的问答语句进行编码,并将编码存储至编码存储数据库里,利用预训练好的第三生成式大模型调取编码存储数据库编码数据进行有监督训练;
提取用户对话语句中问题中的关键词及对应的回答中的关键词、回答的语速,以及提取对应的上下文信息,根据提取的关键词和上下文信息,生成预测模型,其包括第一生成单元和第二生成单元;
第一生成单元,用于当接收到对话生成请求时,将请求生成对话的问题语句输入至所述对话控制模型中的编码部分,得到上下文语义编码;第二生成单元,用于将请求生成对话的语速分类标签以及所述上下文语义编码共同输入至对话控制模型中的解码部分,得到与所述语速分类标签相匹配回答语句表示,组成后输出相应的回答语句。
进一步实施的,在所述基于预先训练的语速分类器,对所述智能对话中的问答语料进行语速标记,得到携带有语速标签的问答语料之前,所述方法还包括:对所述智能对话中的问答语料进行编码,得到未知语速的问答向量,得到第一训练集;所述基于预先训练的语速分类器,对所述智能对话中的问答语料进行语速标记,得到携带有语速标签的问答语料。
进一步实施的,根据所述用户输入语音和匹配的输出结果生成新人机对话序列;将所述新人机对话序列中的首项用户输入语音和首项输出结果作为起始样本对;将所述新人机对话序列中位于非首项输出结果前的所有对话内容和所述非首项输出结果作为非起始样本对;基于包含所述起始样本对和所述非起始样本,构建所述第一训练集。
进一步实施的,还包括,提取人类对话语句中问题中的关键词及对应的回答中的关键词,根据提取的关键词生成映射关系,根据所述映射关系生成预测模型。
进一步实施的,对还包括所述预测模型的输出答复进行匹配度排序,根据所述候选回答的匹配度大小对每个所述候选回答进行排序,得到初始排序结果;根据预设的处理规则对所述初始排序结果进行顺序调整,得到所述候选回答的最终排序结果;其中,所述预设的处理规则包括以下中的一种或多种:候选回答的来源优先级、候选回答的长度、候选回答与对话问题的重复度、候选回答的来源占比、候选回答中包含的词语序列的联合概率。
进一步实施的,所述候选回答中的候选回答包括至少一个检索回答和/或至少一个生成回答。
最后应说明的是:以上仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 生成式大模型训练方法、基于模型的人机语音交互方法
- 一种生成式模型训练方法、信息交互方法及其装置