学习装置、推理装置、程序、学习方法和推理方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及学习装置、推理装置、程序、学习方法和推理方法。
背景技术
以往,为了进行自然语言的常识推理处理,存在使用深度学习来计算推理的似然度的方式(例如参照专利文献1)。
现有技术文献
专利文献
专利文献1:美国专利第10452978号说明书
发明内容
发明要解决的课题
但是,在现有技术中,将单词的意思作为依赖于上下文的分散表现来进行维度压缩,因此,计算量庞大。
因此,本发明的一个或多个方式的目的在于,能够以较少的计算量进行模型的学习和推理。
用于解决课题的手段
本发明的第一方式的学习装置的特征在于,所述学习装置具有:词素分析执行部,其对多个字符串执行词素分析,由此确定所述多个字符串中包含的多个单词的词性;确定部,其根据所确定的所述词性,确定从所述多个字符串中选择出的多个单词即多个对象词的序列;以及生成部,其计算语料库中的所述序列的自互信息量即序列自互信息量,进行所述序列和所述序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。
本发明的第二方式的学习装置的特征在于,所述学习装置具有:词素分析执行部,其对由构成提问句的字符串和构成针对所述提问句的回答句的多个字符串构成的第一多个字符串执行词素分析,由此确定所述第一多个字符串中包含的多个单词的词性,并且,对构成针对所述提问句的回答句的多个字符串即第二多个字符串执行词素分析,由此确定所述第二多个字符串中包含的多个单词的词性;确定部,其根据基于所述第一多个字符串确定的所述词性确定从所述第一多个字符串中选择出的多个单词即第一多个对象词的组合,并且,根据基于所述第二多个字符串确定的所述词性确定从所述第二多个字符串中选择出的多个单词即第二多个对象词的序列;以及生成部,其计算语料库中的所述组合的自互信息量即组合自互信息量,进行所述组合和所述组合自互信息量的学习,由此生成作为已学习模型的组合自互信息量模型,并且,计算语料库中的所述序列的自互信息量即序列自互信息量,进行所述序列和所述序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。
本发明的第一方式的推理装置参照序列自互信息量模型进行推理,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,其特征在于,所述推理装置具有:取得部,其取得2以上的数量作为针对提问句的回答的步骤数;步骤句生成部,其从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句;词素分析执行部,其对所述多个步骤句分别执行词素分析,由此确定所述多个步骤句中分别包含的多个单词的词性;以及推理部,其根据所确定的所述词性确定从所述多个步骤句中分别选择出的多个单词即多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述多个步骤句各自的似然度即排序用似然度。
本发明的第二方式的推理装置参照组合自互信息量模型和序列自互信息量模型进行推理,该组合自互信息量模型是根据预定的词性的多个单词的组合和语料库中的所述组合的自互信息量即组合自互信息量进行学习后的已学习模型,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,其特征在于,所述推理装置具有:取得部,其取得2以上的数量作为提问句和针对所述提问句的回答的步骤数;步骤句生成部,其从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,在所述多个步骤句各自之前连结所述提问句,由此生成多个带提问的步骤句;词素分析执行部,其对所述多个带提问的步骤句分别执行词素分析,由此确定所述多个带提问的步骤句中分别包含的多个单词的词性;以及推理部,其根据所确定的所述词性确定从所述多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合,参照所述组合自互信息量模型确定所确定的所述组合的似然度,由此确定所述多个步骤句各自的似然度即第一似然度,从使用所述第一似然度筛选所述多个步骤句而提取出的多个带提问的步骤句中去除所述提问句,由此生成多个对象步骤句,根据所确定的所述词性确定从所述多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述多个步骤句各自的似然度即排序用似然度。
本发明的第三方式的推理装置参照组合自互信息量模型、序列自互信息量模型和对象已学习模型进行推理,该组合自互信息量模型是根据预定的词性的多个单词的组合和语料库中的所述组合的自互信息量即组合自互信息量进行学习后的已学习模型,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,该对象已学习模型是与所述组合自互信息量模型和所述序列自互信息量模型不同的已学习模型,其特征在于,所述推理装置具有:取得部,其取得2以上的数量作为提问句和针对所述提问句的回答的步骤数;步骤句生成部,其从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,在所述多个步骤句各自之前连结所述提问句,由此生成多个带提问的步骤句;词素分析执行部,其对所述多个带提问的步骤句分别执行词素分析,由此确定所述多个带提问的步骤句中分别包含的多个单词的词性;第一推理部,其根据所确定的所述词性确定从所述多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合,参照所述组合自互信息量模型确定所确定的所述组合的似然度,由此确定所述多个步骤句各自的似然度即第一似然度,从使用所述第一似然度筛选所述多个步骤句而提取出的多个带提问的步骤句中去除所述提问句,由此生成第一多个对象步骤句,根据所确定的所述词性确定从所述第一多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述第一多个对象步骤句各自的似然度即第二似然度,使用所述第二似然度筛选所述第一多个对象步骤句,由此提取第二多个对象步骤句;以及第二推理部,其参照所述对象已学习模型确定所述第二多个对象步骤句各自的似然度即排序用似然度。
本发明的第一方式的程序的特征在于,所述程序使计算机作为以下部分发挥功能:词素分析执行部,其对多个字符串执行词素分析,由此确定所述多个字符串中包含的多个单词的词性;确定部,其根据所确定的所述词性,确定从所述多个字符串中选择出的多个单词即多个对象词的序列;以及生成部,其计算语料库中的所述序列的自互信息量即序列自互信息量,进行所述序列和所述序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。
本发明的第二方式的程序的特征在于,所述程序使计算机作为以下部分发挥功能:词素分析执行部,其对由构成提问句的字符串和构成针对所述提问句的回答句的多个字符串构成的第一多个字符串执行词素分析,由此确定所述第一多个字符串中包含的多个单词的词性,并且,对构成针对所述提问句的回答句的多个字符串即第二多个字符串执行词素分析,由此确定所述第二多个字符串中包含的多个单词的词性;确定部,其根据基于所述第一多个字符串确定的所述词性确定从所述第一多个字符串中选择出的多个单词即第一多个对象词的组合,并且,根据基于所述第二多个字符串确定的所述词性确定从所述第二多个字符串中选择出的多个单词即第二多个对象词的序列;以及生成部,其计算语料库中的所述组合的自互信息量即组合自互信息量,进行所述组合和所述组合自互信息量的学习,由此生成作为已学习模型的组合自互信息量模型,并且,计算语料库中的所述序列的自互信息量即序列自互信息量,进行所述序列和所述序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。
本发明的第三方式的程序使计算机作为推理装置发挥功能,该推理装置参照序列自互信息量模型进行推理,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,其特征在于,所述程序使所述计算机作为以下部分发挥功能:取得部,其取得2以上的数量作为针对提问句的回答的步骤数;步骤句生成部,其从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句;词素分析执行部,其对所述多个步骤句分别执行词素分析,由此确定所述多个步骤句中分别包含的多个单词的词性;以及推理部,其根据所确定的所述词性确定从所述多个步骤句中分别选择出的多个单词即多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述多个步骤句各自的似然度即排序用似然度。
本发明的第四的方式的程序使计算机作为推理装置发挥功能,该推理装置参照组合自互信息量模型和序列自互信息量模型进行推理,该组合自互信息量模型是根据预定的词性的多个单词的组合和语料库中的所述组合的自互信息量即组合自互信息量进行学习后的已学习模型,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,其特征在于,所述程序使所述计算机作为以下部分发挥功能:取得部,其取得2以上的数量作为提问句和针对所述提问句的回答的步骤数;步骤句生成部,其从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,在所述多个步骤句各自之前连结所述提问句,由此生成多个带提问的步骤句;词素分析执行部,其对所述多个带提问的步骤句分别执行词素分析,由此确定所述多个带提问的步骤句中分别包含的多个单词的词性;以及推理部,其根据所确定的所述词性确定从所述多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合,参照所述组合自互信息量模型确定所确定的所述组合的似然度,由此确定所述多个步骤句各自的似然度即第一似然度,从使用所述第一似然度筛选所述多个步骤句而提取出的多个带提问的步骤句中去除所述提问句,由此生成多个对象步骤句,根据所确定的所述词性确定从所述多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述多个步骤句各自的似然度即排序用似然度。
本发明的第五的方式的程序使计算机作为推理装置发挥功能,该推理装置参照组合自互信息量模型、序列自互信息量模型和对象已学习模型进行推理,该组合自互信息量模型是根据预定的词性的多个单词的组合和语料库中的所述组合的自互信息量即组合自互信息量进行学习后的已学习模型,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,该对象已学习模型是与所述组合自互信息量模型和所述序列自互信息量模型不同的已学习模型,其特征在于,所述程序使所述计算机作为以下部分发挥功能:取得部,其取得2以上的数量作为提问句和针对所述提问句的回答的步骤数;步骤句生成部,其从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,在所述多个步骤句各自之前连结所述提问句,由此生成多个带提问的步骤句;词素分析执行部,其对所述多个带提问的步骤句分别执行词素分析,由此确定所述多个带提问的步骤句中分别包含的多个单词的词性;第一推理部,其根据所确定的所述词性确定从所述多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合,参照所述组合自互信息量模型确定所确定的所述组合的似然度,由此确定所述多个步骤句各自的似然度即第一似然度,从使用所述第一似然度筛选所述多个步骤句而提取出的多个带提问的步骤句中去除所述提问句,由此生成第一多个对象步骤句,根据所确定的所述词性确定从所述第一多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述第一多个对象步骤句各自的似然度即第二似然度,使用所述第二似然度筛选所述第一多个对象步骤句,由此提取第二多个对象步骤句;以及第二推理部,其参照所述对象已学习模型确定所述第二多个对象步骤句各自的似然度即排序用似然度。
本发明的第一方式的学习方法的特征在于,对多个字符串执行词素分析,由此确定所述多个字符串中包含的多个单词的词性,根据所确定的所述词性,确定从所述多个字符串中选择出的多个单词即多个对象词的序列,计算语料库中的所述序列的自互信息量即序列自互信息量,进行所述序列和所述序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。
本发明的第二方式的学习方法的特征在于,对由构成提问句的字符串和构成针对所述提问句的回答句的多个字符串构成的第一多个字符串执行词素分析,由此确定所述第一多个字符串中包含的多个单词的词性,对构成针对所述提问句的回答句的多个字符串即第二多个字符串执行词素分析,由此确定所述第二多个字符串中包含的多个单词的词性,根据基于所述第一多个字符串确定的所述词性确定从所述第一多个字符串中选择出的多个单词即第一多个对象词的组合,根据基于所述第二多个字符串确定的所述词性确定从所述第二多个字符串中选择出的多个单词即第二多个对象词的序列,计算语料库中的所述组合的自互信息量即组合自互信息量,进行所述组合和所述组合自互信息量的学习,由此生成作为已学习模型的组合自互信息量模型,计算语料库中的所述序列的自互信息量即序列自互信息量,进行所述序列和所述序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。
本发明的第一方式的推理方法参照序列自互信息量模型进行推理,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,其特征在于,取得2以上的数量作为针对提问句的回答的步骤数,从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,对所述多个步骤句分别执行词素分析,由此确定所述多个步骤句中分别包含的多个单词的词性,根据所确定的所述词性确定从所述多个步骤句中分别选择出的多个单词即多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述多个步骤句各自的似然度即排序用似然度。
本发明的第二方式的推理方法参照组合自互信息量模型和序列自互信息量模型进行推理,该组合自互信息量模型是根据预定的词性的多个单词的组合和语料库中的所述组合的自互信息量即组合自互信息量进行学习后的已学习模型,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,其特征在于,取得2以上的数量作为提问句和针对所述提问句的回答的步骤数,从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,在所述多个步骤句各自之前连结所述提问句,由此生成多个带提问的步骤句,对所述多个带提问的步骤句分别执行词素分析,由此确定所述多个带提问的步骤句中分别包含的多个单词的词性,根据所确定的所述词性确定从所述多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合,参照所述组合自互信息量模型确定所确定的所述组合的似然度,由此确定所述多个步骤句各自的似然度即第一似然度,从使用所述第一似然度筛选所述多个步骤句而提取出的多个带提问的步骤句中去除所述提问句,由此生成多个对象步骤句,根据所确定的所述词性确定从所述多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述多个步骤句各自的似然度即排序用似然度。
本发明的第三方式的推理方法参照组合自互信息量模型、序列自互信息量模型和对象已学习模型进行推理,该组合自互信息量模型是根据预定的词性的多个单词的组合和语料库中的所述组合的自互信息量即组合自互信息量进行学习后的已学习模型,该序列自互信息量模型是根据预定的词性的多个单词的序列和语料库中的所述序列的自互信息量即序列自互信息量进行学习后的已学习模型,该对象已学习模型是与所述组合自互信息量模型和所述序列自互信息量模型不同的已学习模型,其特征在于,取得2以上的数量作为提问句和针对所述提问句的回答的步骤数,从成为针对所述提问句的回答候选的多个候选句中提取所述步骤数的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句分别包含所述两个以上的候选句的所述多个步骤句,在所述多个步骤句各自之前连结所述提问句,由此生成多个带提问的步骤句,对所述多个带提问的步骤句分别执行词素分析,由此确定所述多个带提问的步骤句中分别包含的多个单词的词性,根据所确定的所述词性确定从所述多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合,参照所述组合自互信息量模型确定所确定的所述组合的似然度,由此确定所述多个步骤句各自的似然度即第一似然度,从使用所述第一似然度筛选所述多个步骤句而提取出的多个带提问的步骤句中去除所述提问句,由此生成第一多个对象步骤句,根据所确定的所述词性确定从所述第一多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照所述序列自互信息量模型确定所确定的所述序列的似然度,由此确定所述第一多个对象步骤句各自的似然度即第二似然度,使用所述第二似然度筛选所述第一多个对象步骤句,由此提取第二多个对象步骤句,参照所述对象已学习模型确定所述第二多个对象步骤句各自的似然度即排序用似然度。
发明效果
根据本发明的一个或多个方式,能够以较少的计算量进行模型的学习和推理。
附图说明
图1是概略地示出实施方式1的信息处理装置的结构的框图。
图2是概略地示出作为信息处理装置的实现例的计算机的结构的框图。
图3是示出实施方式1的信息处理装置中进行序列自互信息量模型的学习的动作的流程图。
图4是概略地示出实施方式2的信息处理装置的结构的框图。
图5是示出实施方式2的信息处理装置中进行常识推理的动作的流程图。
图6是概略地示出实施方式3的信息处理装置的结构的框图。
图7是示出实施方式3的信息处理装置中进行组合自互信息量模型的学习的动作的流程图。
图8是概略地示出实施方式4的信息处理装置的结构的框图。
图9是示出实施方式4的信息处理装置中进行常识推理的动作的流程图。
图10是概略地示出实施方式5的信息处理装置的结构的框图。
图11是示出实施方式5的信息处理装置中进行常识推理的动作的流程图。
具体实施方式
实施方式1
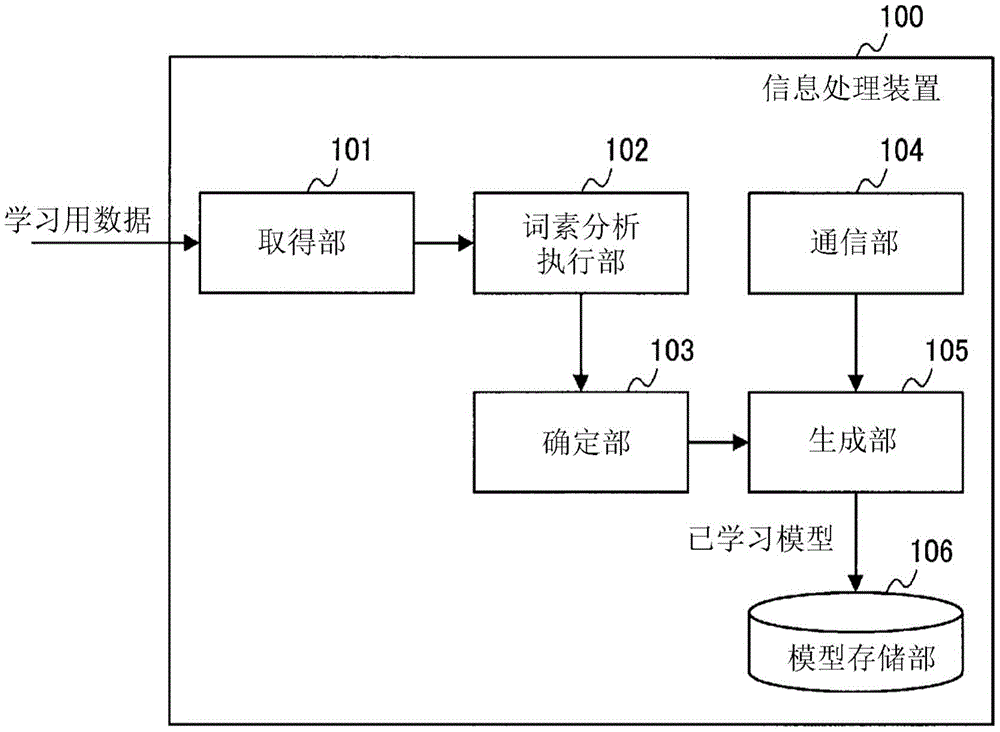
图1是概略地示出作为实施方式1的学习装置发挥功能的信息处理装置100的结构的框图。
信息处理装置100具有取得部101、词素分析执行部102、确定部103、通信部104、生成部105和模型存储部106。
取得部101取得学习用数据。学习用数据是包含多个字符串的文本数据。例如,取得部101可以经由通信部104从其他装置取得学习用数据,也可以经由未图示的输入部从用户等取得学习用数据。然后,取得部101将学习用数据提供给词素分析执行部102。另外,这里,设多个字符串是针对提问句的回答。
词素分析执行部102对由学习用数据表示的多个字符串执行词素分析,由此确定多个字符串中包含的多个单词各自的词性。
然后,词素分析执行部102将表示确定了词性的多个单词的带词性的单词数据提供给确定部103。
确定部103根据所确定的词性,从由带词性的单词数据表示的确定了词性的多个单词中进行选择,由此确定多个单词即多个对象词的序列。这里,设多个对象词是一个项和两个谓语,但是不限于这种例子。然后,确定部103将表示所确定的序列的序列数据提供给生成部105。
这里,谓语是动词、形容词、形容动词或サ变名词,项是能够成为主语或宾语的单词,这里设为名词。
通信部104与其他装置进行通信。这里,例如与互联网上的服务器(未图示)进行通信,由此能够与该服务器中蓄积的语料库连接。语料库是将自然语言的文章结构化并大规模集成的数据。
生成部105经由通信部104与语料库连接,由此计算由序列数据表示的一个项和两个谓语的序列在语料库中的自互信息量即序列自互信息量。
序列自互信息量例如通过下述的(1)式来计算。
这里,w
此外,P(w
这里,在项w
此外,在项w
例如,“ペンを、持って、書く”和“ペンで、書いて、持つ”的意思不同,因此,在一个项和两个谓语的序列中计算出现概率,由此能够进行与由于这三个词的顺序而产生的意思差异对应的模型的学习。此时,功能词不具有实质上的意思,因此,在进行后述的词素分析时被删除,“ペンを、持って、書く”被转换为“ペン、持つ、書く”的内容词的标准形,“ペンで、書いて、持つ”也同样被转换为“ペン、書く、持つ”,换言之,虽然是由相同单词构成的Bag-of-wors,但是,能够以不同的似然度进行序列不同的模式的学习。
然后,生成部105进行一个项和两个谓语的序列以及计算出的序列自互信息量的学习,由此生成作为已学习模型的序列自互信息量模型。生成的序列自互信息量模型被存储于模型存储部106。序列自互信息量模型例如是将一个项和两个谓语的序列自互信息量设为2层张量的模型。另外,下面,将2层张量描述为三轴张量。
模型存储部106是存储序列自互信息量模型的存储部。
图2是概略地示出作为信息处理装置100的实现例的计算机120的结构的框图。
信息处理装置100能够通过具有非易失性存储器121、易失性存储器122、NIC(Network Interface Card:网络接口卡)123和处理器124的计算机120来实现。
非易失性存储器121是存储信息处理装置100中的处理所需的数据和程序的辅助存储装置。例如,非易失性存储器121是HDD(Hard Disk Drive:硬盘驱动器)或SSD(SolidState Drive:固态驱动器)。
易失性存储器122是对处理器124提供作业区域的主存储装置。例如,易失性存储器122是RAM(Random Access Memory:随机存取存储器)。
NIC123是用于与其他装置进行通信的通信接口。
处理器124对信息处理装置100中的处理进行控制。例如,处理器124是CPU(Central Processing Unit:中央处理单元)或FPGA(Field Programmable Gate Array:现场可编程门阵列)等。处理器124也可以是多处理器。
例如,处理器124将非易失性存储器121中存储的程序读出到易失性存储器122,执行该程序,由此能够实现取得部101、词素分析执行部102、确定部103和生成部105。这种程序可以通过网络来提供,此外,也可以记录于记录介质来提供。即,这种程序例如也可以作为程序产品来提供。
模型存储部106能够通过非易失性存储器121来实现。
通信部104能够通过NIC123来实现。
另外,信息处理装置100可以通过处理电路来实现,或者,也可以通过软件、固件或它们的组合来实现。另外,处理电路也可以是单一电路或复合电路。
换言之,信息处理装置100能够通过处理电路网来实现。
图3是示出实施方式1的信息处理装置100中进行序列自互信息量模型的学习的动作的流程图。
首先,取得部101取得学习用数据(S10)。然后,取得部101将该学习用数据提供给词素分析执行部102。
词素分析执行部102对由学习用数据表示的多个字符串执行词素分析,由此确定多个字符串中包含的多个单词各自的词性(S11)。然后,词素分析执行部102删除确定了词性的多个单词中的(在本实施方式中为动词、形容词、形容动词、サ变名词和名词以外的词性的)单词,将其余的单词转换为标准形。然后,词素分析执行部102将表示被转换为标准形的单词和不需要转换为标准形的单词的带词性的单词数据提供给确定部103。
确定部103判断在由带词性的单词数据表示的确定了词性的多个单词中是否包含两个以上的谓语(S12)。在包含两个以上的谓语的情况下(S12:是),处理进入步骤S13,在包含一个以下的谓语的情况下(S12:否),处理结束。在本实施方式中,在单词的词性为动词、形容词、形容动词和サ变名词中的任意一方的情况下,该单词被判断为谓语。
在步骤S13中,确定部103从由带词性的单词数据表示的确定了词性的多个单词中确定由一个项和两个谓语构成的一个序列。这里确定的序列是还未在步骤S14中计算序列自互信息量的序列。然后,确定部103将表示所确定的序列的序列数据提供给生成部105。这里,未判定为谓语的单词成为项。
生成部105经由通信部104与语料库连接,由此计算由序列数据表示的一个项和两个谓语的序列在语料库中的自互信息量即序列自互信息量(S14)。然后,生成部105进行一个项、两个谓语和计算出的序列自互信息量的学习,由此将它们关联起来,登记于模型存储部106中存储的序列自互信息量模型。
接着,确定部103判断是否留有还未计算序列自互信息量的序列(S15)。在留有这种序列的情况下(S15:是),处理返回步骤S13,在未留有这种序列的情况下(S15:否),处理结束。
如上所述,根据实施方式1,能够将与一个项和两个谓语出现的顺序对应的自互信息量作为已学习模型进行蓄积。
另外,在实施方式1中,生成部105经由通信部104与外部的语料库连接,但是,实施方式1不限于这种例子。例如,也可以在模型存储部106或未图示的其他存储部中存储语料库。这种情况下,不需要通信部104。
此外,在实施方式1中,在信息处理装置100内设置有模型存储部106,但是,实施方式1不限于这种例子。例如,生成部105也可以经由通信部104使设置于其他装置的存储部(未图示)存储序列自互信息量模型。该情况下,不需要信息处理装置100内的模型存储部106。
实施方式2
图4是概略地示出作为实施方式2的推理装置发挥功能的信息处理装置200的结构的框图。
信息处理装置200具有取得部201、通信部202、步骤句生成部203、词素分析执行部204、推理部205和排序部206。
实施方式2的推理装置是参照序列自互信息量模型进行推理的装置。
取得部201取得步骤数数据。步骤数数据是表示针对提问句的回答的步骤的数量即步骤数的数据。例如,取得部201可以经由通信部202从其他装置取得步骤数数据,也可以经由未图示的输入部取得步骤数数据。这里,设步骤数是2以上的数量。因此,取得部201取得2以上的数量作为步骤数。
然后,取得部201将步骤数数据提供给步骤句生成部203。
通信部202与其他装置进行通信。这里,通信部202例如与互联网上的服务器进行通信,由此能够从该服务器具有的候选句存储部130或模型存储部131接收数据。
这里,候选句存储部130存储表示成为针对提问句的回答候选的多个候选句的候选句数据。
模型存储部131存储通过与实施方式1相同的动作生成的序列自互信息量模型作为已学习模型。
步骤句生成部203经由通信部202参照候选句存储部130中存储的候选句数据,由此提取与由从取得部201提供的步骤数数据表示的步骤数相同数量的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句。例如,在步骤数为“2”、一个候选句为“将米量好放入内锅。”、下一个候选句为“清洗米。”的情况下,作为这些候选句的一个序列的“将米量好放入内锅。清洗米。”成为步骤句。该情况下,作为另一个序列的“清洗米。将米量好放入内锅。”也成为步骤句。换言之,多个步骤句分别包含提取出的两个以上的候选句。步骤句生成部203将表示多个步骤句的步骤句数据提供给词素分析执行部204。
词素分析执行部204对由步骤句数据表示的多个步骤句分别执行词素分析,由此确定多个步骤句中分别包含的多个单词各自的词性。然后,词素分析执行部204将按照每个步骤句表示确定了词性的多个单词的带词性的单词数据提供给推理部205。
推理部205根据所确定的词性,确定从由带词性的单词数据表示的确定了词性的多个单词中选择出的多个单词即多个对象词的序列,经由通信部202参照模型存储部131中存储的序列自互信息量模型,由此确定所确定的序列的似然度。这里,设多个对象词是一个项和两个谓语,但是不限于这种例子。
然后,推理部205在根据一个步骤句能够确定多个序列的情况下,将对该多个序列的似然度进行平均而得到的值即平均值设为该步骤句的确定似然度。另外,在根据一个步骤句仅确定一个序列的情况下,该一个序列的似然度成为确定似然度。推理部205将按照每个步骤句表示确定似然度的确定似然度数据提供给排序部206。这里的确定似然度也称作排序用似然度。
排序部206按照由确定似然度数据表示的确定似然度进行多个步骤句的排序。例如,排序部206按照由确定似然度数据表示的确定似然度从高到低的顺序对步骤句进行排序。
以上记载的信息处理装置200也能够通过图2所示的计算机120来实现。
例如,处理器124将非易失性存储器121中存储的程序读出到易失性存储器122,执行该程序,由此能够实现取得部201、步骤句生成部203、词素分析执行部204、推理部205和排序部206。
通信部202能够通过NIC123来实现。
图5是示出实施方式2的信息处理装置200中进行常识推理的动作的流程图。
首先,取得部201取得步骤数数据(S20)。然后,取得部201将步骤数数据提供给步骤句生成部203。
步骤句生成部203经由通信部202参照候选句存储部130中存储的候选句数据,由此生成连结与由从取得部201提供的步骤数数据表示的步骤数相同数量的候选句的序列而成的步骤句(S21)。然后,步骤句生成部203将表示多个步骤句的步骤句数据提供给词素分析执行部204。
词素分析执行部204对由步骤句数据表示的多个步骤句分别执行词素分析,由此确定多个步骤句中分别包含的多个单词各自的词性(S22)。然后,词素分析执行部204将按照每个步骤句表示确定了词性的多个单词的带词性的单词数据提供给推理部205。
推理部205经由通信部202参照模型存储部131中存储的序列自互信息量模型,由此,从由带词性的单词数据表示的确定了词性的多个单词中,按照每个步骤句确定一个项和两个谓语的序列,确定该序列中的似然度。然后,推理部205将对能够根据一个步骤句确定的序列的似然度进行平均而得到的值设为该步骤句的确定似然度(S22)。推理部205将按照每个步骤句表示确定似然度的确定似然度数据提供给排序部206。
排序部206按照由确定似然度数据表示的确定似然度从高到低的顺序对步骤句进行排序(S23)。由此,能够按照确定似然度从高到低的顺序确定步骤句。
如上所述,根据实施方式2,能够根据一个项和两个谓语的出现顺序,从步骤句中确定似然度高的步骤句。
推理部205使用了多个序列的似然度平均,但是,也可以使用除以步骤句的单词数而得到的平均。此外,推理部205也可以使用针对提问句的序列的两个单词和步骤句的序列的两个单词的模型的张量的余弦距离。
实施方式3
图6是概略地示出作为实施方式3的学习装置发挥功能的信息处理装置300的结构的框图。
信息处理装置300具有取得部301、词素分析执行部302、确定部303、通信部104、生成部305、第一模型存储部307和第二模型存储部308。
实施方式3的信息处理装置300的通信部104与实施方式1的信息处理装置100的通信部104相同。
取得部301取得第一学习用数据和第二学习用数据。第一学习用数据和第二学习用数据是包含多个字符串的文本数据。例如,取得部301可以经由通信部104从其他装置取得第一学习用数据和第二学习用数据,也可以经由未图示的输入部从用户等取得第一学习用数据和第二学习用数据。然后,取得部301将第一学习用数据和第二学习用数据提供给词素分析执行部302。
设第一学习用数据表示由构成提问句的字符串和构成针对该提问句的回答句的多个字符串构成的第一多个字符串。换言之,针对该提问句的回答句包含两个以上的句子,包含多个步骤。
此外,设第二学习用数据表示构成针对提问句的回答句的多个字符串即第二多个字符串。换言之,针对该提问句的回答句包含两个以上的句子,包含多个步骤。
词素分析执行部302对由第一学习用数据和第二学习用数据分别表示的多个字符串执行词素分析,由此确定多个字符串中包含的多个单词各自的词性。
然后,词素分析执行部302将表示根据第一多个字符串确定了词性的多个单词的第一带词性的单词数据提供给确定部303,将表示根据第二多个字符串确定了词性的多个单词的第二带词性的单词数据提供给确定部303。
确定部303根据所确定的词性,确定从由第一带词性的单词数据表示的确定了词性的多个单词中选择出的多个单词即第一多个对象词的组合。这里,设第一多个对象词是两个项和一个谓语,但是不限于这种例子。然后,确定部303将表示所确定的组合的组合数据提供给生成部305。
此外,确定部303根据所确定的词性,确定从由第二带词性的单词数据表示的确定了词性的多个单词中选择出的多个单词即第二多个对象词的序列。这里,设第二多个对象词是一个项和两个谓语,但是不限于这种例子。然后,确定部303将表示所确定的序列的序列数据提供给生成部305。
生成部305经由通信部104与语料库连接,由此计算由组合数据表示的两个项和一个谓语的组合在语料库中的自互信息量即组合自互信息量。
组合自互信息量例如通过下述的(4)式来计算。
这里,v
此外,P(v
此外,与实施方式1同样,生成部305经由通信部104与语料库连接,由此计算由组合数据表示的一个项和两个谓语的组合在语料库中的自互信息量即组合自互信息量。
然后,生成部305进行两个项和一个谓语的组合以及计算出的组合自互信息量的学习,由此生成作为第一已学习模型的组合自互信息量模型。生成的组合自互信息量模型被存储于第一模型存储部307。组合自互信息量模型例如是将与两个项和一个谓语的组合对应的组合自互信息量设为三轴张量的模型。
此外,生成部305进行一个项和两个谓语的序列以及计算出的序列自互信息量的学习,由此生成作为第二已学习模型的序列自互信息量模型。生成的序列自互信息量模型被存储于第二模型存储部308。序列自互信息量模型例如是将与一个项和两个谓语的序列对应的序列自互信息量设为三轴张量的模型。
第一模型存储部307是存储组合自互信息量模型的第一存储部。
第二模型存储部308是存储序列自互信息量模型的第二存储部。
图6所示的信息处理装置300也能够通过图2所示的计算机120来实现。
例如,处理器124将非易失性存储器121中存储的程序读出到易失性存储器122,执行该程序,由此能够实现取得部301、词素分析执行部302、确定部303和生成部305。
第一模型存储部307和第二模型存储部308能够通过非易失性存储器121来实现。
通信部104能够通过NIC123来实现。
另外,信息处理装置300可以通过处理电路来实现,或者,也可以通过软件、固件或它们的组合来实现。另外,处理电路也可以是单一电路或复合电路。
换言之,信息处理装置300能够通过处理电路网来实现。
在实施方式3中,根据第二学习用数据生成序列自互信息量模型的动作与实施方式1相同,因此,这里,对根据第一学习用数据生成组合自互信息模型的动作进行说明。
图7是示出实施方式3的信息处理装置300中进行组合自互信息量模型的学习的动作的流程图。
首先,取得部301取得第一学习用数据(S30)。然后,取得部301将第一学习用数据提供给词素分析执行部302。
词素分析执行部302对由第一学习用数据表示的多个字符串执行词素分析,由此确定多个字符串中包含的多个单词各自的词性(S31)。然后,词素分析执行部302将表示确定了词性的多个单词的第一带词性的单词数据提供给确定部303。
确定部303判断在由第一带词性的单词数据表示的确定了词性的多个单词中是否包含一个以上的谓语(S32)。在包含一个以上的谓语的情况下(S32:是),处理进入步骤S33,在不包含谓语的情况下(S32:否),处理结束。
在步骤S33中,确定部303从由带词性的单词数据表示的确定了词性的多个单词中确定由两个项和一个谓语构成的一个组合。这里确定的组合是还未在步骤S34中计算组合自互信息量的组合。然后,确定部303将表示所确定的组合的组合数据提供给生成部305。
生成部305经由通信部104与语料库连接,由此计算由组合数据表示的两个项和一个谓语的组合在语料库中的自互信息量即组合自互信息量(S34)。然后,生成部305进行两个项、一个谓语和计算出的组合自互信息量的学习,由此将它们对应起来,登记于第一模型存储部307中存储的组合自互信息量模型。
接着,确定部303判断是否留有还未计算组合自互信息量的组合(S35)。在留有这种组合的情况下(S35:是),处理返回步骤S33,在未留有这种组合的情况下(S35:否),处理结束。
如上所述,根据实施方式3,能够将与两个项和一个谓语的组合对应的自互信息量以及与一个项和两个谓语出现的顺序对应的自互信息量作为已学习模型进行蓄积。
另外,在实施方式3中,生成部305经由通信部104与外部的语料库连接,但是,实施方式3不限于这种例子。例如,也可以在第一模型存储部307、第二模型存储部308或未图示的其他存储部中存储语料库。这种情况下,不需要通信部104。
此外,在实施方式3中,在信息处理装置300内设置有第一模型存储部307和第二模型存储部308,但是,实施方式3不限于这种例子。例如,生成部305也可以经由通信部104使设置于其他装置的存储部(未图示)存储组合自互信息量模型和序列自互信息量模型中的至少任意一方。这种情况下,不需要设置于信息处理装置300内的第一模型存储部307和第二模型存储部308中的任意一方。
实施方式4
图8是概略地示出作为实施方式4的推理装置发挥功能的信息处理装置400的结构的框图。
信息处理装置400具有取得部401、通信部402、步骤句生成部403、词素分析执行部404、推理部405和排序部406。
实施方式4的推理装置是参照组合自互信息量模型和序列自互信息量模型进行推理的装置。
取得部401取得提问句数据和步骤数数据。提问句数据是表示提问句的字符串的文本数据。步骤数数据是表示针对由提问句数据表示的提问句的回答的步骤的数量即步骤数的数据。例如,取得部401可以经由通信部402从其他装置取得提问句数据和步骤数数据,也可以经由未图示的输入部取得提问句数据和步骤数数据。这里,设步骤数为2以上的数量。因此,取得部401取得2以上的数量作为提问句和成为针对该提问句的回答的步骤的数量。
然后,取得部401将提问句数据和步骤数数据提供给步骤句生成部403。
通信部402与其他装置进行通信。这里,通信部402例如与互联网上的服务器进行通信,由此能够从该服务器具有的候选句存储部432、第一模型存储部433或第二模型存储部434接收数据。
这里,候选句存储部432存储表示成为针对提问句的回答候选的多个候选句的候选句数据。
第一模型存储部433存储通过与实施方式3相同的动作生成的组合自互信息量模型作为第一已学习模型。
第二模型存储部434存储通过与实施方式1相同的动作生成的序列自互信息量模型作为第二已学习模型。
步骤句生成部403经由通信部402参照候选句存储部432中存储的候选句数据,由此提取与由从取得部401提供的步骤数数据表示的步骤数相同数量的候选句,连结提取出的两个以上的候选句,由此生成多个步骤句。换言之,多个步骤句分别包含两个以上的候选句。
进而,步骤句生成部403在生成的多个步骤句各自之前连结由提问句数据表示的提问句,由此生成多个带提问的步骤句。
例如,在由提问句数据表示的提问句为“要煮饭。”且步骤句为“将米量好放入内锅。清洗米。”的情况下,带提问的步骤句成为“要煮饭。将米量好放入内锅。清洗米。”。
步骤句生成部403将表示多个带提问的步骤句的带提问的步骤句数据提供给词素分析执行部404。
词素分析执行部404对由带提问的步骤句数据表示的多个带提问的步骤句分别执行词素分析,由此确定多个带提问的步骤句中分别包含的多个单词各自的词性。
然后,词素分析执行部404将按照每个带提问的步骤句表示确定了词性的多个单词的第一带词性的单词数据提供给推理部405。
推理部405根据所确定的词性,确定从由第一带词性的单词数据表示的确定了词性的多个单词中选择出的多个单词即第一多个对象词的组合,经由通信部402参照第一模型存储部433中存储的组合自互信息量模型,由此确定该组合的似然度。设第一多个对象词是两个项和一个谓语,但是不限于这种例子。然后,推理部405在根据一个带提问的步骤句能够确定多个组合的情况下,将对能够根据一个带提问的步骤句确定的多个组合的似然度进行平均而得到的值即平均值设为该带提问的步骤句的确定似然度。此外,在根据一个带提问的步骤句仅确定一个组合的情况下,该一个组合的似然度成为确定似然度。这里确定的确定似然度也称作第一似然度。
接着,推理部405使用作为第一似然度的确定似然度筛选多个步骤句,由此提取多个带提问的步骤句。例如,推理部405按照作为第一似然度的确定似然度从高到低的顺序提取预定数量的带提问的步骤句。然后,推理部405从提取出的多个带提问的步骤句中去除提问句,由此生成多个对象步骤句。然后,推理部405生成表示生成的多个对象步骤句中分别包含的确定了词性的多个单词的第二带词性的单词数据。
进而,推理部405从由第二带词性的单词数据表示的确定了词性的多个单词中,根据所确定的词性,确定预定的词性的多个单词即第二多个对象词的序列。然后,推理部405经由通信部402参照第二模型存储部434中存储的序列自互信息量模型,由此确定第二多个对象词的序列中的似然度。这里,设第二多个对象词是一个项和两个谓语,但是不限于这种例子。
然后,推理部405在根据一个步骤句能够确定多个序列的情况下,将对该多个序列的似然度进行平均而得到的值即平均值设为该步骤句的确定似然度。在根据一个步骤句仅能够确定一个序列的情况下,该一个序列的似然度成为确定似然度。推理部405将按照每个步骤句表示步骤句的确定似然度的确定似然度数据提供给排序部406。另外,这里确定的确定似然度也称作排序用似然度。
排序部406按照由确定似然度数据表示的确定似然度进行多个步骤句的排序。例如,排序部406按照由确定似然度数据表示的确定似然度从高到低的顺序对步骤句进行排序。
以上记载的信息处理装置400也能够通过图2所示的计算机120来实现。
例如,处理器124将非易失性存储器121中存储的程序读出到易失性存储器122,执行该程序,由此能够实现取得部401、步骤句生成部403、词素分析执行部404、推理部405和排序部406。
此外,通信部402能够通过NIC123来实现。
图9是示出实施方式4的信息处理装置400中进行常识推理的动作的流程图。
首先,取得部401取得提问句数据和步骤数数据(S40)。然后,取得部401将提问句数据和步骤数数据提供给步骤句生成部403。
步骤句生成部403经由通信部402参照候选句存储部432中存储的候选句数据,由此生成连结与由从取得部401提供的步骤数数据表示的步骤数相同数量的候选句的序列而成的步骤句,在该步骤句之前连结由提问句数据表示的提问句,由此生成带提问的步骤句(S41)。然后,步骤句生成部403将表示多个带提问的步骤句的带提问的步骤句数据提供给词素分析执行部404。
词素分析执行部404对由带提问的步骤句数据表示的多个带提问的步骤句分别执行词素分析,由此确定多个带提问的步骤句中分别包含的多个单词各自的词性(S42)。然后,词素分析执行部404将按照每个带提问的步骤句表示确定了词性的多个单词的第一带词性的单词数据提供给推理部405。
推理部405经由通信部402参照第一模型存储部433中存储的组合自互信息量模型,从由第一带词性的单词数据表示的确定了词性的多个单词中,按照每个带提问的步骤句确定两个项和一个谓语的组合,确定该组合中的似然度。然后,推理部405将对能够根据一个带提问的步骤句确定的组合的似然度进行平均而得到的值设为该带提问的步骤句的确定似然度(S43)。
推理部405按照在步骤S43中确定的确定似然度从高到低的顺序,筛选带提问的步骤句(S44)。例如,推理部405按照在步骤S43中确定的确定似然度从高到低的顺序,提取预定数量的带提问的纯分,由此进行筛选。然后,推理部405在带词性的单词数据中,从与提取出的带提问的步骤句对应的确定了词性的多个单词中删除提问句的单词,并且,确定从所确定的带提问的步骤句中删除了提问句后的步骤句。推理部405按照每个所确定的步骤句,生成表示对应的步骤句中包含的确定了词性的多个单词的第二带词性的单词数据。
接着,推理部405经由通信部402参照第二模型存储部434中存储的序列自互信息量模型,由此,从由第二带词性的单词数据表示的确定了词性的多个单词中,按照每个步骤句确定一个项和两个谓语的序列,确定该序列中的似然度。然后,推理部405将对能够根据一个步骤句确定的序列的似然度进行平均而得到的值设为该步骤句的确定似然度(S45)。推理部405将按照每个步骤句表示在步骤S45中确定的确定似然度的确定似然度数据提供给排序部406。
排序部406按照由确定似然度数据表示的确定似然度从高到低的顺序对步骤句进行排序(S46)。由此,能够按照确定似然度从高到低的顺序来确定步骤句。
如上所述,根据实施方式4,能够根据两个项和一个谓语的出现顺序,从带提问的步骤句中确定似然度高的步骤句,从所确定的步骤句中,根据一个项和两个谓语的出现顺序来确定似然度高的步骤句。
实施方式5
图10是概略地示出作为实施方式5的推理装置发挥功能的信息处理装置500的结构的框图。
信息处理装置500具有取得部401、通信部502、步骤句生成部403、词素分析执行部404、第一推理部505、排序部506和第二推理部507。
实施方式5的推理装置是参照组合自互信息量模型、序列自互信息量模型、以及与组合自互信息量模型和序列自互信息量模型不同的已学习模型进行推理的装置。
实施方式5的信息处理装置500的取得部401、步骤句生成部403和词素分析执行部404与实施方式4的信息处理装置400的取得部401、步骤句生成部403和词素分析执行部404相同。
通信部502与其他装置进行通信。这里,通信部502例如与互联网上的服务器进行通信,由此能够从该服务器具有的候选句存储部432、第一模型存储部433、第二模型存储部434或其他模型存储部535接收数据。
这里,实施方式5中的候选句存储部432、第一模型存储部433和第二模型存储部434与实施方式4中的候选句存储部432、第一模型存储部433和第二模型存储部434相同。
其他模型存储部535存储其他模型,该其他模型是以与组合自互信息量模型和序列自互信息量模型不同的理论进行学习后的已学习模型。例如,作为其他模型,如基于BERT(Bidirectional Encoder Representations from Transformers)的已学习模型、基于RoBERTa(A Robustly Optimized BERT Pretraining Approach)的已学习模型、基于GPT-2(Generative Pre-trained Transformer 2)的已学习模型、基于T5(Text-to-TextTransfer Transformer)的已学习模型、基于Turing NLG(Natural Language Generation)或GPT-3(Generative Pre-trained Transformer 3)的已学习模型等那样,使用基于公知理论的已学习模型即可。
另外,这里,作为其他模型,设为使用基于BERT的已学习模型。其他模型也称作对象已学习模型。
与实施方式4中的推理部405同样,第一推理部505使用第一模型存储部433中存储的组合自互信息量模型和第二模型存储部434中存储的序列自互信息量模型计算每个步骤句的确定似然度。而且,第一推理部505按照计算出的确定似然度从高到低的顺序确定预定数量的步骤句,生成表示所确定的多个步骤句的筛选步骤句数据,将该筛选步骤句数据提供给第二推理部507。
例如,第一推理部505根据由词素分析执行部404确定的词性,确定从多个带提问的步骤句中分别选择出的多个单词即第一多个对象词的组合。第一推理部505参照第一模型存储部433中存储的组合自互信息量模型计算所确定的组合的似然度,由此确定多个步骤句各自的似然度即第一似然度。
进而,第一推理部505从使用第一似然度筛选多个步骤句而提取出的多个带提问的步骤句中去除提问句,由此生成第一多个对象步骤句。而且,第一推理部505根据由词素分析执行部404确定的词性,确定从第一多个对象步骤句中分别选择出的多个单词即第二多个对象词的序列,参照第二模型存储部434中存储的序列自互信息量模型计算所确定的序列的似然度,由此确定第一多个对象步骤句各自的似然度即第二似然度。第一推理部505使用第二似然度筛选第一多个对象步骤句,由此提取第二多个对象步骤句。
最后,第一推理部505生成表示提取出的第二多个对象步骤句的筛选步骤句数据。
第二推理部507参照其他模型存储部535中存储的其他模型,确定第二多个对象步骤句各自的似然度即排序用似然度。
例如,第二推理部507经由通信部502参照其他模型存储部535中存储的其他模型,由此计算由筛选步骤句数据表示的多个步骤句各自的上下文的正确度的似然度。在本实施方式中,使用带提问句的步骤句的单词串的平均似然度求出上下文的正确度。然后,第二推理部507生成按照每个步骤句表示计算出的似然度的似然度数据,将该似然度数据提供给排序部506。另外,由这里的似然度数据表示的似然度成为排序用似然度。
排序部506按照由似然度数据表示的似然度进行多个步骤句的排序。具体而言,排序部506按照由似然度数据表示的似然度从高到低的顺序对步骤句进行排序。
以上记载的信息处理装置500也能够通过图2所示的计算机120来实现。
例如,处理器124将非易失性存储器121中存储的程序读出到易失性存储器122,执行该程序,由此能够实现取得部401、步骤句生成部403、词素分析执行部404、第一推理部505、排序部506和第二推理部507。
此外,通信部502能够通过NIC123来实现。
图11是示出实施方式5的信息处理装置500中进行常识推理的动作的流程图。
首先,取得部401取得提问句数据和步骤数数据(S50)。然后,取得部401将提问句数据和步骤数数据提供给步骤句生成部403。
步骤句生成部403经由通信部502参照候选句存储部432中存储的候选句数据,由此生成连结与由从取得部401提供的步骤数数据表示的步骤数相同数量的候选句的序列而成的步骤句,在该步骤句之前连结由提问句数据表示的提问句,由此生成带提问的步骤句(S51)。然后,步骤句生成部403将表示多个带提问的步骤句的带提问的步骤句数据提供给词素分析执行部404。
词素分析执行部404对由带提问的步骤句数据表示的多个带提问的步骤句分别执行词素分析,由此确定多个带提问的步骤句中分别包含的多个单词各自的词性(S52)。然后,词素分析执行部404将按照每个带提问的步骤句表示确定了词性的多个单词的第一带词性的单词数据提供给第一推理部505。
第一推理部505经由通信部502参照第一模型存储部433中存储的组合自互信息量模型,从由第一带词性的单词数据表示的确定了词性的多个单词中,按照每个带提问的步骤句确定两个项和一个谓语的组合,确定该组合中的似然度。然后,第一推理部505将对能够根据一个带提问的步骤句确定的组合的似然度进行平均而得到的值即平均值设为该带提问的步骤句的确定似然度(S53)。
第一推理部505按照在步骤S53中确定的确定似然度从高到低的顺序,筛选带提问的步骤句(S54)。例如,第一推理部505按照在步骤S53中确定的确定似然度从高到低的顺序,提取预定数量的带提问的步骤句。第一推理部505在带词性的单词数据中,从与提取出的带提问的步骤句对应的确定了词性的多个单词中删除提问句的单词,并且,确定从所确定的带提问的步骤句中删除了提问句后的步骤句。然后,第一推理部505按照每个所确定的步骤句,生成表示对应的步骤句中包含的确定了词性的多个单词的第二带词性的单词数据。
接着,第一推理部505经由通信部502参照第二模型存储部434中存储的序列自互信息量模型,由此,从由第二带词性的单词数据表示的确定了词性的多个单词中,按照每个步骤句确定一个项和两个谓语的序列,确定该序列中的似然度。然后,第一推理部505将对能够根据一个步骤句确定的序列的似然度进行平均而得到的值即平均值设为该步骤句的确定似然度(S55)。
接着,第一推理部505按照在步骤S55中计算出的确定似然度从高到低的顺序筛选步骤句(S56)。例如,第一推理部505按照在步骤S55中计算出的确定似然度从高到低的顺序,提取预定数量的步骤句。然后,第一推理部505生成表示提取出的多个步骤句的筛选步骤句数据,将该筛选步骤句数据提供给第二推理部507。
第二推理部507经由通信部502参照其他模型存储部535中存储的其他模型,由此计算由筛选步骤句数据表示的多个步骤句各自的上下文的正确度的似然度(S57)。然后,第二推理部507生成按照每个步骤句表示计算出的似然度的似然度数据,将该似然度数据提供给排序部506。
排序部506按照由似然度数据表示的似然度从高到低的顺序对步骤句进行排序(S57)。由此,能够按照似然度从高到低的顺序来确定步骤句。
如上所述,根据实施方式5,能够根据两个项和一个谓语的出现顺序,从带提问的步骤句中确定似然度高的步骤句,从所确定的步骤句中,根据一个项和两个谓语的出现顺序来筛选似然度高的步骤句。而且,例如,通过BERT等对筛选出的步骤句的似然度进行推理,由此,即使使用了处理负荷重的理论,也能够减轻处理负荷。
标号说明
100:信息处理装置;101:取得部;102:词素分析执行部;103:确定部;104:通信部;105:生成部;106:模型存储部;200:信息处理装置;201:取得部;202:通信部;203:步骤句生成部;204:词素分析执行部;205:推理部;206:排序部;300:信息处理装置;301:取得部;302:词素分析执行部;303:确定部;305:生成部;307:第一模型存储部;308:第二模型存储部;400:信息处理装置;401:取得部;402:通信部;403:步骤句生成部;404:词素分析执行部;405:推理部;406:排序部;500:信息处理装置;502:通信部;505:第一推理部;506:排序部;507:第二推理部。
- 移动体检测装置及检测方法、移动体学习装置及学习方法、移动体检测系统以及程序
- 图像处理装置、学习装置、图像处理方法、识别基准的生成方法、学习方法和程序
- 一种基于知识图谱的数据推理方法、装置、服务器和介质
- 信息处理装置及估计方法、以及学习装置及学习方法
- 机器学习装置、数值控制装置、数值控制系统以及机器学习方法
- 推理装置、学习装置、推理方法、学习方法、推理程序和学习程序
- 学习装置、学习方法、学习数据生成装置、学习数据生成方法、推理装置和推理方法